Reinforcement Learning for Solving Yahtzee
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mutant Standard PUA Encoding Reference 0.3.1 (October 2018)
Mutant Standard PUA Encoding Reference 0.3.1 (October 2018) Mutant Standard’s PUA codepoints start at block 16 in Plane 10 Codepoint that Codepoint that New codepoint has existed has been given (SPUA-B) - U+1016xx, and will continue into the next blocks (1017xx, This document is licensed under a Creative Commons before this wording changes version this version 1018xx, etc.) if necessary. Attribution-ShareAlike 4.0 International License. Every Mutant Standard PUA encoding automatically assumes full- The data contained this document (ie. encodings, emoji descriptions) however, can be used in whatever way you colour emoji representations, so Visibility Selector 16 (U+FE0F) is like. not appropriate or necessary for any of these. Comments 0 1 2 3 4 5 6 7 8 9 A B C D E F Shared CMs 1 1016 0 Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier R1 (dark red) R2 (red) R3 (light red) D1 (dark red- D2 (red-orange) D3 (light red- O1 (dark O2 (orange) O3 (light Y1 (dark yellow) Y2 (yellow) Y3 (light L1 (dark lime) L2 (lime) L3 (light lime) G1 (dark green) orange) orange) orange) orange) yellow) Shared CMs 2 1016 1 Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier Color Modifier G2 (green) G3 (light green) T1 (dark teal) T2 (teal) -

Of Dice and Men the Role of Dice in Board and Table Games
Homo Ludens 1/(2) (2010) Homo Ludens Of Dice and Men The role of dice in board and table games Jens Jahnke, Britta Stöckmann Kiel, Germany Uniwersytet im. Adama Mickiewicza w Poznaniu When it comes to games, dice belong to the oldest playthings or gambling instruments men have used to pass their time and/or make some money, and it is striking that still today it is hard to imagine the realm of board and table games1 without them. Dominions fell, Caesars were overthrown, however, the die is still rolling – but is it also still ruling? Trying to answer this question, we approach the topic from two angles, analysing !rst the historical and then the current situation. In the !rst part the authors would like to give a quick retrospection into the history of the die to highlight a few outstanding facts about dice and gambling in their sociocultural context. "e second part then will discuss the cur- rent situation on the German board game market from a more technical and functional point of view: how dice are being integrated into board and table games, and how the out- come is being received. To narrow down the !eld we will concentrate on this speci!c range and leave out dice in casino games as well as in RPGs. "e focus on German board games is due to the fact that they constitute one of the biggest board game markets worldwide and therefore provides a lot of material for the analysis, which at the same time does not exclude games from other countries. -

Statistics and Probability Tetra Dice a Game Requires Each Player to Roll
High School – Statistics and Probability Tetra Dice A game requires each player to roll three specially shaped dice. Each die is a regular tetrahedron (four congruent, triangular faces). One face contains the number 1; one face contains the number 2; on another face appears the number 3; the remaining face shows the number 4. After a player rolls, the player records the numbers on the underneath sides of all three dice, and then calculates their sum. You win the game if the sum divides evenly by three. What is the probability of winning this game? Un juego exige que cada jugador lance tres dados con forma especial. Cada dado es un tetraedro regular (cuatro caras triangulares y congruentes). Una cara contiene el número 1; otra cara contiene el número 2; en otra cara aparece el número 3; la cara que sobra muestra el número 4. Después de que un jugador lanza los dados, el jugador registra los números de los lados cara abajo de los tres dados, y luego calcula su suma. Se gana el juego si la suma se divide exactamente por tres. ¿Cuál es la probabilidad de ganar este juego? В этой игре от каждого игрока требуется бросить три игральных кубика особенной формы. Каждый игральный кубик представляет собой правильный тетраэдр (четыре подобные треугольные грани). На однойграни стоит цифра 1; на одной грани стоит цифра 2; ещё на одной грани стоит цифра 3; на последней грани стоит цифра 4. После броска игрок записывает цифры, выпавшие на нижнейграни всех трёх кубиков, и затем вычисляет их сумму. Выигрывает тот игрок, чья сумма делится на три без остатка. -

Origins of Chess Protochess, 400 B.C
Origins of Chess Protochess, 400 B.C. to 400 A.D. by G. Ferlito and A. Sanvito FROM: The Pergamon Chess Monthly September 1990 Volume 55 No. 6 The game of chess, as we know it, emerged in the North West of ancient India around 600 A.D. (1) According to some scholars, the game of chess reached Persia at the time of King Khusrau Nushirwan (531/578 A.D.), though some others suggest a later date around the time of King Khusrau II Parwiz (590/628 A.D.) (2) Reading from the old texts written in Pahlavic, the game was originally known as "chatrang". With the invasion of Persia by the Arabs (634/651 A.D.), the game’s name became "shatranj" because the phonetic sounds of "ch" and "g" do not exist in Arabic language. The game spread towards the Mediterranean coast of Africa with the Islamic wave of military expansion and then crossed over to Europe. However, other alternative routes to some parts of Europe may have been used by other populations who were playing the game. At the moment, this "Indian, Persian, Islamic" theory on the origin of the game is accepted by the majority of scholars, though it is fair to mention here the work of J. Needham and others who suggested that the historical chess of seventh century India was descended from a divinatory game (or ritual) in China. (3) On chess theories, the most exhaustive account founded on deep learning and many years’ studies is the A History of Chess by the English scholar, H.J.R. -

Tetrahedron Probability Lab Name______
Tetrahedron Probability Lab Name______________________ Follow the directions carefully and answer all questions. 1. You have two regular tetrahedron templates. LABEL the faces of one of the tetrahedrons with the words YELLOW, RED, BLUE, and GREEN. 2. Fold the tetrahedron to form a four-sided die. Tape the sides. Note that there are tabs on the template to help with the taping. 3. Roll this “die” 20 times. Record how many time each color lands face down by placing a tally mark in the correct space in the table below. YELLOW RED BLUE GREEN 4. On the basis of your 20 rolls, does it appear that one color is more likely to land face down? ________ If so, what color?_______________ 5. Based upon your 20 rolls, express the probability (with a denominator of 20) that the GREEN face will land face down?___________ The RED face? __________ The YELLOW face?___________ The BLUE face?____________ What should be the sum of these four fractions?______________ 6. Roll your tetrahedron die another 20 times. Keep a record similar to the record from questions 3. Record your results below. YELLOW RED BLUE GREEN 7. Did you get approximately the same results?__________________________ All Rights Reserved © MathBits.com 8. Now, combine the results of all 40 rolls of the tetrahedron die. Using a fraction whose denominator is 40, write the probability of each color landing face down on any given roll of the die. GREEN_______ RED_______ YELLOW _______ BLUE _______ 9. Was your rolling of this die a good, fair sampling? _____ Why, or why not? 10. -

BAR DICE in the SAN FRANCISCO BAY AREA Alan Dundes Department of Anthropology University of California Berkeley, California and Carl R
BAR DICE IN THE SAN FRANCISCO BAY AREA Alan Dundes Department of Anthropology University of California Berkeley, California and Carl R. Pagter normal price of the drink; if the bartender loses, INTRODUCTION the customer gets a free drink.) Of the more than Games involving the use of dice are among the 20 bar dice games reported here, Boss Dice-with oldest forms of organized human play. Dice games nothing wild-is by far the most common game be- have been widely reported from many different tween customer and bartender. cultural areas. In the United States, dice games are Bars which permit dice games normally have commonly associated with gambling, and in Neva- multiple sets of dice cups and dice, which are pro- da, where there is legalized gambling, one may find vided to partrons upon request. It is not uncom- a variety of such traditional games as craps. Dice mon for such bars to be sought out by devotees are not associated solely with professional gamblers of bar dice games. Even if these bars are not con- inasmuch as they are employed as an integral part sciously sought out, they may well have achieved of numerous children's board games, e.g., Par- the popularity they possess in part because of the cheesi, Monopoly, etc. ambiance of dice play. On the other hand, the One of the most flourishing groups of dice noise of numerous dice cups being banged down on games in contemporary America consists of those the bar does prove annoying to some customers. commonly played at bars. -
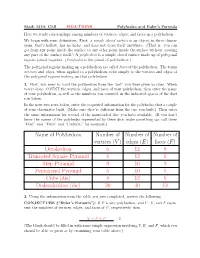
Edges (E) Faces (F) Octahedron 6 12 8 Truncated Square Pyramid 8
Math 1310: CLS SOLUTIONS Polyhedra and Euler's Formula Here we study relationships among numbers of vertices, edges, and faces in a polyhedron. We begin with some definitions. First: a simple closed surface is an object, in three dimen- sions, that's hollow, has no holes, and does not cross itself anywhere. (That is: you can get from any point inside the surface to any other point inside the surface without crossing any part of the surface itself.) A polyhedron is a simple closed surface made up of polygonal regions joined together. (Polyhedra is the plural of polyhedron.) The polygonal regions making up a polyhedron are called faces of the polyhedron. The terms vertices and edges, when applied to a polyhedron, refer simply to the vertices and edges of the polygonal regions making up that polyhedron. 1. First, you need to build the polyhedron from the \net" you were given in class. When you're done, COUNT the vertices, edges, and faces of your polyhedron; then enter the name of your polyhedron, as well as the numbers you counted, in the indicated spaces of the first row below. In the next two rows below, enter the requested information for the polyhedra that a couple of your classmates built. (Make sure they're different from the one you built.) Then enter the same information for several of the many-sided dice you have available. (If you don't know the names of the polyhedra represented by these dice, make something up: call them \Fred" and \Taku" and \Lucinda," for example.) Name of Polyhedron Number of Number of Number of vertices (V ) edges (E) faces (F ) Octahedron 6 12 8 Truncated Square Pyramid 8 12 6 Step Pyramid 9 16 9 Pentagonal Pyramid 6 10 6 Cube (die) 8 12 6 Dodecahedron (die) 20 30 12 2. -

AMT LC Magic Dice P.Indd
LESSON CARD Magic Dice An activity suitable for years 2–6 Learning areas: Number and place value, patterns and algebra, linear and non-linear relationships, data representation and interpretation (refer to the electronic version for links to Australian Curriculum content descriptors) Resources: Lots of regular six-sided dice (plus 8-, 10-, 12- or 20-sided dice for later challenges). Extra resources for this activity are available at http://www.amt.edu.au/mathspack, including nets to create your own dice from paper or card, plus a summary table to help with Challenge (b). In this activity you will learn a trick to amaze your family and friends! Take three dice and stack them on your desk as shown. If you look from different angles, the following numbers are visible: top layer: 1, 3, 5, 2 and 4 middle layer: 1, 4, 6 and 3 bottom layer: 2, 6, 5 and 1 So the hidden numbers are 6, 2, 5, 3 and 4. Adding these up, we see that the hidden front view back view total is 20. Tip: When adding up the hidden total, start from the top and work down: ‘6 plus 2 equals 8, plus 5 equals 13, plus 3 equals 16, plus 4 equals 20.’ Challenges (a) Create the three different stacks shown here. What is the hidden total for each one? SOLVE PROBLEMS. CREATE THE FUTURE. (b) Draw up a table to summarise your results so far, for example: top face visible side faces hidden faces hidden total 1 3,5,2,4 1,4,6,3 2,6,5,1 6,2,5,3,4 20 6 4,5,. -

Feelings Dice Game - 6 Sided
Feelings Dice Game - 6 Sided Number of players: minimum of two Directions : 1. Carefully cut out the dice along the lines. Make sure to keep the shaded tabs! 2. Fold and glue the tabs on the inside of the cube or tape along the lines. 3. Roll the dice. The group can share one die or each person can have their own, depending on how many dice you have made! Start from oldest to youngest. Read the feeling word that is on the top side of the die or describe the emotion on the face. 4. For each round, players can do one of the following: • Use your face to show what this feeling looks like on you. • What clues does your body give you that you might have this feeling? • What kinds of things happen to you that might cause you to feel this way? • What kinds of things happen to others that might cause them to feel this way? • Do a short skit that acts this feeling out. • Roll the die, don’t let anyone see which one lands on top! Now act out a short skit without words and have others guess what feeling it might be. • Tell about a time that you had this feeling and what caused it. • Tell about a time that you saw someone else have this feeling and what may have caused it. • Find the feeling on the die that you would have if... someone gave you a birthday present...a friend moved away...your brother rode your bike and broke it...you did really well on your swimming test.. -

Octahedral Dice
Butler University Digital Commons @ Butler University Scholarship and Professional Work - LAS College of Liberal Arts & Sciences 2008 Octahedral Dice Todd Estroff Jeremiah Farrell Butler University, [email protected] Follow this and additional works at: https://digitalcommons.butler.edu/facsch_papers Part of the Geometry and Topology Commons, Other Mathematics Commons, and the Probability Commons Recommended Citation Estroff, Todd and Farrell, Jeremiah, "Octahedral Dice" G4G8 Exchange Book / (2008): 56-57. Available at https://digitalcommons.butler.edu/facsch_papers/920 This Article is brought to you for free and open access by the College of Liberal Arts & Sciences at Digital Commons @ Butler University. It has been accepted for inclusion in Scholarship and Professional Work - LAS by an authorized administrator of Digital Commons @ Butler University. For more information, please contact [email protected]. Presented by Dr. Todd Estroff to honor Martin Gardner at G4G8 OCTAHEDRAL DICE By Todd Estroff and Jeremiah Farrell All five Platonic solids have been used as random numbei·"· generators in games involving chance with the cube being the most popular. Martin Gardner, in his article on dice (MG 1977) remarks: "Why cubical? ... It is the easiest to make, its six sides accommodate a set of numbers neither too large nor too small, and it rolls easily enough but not too easily." Gardner adds that the octahedron has been the next most popular as a randomizer. We offer here several problems and games using octahedral dice. The first two are extensions from Gardner's article. All answers will be given later. (1) How can two octahedrons be labeled, each side bearing a number 1 through 8 or left blank, to make a pair of dice that will throw with equal probability each sum from 1 tlu·ough 16? The next several problems make use of sets of standard octahedral dice, where each die has the numbers 1-8, 2-7, 3-6 and 4-5 on opposite faces. -

An Etruscan Dodecahedron
An Etruscan Dodecahedron Amelia Carolina Sparavigna Department of Applied Science and Technology Politecnico di Torino, C.so Duca degli Abruzzi 24, Torino, Italy The paper is proposing a short discussion on the ancient knowledge of Platonic solids, in particular, by Italic people. How old is the knowledge of Platonic solids? Were they already known to the ancients, before Plato? If we consider Wikipedia [1], the item on Platonic solids is telling that there are some objects, created by the late Neolithic people, which can be considered as evidence of knowledge of these solids. It seems therefore that it was known, may be a millennium before Plato, that there were exactly five and only five perfect bodies. These perfect bodies are the regular tetrahedron, cube, octahedron, dodecahedron and icosahedron. In his book on regular polytopes [2], Harold Scott Macdonald Coxeter, writes "The early history of these polyhedra is lost in the shadows of antiquity. To ask who first constructed them is almost as futile to ask who first used fire. The tetrahedron, cube and octahedron occur in nature as crystals. ... The two more complicated regular solids cannot form crystals, but need the spark of life for their natural occurrence. Haeckel (Ernst Haeckel's 1904, Kunstformen der Natur.) observed them as skeletons of microscopic sea animals called radiolaria, the most perfect examples being the Circogonia icosaedra and Circorrhegma dodecahedra. Turning now to mankind, excavations on Monte Loffa, near Padua, have revealed an Etruscan dodecahedron which shows that this figure was enjoyed as a toy at least 2500 years ago." Before Plato, Timaeus of Locri, a philosopher among the earliest Pythagoreans, invented a mystical correspondence between the four easily constructed solids (tetrahedron, icosahedron, octahedron and cube), and the four natural elements (fire, air, water and earth). -

Game Dice Polyhedrons 6-In-1
Activity Sheet for Game Dice Polyhedrons Game Dice Polyhedrons The typical set of multi-sided game dice includes six distinct geometric shapes. All but one of these shapes are considered regular Platonic solids (named after Plato, a philosopher from Ancient Greece). The Platonic solids include the four, six, eight, twelve, and twenty-sided dice. As you will read below, the 10-sided die is a special case. 4-Sided Die / Tetrahedron ! The Royal Game of Ur, Also known as a triangular pyramid. A regular dating from 2600 BCE, tetrahedron, such as our 4-sided die, is one in which all was played with a set of four faces are equilateral triangles. tetrahedral dice. Faces: 4 Vertices: 4 Edges: 6 6-Sided Die / Hexahedron ! The atoms that make up The cube is the only regular hexahedron and is also the table salt's atomic lattice are only convex polyhedron whose faces are all squares. arranged in a cubic shape, which results in the cubic shape of salt crystals. Faces: 6 Vertices: 8 Edges: 12 8-Sided Die / Octahedron ! Natural crystals of An octahedron is a polyhedron with eight triangular diamond, alum or fluorite are faces. A regular octahedron, such as our 8-sided die, is commonly octahedral. one in which all eight faces are equilateral triangles. Faces: 8 Vertices: 6 Edges: 12 10-Sided Die / Pentagonal Trapezohedron ! The pentagonal There are 32,300 topologically distinct decahedra and trapezohedron was none are regular, making decahedron an ambiguous patented for use as a term in geometry. The shape most often associated with gaming die in 1906.