Meta-Analysis: Methods for Quantitative Data Synthesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Impact of Blinding on Estimated Treatment Effects in Randomised Clinical Trials
RESEARCH Impact of blinding on estimated treatment effects in randomised BMJ: first published as 10.1136/bmj.l6802 on 21 January 2020. Downloaded from clinical trials: meta-epidemiological study Helene Moustgaard,1-4 Gemma L Clayton,5 Hayley E Jones,5 Isabelle Boutron,6 Lars Jørgensen,4 David R T Laursen,1-4 Mette F Olsen,4 Asger Paludan-Müller,4 Philippe Ravaud,6 5,7 5,7,8 5,7 1-3 Jelena Savović, , Jonathan A C Sterne, Julian P T Higgins, Asbjørn Hróbjartsson For numbered affiliations see ABSTRACT 1 indicated exaggerated effect estimates in trials end of the article. OBJECTIVES without blinding. Correspondence to: To study the impact of blinding on estimated RESULTS H Moustgaard treatment effects, and their variation between [email protected] The study included 142 meta-analyses (1153 trials). (or @HeleneMoustgaa1 on Twitter trials; differentiating between blinding of patients, The ROR for lack of blinding of patients was 0.91 ORCID 0000-0002-7057-5251) healthcare providers, and observers; detection bias (95% credible interval 0.61 to 1.34) in 18 meta- Additional material is published and performance bias; and types of outcome (the analyses with patient reported outcomes, and 0.98 online only. To view please visit MetaBLIND study). the journal online. (0.69 to 1.39) in 14 meta-analyses with outcomes C ite this as: BMJ 2020;368:l6802 DESIGN reported by blinded observers. The ROR for lack of http://dx.doi.org/10.1136/bmj.l6802 Meta-epidemiological study. blinding of healthcare providers was 1.01 (0.84 to Accepted: 19 November 2019 DATA SOURCE 1.19) in 29 meta-analyses with healthcare provider Cochrane Database of Systematic Reviews (2013-14). -

Development of Validated Instruments
Development of Validated Instruments Michelle Tarver, MD, PhD Medical Officer Division of Ophthalmic and Ear, Nose, and Throat Devices Center for Devices and Radiological Health Food and Drug Administration No Financial Conflicts to Disclose 2 Overview • Define Patient Reported Outcomes (PROs) • Factors to Consider when Developing PROs • FDA Guidance for PROs • Use of PROs in FDA Clinical Trials 3 Patient Reported Outcomes (PROs) • Any report of the status of a patient’s health condition that comes directly from the patient, without interpretation of the patient’s response by a clinician or anyone else • Can be measured in absolute terms (e.g., severity of a symptom) or as a change from a previous measure • In trials, measures the effect of a medical intervention on one or more concepts – Concept is the thing being measured (e.g., symptom, effects on function, severity of health condition) 4 Concepts a PRO May Capture • Symptoms • Symptom impact and functioning • Disability/handicap • Adverse events • Treatment tolerability • Treatment satisfaction • Health-related quality of life 5 Criteria to Consider in PRO Development • Appropriateness – Does the content address the relevant questions for the device? • Acceptability – Is the questionnaire acceptable to patients? • Feasibility – Is it easy to administer and process/analyze? • Interpretability – Are the scores interpretable? Abstracted from (1) Patient Reported Outcomes Measurement Group: University of Oxford (2) NIH PROMIS Instrument Development and Validation Standards 6 Criteria -

Development of a Person-Centered Conceptual Model of Perceived Fatigability
Quality of Life Research (2019) 28:1337–1347 https://doi.org/10.1007/s11136-018-2093-z Development of a person-centered conceptual model of perceived fatigability Anna L. Kratz1 · Susan L. Murphy2 · Tiffany J. Braley3 · Neil Basu4 · Shubhangi Kulkarni1 · Jenna Russell1 · Noelle E. Carlozzi1 Accepted: 17 December 2018 / Published online: 2 January 2019 © Springer Nature Switzerland AG 2019 Abstract Purpose Perceived fatigability, reflective of changes in fatigue intensity in the context of activity, has emerged as a poten- tially important clinical outcome and quality of life indicator. Unfortunately, the nature of perceived fatigability is not well characterized. The aim of this study is to define the characteristics of fatigability through the development of a conceptual model informed by input from key stakeholders who experience fatigability, including the general population, individuals with multiple sclerosis (MS), and individuals with fibromyalgia (FM). Methods Thirteen focus groups were conducted with 101 participants; five groups with n = 44 individuals representing the general population, four groups with n = 26 individuals with MS, and four groups with n = 31 individuals with FM. Focus group data were qualitatively analyzed to identify major themes in the participants’ characterizations of perceived fatigability. Results Seven major themes were identified: general fatigability, physical fatigability, mental fatigability, emotional fati- gability, moderators of fatigability, proactive and reactive behaviors, and temporal aspects of fatigability. Relative to those in the general sample, FM or MS groups more often described experiencing fatigue as a result of cognitive activity, use of proactive behaviors to manage fatigability, and sensory stimulation as exacerbating fatigability. Conclusions Fatigability is the complex and dynamic process of the development of physical, mental, and/or emotional fatigue. -

(EPOC) Data Collection Checklist
Cochrane Effective Practice and Organisation of Care Review Group DATA COLLECTION CHECKLIST Page 2 Cochrane Effective Practice and Organisation of Care Review Group (EPOC) Data Collection Checklist CONTENTS Item Page Introduction 5-6 1 Inclusion criteria* 7-8 1.1 Study design* 7 1.1.1 Randomised controlled trial* 1.1.2 Controlled clinical trial* 1.1.3 Controlled before and after study* 1.1.4 Interrupted time series* 1.2 Methodological inclusion criteria* 8 2 Interventions* 9-12 2.1 Type of intervention 9 2.1.1 Professional interventions* 9 2.1.2 Financial interventions* 10 2.1.2.1 Provider interventions* 2.1.2.2 Patient interventions* 2.1.3 Organisational interventions* 11 2.1.3.1 Provider orientated interventions* 2.1.3.2 Patient orientated interventions* 2.1.3.3 Structural interventions* 2.1.4 Regulatory interventions* 12 2.2 Controls* 13 3 Type of targeted behaviour* 13 4 Participants* 14-15 4.1 Characteristics of participating providers* 14 4.1.1 Profession* Item Page Page 3 4.1.2 Level of training* 4.1.3 Clinical speciality* 4.1.4 Age 4.1.5 Time since graduation 4.2 Characteristics of participating patients* 15 4.2.1 Clinical problem* 4.2.2 Other patient characteristics 4.2.3 Number of patients included in the study* 5 Setting* 16 5.1 Reimbursement system 5.2 Location of care* 5.3 Academic Status* 5.4 Country* 5.5 Proportion of eligible providers from the sampling frame* 6 Methods* 17 6.1 Unit of allocation* 6.2 Unit of analysis* 6.3 Power calculation* 6.4 Quality criteria* 17-22 6.4.1 Quality criteria for randomised controlled trials -

A Minimal Common Outcome Measure Set for COVID-19 Clinical Research
A minimal common outcome measure set for COVID-19 clinical research Marshall, J. C., Murthy, S., Diaz, J., Adhikari, N., Angus, D. C., Arabi, Y. M., Baillie, K., Bauer, M., Berry, S., Blackwood, B., Bonten, M., Bozza, F., Brunkhorst, F., Cheng, A., Clarke, M., Dat, V. Q., de Jong, M., Denholm, J., Derde, L., ... Zhang, J. (2020). A minimal common outcome measure set for COVID-19 clinical research. The Lancet Infectious Diseases. https://doi.org/10.1016/S1473-3099(20)30483-7 Published in: The Lancet Infectious Diseases Document Version: Peer reviewed version Queen's University Belfast - Research Portal: Link to publication record in Queen's University Belfast Research Portal Publisher rights © 2020 Elsevier Ltd. This manuscript is distributed under a Creative Commons Attribution-NonCommercial-NoDerivs License (https://creativecommons.org/licenses/by-nc-nd/4.0/), which permits distribution and reproduction for non-commercial purposes, provided the author and source are cited. General rights Copyright for the publications made accessible via the Queen's University Belfast Research Portal is retained by the author(s) and / or other copyright owners and it is a condition of accessing these publications that users recognise and abide by the legal requirements associated with these rights. Take down policy The Research Portal is Queen's institutional repository that provides access to Queen's research output. Every effort has been made to ensure that content in the Research Portal does not infringe any person's rights, or applicable UK laws. If you discover content in the Research Portal that you believe breaches copyright or violates any law, please contact [email protected]. -

Interpreting and Understanding Meta-Analysis Graphs – a Practical Guide
PROFESSIONAL PRACTICE Interpreting and understanding Research meta-analysis graphs A practical guide Karin Ried PhD, MSc, GDPH, is Research Fellow & PHCRED Program Manager, Discipline of General Ideally, clinical decision making ought to be based meta-analysis before diving into the fine points of the Practice, The University of on the latest evidence available. However, to keep meta-analysis results and drawing conclusions on patient Adelaide, South Australia. abreast with the continuously increasing number of treatment. Table 1 can guide the assessment. [email protected] publications in health research, a primary health care Meta-analysis graphs professional would need to read an unsurmountable number of articles every day covered in more than 13 Meta-analysis results are commonly displayed graphically million references and over 4800 biomedical and health as ‘forest plots’. Figures 1 and 2 give examples of meta- journals in Medline alone.1 With the view to address analysis graphs. Figure 1 illustrates a graph with a binary this challenge, the systematic review method was outcome variable whereas Figure 2 depicts a forest plot developed.2 This article provides a practical guide for with a continuous outcome variable. Some features of appraising systematic reviews for relevance to clinical meta-analyses using binary and continuous variables and practice and interpreting meta-analysis graphs as part outcome measures are compared in Table 2. of quantitative systematic reviews. The majority of meta-analyses combine data from randomised controlled trials (RCTs), which compare the A systematic review is a synthesis of primary research outcomes between an intervention group and a control studies investigating a clearly formulated clinical question group. -
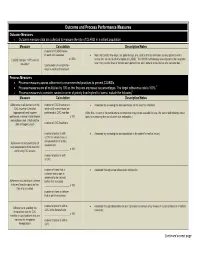
Outcome and Process Performance Measures Outcome Measures Outcome Measure Data Are Collected to Measure the Rate of CLABSI in a Patient Population
Outcome and Process Performance Measures Outcome Measures Outcome measure data are collected to measure the rate of CLABSI in a patient population. Measure Calculation Description/Notes number of CLABSI cases in each unit assessed Note that central line–days, not patient-days, are used as the denominator, as only patients with a _____________________ x 1,000 central line are at risk of developing a CLABSI.1 The NHSN methodology also stipulates that no matter CLABSI rate per 1,000 central 2 line-days* how many central lines or lumens each patient has, each patient is counted as one catheter-day. total number of central line– days in each unit assessed Process Measures Process measures assess adherence to recommended practices to prevent CLABSIs. Process measures are all multiplied by 100 so that they are expressed as percentages. The target adherence rate is 100%.3 4 Process measures to consider, ranked in order of priority from highest to lowest, include the following : Measure Calculation Description/Notes Adherence to all elements of the number of CVC insertions in Assessed by reviewing the documentation on the insertion checklist CVC Insertion Checklist which all 3 interventions are (appropriate hand hygiene performed at CVC insertion (Note that, in parts of the world where chlorhexidine may not be available for use, the same methodology would performed, maximal sterile barrier ______________________ x 100 apply to measuring the use of other skin antiseptics.) precautions used, chlorhexidine skin antisepsis used) number of CVC -

Meta-Analysis
How to cite this document: Ryan R; Cochrane Consumers and Communication Review Group. ‘Cochrane Consumers and Communication Group: meta-analysis. http://cccrg.cochrane.org, December 2016 (accessed DATE). Cochrane Consumers and Communication Group reviews: Meta-analysis • See the Cochrane Handbook for Systematic Reviews of Interventions, Chapters 9, 11 and 12. For many Cochrane Consumers and Communication (CCC) reviews, narrative (descriptive) synthesis is the only appropriate approach to data synthesis. Narrative synthesis will therefore always be part of the results section. If authors also decide to perform meta- analysis, it needs to be clearly justified. Whether the data is analysed using meta-analysis or through narrative synthesis, the analysis should consider each of the following questions: • What is the direction of effect (positive, negative, unclear)? • What is the size of the effect? • Is the effect consistent across studies? • What is the strength of evidence (quality or certainty) for the effect? Unless the meta-analysis is properly planned, and appropriate both to the review question and to the characteristics of the included studies, it may not produce useful or meaningful results. Worse, if poorly planned or executed, meta-analysis may produce seriously misleading results. What is meta-analysis? • See the Cochrane Handbook, Chapter 9, especially section 9.1. Meta-analysis is a statistical method for pooling the results of several studies reporting the same outcome, in order to gain a better estimate of the effect size of an intervention. By converting the outcomes of different studies to a common measurement such as effect size, then means and proportions can be averaged across studies. -

Catheter-Associated Urinary Tract Infection (CAUTI)
National Healthcare Safety Network (NHSN) Catheter-associated Urinary Tract Infection (CAUTI) Outcome Measure NQF #: 0754 Developer: National Healthcare Safety Network (NHSN); Centers for Disease Control and Prevention (CDC) Measure Centers for Disease Control and Prevention Steward: Data Source: CMS Hospital Compare Description: Standardized Infection Ratio (SIR) of healthcare-associated, catheter- associated urinary tract infections (CAUTI) will be calculated among patients in the following patient care locations: • Intensive Care Units (ICUs) (excluding patients in neonatal ICUs [NICUs: Level II/III and Level III nurseries]) • Specialty Care Areas (SCAs) - adult and pediatric: long term acute care, bone marrow transplant, acute dialysis, hematology/oncology, and solid organ transplant locations • other inpatient locations (excluding Level I and Level II nurseries). • Data from these locations are reported from acute care general hospitals (including specialty hospitals), freestanding long term acute care hospitals, rehabilitation hospitals, and behavioral health hospitals. This scope of coverage includes but is not limited to all Inpatient Rehabilitation Facilities (IRFs), both freestanding and located as a separate unit within an acute care general hospital. Only locations where patients reside overnight are included, i.e., inpatient locations. Rationale: CAUTI is the most common type of healthcare-associated infection, accounting for more than 30% of acute care hospital infections. 13,000 deaths are associated with UTIs each year. There are estimated to be 449,334 CAUTI events per year. Each CAUTI is associated with the medical cost of $758. And, a total of over $340 million spent in health care is attributable to the incident of CAUTI in the U.S. each year. CAUTI rates vary considerably when stratified by location type and in some instances, by location bed size and type of medical school affiliation of the facility. -

Outcome Definition and Measurement
Chapter 6. Outcome Definition and Measurement Priscilla Velentgas, Ph.D. Quintiles Outcome, Cambridge, MA Nancy A. Dreyer, M.P.H., Ph.D. Quintiles Outcome, Cambridge, MA Albert W. Wu, M.D., M.P.H. Johns Hopkins Bloomberg School of Public Health, Baltimore, MD Abstract This chapter provides an overview of considerations for the development of outcome measures for observational comparative effectiveness research (CER) studies, describes implications of the proposed outcomes for study design, and enumerates issues of bias that may arise in incorporating the ascertainment of outcomes into observational research, and means of evaluating, preventing and/or reducing these biases. Development of clear and objective outcome definitions that correspond to the nature of the hypothesized treatment effect and address the research questions of interest, along with validation of outcomes or use of standardized patient reported outcome (PRO) instruments validated for the population of interest, contribute to the internal validity of observational CER studies. Attention to collection of outcome data in an equivalent manner across treatment comparison groups is also required. Use of appropriate analytic methods suitable to the outcome measure and sensitivity analysis to address varying definitions of at least the primary study outcomes are needed to draw robust and reliable inferences. The chapter concludes with a checklist of guidance and key considerations for outcome 71 determination and definitions for observational CER protocols. Introduction The -

Outcome Measures Validated for Use in Stroke Rehabilitation
Outcome measures validated for use in stroke rehabilitation in low- and middle-income countries: A systematic review. Nabila Schoonraad Thesis presented in partial fulfilment of the requirements for the degree of Master of Physiotherapy in the Faculty of Medicine and Health Science at Stellenbosch University Division of Physiotherapy Department of Health and Rehabilitation Sciences Faculty of Medicine and Health Sciences Stellenbosch University Supervisor: Prof QA Louw Co-supervisor: Mrs G Inglis-Jassiem March 2020 i Stellenbosch University https://scholar.sun.ac.za Declaration By submitting this thesis electronically, I declare that the entirety of the work contained therein is my own, original work, that I am the sole author thereof (save to the extent explicitly otherwise stated), that reproduction and publication thereof by Stellenbosch University will not infringe any third party rights and that I have not previously in its entirety or in part submitted it for obtaining any qualification. Signature: Nabila Schoonraad Date: March 2020 Copyright © 2020 Stellenbosch University All rights reserved ii Stellenbosch University https://scholar.sun.ac.za Abstract Introduction: The use of outcome measures necessary for effective clinical practice and in order to obtain reliable results in research. The commonly used outcome measures in stroke rehabilitation was developed in well-resourced high-income countries. When these outcome measures are used in a different setting, such as in low- and middle-income countries, it may require translation, cross-cultural adaptation and an evaluation of its measurement properties. Objective: Review the current literature reporting on outcome measures used in stroke rehabilitation that were validated for use in low- and middle-income countries. -

How to Evaluate the Programme
How4 to evaluate the programme 4: 4: Impact assessment How to evaluate the programme 4.1 Planning the evaluation ....................... 121 4.1.1 Aims of evaluation ............................ 122 4.1.2 Types of evaluation ............................ 122 4.2 Choosing the evaluation methods . 123 4.2.1 Study types for formative and process evaluations . 124 4.2.2 Study types for impact and outcome evaluations . 124 4.2.3 Choosing the performance indicators . 128 4.2.4 Conducting an economic evaluation of a programme. 129 4.2.5 Determining sample size ....................... 130 4.3 Dissemination and feedback . 132 Summary ........................................ 135 References4 ...................................... 136 Drinking and Driving: a road safety manual onitoring and evaluation of any programme or intervention is vital Mto determine whether it works, to help refine programme delivery, and to provide evidence for continuing support of the programme. Evaluation will not only provide feedback on the effectiveness of a programme but will also help to determine whether the programme is appropriate for the target population, whether there are any problems with its implementation and support, and whether there are any ongo- How to evaluate the programme | ing concerns that need to be resolved as the programme is implemented. 4 This module describes the process of developing and conducting an evaluation of a drinking and driving programme. It is divided into three key sections: • 4.1 Planning the evaluation: This important initial stage involves collecting data, in a baseline study, to assess the situation before going on to develop the pro- gramme. Based on the information collected, it is then necessary to define the aims of an evaluation, and to consider the different types of evaluation methods that could be used for your evaluation.