"Ping" Tracking
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fill Your Boots: Enhanced Embedded Bootloader Exploits Via Fault Injection and Binary Analysis
IACR Transactions on Cryptographic Hardware and Embedded Systems ISSN 2569-2925, Vol. 2021, No. 1, pp. 56–81. DOI:10.46586/tches.v2021.i1.56-81 Fill your Boots: Enhanced Embedded Bootloader Exploits via Fault Injection and Binary Analysis Jan Van den Herrewegen1, David Oswald1, Flavio D. Garcia1 and Qais Temeiza2 1 School of Computer Science, University of Birmingham, UK, {jxv572,d.f.oswald,f.garcia}@cs.bham.ac.uk 2 Independent Researcher, [email protected] Abstract. The bootloader of an embedded microcontroller is responsible for guarding the device’s internal (flash) memory, enforcing read/write protection mechanisms. Fault injection techniques such as voltage or clock glitching have been proven successful in bypassing such protection for specific microcontrollers, but this often requires expensive equipment and/or exhaustive search of the fault parameters. When multiple glitches are required (e.g., when countermeasures are in place) this search becomes of exponential complexity and thus infeasible. Another challenge which makes embedded bootloaders notoriously hard to analyse is their lack of debugging capabilities. This paper proposes a grey-box approach that leverages binary analysis and advanced software exploitation techniques combined with voltage glitching to develop a powerful attack methodology against embedded bootloaders. We showcase our techniques with three real-world microcontrollers as case studies: 1) we combine static and on-chip dynamic analysis to enable a Return-Oriented Programming exploit on the bootloader of the NXP LPC microcontrollers; 2) we leverage on-chip dynamic analysis on the bootloader of the popular STM8 microcontrollers to constrain the glitch parameter search, achieving the first fully-documented multi-glitch attack on a real-world target; 3) we apply symbolic execution to precisely aim voltage glitches at target instructions based on the execution path in the bootloader of the Renesas 78K0 automotive microcontroller. -

Searching for Privacy: How to Protect Your Search Activity
Searching for Privacy: How to Protect Your Search Activity Abstract: This guide explains how to perform searches anonymously, protecting you from increasingly intrusive tracking and analysis by corporate and governmental organizations. Toll free: 866.760.0222 Toll free: 0808.101.2678 www.ioactive.com Copyright ©2010 by IOActive, Incorporated All Rights Reserved. Contents Understanding the Problem.................................................................................................................. 2 You are not Anonymous ....................................................................................................................... 2 A Solution ............................................................................................................................................. 3 Configuring your computer to perform anonymized searches.............................................................. 5 Conclusion.......................................................................................................................................... 16 References ......................................................................................................................................... 17 About IOActive.................................................................................................................................... 17 Confidential. Proprietary. Understanding the Problem If you have something that you don't want anyone to know, maybe you shouldn't be doing it in the first place. If you -

Paid Social Trends Iprospect QUARTERLY REPORT | 2017 Q4
Paid Social Trends iPROSPECT QUARTERLY REPORT | 2017 Q4 By Brittany Richter, VP, Head of Social Media and Katherine Patton, Director, Paid Social iProspect.com COPYRIGHT 2018 © iPROSPECT, INC. ALL RIGHTS RESERVED. iProspect Quarterly Report Paid Social Trends | 2017 Q4 2 Reviewing Overarching Q4 2017 Trends While the cost of inventory continues to rise, so does the value that brands see in paid social advertising. The brands that saw the strongest Q4 business performance were the ones that leveraged the Facebook pixel, optimized toward site engagement (Retail) or Reach (CPG, branding), took advantage of Dynamic Broad Audiences (DABA), and planned content designed for the feed. Based on iProspect client data, paid social continues to drive performance in its own right while also fueling our clients’ first-party data, which can be leveraged to drive cross-channel performance. The following trends and insights are based on analysis of the data from more than 210 brands managed by iProspect U.S. (though the spend is not confined to U.S. mar- kets). The spend data is representative of Facebook, Instagram, Pinterest, Snap, Inc., and Twitter, while performance data is specific to Facebook and Instagram only. SPEND Overall, iProspect’s paid social clients’ total Q4 social spend was up 72% quarter over quarter (QoQ) compared to Q3 2017, and 86% year over year (YoY) when compared to Q4 of 2016. Q4 is consistently the busiest time of the year for many of our clients, so it’s not unusual to see an increase spend as they strive to hit annual goals and capitalize on the holiday time period. -

Using Static and Dynamic Binary Analysis with Ret-Sync
Bière sécu Bordeaux 1st event Date 26/02/2020 Place Zytho By Jiss – Daniel – Tiana Combining static and dynamic binary analysis ret-sync Date 26/02/2020 Place Zytho By Jean-Christophe Delaunay Context 2 approaches in reverse-engineering (RE) : static (disass/decompile) IDA, Ghidra, etc. dynamic (debug) x64dbg, WinDbg, LLDB, etc. Possible to combine both worlds in the same tool… … but often painful to use (eg. IDA dbg) Annoying to switch between multiple tools 3 / 29 Context Classical example: I’m debugging using WinDbg, I spot a routine or structure which seems interesting I’d like to know if I’ve already documented it within IDA … I need to compute the offset from the load address of my module (ASLR/relloc) … add it to the preferred load address of my module in my idb Conclusion: straightforward but painful if I have to do that every 2 minutes … even more painful provided that I use x64dbg for usermode and WinDbg for kernelmode 4 / 29 Solutions Code a new tool which would combine both worlds… 5 / 29 Solutions Code a new tool which would combine both worlds… 6 / 29 Solutions Code a new tool which would combine both worlds… Set-up a glue which would create an interface between the disass and the debugger(s)… … ret-sync by Alexandre Gazet https://github.com/bootleg/ret-sync 7 / 29 ret-sync: support Static: IDA Ghidra Dynamic: WinDbg(-preview) GDB LLDB OllyDbg 1.10 OllyDbg v2 x64dbg 8 / 29 ret-sync: features Permits to “follow” the program workflow in IDA/Ghidra view “step” in the dbg “step” in the disass static view Dynamic switching between multiple idbs trace within toto.exe trace within toto.idb toto.exe issues a call in fistouille.dll switch to fistouille.idb Automagical rebase Sending commands to the dbg (bp, hbp, lbl, etc.) Custom commands1 All features are available both in disass AND decompiled views etc. -

Longitudinal Study of Links, Linkshorteners, and Bitly Usage on Twitter Longitudinella Mätningar Av Länkar, Länkförkortare Och Bitly An- Vänding På Twitter
Linköping University | Department of Computer and Information Science Bachelor’s thesis, 16 ECTS | Link Usage 2020 | LIU-IDA/LITH-EX-G--20/001--SE Longitudinal study of links, linkshorteners, and Bitly usage on Twitter Longitudinella mätningar av länkar, länkförkortare och Bitly an- vänding på Twitter Mathilda Moström Alexander Edberg Supervisor : Niklas Carlsson Examiner : Marcus Bendtsen Linköpings universitet SE–581 83 Linköping +46 13 28 10 00 , www.liu.se Upphovsrätt Detta dokument hålls tillgängligt på Internet - eller dess framtida ersättare - under 25 år från publicer- ingsdatum under förutsättning att inga extraordinära omständigheter uppstår. Tillgång till dokumentet innebär tillstånd för var och en att läsa, ladda ner, skriva ut enstaka ko- pior för enskilt bruk och att använda det oförändrat för ickekommersiell forskning och för undervis- ning. Överföring av upphovsrätten vid en senare tidpunkt kan inte upphäva detta tillstånd. All annan användning av dokumentet kräver upphovsmannens medgivande. För att garantera äktheten, säker- heten och tillgängligheten finns lösningar av teknisk och administrativ art. Upphovsmannens ideella rätt innefattar rätt att bli nämnd som upphovsman i den omfattning som god sed kräver vid användning av dokumentet på ovan beskrivna sätt samt skydd mot att dokumentet ändras eller presenteras i sådan form eller i sådant sammanhang som är kränkande för upphovsman- nens litterära eller konstnärliga anseende eller egenart. För ytterligare information om Linköping University Electronic Press se förlagets hemsida http://www.ep.liu.se/. Copyright The publishers will keep this document online on the Internet - or its possible replacement - for a period of 25 years starting from the date of publication barring exceptional circumstances. The online availability of the document implies permanent permission for anyone to read, to down- load, or to print out single copies for his/hers own use and to use it unchanged for non-commercial research and educational purpose. -
Webtrekk Documentation
Documentation Webtrekk GmbH | Robert-Koch-Platz 4 | 10115 Berlin Webtrekk Support | [email protected] Teaser Tracking Plugin (v2) Table of Contents 1 Disclaimer 3 1.1 Introduction 4 2 Technical Requirements 5 2.1 Browser Support 5 3 Creating Teaser Parameters 6 4 Configuring and Activating the Plugin 8 4.1 Tag Integration (Web) 8 4.2 JavaScript 10 5 Initializing the Teaser Elements 13 6 Best Practices 16 6.1 View Tracking with Dynamic Teaser Insertion 16 6.2 View Tracking 17 6.3 Customizing a Website Goal 18 6.4 Customizing the Engagement Page 18 12/13/2018 2/18 Teaser Tracking Plugin (v2) 1 Disclaimer This manual is the intellectual property of Webtrekk GmbH. This includes the contents but also all images, tables, and drawings. Change or removal of copyright notices, registering mark or control numbers are not allowed. Any use not permitted by German copyright law requires the prior written consent of the respective author or creator. This applies in particular to reproduction, editing, translation, storage, processing or distribution of contents in databases or other electronic media and systems. Webtrekk GmbH allows the use of the content solely for the contractual purpose. It should be noted that the contents of this manual may be subject to changes, without that a reporting obligation on the part of Webtrekk GmbH can be derived from this. Users of this manual must independently obtain information themselves, whether modified versions or notes to the contents are present, for example on the Internet at https://docs.webtrekk.com/, and take these into account during operation. -

Powerview Command Reference
PowerView Command Reference TRACE32 Online Help TRACE32 Directory TRACE32 Index TRACE32 Documents ...................................................................................................................... PowerView User Interface ............................................................................................................ PowerView Command Reference .............................................................................................1 History ...................................................................................................................................... 12 ABORT ...................................................................................................................................... 13 ABORT Abort driver program 13 AREA ........................................................................................................................................ 14 AREA Message windows 14 AREA.CLEAR Clear area 15 AREA.CLOSE Close output file 15 AREA.Create Create or modify message area 16 AREA.Delete Delete message area 17 AREA.List Display a detailed list off all message areas 18 AREA.OPEN Open output file 20 AREA.PIPE Redirect area to stdout 21 AREA.RESet Reset areas 21 AREA.SAVE Save AREA window contents to file 21 AREA.Select Select area 22 AREA.STDERR Redirect area to stderr 23 AREA.STDOUT Redirect area to stdout 23 AREA.view Display message area in AREA window 24 AutoSTOre .............................................................................................................................. -
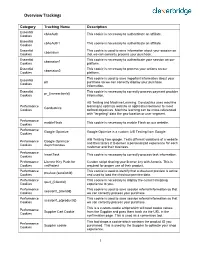
Overview Trackings
Overview Trackings Category Tracking Name Description Essential cbAcAuth This cookie is necessary to authenticate an affiliate. Cookies Essential cbAcAuth1 This cookie is necessary to authenticate an affiliate. Cookies Essential This cookie is used to save information about your session so cbsession Cookies that we can correctly process your purchase. Essential This cookie is necessary to authenticate your session on our cbsession1 Cookies platform. Essential This cookie is necessary to process your actions on our cbsession2 Cookies platform. This cookie is used to save important information about your Essential p0 purchase so we can correctly display your purchase Cookies information. Essential This cookie is necessary to correctly process payment provider pr_{transactionId} Cookies information. AB Testing and Machine Learning. Conductrics uses machine Performance learning to optimize website or application behavior to meet Conductrics Cookies defined objectives. Machine learning can be cross-referenced with "targeting" data like geo-location or user segment. Performance enableFlash This cookie is necessary to enable Flash on our website. Cookies Performance Google Optimize Google Optimize is a custom A/B Testing from Google. Cookies A/B Testing from google. Tests different variations of a website Performance Google Optimizer and then tailors it to deliver a personalized experience for each Cookies Asynchronous customer and their business. Performance InsertTask This cookie is necessary to correctly process task information. Cookies Performance License Key Push for Custom script sharing your license key with Acronis. This is Cookies vmProtect required for proper use of their product. Performance This cookie is used to identify that a checkout preview is active preview-{sessionId} Cookies and used to load the checkout preview data. -

Blue Coat SGOS Command Line Interface Reference, Version 4.2.3
Blue Coat® Systems ProxySG™ Command Line Interface Reference Version SGOS 4.2.3 Blue Coat ProxySG Command Line Interface Reference Contact Information Blue Coat Systems Inc. 420 North Mary Ave Sunnyvale, CA 94085-4121 http://www.bluecoat.com/support/contact.html [email protected] http://www.bluecoat.com For concerns or feedback about the documentation: [email protected] Copyright© 1999-2006 Blue Coat Systems, Inc. All rights reserved worldwide. No part of this document may be reproduced by any means nor modified, decompiled, disassembled, published or distributed, in whole or in part, or translated to any electronic medium or other means without the written consent of Blue Coat Systems, Inc. All right, title and interest in and to the Software and documentation are and shall remain the exclusive property of Blue Coat Systems, Inc. and its licensors. ProxySG™, ProxyAV™, CacheOS™, SGOS™, Spyware Interceptor™, Scope™, RA Connector™, RA Manager™, Remote Access™ are trademarks of Blue Coat Systems, Inc. and CacheFlow®, Blue Coat®, Accelerating The Internet®, WinProxy®, AccessNow®, Ositis®, Powering Internet Management®, The Ultimate Internet Sharing Solution®, Permeo®, Permeo Technologies, Inc.®, and the Permeo logo are registered trademarks of Blue Coat Systems, Inc. All other trademarks contained in this document and in the Software are the property of their respective owners. BLUE COAT SYSTEMS, INC. DISCLAIMS ALL WARRANTIES, CONDITIONS OR OTHER TERMS, EXPRESS OR IMPLIED, STATUTORY OR OTHERWISE, ON SOFTWARE AND DOCUMENTATION FURNISHED HEREUNDER INCLUDING WITHOUT LIMITATION THE WARRANTIES OF DESIGN, MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL BLUE COAT SYSTEMS, INC., ITS SUPPLIERS OR ITS LICENSORS BE LIABLE FOR ANY DAMAGES, WHETHER ARISING IN TORT, CONTRACT OR ANY OTHER LEGAL THEORY EVEN IF BLUE COAT SYSTEMS, INC. -

Your Guide to Installing and Using Coastal Explorer EXPLORING COASTAL EXPLORER Version 4
EXPLORING COASTAL EXPLORER Your guide to installing and using Coastal Explorer EXPLORING COASTAL EXPLORER Version 4 Your guide to installing and using Coastal Explorer Copyright © 2017 Rose Point Navigation Systems. All rights reserved. Rose Point Navigation Systems, Coastal Explorer, and Coastal Explorer Network are trademarks of Rose Point Navigation Systems. The names of any other companies and/or products mentioned herein may be the trademarks of their respective owners. WARNINGS: Use Coastal Explorer at your own risk. Be sure to carefully read and understand the user's manual and practice operation prior to actual use. Coastal Explorer depends on information from the Global Position System (GPS) and digital charts, both of which may contain errors. Navigators should be aware that GPS- derived positions are often of higher accuracy than the positions of charted data. Rose Point Navigation Systems does not warrant the accuracy of any information presented by Coastal Explorer. Coastal Explorer is intended to be used as a supplementary aid to navigation and must not be considered a replacement for official government charts, notices to mariners, tide and current tables, and/or other reference materials. The captain of a vessel is ultimately responsible for its safe navigation and the prudent mariner does not rely on any single source of information. The information in this manual is subject to change without notice. Rose Point Navigation Systems 18005 NE 68th Street Suite A100 Redmond, WA 98052 Phone: 425-605-0985 Fax: 425-605-1285 e-mail: [email protected] www.rosepoint.com Welcome to Coastal Explorer Thank you for choosing Coastal Explorer! If you are new to navigation software, but use a computer for anything else, you will find that Coastal Explorer works just like many other Windows applications: you create documents, edit them, save them, print them, etc. -

Fordcommercialvehiclecenter.Com Privacy Statement
fordcommercialvehiclecenter.com Privacy Statement 1. General Statement: We respect your privacy and are committed to protecting it. This privacy statement explains our policies and practices regarding online customer information. It is through this disclosure that we intend to provide you with a level of comfort and confidence in how we collect, use, and safeguard personal and other information we collect or that you provide through this website, and how you can contact us if you have any questions or concerns. It is our sincere hope that by explaining our data handling practices we will develop a trusting and long-lasting relationship with you. By using the site, you agree to the terms of this privacy statement. 2. Information About Our Organization and Website and General Data Collection Practices: This Privacy Statement applies to www.fordcommercialvehiclecenter.com is administered by Marketing Associates, 777 Woodward Avenue, Detroit, MI 48226 on behalf of Ford Motor Company. The business purpose of this website is to provide Ford commercial business customers with an online Ford Commercial Vehicle Center dealer locator, and product and upfit incentive information. For added convenience, a select set of site features are accessible from web-enabled mobile devices as a mobile-optimized web experience. These site features may be limited in functionality. Online Tracking Information When you visit this site analytics providers may collect information about your online activity over time and across websites. Because there is not yet a common understanding of how to interpret web browser-based “Do Not Track” (“DNT”) signals other than cookies, Ford Motor Company does not currently respond to undefined “DNT” signals to its US websites. -

VNC User Guide 7 About This Guide
VNC® User Guide Version 5.3 December 2015 Trademarks RealVNC, VNC and RFB are trademarks of RealVNC Limited and are protected by trademark registrations and/or pending trademark applications in the European Union, United States of America and other jursidictions. Other trademarks are the property of their respective owners. Protected by UK patent 2481870; US patent 8760366 Copyright Copyright © RealVNC Limited, 2002-2015. All rights reserved. No part of this documentation may be reproduced in any form or by any means or be used to make any derivative work (including translation, transformation or adaptation) without explicit written consent of RealVNC. Confidentiality All information contained in this document is provided in commercial confidence for the sole purpose of use by an authorized user in conjunction with RealVNC products. The pages of this document shall not be copied, published, or disclosed wholly or in part to any party without RealVNC’s prior permission in writing, and shall be held in safe custody. These obligations shall not apply to information which is published or becomes known legitimately from some source other than RealVNC. Contact RealVNC Limited Betjeman House 104 Hills Road Cambridge CB2 1LQ United Kingdom www.realvnc.com Contents About This Guide 7 Chapter 1: Introduction 9 Principles of VNC remote control 10 Getting two computers ready to use 11 Connectivity and feature matrix 13 What to read next 17 Chapter 2: Getting Connected 19 Step 1: Ensure VNC Server is running on the host computer 20 Step 2: Start VNC