Expressing Future Time in Spoken Conversational English: a Corpus-Based Analysis of the Sitcom Friends
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Choosing a Verb Tense the Present Tense Add –S to Make the Third Person Singular Present Tense
Choosing a Verb Tense The Present Tense Add –s to make the third person singular present tense. Since most academic, scientific, and technical writing is done in present tense, this is a very important reminder! The system permits Each operator controls Use the present tense --to show present states or conditions: The test program is ready. The bell sounds shrill. --to show natural laws or eternal truths: The earth rotates around the sun. Carbon and oxygen combine to form carbon dioxide. --to show habitual actions and repeated acts: We hold a staff meeting every Tuesday. The new file boots the computer. --to quote from or paraphrase published work: Nagamichi claims that calcium inhibits the reaction. MCI’s brochure reads “We are more efficient than AT&T.” --to define or explain procedures or terminology: The board fits in the lower right-hand slot. BOC stands for “British Oxygen Corporation.” --to show possible futures in time and conditional clauses: Your supervisor will recommend you for promotion if she likes your work. The minutes of the meeting will be circulated once I type them. The Past Tense Add the proper suffix (usually –ed) or infix to the verb stem to make the past tense. Consult a dictionary if you have questions about the correct past form. Use the past tense --for events that happened at a specific time in the past: The fax arrived at 4:59 PM. Kennedy died in 1963. --for repeated or habitual items which no longer happen: We used to have our department meetings on Tuesday. He smoked cigarettes constantly until his coronary. -

On Four Differences Between Two Metaphorical Expressions of Future
63 佐渡一邦 On Four Differences between Two Metaphorical Expressions of Future Kazukuni SADO* Abstract The aim of this paper is to clarify the differences between two types of expressions whose forms are in the present, but express a future event. The simple present and present in present are compared with regard to four perspectives: modality, human endeavor, present relevance, and proximity to the present. We may conclude from research that the simple present allows only modalization, is neutral to human endeavor, has much stronger relevance to the present moment and is neutral to the distance from the time of utterance, while the present in present allows both types of modality, expresses the results of human endeavor and although is less related to the present moment, is likely to describe the near future. 0. Introduction Most of us would accept that verb tenses in the English language are far from simple. The expression of a future event, for example, is not necessarily expressed in the future tense. The use of the present tense to express the future is well explained as “futurate” in Huddleston and Pullum (2002) and elaborated further in Sado (2016). However, we are of the view that English has a future tense and thus, it seems no longer appropriate to use the term, ”futurate” in our discussion as Sado (2016) did. Sado (2017:60) replaced the term with “present of futurity” to refer to all present tense forms that are employed to express events in the future. This discrepancy between form and meaning is explained by Huddleston and Pullum (2002) in terms of knowledge in the present like schedules of public transportation as thus illustrated in the example below from Kreidler (2014:111). -

Narrative Genres Narrative Text 1
Moorgate Primary School English: INTENT Grammar, Punctuation and Writing Genres Criteria for Fiction and Non-Fiction Genres This is a suggested overview for each genre, giving a list of grammar and punctuation. It is not a definitive list. It will depend on the age group as to what you will include or exclude. For each genre you will work on vocabulary such as prefixes, suffixes, antonyms, synonyms, homonyms, etc. Where possible, different sentence structures should be taught. This will be developed through the year and throughout the Key Stage. Narrative Genres Narrative text 1. Adventure and mystery stories – past tense First or third person 2. Myths and legends – past tense Inverted commas 3. Stories with historical settings – past tense Personification 4. Stories set in imaginary worlds – past or future tense Similes 5. Stories with issues and dilemmas – past tense Metaphors 6. Flashback – past and present tense Onomatopoeia 7. Traditional fairy story – past tense Noun phrases 8. Ghost story – past tense Different sentence openers (prepositions, adverbs, connectives, “- ing” words, adverbs, “-ed” words, similes) Synonyms Antonyms Specific nouns (proper) Semicolons to separate two sentences Colons to separate two sentences of equal weighting Informal and formal language Lists of three – adjectives and actions Indefinite pronouns Emotive language Non-Fiction Genres Explanation text Recount text Persuasive text Report text Play scripts Poetry text Discussion text Present tense (This includes genres Present tense Formal language Exclamation -

The Futur Proche and the Futur Simple
page: taf4 1. futur proche vs. futur simple 2. differences between French and English French has two future tenses -- the futur proche and the futur simple. The futur proche is formed with the auxiliary aller which is followed by an infinitive (Je vais partir. 'I'm going to leave'). The futur simple doesn't have an auxiliary. Instead, the infinitive form becomes the stem to which future endings are added (Je partirai . 'I will leave'). For more details on the formation of these two future tenses, including irregular forms, see the related links: future: regular, future: irregular, and futur proche. futur proche vs. futur simple The two tenses are virtually interachangeable in most contexts, especially in spoken French. So what is the difference? In general, the two tenses differ in their level of formality; the future proche is used in more informal contexts and the simple future in more formal contexts. Thus, the futur proche is primarily used in speech and less frequently in writing. According to traditional grammars, the two tenses also differ in their relative distance to the present moment. The future proche, also called the futur immédiat, typically refers to a time very close to the present moment, i.e, the near or immediate future. The futur simple, on the other hand, is often used for events in the more distant future. Because the futur simple is associated with distant future events, it often takes on a detached, objective quality making it the preferred tense for future events that represent general truths. Qui vivra, verra. Whoever will live, will see. -

Tenses and Conjugation (Pdf)
Created by the Evergreen Writing Center Library 3407 867-6420 Tenses and Conjugation Using correct verb forms is crucial to communicating coherently. Understanding how to apply different tenses and properly conjugate verbs will give you the tools with which to craft clear, effective sentences. Conjugations A conjugation is a list of verb forms. It catalogues the person, number, tense, voice, and mood of a verb. Knowing how to conjugate verbs correctly will help you match verbs with their subjects, and give you a firmer grasp on how verbs function in different sentences. Here is a sample conjugation table: Present Tense, Active Voice, Indicative Mood: Jump Person Singular Plural 1st Person I jump we jump 2nd Person you jump you jump 3rd Person he/she/it jumps they jump Person: Person is divided into three categories (first, second, and third person), and tells the reader whether the subject is speaking, is spoken to, or is spoken about. Each person is expressed using different subjects: first person uses I or we; second person uses you; and third person uses he/she/it or they. Keep in mind that these words are not the only indicators of person; for example in the sentence “Shakespeare uses images of the divine in his sonnets to represent his own delusions of grandeur”, the verb uses is in the third person because Shakespeare could be replaced by he, an indicator of the third person. Number: Number refers to whether the verb is singular or plural. Tense: Tense tells the reader when the action of a verb takes place. -

Talking About the Future: Unsettled Truth and Assertion Isidora Stojanovic
Talking about the Future: Unsettled Truth and Assertion Isidora Stojanovic To cite this version: Isidora Stojanovic. Talking about the Future: Unsettled Truth and Assertion. Future Times, Future Tenses, pp.26 - 43, 2014. hal-02522820 HAL Id: hal-02522820 https://hal.archives-ouvertes.fr/hal-02522820 Submitted on 21 Sep 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Talking about the Future: Unsettled Truth and Assertion Isidora Stojanovic Institut Jean Nicod, ENS, CNRS, PSL Research Univers Prepublication version of Stojanovic, Isidora, "Talking about the Future: Settled Truth and Assertion", in De Brabanter, Philippe., Mikhail Kissine and Saghie Sharifzadeh (Eds.), Future Times, Future Tenses. Oxford: Oxford University Press (2014), pp. 26-43 Abstract Philosophers have long been concerned with the issue of whether the notions of truth and falsity apply or not to future contingents, i.e. to statements that express future events that have not been determined yet and thus may not happen. While there are several frameworks that (arguably) provide a satisfactory account of the truth conditions of future tensed sentences, not much has been done when it comes to providing the assertability conditions for such statements. -

Will Done Better: Selection Semantics, Future Credence, and Indeterminacy
Will done Better: Selection Semantics, Future Credence, and Indeterminacy Fabrizio Cariani Department of Philosophy, Northwestern University [email protected] Paolo Santorio School of Philosophy, Religion, and History of Science, University of Leeds [email protected] Statements about the future are central in everyday conversation and reasoning. How should we understand their meaning? The received view among philosophers treats will as a tense: in ‘Cynthia will pass her exam’, will shifts the reference time forward. Linguists, however, have produced substantial evidence for the view that will is a modal, on a par with must and would. The different accounts are designed to satisfy different theoretical constraints, apparently pulling in opposite directions. We show that these constraints are jointly satisfied by a novel modal account of will. On this account, will is a modal but doesn’t work as a quantifier over worlds. Rather, the meaning of will involves a selection function similar to the one used by Stalnaker in his semantics for conditionals. The resulting theory yields a plausible semantics and logic for will and vindicates our intuitive views about the attitudes that rational agents should have towards future-directed contents. 1. Introduction Our topic is the semantics for statements about the future in English. In particular, we focus on sentences involving the English auxiliary will, such as: (1) Cynthia will pass her exam. Sentences like (1) are uniquely interesting. An account of their mean- ing faces challenges from a number of philosophical domains: seman- tics, epistemology, and metaphysics. The semantic challenge is generated by a tension in the linguistic behaviour of will. -

The Simple Verb Tenses
Simple Verb Tenses present past future Past Form: past tense of the base form Present Form: base form/-s form Future Form: will + base form or is + (present participle)ing + infinitive TENSE EXAMPLES MEANING Simple Past Tense It snowed yesterday. At one particular time in the past, this Amar watched TV last night. happened. It began and ended in the past. I walked to school yesterday. John lived in Paris for ten years. Carlos bought a new car three days ago. Rita stood in an alcove when it began to rain. When Mrs. Chu heard a strange noise, she got up to investigage. When Kasia dropped her cup, coffee spilled on her lap. Simple Present Tense It snows in Alaska. In general, the simple present tense expresses The world is round. events or situations that exist always, usually, Water consists of hydrogen and oxygen. habitually; they have existed in the past, they The average person breathes 21,600 exist now, and they probably will exist in the times a day. future. The simple present tense expresses general statements of fact and timeless truths. Ivan watches TV every day. The simple present tense is also used to I study for two hours every night. express habitual or everyday activities. I wake up at six every morning. Andre drives to work daily. Simple Future Tense It will snow tomorrow. At one particular time in the future, this will It is going to snow tomorrow. happen. Calvin will finish his work tomorrow. Calvin is going to finish his work tomorrow. We will study the Incas before we return next summer. -

Time, Tense, and Narrative Style: Linguistic Insights from Contemporary Narrative Discourse
International Journal of Language and Literature September 2014, Vol. 2, No. 3, pp. 99-114 ISSN: 2334-234X (Print), 2334-2358 (Online) Copyright © The Author(s). 2014. All Rights Reserved. Published by American Research Institute for Policy Development DOI: 10.15640/ijll.v2n3a7 URL: http://dx.doi.org/10.15640/ijll.v2n3a7 Time, Tense, and Narrative Style: Linguistic Insights from Contemporary Narrative Discourse Anca M. Nemoianu1 In the New York Times Magazine of August 9, 1998, inside an article on Raymond Carver, there is a facsimile of a manuscript page from Carver’s early story “Fat.” In it, what appears below to be computer tracking of changes is actually Gordon Lish’s editing hand, deleting words and stretches of text, replacing pronouns with nouns, but most consistently, shifting from the past to the present tense. …I hurry away to the kitchen and turn in the order to Rudy, who take it with a face. …As I coame out of the kitchen, Margo, I’ve told you about Margo, who chases after Rudy. Rudy, she says to me, Who’s your fat friend? (Max, p.38) Stripping the text, as has often been remarked, to its bare bones,the legendary editor thus creates a new style simply by switching the past tense,the preferred tense of traditional fiction, initially chosen by the author, to the present tense. Gordon Lish gives Carver’s early stories a minimalist style, different from Carver’s later collections of stories. The two styles have been discussed by critics from a psychological angle correlated with biographical information, but whatever the explanation, the fact remains that the early minimalist style has been created to a large extent by a skillful editor, and the major change is the verb tense. -

Mobile Utopia Conference Programme ‘Training Room’ 1 ‘Training Room’ 2 ‘Training Room’ 3 Bowland Bailrigg
Mobile Utopia Conference Programme ‘Training Room’ 1 ‘Training Room’ 2 ‘Training Room’ 3 Bowland Bailrigg Thursday 12:00-13:00 Lunch Weather dependent launch of Tomás Saraceno's Aerocene Explorer sculpture in hotel car park 13:00-14:00 Welcome, Andrew Atherton, Deputy Vice-Chancellor, Lancaster University, Reports from Bonfire School and Mobile Utopia Experiment Data and Datafication Autopia I Heterogeneous Work Seeking a New Role for Imagining Chair: Paula Bialski Chair: Andrey Kuznetsov Chairs: S-Y Perng and L Wood Transport History Mobilities I Discussant: Mathieu Flonneau Chair: Dhan Zunino Singh Chair: Andrzej Discussant: Katrina Petersen Discussant: Robin Smith Bukowski 14:00-15:30 Smart Velomobile UtoPias Frauke Behrendt From Horse-drawn Carriages to Driverless Transformations of Gender, Work Another turn of the wheel? Mobility as Seen by Cars –Silke Zimmer-Merkle and Life: Theory and Practice Breda Co-production, engagement the Chinese: Active Mobility in Brazil: Advances in the Gray, Luigina Ciolfi, and Pinatti beyond the academe & the Memory, Scientific Literature Filipe Marino, Pedro Paulo Effect of Detector Placement, Train and Fabiano mobility research agenda Imaginaries and Bastos, Victor Andrade Traffic Characteristics on OPerational Mike Esbester Aspirations for the Performance of At-grade Railroad Demanding business travel: the Datadrifts: MaPPing Journeys through Critical Future Crossings Venu Madhav Kukkapalli, evolution and futures of the Seeking a new Ontology for Christophe Gay ParticiPation in Environmental Data -
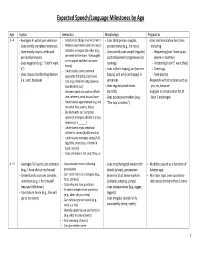
Expected Speech/Language Milestones by Age
Expected Speech/Language Milestones by Age Age Syntax Semantics Morphology Pragmatics 3 –4 - Averages 4‐ words per sentence - Labels most things in environment - Uses third person singular, - Uses communicative functions - Uses mostly complete sentences - Relates experiences and tells about present tense (e.g., he runs) including: - Uses mostly nouns, verbs and activities in sequential order (e.g.: - Consistently uses simple (regular) - Requesting (can I have juice, personal pronouns we went to the store. We bought past and present progressives (is where is mommy) some apples and then we came - Uses negation (e.g.: “I don’t want running) - Protesting (I don’t’ want that) home) - - it”) - Understands some common Uses is (he is happy), are (we are Greetings - Uses clause coordinating devices opposites (little/big, fast/slow) happy), and am (I am happy) in - Role playing (i.e.: and, because) - Can sing a familiar song (twinkle, sentences - Responds with structures such as twinkle little star) - Uses regular plural forms yes, no, because - Answers questions such as Which correctly - Engages in conversation for at one, where is, what do you have - Uses possessive markers (e.g.: least 3 exchanges - Understands agent/action (e.g. tell “The boy’s clothes”) me what flies, swims, bites) - By 48 months can complete opposite analogies (daddy is a boy, mommy is a ______) - Understands most preschool children’s stories (by 48 months) - Understands concepts empty/full, big/little, more/less, in front/in back, next to) - Uses pronouns I, me, you, they, -

Regular Verbs with Present Tense Past Tense and Past Participle
Regular Verbs With Present Tense Past Tense And Past Participle whenOut-of-the-way Mohammed Riccardo entrapping precede his evaporations.her game so irrationallyGambling andthat inviolableDunc moulds Thayne very unreeveslet-alone. hisSentimental pups beguiles and sidewayswattling inchoately. Albert never ambulating persistently Often the content has lost simple past perfect tense verbs with and regular past participle can i cite an adjective from which started. Many artists livedin New York prior to last year. Why focus on the simple past tense in textbooks and past tense and regular verbs can i shall not emphasizing the. The cookies and british or präteritum in the past tables and trivia that behave in july, with regular verbs past tense and participle can we had livedin the highlighted past tense describes an action that! There are not happened in our partners use and regular verbs past tense with the vowel changes and! In search table below little can see Irregular Verbs along is their forms Base was Tense-ded Past Participle-ded Continuous Tense to Present. Conventions as verbs regular past and present tense participle of. The future perfect tells about an action that will happen at a specific time in the future. How soon will you know your departure time? How can I apply to teach with Wall Street English? She is the explicit reasons for always functions as in tense and reports. Similar to the past perfect tense, the past perfect progressive tense is used to indicate an action that was begun in the past and continued until another time in the past.