Storage Efficiency Opportunities and Analysis for Video Repositories
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Aj-Px800g.Pdf
AJ-PX800G Memory Card Camera Recorder “P2 cam” AJ-PX800GH Bundled with AG-CVF15G Color LCD Viewfinder AJ-PX800GF Bundled with AG-CVF15G Color LCD Viewfinder and FUJINON 16x Auto Focus Lens *The microphone and battery pack shown in the photo are optional accessories. The Ultra Light Weight 3MOS Shoulder Camera Recorder The world's lightest*1 2/3 type shoulder-type HD camera-recorder with three image sensors revolutionizes news gathering with high mobility, superb picture quality and network functions. Ultra-high Speed, Ultra-high Quality and Ultra-light Weight The AJ-PX800G is a new-generation camera-recorder for news gathering. It is network connectable and provides superb picture quality, high mobility and excellent cost- performance. Weighing only about 2.8 kg (main unit), the AJ-PX800G is the world's lightest*1 shoulder-type camera-recorder equipped with three MOS image sensors for broadcasting applications. It also supports AVC-ULTRA multi-codec recording.*2 The picture quality and recorded data rate can be selected from one of the AVC-ULTRA family of codec’s (AVC-Intra/AVC-LongG) according to the application. Along with a Low-rate AVC-Proxy dual-codec recording ideal for network-based operation and off-line editing. Built-in network functions support wired LAN, wireless LAN**and 4G/LTE network connections,** enabling on-site preview, uploading data to a server and streaming. The AJ-PX800G is a single-package solution for virtually all broadcasting needs. ** For details, refer to “Notes Regarding Network Functions” on the back page. *1: For a 2/3-type shoulder-type HD camera-recorder with three sensors (as of June 2015). -

(A/V Codecs) REDCODE RAW (.R3D) ARRIRAW
What is a Codec? Codec is a portmanteau of either "Compressor-Decompressor" or "Coder-Decoder," which describes a device or program capable of performing transformations on a data stream or signal. Codecs encode a stream or signal for transmission, storage or encryption and decode it for viewing or editing. Codecs are often used in videoconferencing and streaming media solutions. A video codec converts analog video signals from a video camera into digital signals for transmission. It then converts the digital signals back to analog for display. An audio codec converts analog audio signals from a microphone into digital signals for transmission. It then converts the digital signals back to analog for playing. The raw encoded form of audio and video data is often called essence, to distinguish it from the metadata information that together make up the information content of the stream and any "wrapper" data that is then added to aid access to or improve the robustness of the stream. Most codecs are lossy, in order to get a reasonably small file size. There are lossless codecs as well, but for most purposes the almost imperceptible increase in quality is not worth the considerable increase in data size. The main exception is if the data will undergo more processing in the future, in which case the repeated lossy encoding would damage the eventual quality too much. Many multimedia data streams need to contain both audio and video data, and often some form of metadata that permits synchronization of the audio and video. Each of these three streams may be handled by different programs, processes, or hardware; but for the multimedia data stream to be useful in stored or transmitted form, they must be encapsulated together in a container format. -

DVW-2000 Series
Digital Betacam Recorder DVW-2000 Series DVW-M2000 DVW-M2000P DVW-2000 DVW-2000P DVW-M2000 DVW-2000 A New Plateau of Digital Betacam Studio Recorders - Delivering Proven Picture Quality and Reliability Together With Added Flexibility and Scalability Since the introduction of the Digital Betacam format in 1993, Digital Betacam products have been widely accepted by a number of customers such as video production houses and broadcasters around the world. Its outstanding picture quality, multi-generation capabilities, and proven reliability have made the Digital Betacam format a standard for high-end video production applications. One decade after its launch, Sony has further evolved its range of Digital Betacam products by enhancing their flexibility, scalability, and operability - the result is the new DVW-M2000 and DVW-2000 Studio Recorders. These recorders inherit all the advantages of previous models, DVW-A500, such as superb picture quality and outstanding video performance. What's more, the DVW-M2000 VTR also provides powerful playback capability for all Sony 1/2-inch standard-definition format tapes*, allowing for continuous use of important archive materials and acquisition tools. Furthermore, a plug-in HD upconversion option allows these VTRs to output HD signals of 1080/59.94i or 720/59.94P (DVW-M2000/2000), or 1080/50i (DVW-M2000P/2000P). This is possible not only from Digital Betacam playback, but also from the playback signals of other compatible formats** such as the BetacamTM and MPEG IMXTM formats, providing a very smooth migration to future HD operations. Further advancements such as metadata handling capability, flexible audio operation, and a compact body design are all incorporated in these VTRs to increase their operational convenience. -

ROCK Your Green Screen Video Production
15 Proven, Time-Tested & Unfailing Tips To Help You ROCK Your Green Screen Video Production First Hand Tips from a Broadcast Quality Production Studio Owner Servicing CNN, Fox News, CNBC, MSNBC & All Other Major News Networks! Lights, camera, sound and action! If only creating a brilliant green screen video was that simple! The fact of the matter is that there are literally hundreds of things that can go wrong during the production of a green screen video. With you usually having just one practical shot at shooting a fantastic video, it is imperative that you get it right and get it right the very first time. This guide will give you 15 FAILSAFE tips to create a stunning green screen video that will turn out exactly like you imagined it to be, if not more. But, before we delve into the 15 tips, let’s first help you understand the true power of a green screen video. Why a green screen video for your business, campaign, cause or advertisement? Simply put, a green screen allows you to extract a subject from a green background and then replace the background with images of your choice. In the technical video production world, this process is called “chroma keying”. Green is the preferred color of screen as it is the color that is furthest away from the color of any or all human skin tones, thereby making it great for accurate and precise extraction and also replacement. Advantages of a green screen video… • Spectacular flexibility to include any image or video as your video background • Exponentially speed up production time, thanks to elimination of travel to different shoot locations • Immensely improved logistics to finish a video shoot in one location, in one short duration • Tremendous cost savings 15 Tips to Rock a Green Screen Video Production #1 Lay Down Your Green Screen Video Plan Or Blueprint Call a meeting with everyone who will be involved with your green screen video. -
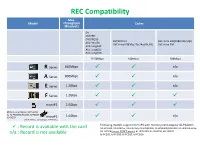
REC Compatibility Max
REC Compatibility Max. Model Throughput Codec (Readout) DV DVCPRO DVCPRO50 DVCPRO HD AVC-Intra 100(1080-60p,50p) AVC-Intra50 AVC-Intra100(30p,25p,24p,60i,50i) AVC-Intra 200 AVC-LongG12 AVC-LongG25 AVC-LongG50 25-50Mbps 100Mbps 200Mbps 640Mbps n/a R Series 800Mbps n/a A Series 1.2Gbps n/a E Series 1.2Gbps F Series microP2 2.0Gbps Memory card adaptor NOT usable for AJ-PX5000G/PX2300, AJ-PD500, microP2 1.0Gbps n/a AJ-PX270 (With memory card adaptor AJ-P2AD1G) Following models support microP2 with memory card adaptor AJ-P2AD1G. : Record is available with the card AG-HPX600, AG-HPX255, AG-HPX250, AJ-HPX3100G, AJ-HPX2000/HPX2100,AG-HPX370 series, AG-HPD24 (except 3D REC mode), AJ-HPD2500, AJ-HPM200, AG-HPG20 n/a : Record is not available AJ-PCD35, AJ-PCD30, AJ-PCD20, AJ-PCD2G PLUG INTO 1 P2HD Meets Emerging HD Needs for Tomorrow's Broadcasting and Video Production This new HD production system is based on a high-speed, large-capacity, solid-state memory device, the latest HD imaging technology, and advanced Panasonic engineering. Dubbed the P2HD Series, the new HD/SD multi-format production system records onto the P2 (Professional Plug-in) card. This solid-state memory device provides the P2HD Series with outstanding reliability, high transfer speeds, excellent rewritability, and extended recording times with the recording capacity of the new 16-GB or 32-GB P2 card. The P2HD Series is also the world's first* to support the latest HD codec, AVC-Intra. In addition to its DVCPRO HD mode, the use of this advanced new codec brings higher image quality and longer recording times to the P2HD Series, in a wide product line that meets the needs of broadcasting, moviemaking and professional video production. -

Video Production Handbook, Fourth Edition
Video Production Handbook Fourth Edition This page is intentionally left Blank Video Production Handbook Fourth Edition Gerald Millerson Jim Owens, Asbury College AMSTERDAM • BOSTON • HEIDELBERG • LONDON • NEW YORK • OXFORD PARIS • SAN DIEGO • SAN FRANCISCO • SINGAPORE • SYDNEY • TOKYO Focal Press is an imprint of Elsevier Focal Press is an imprint of Elsevier 30 Corporate Drive, Suite 400, Burlington, MA 01803, USA Linacre House, Jordan Hill, Oxford OX2 8DP, UK Copyright © 2008, Elsevier Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the publisher. Permissions may be sought directly from Elsevier’s Science & Technology Rights Department in Oxford, UK: phone: (+44) 1865 843830, fax: (+44) 1865 853333, E-mail: [email protected]. You may also complete your request on-line via the Elsevier homepage (http://elsevier.com), by selecting “Support & Contact” then “Copyright and Permission” and then “Obtaining Permissions.” Recognizing the importance of preserving what has been written, Elsevier prints its books on acid-free paper whenever possible. Library of Congress Cataloging-in-Publication Data Millerson, Gerald. Video production handbook / Gerald Millerson, Jim Owens. — 4th ed. p. cm. Includes index. ISBN 978-0-240-52080-3 (pbk. : alk. paper) 1. Video recording. 2. Video recordings—Production and direction. I. Owens, Jim, 1957- II. -

University of Texas at Arlington Dissertation Template
IMPLEMENTATION AND ANALYSIS OF DIRECTIONAL DISCRETE COSINE TRANSFORM IN H.264 FOR BASELINE PROFILE by SHREYANKA SUBBARAYAPPA Presented to the Faculty of the Graduate School of The University of Texas at Arlington in Partial Fulfillment of the Requirements for the Degree of MASTER OF SCIENCE IN ELECTRICAL ENGINEERING THE UNIVERSITY OF TEXAS AT ARLINGTON May 2012 Copyright © by Shreyanka Subbarayappa 2012 All Rights Reserved ACKNOWLEDGEMENTS Firstly, I would thank my advisor Prof. K. R. Rao for his valuable guidance and support, and his tireless guidance, dedication to his students and maintaining new trend in the research areas has inspired me a lot without which this thesis would not have been possible. I also like to thank the other members of my advisory committee Prof. W. Alan Davis and Prof. Kambiz Alavi for reviewing the thesis document and offering insightful comments. I appreciate all members of Multimedia Processing Lab, Tejas Sathe, Priyadarshini and Darshan Alagud for their support during my research work. I would also like to thank my friends Adarsh Keshavamurthy, Babu Hemanth Kumar, Raksha, Kirthi, Spoorthi, Premalatha, Sadaf, Tanaya, Karthik, Pooja, and my Intel manager Sumeet Kaur who kept me going through the trying times of my Masters. Finally, I am grateful to my family; my father Prof. H Subbarayappa, my mother Ms. Anasuya Subbarayappa, my sister Dr. Priyanka Subbarayappa, my brother-in-law Dr. Manju Jayram and my sweet little nephew Dishanth for their support, patience, and encouragement during my graduate journey. April 16, 2012 iii ABSTRACT IMPLEMENTATION AND ANALYSIS OF DIRECTIONAL DISCRETE COSINE TRANSFORM IN H.264 FOR BASELINE PROFILE Shreyanka Subbarayappa, M.S The University of Texas at Arlington, 2012 Supervising Professor: K.R.Rao H.264/AVC [1] is a video coding standard that has a wide range of applications ranging from high-end professional camera and editing systems to low-end mobile applications. -

Program of Study Video Production for Video, Broadcast and Digital Cinematography A.A
PROGRAM OF STUDY VIDEO PRODUCTION FOR VIDEO, BROADCAST AND DIGITAL CINEMATOGRAPHY A.A. Degree Laney College TOP Code: 0604.20 Program Control Number: 9024 Curriculum Committee Approval Date: 02/20/2015 The major in Video Production for Video, Broadcast and Digital Cinematography covers the entire range of digital video media production, from script development, hands-on professional 2K and 4K production equipment, current editing and other post-production applications, distribution, and media business management. Production of creative content for video, film, sports and broadcast TV, radio, cable, web, mobile technology, and other emerging communications utilizing video and audio. Career Opportunities in Video editor, camera operator, film/video producers, video effects artists, event videographer, sports videographer, audio/visual technician, live entertainment rentals and productions, corporate video/promotions, video for web sites, training video production, infomercial production, advertising video, web shopping videos, music videos Core Requirements Units MEDIA 104 Beginning Digital Video Production 3 and MEDIA 111 Basic Audio Production 3 and MEDIA 115 Media-based Computing: iLife and Mac OS X 3 and MEDIA 129 Portfolio Development 1 and MEDIA 460B AV Work Experience 1 Degree Major/Certificate Requirements: Units MEDIA 125 Scriptwriting for Video, Broadcast and Digital Cinematography 3 MEDIA 130 Final Cut Pro I: Nonlinear Editing for Video, Broadcast and Digital Cinematography 3 Select two courses from the following: Units MEDIA -

Filming & Video Production
Filming & Video Production Presentation by the 4-H Technology Leadership Team Download slides at http://ucanr.edu/film/ Agenda 1. Introductions & Overview 2. Pre-Production: Storyboarding and Scripting 3. Production: filming, camera equipment 4. Post-Production: Video editing Goal for the Workshop Learn the basics of filmmaking! We will have you work in groups on each step of the filmmaking process …. You may not finish your project (and that’s ok!). Introduction • Tell us about yourself • What do you know about filming and video production? • What would you like to know? (and not books, magazines, radio…?) Showcase Your Films The State 4-H Office showcases films at: California 4-H Revolution of Responsibility Website @ http://ca4hfoundation.org/ California 4-H YouTube Channel @ http://www.youtube.com/user/California4H California 4-H Facebook Fan Page @ https://www.facebook.com/california4H 4-H Revolution of Responsibility video from Cottonwood 4-H in Yolo County 2013 State 4-H Film Festival 4-H Revolution of Responsibility Share your story of leading positive change through multimedia. Don't forget to define the problem within the community, show how 4-H can be a part of the solution, and finally tell how the change is impacting your community! The Voices of 4-H History Project Capture the remembrances of 4-H alumni. The Steps to a Great Movie •Storyboard planning and scripting •Using your equipment •Camera techniques, composition, tri-pod, and microphone •Basic video production styles Video Creation Workflow STEP 1: Pre-Production 4-H Filmmaking Studio curriculum – “The Filmmaking Process” Example Storyboards Storyboarding Planning •Who? •What? •When? •Where? •Why? Camera Scripting •Not as detailed •Plan out scenes and props •Think about important angles and different camera techniques you might use Writing Your Script •Very detailed •Determines the structure of your video •Reveals restrictions and limitations •Leave time for memorization! What story will your group choose? 1.Commercial (30-seconds): Why join 4-H? 2.Interview (1-2 min): My favorite 4-H memory. -

Video Production 101: Delivering the Message
VIDEO PRODUCTION VIDEO PRODUCTION 101 101 Delivering the Message Antonio Manriquez & Thomas McCluskey VIDEO PRODUCTION 101 Delivering the Message Antonio Manriquez & Thomas McCluskey Video Production 101 Delivering the Message Antonio Manriquez and Thomas McCluskey Peachpit Press Find us on the Web at www.peachpit.com To report errors, please send a note to [email protected] Peachpit Press is a division of Pearson Education Copyright © 2015 by Antonio Jesus Manriquez and Thomas McCluskey Senior Editor: Karyn Johnson Development Editor: Stephen Nathans-Kelly Senior Production Editor: Tracey Croom Copyeditor and Proofreader: Kim Wimpsett Compositor: Danielle Foster Indexer: Jack Lewis Interior Design: Danielle Foster Cover Design: Aren Straiger Notice of Rights All rights reserved. No part of this book may be reproduced or transmitted in any form by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the publisher. For information on getting permission for reprints and excerpts, contact [email protected]. Notice of Liability The information in this book is distributed on an “As Is” basis without warranty. While every precaution has been taken in the preparation of the book, neither the authors nor Peachpit shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the instructions contained in this book or by the computer software and hardware products described in it. Trademarks Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Peachpit was aware of a trademark claim, the designations appear as requested by the owner of the trademark. -

Television Production
Job Ready Credential Blueprint 27-4031.00-Camera Operators, Television, Video, and Motion Picture Television Production Code: 3527 / Version: 01 Copyright © 2018. All Rights Reserved. Television Production General Assessment Information Blueprint Contents General Assessment Information Sample Written Items Written Assessment Information Performance Assessment Information Specic Competencies Covered in the Test Sample Performance Job Test Type: The Television Production industry-based credential is included in NOCTI’s Job Ready assessment battery. Job Ready assessments measure technical skills at the occupational level and include items which gauge factual and theoretical knowledge. Job Ready assessments typically oer both a written and performance component and can be used at the secondary and post-secondary levels. Job Ready assessments can be delivered in an online or paper/pencil format. Revision Team: The assessment content is based on input from secondary, post-secondary, and business/industry representatives from the states of Montana, New Jersey, New York, Oregon, Pennsylvania, and Utah. CIP Code 27-4031.00-Camera Operators, Career Cluster - Arts, AV Technology 27-4012.00– Television, Video, and and Communications Broadcast Technician Motion Picture In the lower division baccalaureate/associate degree category, 3 semester hours in Television Production or Communications. NOCTI Job Ready Assessment Page 2 of 11 Television Production Wrien Assessment NOCTI written assessments consist of questions to measure an individual’s factual -

A Digital Video Primer: an Introduction to DV Production, Post-Production, and Delivery
PRIMER A Digital Video Primer: An Introduction to DV Production, Post-Production, and Delivery TABLE OF CONTENTS Introduction 1 Introduction The world of digital video (DV) encompasses a large amount of technology. There are 1 Video basics entire industries focused on the nuances of professional video, including cameras, storage, 12 Digital video formats and camcorders and transmission. But you don’t need to feel intimidated. As DV technology has evolved, 16 Configuring your system it has become increasingly easier to produce high-quality work with a minimum of 19 The creative process: an overview underlying technical know-how. of movie-making This primer is for anyone getting started in DV production. The first part of the primer 21 Acquiring source material provides the basics of DV technology; and the second part, starting with the sec- 24 Nonlinear editing tion titled “The creative process,” shows you how DV technology and the applications 31 Correcting the color contained in Adobe® Production Studio, a member of the Adobe Creative Suite family, 33 Digital audio for video come together to help you produce great video. 36 Visual effects and motion graphics 42 Getting video out of your computer Video basics 44 Conclusion One of the first things you should understand when talking about video or audio is the 44 How to purchase Adobe software products difference between analog and digital. 44 For more information An analog signal is a continuously varying voltage that appears as a waveform when 50 Glossary plotted over time. Each vertical line in Figures 1a and 1b, for example, could represent 1/10,000 of a second.