Paws.Machine.Learning: 'Amazon Web Services' Machine Learning Services
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Building Resilience for the Long Run
Building Resilience for the Long Run How Travel & Hospitality companies can stay agile during business disruption COPYRIGHT 2020, AMAZON WEB SERVICES, INC. OR ITS AFFILIATES 1 About AWS Travel and Hospitality WS Travel and Hospitality is the global industry practice for Amazon Web Services (AWS), with a charter to support customers as they accelerate cloud adoption. Companies around the world, across every segment of the travel and hospitality industry - and of every size - run on AWS. This includes industry leaders like Airbnb, Avis Budget Group, Best Western, Choice Hotels, DoorDash, Dunkin’ Brands, Expedia Group, Korean Air, McDonald’s, Ryanair, SiteMinder, Sysco, Toast, United Airlines, and Wyndham Hotels. These companies and many others are transforming their business by leveraging technology to enhance customer experiences and increase operational efficiency. For more information about AWS Travel and Hospitality, please visit aws.com/travel. Keep up-to-date with executive insights and industry viewpoints at the AWS Travel and Hospitality Blog. Click here to be contacted by an AWS representative. COPYRIGHT 2020, AMAZON WEB SERVICES, INC. OR ITS AFFILIATES AWS.COM/TRAVEL 2 Foreword It has been said that challenges should not paralyze you but help discover who you are. We have seen time and again that immense challenges can bring about incredible innovation. That is especially true today. Around the globe, travel and hospitality companies are taking advantage of the flexibility of the AWS Cloud to innovate quickly and meet their needs during these trying times. Faced with disruption – whether a localized weather event or a pandemic that spans continents – travel and hospitality companies respond and rebuild. -

Amazon Polly: Use Cases
A I M 3 0 3 Stop guessing: Use AI to understand customer conversations Dirk Fröhner Boaz Ziniman Senior Solutions Architect Principal Technical Evangelist Amazon Web Services Amazon Web Services © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Agenda • Introduction Amazon Web Services (AWS) AI/ML offering • Introduction Amazon Connect • Architecture of the labs • Work on the labs • Wrap-up Related breakouts • AIM211 - AI document processing for business automation • AIM212 - ML in retail: Solutions that add intelligence to your business • AIM222 - Monetizing text-to-speech AI • AIM302 - Create a Q&A bot with Amazon Lex and Amazon Alexa © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Natural language processing (NLP) • Automatic speech recognition (ASR) • Natural language understanding (NLU) • Text to speech • Translation @ziniman @ziniman Use cases for NLP Voice of customer Knowledge management Education applications Customer service/ Semantic search Accessibility call centers Enterprise Captioning workflows Information bots digital assistant Personalization Localization The Amazon ML stack: Broadest & deepest set of capabilities Vision Speech Language Chatbots Forecasting Recommendations A I s e r v i c e s A m a z o n A m a z o n T r a n s l a t e A m a z o n A m a z o n A m a z o n A m a z o n A m a z o n C o m p r e h e n d A m a z o n A m a z o n A m a z o n Rekognition Rekognition T e x t r a c t P o l l y T r a n s c r i b e & A m a z o n L e x F o r e c a s t Personalize i m a -

Building Alexa Skills Using Amazon Sagemaker and AWS Lambda
Bootcamp: Building Alexa Skills Using Amazon SageMaker and AWS Lambda Description In this full-day, intermediate-level bootcamp, you will learn the essentials of building an Alexa skill, the AWS Lambda function that supports it, and how to enrich it with Amazon SageMaker. This course, which is intended for students with a basic understanding of Alexa, machine learning, and Python, teaches you to develop new tools to improve interactions with your customers. Intended Audience This course is intended for those who: • Are interested in developing Alexa skills • Want to enhance their Alexa skills using machine learning • Work in a customer-focused industry and want to improve their customer interactions Course Objectives In this course, you will learn: • The basics of the Alexa developer console • How utterances and intents work, and how skills interact with AWS Lambda • How to use Amazon SageMaker for the machine learning workflow and for enhancing Alexa skills Prerequisites We recommend that attendees of this course have the following prerequisites: • Basic familiarity with Alexa and Alexa skills • Basic familiarity with machine learning • Basic familiarity with Python • An account on the Amazon Developer Portal Delivery Method This course is delivered through a mix of: • Classroom training • Hands-on Labs Hands-on Activity • This course allows you to test new skills and apply knowledge to your working environment through a variety of practical exercises • This course requires a laptop to complete lab exercises; tablets are not appropriate Duration One Day Course Outline This course covers the following concepts: • Getting started with Alexa • Lab: Building an Alexa skill: Hello Alexa © 2018, Amazon Web Services, Inc. -
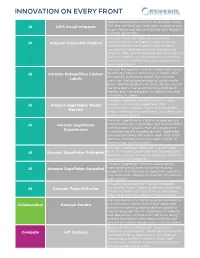
Innovation on Every Front
INNOVATION ON EVERY FRONT AWS DeepComposer uses AI to compose music. AI AWS DeepComposer The new service gives developers a creative way to get started and become familiar with machine learning capabilities. Amazon Transcribe Medical is a machine AI Amazon Transcribe Medical learning service that makes it easy to quickly create accurate transcriptions from medical consultations between patients and physician dictated notes, practitioner/patient consultations, and tele-medicine are automatically converted from speech to text for use in clinical documen- tation applications. Amazon Rekognition Custom Labels helps users AI Amazon Rekognition Custom identify the objects and scenes in images that are specific to business needs. For example, Labels users can find corporate logos in social media posts, identify products on store shelves, classify machine parts in an assembly line, distinguish healthy and infected plants, or detect animated characters in videos. Amazon SageMaker Model Monitor is a new AI Amazon SageMaker Model capability of Amazon SageMaker that automatically monitors machine learning (ML) Monitor models in production, and alerts users when data quality issues appear. Amazon SageMaker is a fully managed service AI Amazon SageMaker that provides every developer and data scientist with the ability to build, train, and deploy ma- Experiments chine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models. Amazon SageMaker Debugger is a new capa- AI Amazon SageMaker Debugger bility of Amazon SageMaker that automatically identifies complex issues developing in machine learning (ML) training jobs. Amazon SageMaker Autopilot automatically AI Amazon SageMaker Autopilot trains and tunes the best machine learning models for classification or regression, based on your data while allowing to maintain full control and visibility. -

“Jeff, What Does Day 2 Look Like?” That's a Question I Just Got at Our
“Jeff, what does Day 2 look like?” That’s a question I just got at our most recent all-hands meeting. I’ve been reminding people that it’s Day 1 for a couple of decades. I work in an Amazon building named Day 1, and when I moved buildings, I took the name with me. I spend time thinking about this topic. “Day 2 is stasis. Followed by irrelevance. Followed by excruciating, painful decline. Followed by death. And that is why it is always Day 1.” To be sure, this kind of decline would happen in extreme slow motion. An established company might harvest Day 2 for decades, but the final result would still come. I’m interested in the question, how do you fend off Day 2? What are the techniques and tactics? How do you keep the vitality of Day 1, even inside a large organization? Such a question can’t have a simple answer. There will be many elements, multiple paths, and many traps. I don’t know the whole answer, but I may know bits of it. Here’s a starter pack of essentials for Day 1 defense: customer obsession, a skeptical view of proxies, the eager adoption of external trends, and high-velocity decision making. True Customer Obsession There are many ways to center a business. You can be competitor focused, you can be product focused, you can be technology focused, you can be business model focused, and there are more. But in my view, obsessive customer focus is by far the most protective of Day 1 vitality. -
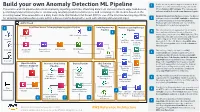
Build Your Own Anomaly Detection ML Pipeline
Device telemetry data is ingested from the field Build your own Anomaly Detection ML Pipeline 1 devices on a near real-time basis by calls to the This end-to-end ML pipeline detects anomalies by ingesting real-time, streaming data from various network edge field devices, API via Amazon API Gateway. The requests get performing transformation jobs to continuously run daily predictions/inferences, and retraining the ML models based on the authenticated/authorized using Amazon Cognito. incoming newer time series data on a daily basis. Note that Random Cut Forest (RCF) is one of the machine learning algorithms Amazon Kinesis Data Firehose ingests the data in for detecting anomalous data points within a data set and is designed to work with arbitrary-dimensional input. 2 real time, and invokes AWS Lambda to transform the data into parquet format. Kinesis Data AWS Cloud Firehose will automatically scale to match the throughput of the data being ingested. 1 Real-Time Device Telemetry Data Ingestion Pipeline 2 Data Engineering Machine Learning Devops Pipeline Pipeline The telemetry data is aggregated on an hourly 3 3 basis and re-partitioned based on the year, month, date, and hour using AWS Glue jobs. The Amazon Cognito AWS Glue Data Catalog additional steps like transformations and feature Device #1 engineering are performed for training the SageMaker AWS CodeBuild Anomaly Detection ML Model using AWS Glue Notebook Create ML jobs. The training data set is stored on Amazon Container S3 Data Lake. Amazon Kinesis AWS Lambda S3 Data Lake AWS Glue Device #2 Amazon API The training code is checked in an AWS Gateway Data Firehose 4 AWS SageMaker CodeCommit repo which triggers a Machine Training CodeCommit Containers Learning DevOps (MLOps) pipeline using AWS Dataset for Anomaly CodePipeline. -

Cloud Computing & Big Data
Cloud Computing & Big Data PARALLEL & SCALABLE MACHINE LEARNING & DEEP LEARNING Ph.D. Student Chadi Barakat School of Engineering and Natural Sciences, University of Iceland, Reykjavik, Iceland Juelich Supercomputing Centre, Forschungszentrum Juelich, Germany @MorrisRiedel LECTURE 11 @Morris Riedel @MorrisRiedel Big Data Analytics & Cloud Data Mining November 10, 2020 Online Lecture Review of Lecture 10 –Software-As-A-Service (SAAS) ▪ SAAS Examples of Customer Relationship Management (CRM) Applications (PAAS) (introducing a growing range of machine (horizontal learning and scalability artificial enabled by (IAAS) intelligence Virtualization capabilities) in Clouds) [5] AWS Sagemaker [4] Freshworks Web page [3] ZOHO CRM Web page modfied from [2] Distributed & Cloud Computing Book [1] Microsoft Azure SAAS Lecture 11 – Big Data Analytics & Cloud Data Mining 2 / 36 Outline of the Course 1. Cloud Computing & Big Data Introduction 11. Big Data Analytics & Cloud Data Mining 2. Machine Learning Models in Clouds 12. Docker & Container Management 13. OpenStack Cloud Operating System 3. Apache Spark for Cloud Applications 14. Online Social Networking & Graph Databases 4. Virtualization & Data Center Design 15. Big Data Streaming Tools & Applications 5. Map-Reduce Computing Paradigm 16. Epilogue 6. Deep Learning driven by Big Data 7. Deep Learning Applications in Clouds + additional practical lectures & Webinars for our hands-on assignments in context 8. Infrastructure-As-A-Service (IAAS) 9. Platform-As-A-Service (PAAS) ▪ Practical Topics 10. Software-As-A-Service -

Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide
Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS: AWS Technical Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Table of Contents Abstract and introduction .................................................................................................................... i Abstract .................................................................................................................................... 1 Introduction .............................................................................................................................. 1 Personas for an ML platform ............................................................................................................... 2 AWS accounts .................................................................................................................................... 3 Networking architecture ..................................................................................................................... -

AWS Is How Game Tech Volume 2
Behind great games, there’s game tech. AWS is How Game Tech Volume 2 AWS IS HOW GAME TECH EDITION Volume 2 2 Player profile Player Player ID: Eric Morales Classification: Reconnecting through tech Head of AWS Game Tech EMEA Player history Stockholm Joined Gamer since 59°32′N 18°06′E July 2015 1995 Over the past year, many of us have felt compelled to escape into a game, even if only for a few hours. Technology has been our salvation and our solace. When we’ve been forced to stay apart, tech has helped us to feel connected, whether by racing strangers through virtual cities or teaming up to battle awesome foes in Wolcen: Lords of Mayhem. There has, perhaps, never been a greater keep pushing forward on a bumpy road and instead of sticking to a plan that no longer Perhaps one of the key things we can need for the escape that gaming gives when to somersaulto a ne ont w one. fits. New ideas come through all the time learn from these studios is that adversity us. So I’d like to say an extra thank you to and you have to embrace them.” can spark the creativity we need to build Building on AWS gives studios the chance the studios we’re featuring in this issue. something truly spectacular. In many to experiment, innovate, and make For some of the developers we spoke Without you, lockdown would have been games, your character levels up and gets mistakes in order to keep forging ahead. to, the pandemic has been just one of just a little bit harder for so many millions stronger regardless of your own skill, which I’m 100 percent with Roberta Lucca many hurdles they’ve overcome. -

Interactive Attendee Guide for Oil & Gas Professionals
oil & gas Interactive attendee guide for Oil & Gas Professionals Hello, On behalf of the entire AWS Worldwide Oil & Gas team, welcome to re:Invent 2018! This year’s conference is going to be our Welcome. biggest yet, with 50,000+ attendees and more than 2,000 technical sessions. To get the most out of re:Invent, we encourage you to take advantage of the resources outlined in this document, including our “How to re:Invent” video series. Keep in mind that reserved seating goes live on October 11. You can start planning your schedule at any time by logging into your account, visiting the session catalog, and marking sessions of interest. Although re:Invent is a big conference, the strength of the Oil & Gas community makes it feel much smaller. We look forward to seeing you in Vegas! Arno van den Haak Business Development, AWS Worldwide Oil & Gas © 2018 | Amazon Web Services. All rights reserved. Table of contents What to expect in 2018 » Let’s get started. re:Invent agenda » Oil & Gas sessions » This guide is designed to help attendees of AWS re:Invent 2018 plan their experience and identify breakout sessions and events of interest. It is intended to complement the re:Invent app, Other recommended sessions » which will help attendees navigate the conference on-site. Networking opportunities » Click on the links to navigate this guide. Executive Summit overview » Event venues and logistics » AWS Oil & Gas contacts » © 2018 | Amazon Web Services. All rights reserved. What to expect Networking re:Invent Agenda Oil & Gas Other Recommended Executive Summit Event Venue AWS Oil & Gas in 2018 Sessions Sessions Opportunities Overview and Logistics Expert Contacts What Where AWS re:Invent is a learning conference hosted by Amazon Web We are taking over Las Vegas--with events at the ARIA, Vdara, Services (AWS) for the global cloud computing community. -

Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework
Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework Analytics Lens: AWS Well-Architected Framework Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Analytics Lens AWS Well-Architected Framework Table of Contents Abstract ............................................................................................................................................ 1 Abstract .................................................................................................................................... 1 Introduction ...................................................................................................................................... 2 Definitions ................................................................................................................................. 2 Data Ingestion Layer ........................................................................................................... 2 Data Access and Security Layer ............................................................................................ 3 Catalog and Search Layer ................................................................................................... -

Vendor Rating: Amazon
Vendor Rating: Amazon Published 7 July 2020 - ID G00722718 - 55 min read By Analysts Ed Anderson, Mike Dorosh, Rita Sallam, Adam Woodyer, Jason Daigler, Bern Elliot, David Wright, Patrick Connaughton, Yefim Natis, Mark Paine, Thomas Murphy, Sandeep Unni, Steve Riley, Peter Havart-Simkin, Craig Lowery Initiatives:Sourcing, Procurement and Vendor Management Leaders Amazon’s technology-driven growth continues to disrupt and reshape markets. Amazon Web Services leads in cloud market share bolstered by an aggressive pace of innovation. Market shifts will challenge Amazon to adapt its disruptive models and continue high rates of growth. Overall Rating Figure 1. Vendor Rating for Amazon Overall Rating: Strong Amazon is a multifaceted conglomerate consisting of business interests in e-commerce, cloud computing, digital content delivery, retail and grocery, as well as extensive logistics resources including fulfillment centers, shipping and delivery. Amazon leverages the power of technology to disrupt traditional markets and deliver its unique customer experiences. Amazon Web Services Gartner, Inc. | 722718 Page 1/33 (AWS), the Amazon cloud computing powerhouse, demonstrates the power that disruptive technology can have on a market. Through 2019, AWS continued as the cloud market share leader with annual revenue exceeding $35 billion in 2019 and a run rate of $41 billion in 2020. 1,2 Amazon is culturally wired to deliver an aggressive pace of innovation, driven by expanding customer and vertical industry requirements. Cross-leverage between Amazon’s e-commerce and cloud businesses support a foundation of efficiency, dynamic operations, adaptability and innovation. While the e-commerce and retail businesses drive revenue growth, AWS drives profitability, allowing Amazon to invest in business initiatives that keep it at the forefront of its respective markets.