Voting Theory for Democracy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

I'll Have What She's Having: Reflective Desires and Consequentialism
I'll Have What She's Having: Reflective Desires and Consequentialism by Jesse Kozler A thesis submitted in partial fulfillment of the requirements for the degree of Bachelor of Arts with Honors Department of Philosophy in the University of Michigan 2019 Advisor: Professor James Joyce Second Reader: Professor David Manley Acknowledgments This thesis is not the product of solely my own efforts, and owes its existence in large part to the substantial support that I have received along the way from the many wonderful, brilliant people in my life. First and foremost, I want to thank Jim Joyce who eagerly agreed to advise this project and who has offered countless insights which gently prodded me to refine my approach, solidify my thoughts, and strengthen my arguments. Without him this project would never have gotten off the ground. I want to thank David Manley, who signed on to be the second reader and whose guidance on matters inside and outside of the realm of my thesis has been indispensable. Additionally, I want to thank Elizabeth Anderson, Peter Railton, and Sarah Buss who, through private discussions and sharing their own work, provided me with inspiration at times I badly needed it and encouraged me to think about previously unexamined issues. I am greatly indebted to the University of Michigan LSA Honors Program who, through their generous Honors Summer Fellowship program, made it possible for me to stay in Ann Arbor and spend my summer reading and thinking intentionally about these issues. I am especially grateful to Mika LaVaque-Manty, who whipped me into shape and instilled in me a work ethic that has been essential to the completion of this project. -

Cesifo Working Paper No. 9141
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Pakhnin, Mikhail Working Paper Collective Choice with Heterogeneous Time Preferences CESifo Working Paper, No. 9141 Provided in Cooperation with: Ifo Institute – Leibniz Institute for Economic Research at the University of Munich Suggested Citation: Pakhnin, Mikhail (2021) : Collective Choice with Heterogeneous Time Preferences, CESifo Working Paper, No. 9141, Center for Economic Studies and Ifo Institute (CESifo), Munich This Version is available at: http://hdl.handle.net/10419/236683 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, If the documents have been made available under an Open gelten abweichend von diesen Nutzungsbedingungen die in der dort Content Licence (especially Creative Commons Licences), you genannten Lizenz gewährten Nutzungsrechte. may exercise further usage rights as specified in the indicated licence. www.econstor.eu 9141 2021 June 2021 Collective Choice with Hetero- geneous Time Preferences Mikhail Pakhnin Impressum: CESifo Working Papers ISSN 2364-1428 (electronic version) Publisher and distributor: Munich Society for the Promotion of Economic Research - CESifo GmbH The international platform of Ludwigs-Maximilians University’s Center for Economic Studies and the ifo Institute Poschingerstr. -

Review of Paradoxes Afflicting Various Voting Procedures Where One out of M Candidates (M ≥ 2) Must Be Elected
Dan S. Felsenthal Review of paradoxes afflicting various voting procedures where one out of m candidates (m ≥ 2) must be elected Workshop Paper Original citation: Felsenthal, Dan S. (2010) Review of paradoxes afflicting various voting procedures where one out of m candidates (m ≥ 2) must be elected. In: Assessing Alternative Voting Procedures, London School of Economics and Political Science, London, UK. This version available at: http://eprints.lse.ac.uk/27685/ Available in LSE Research Online: April 2010 © 2010 Dan S. Felsenthal LSE has developed LSE Research Online so that users may access research output of the School. Copyright © and Moral Rights for the papers on this site are retained by the individual authors and/or other copyright owners. Users may download and/or print one copy of any article(s) in LSE Research Online to facilitate their private study or for non-commercial research. You may not engage in further distribution of the material or use it for any profit-making activities or any commercial gain. You may freely distribute the URL (http://eprints.lse.ac.uk) of the LSE Research Online website. Review of Paradoxes Afflicting Various Voting Procedures Where One Out of m Candidates (m ≥ 2) Must Be Elected* Dan S. Felsenthal University of Haifa and Centre for Philosophy of Natural and Social Science London School of Economics and Political Science Revised 3 May 2010 Prepared for presentation in a symposium and a workshop on Assessing Alternative Voting Procedures Sponsored by The Leverhulme Trust (Grant F/07-004/AJ) London School of Economics and Political Science, 27 May 2010 and Chateau du Baffy, Normandy, France, 30 July – 2 August, 2010 Please send by email all communications regarding this paper to the author at: [email protected] or at [email protected] * I wish to thank Rudolf Fara and Moshé Machover for helpful comments, and Hannu Nurmi for sending me several examples contained in this paper. -

4 Comparative Law and Constitutional Interpretation in Singapore: Insights from Constitutional Theory 114 ARUN K THIRUVENGADAM
Evolution of a Revolution Between 1965 and 2005, changes to Singapore’s Constitution were so tremendous as to amount to a revolution. These developments are comprehensively discussed and critically examined for the first time in this edited volume. With its momentous secession from the Federation of Malaysia in 1965, Singapore had the perfect opportunity to craft a popularly-endorsed constitution. Instead, it retained the 1958 State Constitution and augmented it with provisions from the Malaysian Federal Constitution. The decision in favour of stability and gradual change belied the revolutionary changes to Singapore’s Constitution over the next 40 years, transforming its erstwhile Westminster-style constitution into something quite unique. The Government’s overriding concern with ensuring stability, public order, Asian values and communitarian politics, are not without their setbacks or critics. This collection strives to enrich our understanding of the historical antecedents of the current Constitution and offers a timely retrospective assessment of how history, politics and economics have shaped the Constitution. It is the first collaborative effort by a group of Singapore constitutional law scholars and will be of interest to students and academics from a range of disciplines, including comparative constitutional law, political science, government and Asian studies. Dr Li-ann Thio is Professor of Law at the National University of Singapore where she teaches public international law, constitutional law and human rights law. She is a Nominated Member of Parliament (11th Session). Dr Kevin YL Tan is Director of Equilibrium Consulting Pte Ltd and Adjunct Professor at the Faculty of Law, National University of Singapore where he teaches public law and media law. -
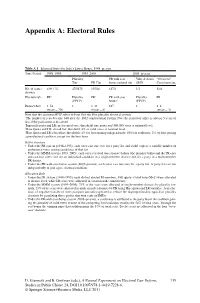
Appendix A: Electoral Rules
Appendix A: Electoral Rules Table A.1 Electoral Rules for Italy’s Lower House, 1948–present Time Period 1948–1993 1993–2005 2005–present Plurality PR with seat Valle d’Aosta “Overseas” Tier PR Tier bonus national tier SMD Constituencies No. of seats / 6301 / 32 475/475 155/26 617/1 1/1 12/4 districts Election rule PR2 Plurality PR3 PR with seat Plurality PR (FPTP) bonus4 (FPTP) District Size 1–54 1 1–11 617 1 1–6 (mean = 20) (mean = 6) (mean = 4) Note that the acronym FPTP refers to First Past the Post plurality electoral system. 1The number of seats became 630 after the 1962 constitutional reform. Note the period of office is always 5 years or less if the parliament is dissolved. 2Imperiali quota and LR; preferential vote; threshold: one quota and 300,000 votes at national level. 3Hare Quota and LR; closed list; threshold: 4% of valid votes at national level. 4Hare Quota and LR; closed list; thresholds: 4% for lists running independently; 10% for coalitions; 2% for lists joining a pre-electoral coalition, except for the best loser. Ballot structure • Under the PR system (1948–1993), each voter cast one vote for a party list and could express a variable number of preferential votes among candidates of that list. • Under the MMM system (1993–2005), each voter received two separate ballots (the plurality ballot and the PR one) and cast two votes: one for an individual candidate in a single-member district; one for a party in a multi-member PR district. • Under the PR-with-seat-bonus system (2005–present), each voter cast one vote for a party list. -

The Rhetoric of the Benign Scapegoat: President Reagan and the Federal Government
Louisiana State University LSU Digital Commons LSU Historical Dissertations and Theses Graduate School 2000 The Rhetoric of the Benign Scapegoat: President Reagan and the Federal Government. Stephen Wayne Braden Louisiana State University and Agricultural & Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_disstheses Recommended Citation Braden, Stephen Wayne, "The Rhetoric of the Benign Scapegoat: President Reagan and the Federal Government." (2000). LSU Historical Dissertations and Theses. 7340. https://digitalcommons.lsu.edu/gradschool_disstheses/7340 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Historical Dissertations and Theses by an authorized administrator of LSU Digital Commons. For more information, please contact [email protected]. INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adversely affect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand comer and continuing from left to right in equal sections with small overlaps. -

Another Consideration in Minority Vote Dilution Remedies: Rent
Another C onsideration in Minority Vote Dilution Remedies : Rent -Seeking ALAN LOCKARD St. Lawrence University In some areas of the United States, racial and ethnic minorities have been effectively excluded from the democratic process by a variety of means, including electoral laws. In some instances, the Courts have sought to remedy this problem by imposing alternative voting methods, such as cumulative voting. I examine several voting methods with regard to their sensitivity to rent-seeking. Methods which are less sensitive to rent-seeking are preferred because they involve less social waste, and are less likely to be co- opted by special interest groups. I find that proportional representation methods, rather than semi- proportional ones, such as cumulative voting, are relatively insensitive to rent-seeking efforts, and thus preferable. I also suggest that an even less sensitive method, the proportional lottery, may be appropriate for use within deliberative bodies, where proportional representation is inapplicable and minority vote dilution otherwise remains an intractable problem. 1. INTRODUCTION When President Clinton nominated Lani Guinier to serve in the Justice Department as Assistant Attorney General for Civil Rights, an opportunity was created for an extremely valuable public debate on the merits of alternative voting methods as solutions to vote dilution problems in the United States. After Prof. Guinier’s positions were grossly mischaracterized in the press,1 the President withdrew her nomination without permitting such a public debate to take place.2 These issues have been discussed in academic circles,3 however, 1 Bolick (1993) charges Guinier with advocating “a complex racial spoils system.” 2 Guinier (1998) recounts her experiences in this process. -

Trump, Condorcet and Borda: Voting Paradoxes in the 2016 Republican Presidential Primaries
Munich Personal RePEc Archive Trump, Condorcet and Borda: Voting paradoxes in the 2016 Republican presidential primaries Kurrild-Klitgaard, Peter University of Copenhagen 15 December 2016 Online at https://mpra.ub.uni-muenchen.de/75598/ MPRA Paper No. 75598, posted 15 Dec 2016 16:00 UTC Trump, Condorcet and Borda: Voting paradoxes in the 2016 Republican presidential primaries1 PETER KURRILD-KLITGAARD Dept. of Political Science, University of Copenhagen Abstract. The organization of US presidential elections make them potentially vulnerable to so-called “voting paradoxes”, identified by social choice theorists but rarely documented empirically. The presence of a record high number of candidates in the 2016 Republican Party presidential primaries may have made this possibility particularly latent. Using polling data from the primaries we identify two possible cases: Early in the pre-primary (2015) a cyclical majority may have existed in Republican voters’ preferences between Bush, Cruz and Walker—thereby giving a rare example of the Condorcet Paradox. Furthermore, later polling data (March 2016) suggests that while Trump (who achieved less than 50% of the total Republican primary vote) was the Plurality Winner, he could have been beaten in pairwise contests by at least one other candidate—thereby exhibiting a case of the Borda Paradox. The cases confirm the empirical relevance of the theoretical voting paradoxes and the importance of voting procedures. Key words: Social choice; Condorcet Paradox; Borda Paradox; US presidential election 2016; Jeb Bush; Chris Christie; Ted Cruz; John Kasich; Marco Rubio; Donald Trump; Scot Walker; voting system. JEL-codes: D71; D72. 1. Introduction Since the 1950s social choice theory has questioned the possibility of aggregating individual preferences to straightforward, meaningful collective choices (Arrow [1951] 1963). -

For Your Ears Only Winter 2019 - 2020
For Your Ears Only Winter 2019 - 2020 Welcome to the latest edition of For Your Ears Only, packed with an abundance of titles to help you choose your next books, that will keep you company through the rest of the winter. As we enter into the new year you may want to discover some different authors, so how about trying the two new books by cosy crime author T P Fielden, or what about Elaine Roberts with her first family saga book called “The Foyles Bookshop Girls”. Then there is a book to take a chance on in the form of “Little” by Edward Carey, a fictional account of the life of Madame Tussaud, or embark on a quest to find out more about the universe in “The Planets” by Brian Cox and Andrew Cohen. You may order any of the books in this FYEO by using the enclosed order form. Alternatively you can email us at [email protected] or telephone Membership Services on 01296 432339. Please be aware that any books you ask for will be added on to the end of your request list, so if you have a long list it may be some time before you get them. If you would like to talk about your requests list, then please get in touch with Membership Services. Happy reading from the Editorial Team Emma Scott, Janet Connolly and Denise James Contents page 02 Recent Additions to the library - Fiction page 59 Recent additions to the library – Non-Fiction p1 RECENT ADDITIONS TO THE LIBRARY X - Denotes Sex, Violence or Strong Language Time - Approximate listening time All Books Available in the European Union and the UK All Books are available on MP3 CD, USB memory stick and can be streamed via Calibre’s website Fiction 20TH CENTURY CLASSICS 13424 EVA TROUT By Elizabeth Bowen Narrator Clare Francis Orphaned at a young age, Eva Trout has found a home of sorts with her former schoolteacher, Iseult Arbles. -

Political Knowledge and the Paradox of Voting
Political Knowledge and the Paradox of Voting Edited by Sofia Magdalena Olofsson We have long known that Americans pay local elections less attention than they do elections for the Presidency and Congress. A recent Portland State University study showed that voter turnout in ten of America’s 30 largest cities sits on average at less than 15% of eligible voters. Just pause and think about this. The 55% of voting age citizens who cast a ballot in last year’s presidential election – already a two-decade low and a significant drop from the longer-term average of 65-80% – still eclipses by far the voter turnout at recent mayoral elections in Dallas (6%), Fort Worth (6%), and Las Vegas (9%). What is more, data tells us that local voter turnout is only getting worse. Look at America’s largest city: New York. Since the 1953 New York election, when 93% of residents voted, the city’s mayoral contests saw a steady decline, with a mere 14% of the city’s residents voting in the last election. Though few might want to admit it, these trends suggest that an unspoken hierarchy exists when it comes to elections. Atop this electoral hierarchy are national elections, elections that are widely considered the most politically, economically, and culturally significant. Extensively covered by the media, they are viewed as high-stakes moral contests that naturally attract the greatest public interest. Next, come state elections: though still important compared to national elections, their political prominence, media coverage, and voter turnout is already waning. At the bottom of this electoral hierarchy are local elections that, as data tells us, a vast majority of Americans now choose not to vote in. -

Economic Growth, Capitalism and Unknown Economic Paradoxes
Sustainability 2012, 4, 2818-2837; doi:10.3390/su4112818 OPEN ACCESS sustainability ISSN 2071-1050 www.mdpi.com/journal/sustainability Article Economic Growth, Capitalism and Unknown Economic Paradoxes Stasys Girdzijauskas *, Dalia Streimikiene and Andzela Mialik Vilnius University, Kaunas Faculty of Humanities, Muitines g. 8, LT-44280, Kaunas, Lithuania; E-Mails: [email protected] (D.S.); [email protected] (A.M.) * Author to whom correspondence should be addressed; E-Mail: [email protected]; Tel.: +370-37-422-566; Fax: +370-37-423-222. Received: 28 August 2012; in revised form: 9 October 2012 / Accepted: 16 October 2012 / Published: 24 October 2012 Abstract: The paper deals with failures of capitalism or free market and presents the results of economic analysis by applying a logistic capital growth model. The application of a logistic growth model for analysis of economic bubbles reveals the fundamental causes of bubble formation—economic paradoxes related with phenomena of saturated markets: the paradox of growing returnability and the paradoxes of debt and leverage trap. These paradoxes occur exclusively in the saturated markets and cause the majority of economic problems of recent days including overproduction, economic bubbles and cyclic economic development. Unfortunately, these paradoxes have not been taken into account when dealing with the current failures of capitalism. The aim of the paper is to apply logistic capital growth models for the analysis of economic paradoxes having direct impact on the capitalism failures such as economic bubbles, economic crisis and unstable economic growth. The analysis of economic paradoxes and their implication son failures of capitalism provided in the paper presents the new approach in developing policies aimed at increasing economic growth stability and overcoming failures of capitalism. -

Alternative Voting in Alabama
1 Alternative Voting in Alabama Alternative voting ( also called ‘modified at-large voting’ ) was first used as an election procedure in Alabama during the 1980s. When the procedure was introduced, it was as novel and as questionable as the first Caesarians used to deliver babies. Today, after several election cycles, alternative voting systems in Alabama are as politically acceptable as C-sections are in delivery rooms. In Alabama today, thirty-two different governing bodies use some form of alternative voting. Three are county governments, one is a county Democratic Committee, and twenty-eight are municipalities. Of these governing bodies, twenty- three use limited voting, five use cumulative voting, and four replaced numbered posts with pure at-large [see glossary.] With the exception of the Conecuh County Democratic Executive Committee and the city of Fort Payne, all of the alternative voting systems in Alabama were first used in 1988 as a result of settlement agreements in the landmark, omnibus redistricting lawsuit, Dillard v. Crenshaw County, et. al. In that case, the Alabama Democratic Conference sued 180 jurisdictions in the state, challenging at-large elections. First Run: Conecuh County, Alabama The first known application of an alternative voting system in Alabama was in the election of members to the Conecuh County Democratic Executive Committee in the September 1982 primary election. It came as a result of a federal lawsuit filed by blacks challenging the discriminatory manner by which members were being elected to the committee. Prior to the court challenge, the Conecuh County Democratic Executive Committee elected members by a strange system which divided the county into two separate malapportioned districts, with each district electing 15 members at-large from numbered places [see glossary] and with a majority vote requirement.