Early Insights Into the Arabic Citation Index
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Downloaded Manually1
The Journal Coverage of Web of Science and Scopus: a Comparative Analysis Philippe Mongeon and Adèle Paul-Hus [email protected]; [email protected] Université de Montréal, École de bibliothéconomie et des sciences de l'information, C.P. 6128, Succ. Centre-Ville, H3C 3J7 Montréal, Qc, Canada Abstract Bibliometric methods are used in multiple fields for a variety of purposes, namely for research evaluation. Most bibliometric analyses have in common their data sources: Thomson Reuters’ Web of Science (WoS) and Elsevier’s Scopus. This research compares the journal coverage of both databases in terms of fields, countries and languages, using Ulrich’s extensive periodical directory as a base for comparison. Results indicate that the use of either WoS or Scopus for research evaluation may introduce biases that favor Natural Sciences and Engineering as well as Biomedical Research to the detriment of Social Sciences and Arts and Humanities. Similarly, English-language journals are overrepresented to the detriment of other languages. While both databases share these biases, their coverage differs substantially. As a consequence, the results of bibliometric analyses may vary depending on the database used. Keywords Bibliometrics, citations indexes, Scopus, Web of Science, research evaluation Introduction Bibliometric and scientometric methods have multiple and varied application realms, that goes from information science, sociology and history of science to research evaluation and scientific policy (Gingras, 2014). Large scale bibliometric research was made possible by the creation and development of the Science Citation Index (SCI) in 1963, which is now part of Web of Science (WoS) alongside two other indexes: the Social Science Citation Index (SSCI) and the Arts and Humanities Citation Index (A&HCI) (Wouters, 2006). -

Russian Index of Science Citation: Overview and Review
Russian Index of Science Citation: Overview and Review Olga Moskaleva,1 Vladimir Pislyakov,2 Ivan Sterligov,3 Mark Akoev,4 Svetlana Shabanova5 1 [email protected] Saint Petersburg State University, Saint Petersburg (Russia) 2 [email protected] National Research University Higher School of Economics, Moscow (Russia) 3 [email protected] National Research University Higher School of Economics, Moscow (Russia) 4 [email protected] Ural Federal University, Ekaterinburg (Russia) 5 [email protected] Scientific Electronic Library, Moscow (Russia) Abstract At the beginning of 2016 the new index was launched on the Web of Science platform — Russian Science Citation Index (RSCI). The database is free for all Web of Science subscribers except those from the former Soviet Union republics. This database includes publications from the 652 best Russian journals and is based on the data from Russian national citation index — Russian Index of Science Citation (RISC). Though RISC was launched in 2005 but there is not much information about it in English-language scholarly literature by now. The aim of this paper is to describe the history, actual structure and user possibilities of RISC. We also draw attention to the novel features of RISC which are crucial to bibliometrics and unavailable in international citation indices. Introduction. History and main objectives of RISC RISC was launched in 2005 as a government-funded project primarily aimed at creating a comprehensive bibliographic/citation database of Russian scholarly publishing for evaluation purposes based on Scientific Electronic Library (further eLIBRARY.RU) which started as a full- text database of scholarly literature for grantholders of Russian Foundation for Basic Research (RFBR). -

Rapid Changes of Serbian Scientific Journals and Their Quality, Visibility
Rapid Changes of Serbian Scientific Journals: Their Quality, Visibility and Role in Science Locally and Globally Aleksandra Popovic University of Belgrade, University Library “Svetozar Markovic”, Bulevar kralja Aleksandra 71, Belgrade, Serbia. [email protected] Sanja Antonic University of Belgrade, University Library “Svetozar Markovic”, Bulevar kralja Aleksandra 71, Belgrade, Serbia. [email protected] Stela Filipi Matutinovic University of Belgrade, University Library “Svetozar Markovic”, Bulevar kralja Aleksandra 71, Belgrade, Serbia. [email protected] Abstract: More than 400 scientific journals are published in Serbia, and 357 are referred to in the Serbian Citation Index - national citation index. The visibility of Serbian scientific journals in the citation database Web of Science has risen significantly in the last decade. Results of this analysis show the presence of Serbian journals in Web of Science, JCR, Scopus and Serbian Citation Index (SCIndeks) during four years (2007 to 2010). The paper discusses different bibliometric parameters in Web of Science, JCR and the Scopus portal SCImago (citations, average citations/year, impact factor, Hirsch index) for Serbian journals. Bibliometric indicators that appear in the National Citation Index are also analyzed. The number of Serbian journals with impact factor has increased during the observed period. The impact of Serbian publishers rose remarkably in 2010, and Serbia has two highly ranked journals. Keywords: Scientific journals, citation analysis, Web of Science, Scopus, national citation index, Serbia Introduction Journals are the main medium in scientific communication. Parameters that characterize those journals can be used for analyzing the scientific disciplines, both in separate regions and globally. It is also possible to follow the development of the scientific community itself, since the appearance of journals show that the scientific community in a particular country has reached the level at which communication through journals is needed. -

Serbian Citation Index
Serbian Citation Index: The sustainability of a business model based on partnership between a non-profit web publisher and journal owners Milica Ševkušić, Biljana Kosanović, Pero Šipka To cite this version: Milica Ševkušić, Biljana Kosanović, Pero Šipka. Serbian Citation Index: The sustainability of a business model based on partnership between a non-profit web publisher and journal owners. ELPUB 2020 24rd edition of the International Conference on Electronic Publishing, Apr 2020, Doha, Qatar. 10.4000/proceedings.elpub.2020.16. hal-02544845 HAL Id: hal-02544845 https://hal.archives-ouvertes.fr/hal-02544845 Submitted on 16 Apr 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Serbian Citation Index: The sustainability of a business model based on partn... 1 Serbian Citation Index: The sustainability of a business model based on partnership between a non-profit web publisher and journal owners Milica Ševkušić, Biljana Kosanović and Pero Šipka Introduction 1 The Open Access (OA) and Open Science (OS) movements have led to global changes in scholarly -

Strani Pravni Život Foreign Legal Life
INSTITUT ZA UPOREDNO PRAVO INSTITUTE OF COMPARATIVE LAW UDC 34 ISSN 0039 2138 ISSN (online) 2620 1127 STRANI PRAVNI ŽIVOT FOREIGN LEGAL LIFE Belgrade, 2020/ No 4/ Year LXIV Izdavač/Publisher INSTITUT ZA UPOREDNO PRAVO/ INSTITUTE OF COMPARATIVE LAW Beograd, Terazije 41 e-mail:[email protected], www.iup.rs tel. + 381 11 32 33 213 Redakcija/Editorial board prof. dr Miodrag Orlić prof. dr Dejan Đurđević prof. dr Olga Cvejić-Jančić prof. dr Dušan Vranjanac prof. dr Spiridon Vrelis (Grčka) prof. dr Branislava Knežić prof. dr Mikele Papa (Italija) doc. dr Branka Babović prof. dr Wolfgang Rohrbach (Austrija) doc. dr Slobodan Vukadinović prof. dr Vid Jakulin (Slovenija) prof. dr Nataša Mrvić Petrović dr Stefanos Kareklas (Grčka) prof. dr Vladimir Čolović prof. dr Alesandro Simoni (Italija) prof. dr Jelena Ćeranić Perišić dr Fabio Ratto Trabucco (Italija) dr Aleksandra Rabrenović prof. dr Đorđe Ignjatović doc. dr Katarina Jovičić dr Jovan Ćirić prof. dr Vladimir Đurić prof. dr Đorđe Đorđević dr Ana Knežević Bojović Ratomir Slijepčević dr Miloš Stanić prof. dr Goran Dajović Aleksandra Višekruna Glavni i odgovorni urednik/ Editor in chief prof. dr Nataša Mrvić Petrović Zamenik glavnog i odgovornog urednika/Deputy of editor in chief prof. dr Jelena Ćeranić Perišić Tehnički urednik/Technical editor Aleksandra Višekruna Sekretar redakcije/Secretary of Editorial board Jovana Misailović Štampa/Print JP Službeni glasnik Tiraž/Circulation 100 primeraka/100 copies Indexed in Serbian Citation Index (SCIndeks), Directory of Open Access Journals (DOAJ), Central and Eastern European Online Library (CEEOL) and European Reference Index for Humanities and Social Sciences (ERIHplus). Funding support for publication of this journal was provided by Ministry of education, science and technological development. -

Journal Publishing in Developing, Transition, and Emerging Countries
Journal Publishing in Developing, Transition and Emerging Countries Proceedings of the 5th Belgrade International Open Access Conference 2012 Belgrade, Serbia, May 18-19, 2012 Edited by Pero Šipka Journal Publishing in Developing, Transition, and Emerging Countries Proceedings of the 5th Belgrade International Open Access Conference 2012 Belgrade, Serbia May 18-19, 2012 Pero Šipka (ed.) Publisher Centre for Evaluation in Education and Science Kneza Miloša 17 11.000 Belgrade Serbia tel. +381 11 32 38 506 www.ceon.rs Copyright information © 2013 Centre for Evaluation in Education and Science ISBN 978-86-89475-01-2 ISSN (print): 2334-7880 ISSN (online): 2334-7880 Cover by PeteF Ordering information Print-on-demand by Amazon. Web access and citation information This entire proceedings can also be viewed on the web at http://boac.ceon.rs/public/full/5th-bioac.pdf. Each paper has a unique identifier (DOI) which can be added to citations to facilitate access. The DOI # should not replace the full citation. Each e-version contains instruction on how to cite a paper. doi:10.5937/BIOAC-111 Output in WoS vs. Representation in JCR of SEE Nations: Does Mother Thomson Cherish All Her Children Equally Biljana Kosanović1 and Pero Šipka2 1 [email protected] National Library of Serbia, Skerlićeva 1, 11000 Belgrade (Serbia) 2 [email protected] Centre for Evaluation in Education and Science, Kneza Miloša 17, 11000 Belgrade (Serbia) Abstract Within the 2005-2010 campaign aimed at extending the coverage of quality regional journals, Thomson Reuters started indexing a large number of journals published among else in SouthEast Europe (SEE). -

European Databases and Repositories for Social Sciences and Humanities Research Output
European databases and repositories for Social Sciences and Humanities research output Report July 2017 European Databases and Repositories for Social Sciences and Humanities Research Output Report July 2017 Authors: Linda Sīle*, Raf Guns*, Gunnar Sivertsen**, Tim Engels* *Centre for R&D Monitoring (ECOOM), Faculty of Social Sciences, University of Antwerp (Belgium) **Nordic Institute for Studies in Innovation, Research and Education (Norway) Cite as Sīle, L. et al. (2017). European Databases and Repositories for Social Sciences and Humanities Research Output. Antwerp: ECOOM & ENRESSH. DOI: 10.6084/m9.figshare.5172322 Except where otherwise noted, this work is licensed under a Creative Commons Attribution 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/ Executive summary This document provides an overview of European databases and repositories for research output within the social sciences and humanities (SSH). The focus is on national databases that are currently in use. This overview is a result of a survey conducted within the framework of European Network for Research Evaluation in the Social Sciences and Humanities (ENRESSH, www.enressh.eu). By means of the survey, we accomplish the milestone ‘presentation of existing databases’, which is linked to the ENRESSH work group 3 task 1: “Confront productivity and structure of outputs in various SSH disciplines, using data from existing national information systems or other databases and repositories” and task 3 “Develop common rules and procedures for building databases” (COST Association 2015, 10). The scope of the survey was 41 European countries with responses received from 39 countries. The data collection was carried out from August 2016 to March 2017. -
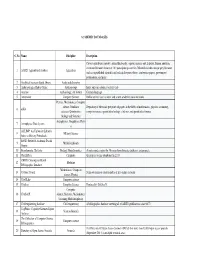
Academic Databases
ACADEMIC DATABASES S. No. Name Discipline Description Covers agriculture, forestry, animal husbandry, aquatic sciences and fisheries, human nutrition, extension literature from over 100 participating countries. Material includes unique grey literature 1 AGRIS: Agricultural database Agriculture such as unpublished scientific and technical reports, theses, conference papers, government publications, and more. 2 Analytical sciences digital library Analytical chemistry 3 Anthropological Index Online Anthropology Index only (no abstracts or full-text). 4 Arachne Archaeology, Art history German language 5 Arnetminer Computer Science Online service used to index and search academic social networks Physics, Mathematics, Computer science, Nonlinear Repository of electronic pre-prints of papers in the fields of mathematics, physics, astronomy, 6 arXiv sciences, Quantitative computer science, quantitative biology, statistics, and quantitative finance. biology and Statistics Astrophysics, Geophysics, Physi 7 Astrophysics Data System cs AULIMP: Air University Library's 8 Military Science Index to Military Periodicals BASE: Bielefeld Academic Search 9 Multidisciplinary Engine 10 Bioinformatic Harvester Biology, Bioinformatics A meta search engine for 50 major bioinformatic databases and projects. 11 ChemXSeer Chemistry the projects seems abandoned in 2018 CHBD: Circumpolar Health 12 Medicine Bibliographic Database Mathematics, Computer 13 Citebase Search Semi-autonomous citation index of free online research science, Physics 14 CiteULike Computer science -

Experience with Indian Citation Index ………………………
Knowledge Indexation and Research Productivity in India: Experience with Indian Citation Index ……………………… Prakash Chand 1 Prakash Chand1 ABSTRACT This paper discusses knowledge, research productivity, construction of citation database and their significance for research and academic activities. It also points out the limitations of databases which are causing the development of national citation databases in many countries like China, Korea, Japan, India, etc. which have already brought their own citation Indexes. All these are becoming inevitable and important, as global society is passing on tight rope of the competition to decide scholarly superiority among knowledge stake holders. The paper discusses various steps required for constructing citation database depicting complete process flow followed in Indian Citation Index. It discusses research productivity in terms of quantitative and qualitative output of African countries published in journals of Indian origin and indexed in Indian Citation Index. The paper analyzes and reveals that 44 African countries have significant academic collaboration with Indian counterparts and journals. It also reveals that 09 African countries do not publish any article (paper) in journals of Indian origin and thus have no academic collaboration. The Indian Citation Index organizes the universe of knowledge spectrum into 51 main (primary) subject categories which are further divided into their ~1000 macro level sub subject categories. The paper also finds that currently Indian Citation Index indexes 290 Open Access (OA) Journals published from India which covers 39 primary subject categories. 1.0 INTRODUCTION Research and innovation are the results of knowledge continuum of human endeavors from the beginning of human civilization. The basic aim of research is to discover and develop methods and systems for advancement of human knowledge. -

Downloaded Manually1
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Université de Montréal The Journal Coverage of Web of Science and Scopus: a Comparative Analysis Philippe Mongeon and Adèle Paul-Hus [email protected]; [email protected] Université de Montréal, École de bibliothéconomie et des sciences de l'information, C.P. 6128, Succ. Centre-Ville, H3C 3J7 Montréal, Qc, Canada Abstract Bibliometric methods are used in multiple fields for a variety of purposes, namely for research evaluation. Most bibliometric analyses have in common their data sources: Thomson Reuters’ Web of Science (WoS) and Elsevier’s Scopus. This research compares the journal coverage of both databases in terms of fields, countries and languages, using Ulrich’s extensive periodical directory as a base for comparison. Results indicate that the use of either WoS or Scopus for research evaluation may introduce biases that favor Natural Sciences and Engineering as well as Biomedical Research to the detriment of Social Sciences and Arts and Humanities. Similarly, English-language journals are overrepresented to the detriment of other languages. While both databases share these biases, their coverage differs substantially. As a consequence, the results of bibliometric analyses may vary depending on the database used. Keywords Bibliometrics, citations indexes, Scopus, Web of Science, research evaluation Introduction Bibliometric and scientometric methods have multiple and varied application realms, that goes from information science, sociology and history of science to research evaluation and scientific policy (Gingras, 2014). Large scale bibliometric research was made possible by the creation and development of the Science Citation Index (SCI) in 1963, which is now part of Web of Science (WoS) alongside two other indexes: the Social Science Citation Index (SSCI) and the Arts and Humanities Citation Index (A&HCI) (Wouters, 2006). -

Svetozar Markovic” in Belgrade
Evaluation of Scientific Work through Education in University Library “Svetozar Markovic” in Belgrade Aleksandra Popovic University Library “Svetozar Markovic”, Belgrade, Serbia [email protected] Dr. Stela Filipi-Matutinovic University Library “Svetozar Markovic”, Belgrade, Serbia [email protected] INFORUM 2009: 15th Conference on Professional Information Resources Prague, May 27-29, 2009 Abstract Scientific work in Serbia is valued through citation and point rating published results published in scientific journals, symposiums, monographs, etc. That is why University Library decided to conduct courses about evaluation to educate high school librarians, researches and postgraduate students. In 2005 we have conducted 7 courses, entitled Citation in SCI data bases, with over 120 participants. Last year we conducted 14 courses and workshops with near 500 attendants. Subjects were Citation data bases (SCI, SCOPUS, Serbian Citation index) and Google Scholar and Evaluation of scientific work. The most successful courses were lectures for the postgraduate students from different faculties. All target groups were interested in ranked lists of journals by IF in subject categories in Social and Science Journal Citation Report (JCR). The most interested groups of attendants were postgraduate students, whose evaluation of our courses was very high. Our Consortium KoBSON (Consortium of Serbian Libraries for Coordinated Acquisition) has brought out all relevant facts about journals IF and subject categories in JCR on its web portal. Numerous attendants had become aware of that information for the first time on our lectures. The second frequently questions were about hetero-citations, co-citations and self-citations. The courses will be continued. Key words: education, evaluation, scientific work, University Library, postgraduate students, citation data bases, JCR . -

Ournal Market and Position of Serbian Researchers in the Field of Economics
ORIGINAL SCIENTIFIC PAPER UDK: 001.3:[050.486:33(497.11) DOI:10.5937/EKOPRE1704321L Date of Receipt: Octobar 20, 2016 1HPDQMD/RMDQLFD (9$/8$7,212)7+(6&,(17,),&-2851$/ University of Kragujevac Faculty of Economics Department of General Economics and MARKET AND POSITION OF SERBIAN Economic Development RESEARCHERS IN THE FIELD OF ECONOMICS 2FHQDWUæLäWDQDXĉQLKĉDVRSLVDLSR]LFLMHVUSVNLK LVWUDæLYDĉDXREODVWLHNRQRPLMH $EVWUDFW 6DæHWDN 3XEOLFDWLRQVLQUHSXWDEOHMRXUQDOVDUHDFUXFLDOFRQGLWLRQIRUVXFFHVVIXO =DXVSHäQRQDXĉQRSURÀOLVDQMHLRVWYDULYDQMH]DYLGQLKDNDGHPVNLK VFLHQWLÀFSURÀOLQJDQGDFFRPSOLVKPHQWRIVLJQLÀFDQWDFDGHPLFUHVXOWV UH]XOWDWDSXEOLNDFLMHXUHQRPLUDQLPĉDVRSLVLPDSUHGVWDYOMDMXYHRPD 7KHSULPDU\JRDORIWKLVSDSHULVWRFRQGXFWDQDQDO\VLVRIWKHPDUNHW YDæDQXVORY2VQRYQLFLOMRYRJUDGDMHGDL]YUäLDQDOL]XWUæLäWDĉDVRSLVD RIHFRQRPLFMRXUQDOVWKDWEHORQJWR0FDWHJRU\DQGWKXVKDYH XREODVWLHNRQRPVNHQDXNHNRMLVXUHIHULVDQLXRGJRYDUDMXăRM0 FRUUHVSRQGLQJLPSDFWIDFWRUV7KHDLPLVWRHPSKDVL]HWKHSRVLWLRQRI NDWHJRULMLVDSULSDGDMXăLPLPSDNWIDNWRURP&LOMUDGDMHLGDXNDæHQD 6HUELDQUHVHDUFKHUVLQWKLVVSHFLÀFPDUNHW7KHHPSLULFDOUHVXOWVKDYH VYHXNXSQXSR]LFLMXVUSVNLKLVWUDæLYDĉDQDRYRPVSHFLÀĉQRPWUæLäWX UHYHDOHGWKDWMRXUQDOVIURPWKHPRVWGHYHORSHGFRXQWULHVKDYHDGRPLQDQW (PSLULMVNLUH]XOWDWLVXSRND]DOLGDĉDVRSLVLL]QDMUD]YLMHQLMLK]HPDOMD UROHRQWKHPDUNHWDQGWKDW6HUELDQUHVHDUFKHUVSXEOLVKWKHUHVXOWVRI LPDMXGRPLQDQWQXXORJXQDWUæLäWXLGDVUSVNLLVWUDæLYDĉLUH]XOWDWHVYRMLK WKHLUVWXGLHVSULPDULO\LQQHLJKERULQJFRXQWULHV5HFRPPHQGDWLRQVDUH VWXGLMDSUHYDVKRGQRSXEOLNXMXXĉDVRSLVLPDL]RNROQLK]HPDOMD3UHSRUXNH WREULQJHPLQHQWMRXUQDOVLQWRIRFXVRI6HUELDQUHVHDUFKHUVEXWDOVRWR