Protocol Considerations for Web Linkbase Access
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
TMS Xdata Documentation
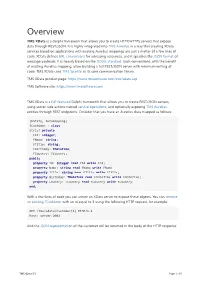
Overview TMS XData is a Delphi framework that allows you to create HTTP/HTTPS servers that expose data through REST/JSON. It is highly integrated into TMS Aurelius in a way that creating XData services based on applications with existing Aurelius mappings are just a matter of a few lines of code. XData defines URL conventions for adressing resources, and it specifies the JSON format of message payloads. It is heavily based on the OData standard. Such conventions, with the benefit of existing Aurelius mapping, allow building a full REST/JSON server with minimum writing of code. TMS XData uses TMS Sparkle as its core communication library. TMS XData product page: https://www.tmssoftware.com/site/xdata.asp TMS Software site: https://www.tmssoftware.com TMS XData is a full-featured Delphi framework that allows you to create REST/JSON servers, using server-side actions named service operations, and optionally exposing TMS Aurelius entities through REST endpoints. Consider that you have an Aurelius class mapped as follows: [Entity, Automapping] TCustomer = class strict private FId: integer; FName: string; FTitle: string; FBirthday: TDateTime; FCountry: TCountry; public property Id: Integer read FId write FId; property Name: string read FName write FName; property Title: string read FTitle write FTitle; property Birthday: TDateTime read FDateTime write FDateTime; property Country: TCountry read FCountry write FCountry; end; With a few lines of code you can create an XData server to expose these objects. You can retrieve an existing TCustomer -

Elastic Load Balancing Application Load Balancers Elastic Load Balancing Application Load Balancers
Elastic Load Balancing Application Load Balancers Elastic Load Balancing Application Load Balancers Elastic Load Balancing: Application Load Balancers Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Elastic Load Balancing Application Load Balancers Table of Contents What is an Application Load Balancer? .................................................................................................. 1 Application Load Balancer components ......................................................................................... 1 Application Load Balancer overview ............................................................................................. 2 Benefits of migrating from a Classic Load Balancer ........................................................................ 2 Related services ......................................................................................................................... 3 Pricing ...................................................................................................................................... 3 Getting started ................................................................................................................................. -

Elastic Load Balancing Application Load Balancers Elastic Load Balancing Application Load Balancers
Elastic Load Balancing Application Load Balancers Elastic Load Balancing Application Load Balancers Elastic Load Balancing: Application Load Balancers Elastic Load Balancing Application Load Balancers Table of Contents What is an Application Load Balancer? .................................................................................................. 1 Application Load Balancer components ......................................................................................... 1 Application Load Balancer overview ............................................................................................. 2 Benefits of migrating from a Classic Load Balancer ........................................................................ 2 Related services ......................................................................................................................... 3 Pricing ...................................................................................................................................... 3 Getting started .................................................................................................................................. 4 Before you begin ....................................................................................................................... 4 Step 1: Configure your target group ............................................................................................. 4 Step 2: Choose a load balancer type ........................................................................................... -

Web Services Security Using SOAP, \Rysdl and UDDI
Web Services Security Using SOAP, \rySDL and UDDI by Lin Yan A Thesis Submitted to the Faculty of Graduate Studies in Partial Fulfillment of the Requirements for the Degtee of MASTER OF SCIENCE Department of Electrical and Computer Engineering University of Manitoba Winnipeg, Manitoba, Canada @ Lin Yan, 2006 THE I]NTVERSITY OF MANITOBA FACULTY OF GRÄDUATE STUDIES COPYRIGHT PERMISSION Web Services Security Using SOAP, WSDL and IJDDI BY Lin Yan A Thesis/Practicum submitted to the Faculty ofGraduate Studies ofThe University of Manitoba in partial fulfillment of the requirement of the degree OF MASTER OF SCIENCE Lin Yan @ 2006 Permission has been granted to the Library ofthe University of Manitoba to lend or sell copies of this thesis/practicum' to the National Library of Canada to microfilm this thesis and to lend or sell copies of the film, and to University Microfitms Inc, to publish an abstract of this thesis/practicum, This reproduction or copy ofthis thesis has been made available by authority ofthe copyright orvner solely for the purpose of private study and research, and may only be reproduced and copied as permitted by copyright laws or with express rvritten authorization from the copyright owner. ABSTRACT The Internet is beginning to change the way businesses operate. Companies are using the Web for selling products, to find suppliers or trading partners, and to link existing applications to other applications. With the rise of today's e-business and e-commerce systems, web services are rapidly becoming the enabling technology to meet the need of commerce. However, they are not without problems. -

Requests Documentation Release 2.26.0
Requests Documentation Release 2.26.0 Kenneth Reitz Sep 21, 2021 Contents 1 Beloved Features 3 2 The User Guide 5 2.1 Installation of Requests.........................................5 2.2 Quickstart................................................6 2.3 Advanced Usage............................................. 15 2.4 Authentication.............................................. 30 3 The Community Guide 33 3.1 Recommended Packages and Extensions................................ 33 3.2 Frequently Asked Questions....................................... 34 3.3 Integrations................................................ 35 3.4 Articles & Talks............................................. 35 3.5 Support.................................................. 36 3.6 Vulnerability Disclosure......................................... 36 3.7 Release Process and Rules........................................ 38 3.8 Community Updates........................................... 38 3.9 Release History.............................................. 39 4 The API Documentation / Guide 71 4.1 Developer Interface........................................... 71 5 The Contributor Guide 93 5.1 Contributor’s Guide........................................... 93 5.2 Authors.................................................. 96 Python Module Index 103 Index 105 i ii Requests Documentation, Release 2.26.0 Release v2.26.0. (Installation) Requests is an elegant and simple HTTP library for Python, built for human beings. Behold, the power of Requests: >>>r= requests.get ('https://api.github.com/user', -

Pulse Secure Virtual Traffic Manager: Trafficscript Guide, V19.3
Pulse Secure Virtual Traffic Manager: TrafficScript Guide Supporting Pulse Secure Virtual Traffic Manager 19.3 Product Release 19.3 Published 15 October, 2019 Document Version 1.0 Pulse Secure Virtual Traffic Manager: TrafficScript Guide Pulse Secure, LLC 2700 Zanker Road, Suite 200 San Jose CA 95134 www.pulsesecure.net © 2019 by Pulse Secure, LLC. All rights reserved. Pulse Secure and the Pulse Secure logo are trademarks of Pulse Secure, LLC in the United States. All other trademarks, service marks, registered trademarks, or registered service marks are the property of their respective owners. Pulse Secure, LLC assumes no responsibility for any inaccuracies in this document. Pulse Secure, LLC reserves the right to change, modify, transfer, or otherwise revise this publication without notice. Pulse Secure Virtual Traffic Manager: TrafficScript Guide The information in this document is current as of the date on the title page. END USER LICENSE AGREEMENT The Pulse Secure product that is the subject of this technical documentation consists of (or is intended for use with) Pulse Secure software. Use of such software is subject to the terms and conditions of the End User License Agreement (“EULA”) posted at http://www.pulsesecure.net/support/eula/. By downloading, installing or using such software, you agree to the terms and conditions of that EULA. © 2019 Pulse Secure, LLC. Pulse Secure Virtual Traffic Manager: TrafficScript Guide Contents PREFACE . 1 DOCUMENT CONVENTIONS . 1 TEXT FORMATTING CONVENTIONS . 1 COMMAND SYNTAX CONVENTIONS . 1 NOTES AND WARNINGS. 2 REQUESTING TECHNICAL SUPPORT . 2 SELF-HELP ONLINE TOOLS AND RESOURCES. 2 OPENING A CASE WITH PSGSC . 3 INTRODUCTION. -

TR-069 CPE WAN Management Protocol V1.1
TECHNICAL REPORT TR-069 CPE WAN Management Protocol v1.1 Version: Issue 1 Amendment 2 Version Date: December 2007 © 2007 The Broadband Forum. All rights reserved. CPE WAN Management Protocol v1.1 TR-069 Issue 1 Amendment 2 Notice The Broadband Forum is a non-profit corporation organized to create guidelines for broadband network system development and deployment. This Technical Report has been approved by members of the Forum. This document is not binding on the Broadband Forum, any of its members, or any developer or service provider. This document is subject to change, but only with approval of members of the Forum. This document is provided "as is," with all faults. Any person holding a copyright in this document, or any portion thereof, disclaims to the fullest extent permitted by law any representation or warranty, express or implied, including, but not limited to, (a) any warranty of merchantability, fitness for a particular purpose, non-infringement, or title; (b) any warranty that the contents of the document are suitable for any purpose, even if that purpose is known to the copyright holder; (c) any warranty that the implementation of the contents of the documentation will not infringe any third party patents, copyrights, trademarks or other rights. This publication may incorporate intellectual property. The Broadband Forum encourages but does not require declaration of such intellectual property. For a list of declarations made by Broadband Forum member companies, please see www.broadband-forum.org. December 2007 © The Broadband -

Second Year Report
UNIVERSITY OF SOUTHAMPTON Web and Internet Science Research Group Electronics and Computer Science A mini-thesis submitted for transfer from MPhil toPhD Supervised by: Prof. Dame Wendy Hall Prof. Vladimiro Sassone Dr. Corina Cîrstea Examined by: Dr. Nicholas Gibbins Dr. Enrico Marchioni Co-Operating Systems by Henry J. Story 1st April 2019 UNIVERSITY OF SOUTHAMPTON ABSTRACT WEB AND INTERNET SCIENCE RESEARCH GROUP ELECTRONICS AND COMPUTER SCIENCE A mini-thesis submitted for transfer from MPhil toPhD by Henry J. Story The Internet and the World Wide Web are global engineering projects that emerged from questions around information, meaning and logic that grew out of telecommunication research. It borrowed answers provided by philosophy, mathematics, engineering, security, and other areas. As a global engineering project that needs to grow in a multi-polar world of competing and cooperating powers, such a system must be built to a number of geopolitical constraints, of which the most important is a peer-to-peer architecture, i.e. one which does not require a central power to function, and that allows open as well as secret communication. After elaborating a set of geopolitical constraints on any global information system, we show that these are more or less satisfied at the raw-information transmission side of the Internet, as well as the document Web, but fails at the Application web, which currently is fragmented in a growing number of large systems with panopticon like architectures. In order to overcome this fragmentation, it is argued that the web needs to move to generalise the concepts from HyperText applications known as browsers to every data consuming application. -

Web Tracking: Mechanisms, Implications, and Defenses Tomasz Bujlow, Member, IEEE, Valentín Carela-Español, Josep Solé-Pareta, and Pere Barlet-Ros
ARXIV.ORG DIGITAL LIBRARY 1 Web Tracking: Mechanisms, Implications, and Defenses Tomasz Bujlow, Member, IEEE, Valentín Carela-Español, Josep Solé-Pareta, and Pere Barlet-Ros Abstract—This articles surveys the existing literature on the of ads [1], [2], price discrimination [3], [4], assessing our methods currently used by web services to track the user online as health and mental condition [5], [6], or assessing financial well as their purposes, implications, and possible user’s defenses. credibility [7]–[9]. Apart from that, the data can be accessed A significant majority of reviewed articles and web resources are from years 2012 – 2014. Privacy seems to be the Achilles’ by government agencies and identity thieves. Some affiliate heel of today’s web. Web services make continuous efforts to programs (e.g., pay-per-sale [10]) require tracking to follow obtain as much information as they can about the things we the user from the website where the advertisement is placed search, the sites we visit, the people with who we contact, to the website where the actual purchase is made [11]. and the products we buy. Tracking is usually performed for Personal information in the web can be voluntarily given commercial purposes. We present 5 main groups of methods used for user tracking, which are based on sessions, client by the user (e.g., by filling web forms) or it can be collected storage, client cache, fingerprinting, or yet other approaches. indirectly without their knowledge through the analysis of the A special focus is placed on mechanisms that use web caches, IP headers, HTTP requests, queries in search engines, or even operational caches, and fingerprinting, as they are usually very by using JavaScript and Flash programs embedded in web rich in terms of using various creative methodologies. -

Mobile Three-Dimensional City Maps
TKK Dissertations in Media Technology Espoo 2009 TKK-ME-D-2 MOBILE THREE-DIMENSIONAL CITY MAPS Antti Nurminen AB TEKNILLINEN KORKEAKOULU TEKNISKA HÖGSKOLAN HELSINKI UNIVERSITY OF TECHNOLOGY TECHNISCHE UNIVERSITÄT HELSINKI UNIVERSITE DE TECHNOLOGIE D’HELSINKI TKK Dissertations in Media Technology Espoo 2009 TKK-ME-D-2 MOBILE THREE-DIMENSIONAL CITY MAPS Antti Nurminen Dissertation for the degree of Doctor of Science in Technology to be presented with due permission of the Department of Media Technology, for public ex- amination and debate in Lecture Hall E at Helsinki University of Technology (Espoo, Finland) on the 10th of December, 2009, at 12 noon. Helsinki University of Technology Faculty of Information and Natural Sciences Department of Media Technology Teknillinen korkeakoulu Informaatio- ja luonnontieteiden tiedekunta Mediatekniikan laitos Distribution: Helsinki University of Technology Faculty of Information and Natural Sciences Department of Media Technology P.O.Box 5400 FIN-02015 TKK Finland Tel. +358-9-451 2870 Fax. +358-9-451 5253 http://media.tkk.fi/ Available in PDF format at http://lib.tkk.fi/Diss/2009/9789522481931/ c Antti Nurminen ISBN 978-952-248-192-4 (print) ISBN 978-952-248-193-1 (online) ISSN 1797-7096 (print) ISSN 1797-710X (online) Redfina Espoo 2009 ABSTRACT Author Antti Nurminen Title Mobile Three-Dimensional City Maps Maps are visual representations of environments and the objects within, depicting their spatial relations. They are mainly used in navigation, where they act as external information sources, supporting observation and de- cision making processes. Map design, or the art-science of cartography, has led to simplification of the environment, where the naturally three- dimensional environment has been abstracted to a two-dimensional repre- sentation, populated with simple geometrical shapes and symbols. -

Version Indication & Negotiation
SIF Infrastructure Specification 3.3: Version Indication & Negotiation www.A4L.org Version 3.3, May 2019 SIF Infrastructure Specification 3.3: Version Indication & Negotiation Version 3.3, May 2019 Preface ...................................................................................................................................... 4 Disclaimer ................................................................................................................................. 4 Permission and Copyright ....................................................................................................... 5 Document Conventions ........................................................................................................... 5 Terms and Abbreviations .......................................................................................................... 5 Notations ..................................................................................................................................... 6 1. Context ............................................................................................................................... 7 2. Problem Statement ........................................................................................................... 8 3. Method ................................................................................................................................ 9 3.1 Schema Identification ....................................................................................................... -

HTTP Working Group M. Nottingham Internet-Draft Akamai Intended Status: Standards Track P
HTTP Working Group M. Nottingham Internet-Draft Akamai Intended status: Standards Track P. McManus Expires: September 9, 2016 Mozilla J. Reschke greenbytes March 8, 2016 HTTP Alternative Services draft-ietf-httpbis-alt-svc-14 Abstract This document specifies "Alternative Services" for HTTP, which allow an origin’s resources to be authoritatively available at a separate network location, possibly accessed with a different protocol configuration. Editorial Note (To be removed by RFC Editor) Discussion of this draft takes place on the HTTPBIS working group mailing list ([email protected]), which is archived at <https://lists.w3.org/Archives/Public/ietf-http-wg/>. Working Group information can be found at <http://httpwg.github.io/>; source code and issues list for this draft can be found at <https://github.com/httpwg/http-extensions>. The changes in this draft are summarized in Appendix A. Status of This Memo This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79. Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/. Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress." This Internet-Draft will expire on September 9, 2016. Nottingham, et al. Expires September 9, 2016 [Page 1] Internet-Draft HTTP Alternative Services March 2016 Copyright Notice Copyright (c) 2016 IETF Trust and the persons identified as the document authors.