Derandomizing Isolation Lemma for K3,3-Free and K5-Free Bipartite Graphs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nowhere-Zero Flows in Regular Matroids and Hadwiger's Conjecture
NOWHERE-ZERO FLOWS IN REGULAR MATROIDS AND HADWIGER'S CONJECTURE LUIS A. GODDYN AND WINFRIED HOCHSTATTLER¨ To the memory of Reinhard B¨orger Abstract. We present a tool that shows, that the existence of a k-nowhere-zero-flow is compatible with 1-,2- and 3-sums in regular matroids. As application we present a conjecture for regular matroids that is equivalent to Hadwiger's conjecture for graphs and Tuttes's 4- and 5-flow conjectures. Keywords: nowhere zero flow, regular matroid, chromatic number, flow number, total unimodularity 1. Introduction A (real) matrix is totally unimodular (TUM) if each subdeterminant belongs to f0; ±1g. Totally unimodular matrices enjoy several nice properties which give them a fundamental role in combinatorial optimization and matroid theory. In this note we prove that the TUM possesses an attractive property. Let S ⊆ R, and let A be a real matrix. A column vector f is a S-flow of A if Af = 0 and every entry of f is a member of ±S. For any additive abelian group Γ use the notation Γ∗ = Γ n f0g. For a TUM A and a column vector f with entries in Γ, the product Af is a well defined column vector with entries in Γ, by interpreting (−1)γ to be the additive inverse of γ. It is convenient to use the language of matroids. A regular oriented matroid M is an oriented matroid that is representable M = M[A] by a TUM matrix A. Here the elements E(M) of M label the columns of A. Each (signed) cocircuit D = (D+;D−) of M corresponds to a f0; ±1g-valued vector in the row space of A and having minimal support. -

Sphere-Cut Decompositions and Dominating Sets in Planar Graphs
Sphere-cut Decompositions and Dominating Sets in Planar Graphs Michalis Samaris R.N. 201314 Scientific committee: Dimitrios M. Thilikos, Professor, Dep. of Mathematics, National and Kapodistrian University of Athens. Supervisor: Stavros G. Kolliopoulos, Dimitrios M. Thilikos, Associate Professor, Professor, Dep. of Informatics and Dep. of Mathematics, National and Telecommunications, National and Kapodistrian University of Athens. Kapodistrian University of Athens. white Lefteris M. Kirousis, Professor, Dep. of Mathematics, National and Kapodistrian University of Athens. Aposunjèseic sfairik¸n tom¸n kai σύνοla kuriarqÐac se epÐpeda γραφήματa Miχάλης Σάμαρης A.M. 201314 Τριμελής Epiτροπή: Δημήτρioc M. Jhlυκός, Epiblèpwn: Kajhγητής, Tm. Majhmatik¸n, E.K.P.A. Δημήτρioc M. Jhlυκός, Staύρoc G. Kolliόποuloc, Kajhγητής tou Τμήμatoc Anaπληρωτής Kajhγητής, Tm. Plhroforiκής Majhmatik¸n tou PanepisthmÐou kai Thl/ni¸n, E.K.P.A. Ajhn¸n Leutèrhc M. Kuroύσης, white Kajhγητής, Tm. Majhmatik¸n, E.K.P.A. PerÐlhyh 'Ena σημαντικό apotèlesma sth JewrÐa Γραφημάτwn apoteleÐ h apόdeixh thc eikasÐac tou Wagner από touc Neil Robertson kai Paul D. Seymour. sth σειρά ergasi¸n ‘Ελλάσσοna Γραφήματα’ apo to 1983 e¸c to 2011. H eikasÐa αυτή lèei όti sthn κλάση twn γραφημάtwn den υπάρχει άπειρη antialusÐda ¸c proc th sqèsh twn ελλασόnwn γραφημάτwn. H JewrÐa pou αναπτύχθηκε gia thn απόδειξη αυτής thc eikasÐac eÐqe kai èqei ακόμα σημαντικό antÐktupo tόσο sthn δομική όσο kai sthn algoriθμική JewrÐa Γραφημάτwn, άλλα kai se άλλα pedÐa όπως h Παραμετρική Poλυπλοκόthta. Sta πλάιsia thc απόδειξης oi suggrafeÐc eiσήγαγαν kai nèec paramètrouc πλά- touc. Se autèc ήτan h κλαδοαποσύνθεση kai to κλαδοπλάτoc ενός γραφήματoc. H παράμετρος αυτή χρησιμοποιήθηκε idiaÐtera sto σχεδιασμό algorÐjmwn kai sthn χρήση thc τεχνικής ‘διαίρει kai basÐleue’. -

Planar Graphs and Wagner's And
PLANAR GRAPHS AND WAGNER'S AND KURATOWSKI'S THEOREMS SQUID TAMAR-MATTIS Abstract. This is an expository paper in which we rigorously prove Wagner's Theorem and Kuratowski's Theorem, both of which establish necessary and sufficient conditions for a graph to be planar. Contents 1. Introduction and Basic Definitions 1 2. Kuratowski's Theorem 3 3. Wagner's Theorem 12 Acknowledgments 13 References 13 1. Introduction and Basic Definitions The planarity of a graph|its ability to be embedded in a plane|is a deceptively meaningful property which, through various theorems, can tell us many other things about a graph. Among other properties, planar graphs were famously found to be 4-colorable. Of course, to use such theorems to determine whether a graph has these properties, we must first determine whether that graph is planar. Wagner's and Kuratowki's theorems show that there are simple and easily testable charac- terizations of planarity, but proving that they work is much less simple. Before we can do that, we must establish some definitions. Definition 1.1. An undirected graph is an ordered pair G = (V; E), where V is a set of vertices, and E is a set of edges, where each edge is a set of two vertices. We will mostly refer to these simply as graphs, as this paper does not deal with directed graphs. Definition 1.2. A graph H is a subgraph of G if H = (W; F ) for some W ⊆ V and F ⊆ E. Definition 1.3. Two vertices u; v 2 V are adjacent in G if fu; vg 2 E. -

Layered Separators in Minor-Closed Graph Classes with Applications
Layered Separators in Minor-Closed Graph Classes with Appli- cations Vida Dujmovi´c y Pat Morinz David R. Wood x Abstract. Graph separators are a ubiquitous tool in graph theory and computer science. However, in some applications, their usefulness is limited by the fact that the separator can be as large as Ω(pn) in graphs with n vertices. This is the case for planar graphs, and more generally, for proper minor-closed classes. We study a special type of graph separator, called a layered separator, which may have linear size in n, but has bounded size with respect to a different measure, called the width. We prove, for example, that planar graphs and graphs of bounded Euler genus admit layered separators of bounded width. More generally, we characterise the minor-closed classes that admit layered separators of bounded width as those that exclude a fixed apex graph as a minor. We use layered separators to prove (log n) bounds for a number of problems where (pn) O O was a long-standing previous best bound. This includes the nonrepetitive chromatic number and queue-number of graphs with bounded Euler genus. We extend these results with a (log n) bound on the nonrepetitive chromatic number of graphs excluding a fixed topological O minor, and a logO(1) n bound on the queue-number of graphs excluding a fixed minor. Only for planar graphs were logO(1) n bounds previously known. Our results imply that every n-vertex graph excluding a fixed minor has a 3-dimensional grid drawing with n logO(1) n volume, whereas the previous best bound was (n3=2). -

Graph Minors and Minimum Degree
Graph Minors and Minimum Degree Gaˇsper Fijavˇz Faculty of Computer and Information Science University of Ljubljana Ljubljana, Slovenia [email protected] David R. Wood Department of Mathematics and Statistics The University of Melbourne Melbourne, Australia [email protected] Submitted: Dec 7, 2008; Accepted: Oct 22, 2010; Published: Nov 5, 2010 Mathematics Subject Classifications: 05C83 graph minors Abstract Let Dk be the class of graphs for which every minor has minimum degree at most k. Then Dk is closed under taking minors. By the Robertson-Seymour graph minor theorem, Dk is characterised by a finite family of minor-minimal forbidden graphs, which we denote by Dbk. This paper discusses Dbk and related topics. We obtain four main results: 4 1. We prove that every (k + 1)-regular graph with less than 3 (k + 2) vertices is in Dbk, and this bound is best possible. 2. We characterise the graphs in Dbk+1 that can be obtained from a graph in Dbk by adding one new vertex. 3. For k 6 3 every graph in Dbk is (k + 1)-connected, but for large k, we exhibit graphs in Dbk with connectivity 1. In fact, we construct graphs in Dk with arbitrary block structure. 4. We characterise the complete multipartite graphs in Dbk, and prove analogous characterisations with minimum degree replaced by connectivity, treewidth, or pathwidth. 1D.W. is supported by a QEII Research Fellowship from the Australian Research Council. An extended abstract of this paper was published in: Proc. Topological & Geometric Graph Theory (TGGT ’08), Electronic Notes in Discrete Mathematics 31:79-83, 2008. -
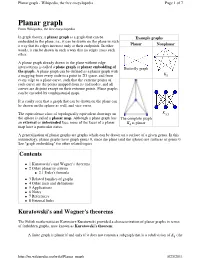
Planar Graph - Wikipedia, the Free Encyclopedia Page 1 of 7
Planar graph - Wikipedia, the free encyclopedia Page 1 of 7 Planar graph From Wikipedia, the free encyclopedia In graph theory, a planar graph is a graph that can be Example graphs embedded in the plane, i.e., it can be drawn on the plane in such a way that its edges intersect only at their endpoints. In other Planar Nonplanar words, it can be drawn in such a way that no edges cross each other. A planar graph already drawn in the plane without edge intersections is called a plane graph or planar embedding of Butterfly graph the graph . A plane graph can be defined as a planar graph with a mapping from every node to a point in 2D space, and from K5 every edge to a plane curve, such that the extreme points of each curve are the points mapped from its end nodes, and all curves are disjoint except on their extreme points. Plane graphs can be encoded by combinatorial maps. It is easily seen that a graph that can be drawn on the plane can be drawn on the sphere as well, and vice versa. The equivalence class of topologically equivalent drawings on K3,3 the sphere is called a planar map . Although a plane graph has The complete graph external unbounded an or face, none of the faces of a planar K4 is planar map have a particular status. A generalization of planar graphs are graphs which can be drawn on a surface of a given genus. In this terminology, planar graphs have graph genus 0, since the plane (and the sphere) are surfaces of genus 0. -

A Characterization of Almost All Minimal Not Nearly Planar Graphs Kwang Ju Choi Louisiana State University and Agricultural and Mechanical College, [email protected]
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2013 A characterization of almost all minimal not nearly planar graphs Kwang Ju Choi Louisiana State University and Agricultural and Mechanical College, [email protected] Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Applied Mathematics Commons Recommended Citation Choi, Kwang Ju, "A characterization of almost all minimal not nearly planar graphs" (2013). LSU Doctoral Dissertations. 2011. https://digitalcommons.lsu.edu/gradschool_dissertations/2011 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. A CHARACTERIZATION OF ALMOST ALL MINIMAL NOT NEARLY PLANAR GRAPHS A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Mathematics by Kwang Ju Choi B.S., Seoul National University, 2000 M.S., Seoul National University, 2006 M.S., Louisiana State University, 2008 August 2013 Acknowledgments This dissertation would not be possible without the assistance of my committee members, my family, and my friends. Foremost, I am grateful to my advisor, Dr. Bogdan Oporowski. He always encouraged me to move forward. I also owe my deepest gratitude to Dr. James Oxley. He advised me to continue working with patience and sharpness for my research. I am also grateful to Dr. Guoli Ding. -
![[Math.CO] 9 Jan 2006 U Oksoha[]Adtoao 1,16]](https://docslib.b-cdn.net/cover/3684/math-co-9-jan-2006-u-oksoha-adtoao-1-16-4663684.webp)
[Math.CO] 9 Jan 2006 U Oksoha[]Adtoao 1,16]
NOTE INDEPENDENT SETS IN GRAPHS WITH AN EXCLUDED CLIQUE MINOR DAVID R. WOOD Abstract. Let G be a graph with n vertices, with independence number α, and with with no Kt+1-minor for some t ≥ 5. It is proved that (2α − 1)(2t − 5) ≥ 2n − 5. 1. Introduction In 1943, Hadwiger [5] made the following conjecture, which is widely considered to be one of the most important open problems in graph theory1; see [17] for a survey. Hadwiger’s Conjecture. For every integer t ≥ 1, every graph with no Kt+1-minor is t-colourable. That is, χ(G) ≤ η(G) for every graph G. Hadwiger’s Conjecture is trivial for t ≤ 2, and is straightforward for t = 3; see [3, 5, 20]. In the cases t = 4 and t = 5, Wagner [18] and Robertson et al. [14] respectively proved that Hadwiger’s Conjecture is equivalent to the Four-Colour Theorem [1, 2, 13]. Hadwiger’s Conjecture is open for all t ≥ 6. Progress on the t = 6 case has been recently been obtained by Kawarabayashi and Toft [8] (without using the Four-Colour Theorem). The best known upper bound is χ(G) ≤ c · η(G)plog η(G) for some constant c, independently due to Kostochka [9] and Thomason [15, 16]. Since α(G) · χ(G) ≥ |G| for every graph G, Hadwiger’s Conjecture implies that (1) α(G) · η(G) ≥ |G|, as observed by Woodall [19]. In general, (1) is weaker than Hadwiger’s Conjecture, but if α(G) = 2, then Plummer et al. [11] proved that (1) is in fact equivalent to Hadwiger’s Conjecture. -

Independent Sets in Graphs with an Excluded Clique Minor David R
Independent sets in graphs with an excluded clique minor David R. Wood To cite this version: David R. Wood. Independent sets in graphs with an excluded clique minor. Discrete Mathematics and Theoretical Computer Science, DMTCS, 2007, 9 (1), pp.171–175. hal-00966507 HAL Id: hal-00966507 https://hal.inria.fr/hal-00966507 Submitted on 26 Mar 2014 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Discrete Mathematics and Theoretical Computer Science DMTCS vol. 9, 2007, 171–176 Independent Sets in Graphs with an Excluded Clique Minor David R. Wood† Departament de Matematica` Aplicada II Universitat Politecnica` de Catalunya Barcelona, Spain [email protected] received December 7, 2006, accepted August 22, 2007. Let G be a graph with n vertices, with independence number α, and with no Kt+1-minor for some t ≥ 5. It is proved α t n n 2 t2 that (2 − 1)(2 − 5) ≥ 2 − 5. This improves upon the previous best bound whenever ≥ 5 . Keywords: graph, minor, independent set, Hadwiger’s Conjecture. Mathematics Subject Classification: 05C15 (Coloring of graphs and hypergraphs) 1 Introduction In 1943, Hadwiger [7] made the following conjecture, which is widely considered to be one of the most important open problems in graph theory(i); see [19] for a survey. -

Disproof of the List Hadwiger Conjecture
Disproof of the List Hadwiger Conjecture J´anos Bar´at∗ Gwena¨el Joret† School of Mathematical Sciences D´epartement d’Informatique Monash University Universit´eLibre de Bruxelles VIC 3800, Australia Brussels, Belgium [email protected] [email protected] David R. Wood‡ Department of Mathematics and Statistics The University of Melbourne Melbourne, Australia [email protected] Submitted: Oct 11, 2011; Accepted: Dec 4, 2011; Published: Dec 12, 2011 Mathematics Subject Classifications: 05C83, 05C15 Abstract The List Hadwiger Conjecture asserts that every Kt-minor-free graph is t- choosable. We disprove this conjecture by constructing a K3t+2-minor-free graph that is not 4t-choosable for every integer t 1. ≥ 1 Introduction In 1943, Hadwiger [6] made the following conjecture, which is widely considered to be one of the most important open problems in graph theory; see [28] for a survey1. Hadwiger Conjecture. Every K -minor-free graph is (t 1)-colourable. t − The Hadwiger Conjecture holds for t 6 (see [3, 6, 19, 20, 30]) and is open for t 7. In fact, the following more general conjecture≤ is open. ≥ ∗Research supported by OTKA Grant PD 75837 and and K 76099. †Postdoctoral Researcher of the Fonds National de la Recherche Scientifique (F.R.S.–FNRS). Sup- ported in part by the Actions de Recherche Concert´ees (ARC) fund of the Communaut´efran¸caise de Belgique. Also supported by an Endeavour Fellowship from the Australian Government. ‡Supported by a QEII Fellowship from the Australian Research Council. 1See [2] for undefined graph-theoretic terminology. Let [a,b] := a,a +1,...,b . -

Reachability in K3,3-Free and K5-Free Graphs Is in Unambiguous Logspace ∗
CHICAGO JOURNAL OF THEORETICAL COMPUTER SCIENCE 2014, Article 2, pages 1–29 http://cjtcs.cs.uchicago.edu/ Reachability in K3;3-free and K5-free Graphs is in Unambiguous Logspace ∗ Thomas Thierauf Fabian Wagner Received May 30, 2012; Revised October 14, 2013, February 8, 2014, March 3, 2014, received in final form April 10, 2014; Published April 14, 2014 Abstract: We show that the reachability problem for directed graphs that are either K3;3-free or K5-free is in unambiguous log-space, UL \ coUL. This significantly extends the result of Bourke, Tewari, and Vinodchandran that the reachability problem for directed planar graphs is in UL \ coUL. Our algorithm decomposes the graphs into biconnected and triconnected components. This gives a tree structure on these components. The non-planar components are replaced by planar components that maintain the reachability properties. For K5-free graphs we also need a decomposition into 4-connected components. Thereby we provide a logspace reduction to the planar reachability problem. We show the same upper bound for computing distances in K3;3-free and K5-free directed graphs and for computing longest paths in K3;3-free and K5-free directed acyclic graphs. Key words and phrases: Reachability, logspace, planar graphs, K3;3-free graphs, K5-free graphs 1 Introduction In this paper we consider the reachability problem on graphs: Reachability Input: a graph G = (V;E) and two vertices s;t 2 V. Question: is there a path from s to t in G? ∗Supported by DFG grants TH 472/4-1 and TO 200/2-2. -
![Spring 2007 [Pdf]](https://docslib.b-cdn.net/cover/6836/spring-2007-pdf-6786836.webp)
Spring 2007 [Pdf]
Le Bulletin du CRM • www.crm.umontreal.ca • Printemps/Spring 2007 | Volume 13 – No 1 | Le Centre de recherches mathématiques Fall Thematic Program Semester: Applied Dynamical Systems by Tony Humphries (McGill University) The Fall Semester of 2007 at the CRM will be lytical and numerical challenges. Thus, the semester will focus devoted to Applied Dynamical Systems. The on two themes. Firstly, the use of dynamical systems in applica- semester will consist of 6 main workshops, with tions, principally in physiology, and secondly the development 5 taking place at the CRM, and a joint AARMS – of new numerical and dynamical systems tools needed in the CRM workshop in Halifax. Graduate student study of such problems. However, in reality applications, anal- and early career scientist participation is en- ysis and numerical methods are all interconnected and some couraged. Two of the Montréal workshops will aspects of all three will be found in each of the workshops. be preceded by graduate level minicourses, and there will also The semester will begin with a workshop on Advanced Al- be two semester long advanced graduate courses as part of the gorithms and Numerical Software for the Bifurcation Analysis of ISM applied mathematics programme. Dynamical Systems (2 – 7 July 2007) organised by E. Doedel Dynamical systems theory describes (Concordia) and H. Osinga (Bristol), qualitative and quantitative features with a preceding minicourse on 30 of solutions of systems of nonlinear June – 1 July 2007. This workshop differential equations, and has di- will address the numerical analysis verse roots in applications such as of discrete and continuous dynam- Poincaré’s work on planetary mo- ical systems that model important tion in the 19th century, the Fermi – physical phenomena.