Quantitative Hyperspectral Imaging Pipeline to Recover Surface Images from CRISM Radiance Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Sherpa and the Snowman
THE SHERPA AND THE SNOWMAN Charles Stonor the "Snowman" exist an ape DOESlike creature dwelling in the unexplored fastnesses of the Himalayas or is he only a myth ? Here the author describes a quest which began in the foothills of Nepal and led to the lower slopes of Everest. After five months of wandering in the vast alpine stretches on the roof of the world he and his companions had to return without any demon strative proof, but with enough indirect evidence to convince them that the jeti is no myth and that one day he will be found to be of a a very remarkable man-like ape type thought to have died out thousands of years before the dawn of history. " Apart from the search for the snowman," the narrative investigates every aspect of life in this the highest habitable region of the earth's surface, the flora and fauna of the little-known alpine zone below the snow line, the unexpected birds and beasts to be met with in the Great Himalayan Range, the little Buddhist communities perched high up among the crags, and above all the Sherpas themselves that stalwart people chiefly known to us so far for their gallant assistance in climbing expeditions their yak-herding, their happy family life, and the wav they cope with the bleak austerity of their lot. The book is lavishly illustrated with the author's own photographs. THE SHERPA AND THE SNOWMAN "When the first signs of spring appear the Sherpas move out to their grazing grounds, camping for the night among the rocks THE SHERPA AND THE SNOWMAN By CHARLES STONOR With a Foreword by BRIGADIER SIR JOHN HUNT, C.B.E., D.S.O. -

Widespread Crater-Related Pitted Materials on Mars: Further Evidence for the Role of Target Volatiles During the Impact Process ⇑ Livio L
Icarus 220 (2012) 348–368 Contents lists available at SciVerse ScienceDirect Icarus journal homepage: www.elsevier.com/locate/icarus Widespread crater-related pitted materials on Mars: Further evidence for the role of target volatiles during the impact process ⇑ Livio L. Tornabene a, , Gordon R. Osinski a, Alfred S. McEwen b, Joseph M. Boyce c, Veronica J. Bray b, Christy M. Caudill b, John A. Grant d, Christopher W. Hamilton e, Sarah Mattson b, Peter J. Mouginis-Mark c a University of Western Ontario, Centre for Planetary Science and Exploration, Earth Sciences, London, ON, Canada N6A 5B7 b University of Arizona, Lunar and Planetary Lab, Tucson, AZ 85721-0092, USA c University of Hawai’i, Hawai’i Institute of Geophysics and Planetology, Ma¯noa, HI 96822, USA d Smithsonian Institution, Center for Earth and Planetary Studies, Washington, DC 20013-7012, USA e NASA Goddard Space Flight Center, Greenbelt, MD 20771, USA article info abstract Article history: Recently acquired high-resolution images of martian impact craters provide further evidence for the Received 28 August 2011 interaction between subsurface volatiles and the impact cratering process. A densely pitted crater-related Revised 29 April 2012 unit has been identified in images of 204 craters from the Mars Reconnaissance Orbiter. This sample of Accepted 9 May 2012 craters are nearly equally distributed between the two hemispheres, spanning from 53°Sto62°N latitude. Available online 24 May 2012 They range in diameter from 1 to 150 km, and are found at elevations between À5.5 to +5.2 km relative to the martian datum. The pits are polygonal to quasi-circular depressions that often occur in dense clus- Keywords: ters and range in size from 10 m to as large as 3 km. -

Regional Investigations of the Effects of Secondaries Upon the Martian Cratering Record
46th Lunar and Planetary Science Conference (2015) 2630.pdf REGIONAL INVESTIGATIONS OF THE EFFECTS OF SECONDARIES UPON THE MARTIAN CRATERING RECORD. Asmin V. Pathare1 and Jean-Pierre Williams2 1Planetary Science Institute, Tucson, AZ 85719 ([email protected]) 2Earth, Planetary, and Space Sciences, University of California , Los Angeles, CA 90095. Motivation: We consider the following paradox: if Zunil-type impacts can generate tens of millions of secondary craters on Mars approximately once every million years [1], then why do so many martian crater counts show so little isochronal evidence (e.g., [2]) of secondary “contamination”? We suggest three possible explanations for this incongruity: (1) Atmospheric Pressure Variations: lower pres- sures at low obliquities may have facilitated massive secondary generation at the time of the Zunil impact; alternatively, higher pressures at high obliquities may have inhibited secondary cratering from other Zunil- sized impacts. (2) Target Material Strength: Zunil impacting into a notably weak regolith may have augmented second- ary crater production relative to similar-sized craters. (3) Surface Modification: secondary craters from previous Zunil-sized impacts may have once been just as prominent as those emanating from Zunil, but have since been obliterated by rapid resurfacing over the past 100 Myr. Figure 1. Modeled annual SFDs for the locations of As part of a newly-funded MDAP, we will conduct Zunil and Pangboche craters and isochrons derived regional investigations of secondary cratering to help from polynomial fits. The crater counts from the two locations are scaled to the same time/area for compari- distinguish amongst these three potential explanations. son with the annual isochrons. -
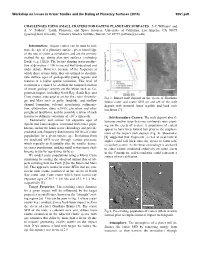
Challenges Using Small Craters for Dating Planetary Surfaces
Workshop on Issues in Crater Studies and the Dating of Planetary Surfaces (2015) 9051.pdf CHALLENGES USING SMALL CRATERS FOR DATING PLANETARY SURFACES. J.-P. Williams1 and A. V. Pathare2, 1Earth, Planetary, and Space Sciences, University of California, Los Angeles, CA 90095 ([email protected]), 2Planetary Science Institute, Tuscon, AZ 85719 ([email protected]). Introduction: Impact craters can be used to esti- mate the age of a planetary surface, given knowledge of the rate of crater accumulation, and are the primary method for age dating planetary surfaces (excluding Earth) (e.g. [1][2]). The factors shaping crater produc- tion at diameters < 100 m are not well understood and under debate. However, because of the frequency at which these craters form, they are utilized to discrimi- nate surface ages of geologically young regions and features at a higher spatial resolution. This level of resolution is required to establish the temporal relation of recent geologic activity on the Moon such as Co- pernican impacs, including North Ray, South Ray, and Cone craters, sites used to anchor the crater chronolo- Fig 1. Impact melt deposit on the ejecta of Giordano gy, and Mars such as gully, landslide, and outflow Bruno crater and crater SFD on and off of the melt channel formation, volcanic resurfacing, sedimenta- deposit with nominal lunar regolith and hard rock tion, exhumation, dune activity, glaciation and other isochrons [7]. periglacial landforms, and the possible relation of such 7 features to obliquity variations of ~10 y timescale. Self-Secondary Craters: The melt deposit also il- Radiometric and cosmic ray exposure ages of lustrates another issue that may confound crater count- Apollo and Luna samples, correlated with crater popu- ing on the ejecta of craters. -

USGS Open-File Report 2006-1263
Abstracts of the Annual Meeting of Planetary Geologic Mappers, Nampa, Idaho 2006 Edited By Tracy K.P. Gregg,1 Kenneth L. Tanaka,2 and R. Stephen Saunders3 Open-File Report 2006-1263 2006 Any use of trade, firm, or product names is for descriptive purposes only and does not imply endorsement by the U.S. Government. U.S. DEPARTMENT OF THE INTERIOR U.S. GEOLOGICAL SURVEY 1 The State University of New York at Buffalo, Department of Geology, 710 Natural Sciences Complex, Buffalo, NY 14260-3050. 2 U.S. Geological Survey, 2255 N. Gemini Drive, Flagstaff, AZ 86001. 3 NASA Headquarters, Office of Space Science, 300 E. Street SW, Washington, DC 20546. Report of the Annual Mappers Meeting Northwest Nazarene University Nampa, Idaho June 30 – July 2, 2006 Approximately 18 people attended this year’s mappers meeting, and many more submitted abstracts and maps in absentia. The meeting was held on the campus of Northwest Nazarene University (NNU), and was graciously hosted by NNU’s School of Health and Science. Planetary mapper Dr. Jim Zimbelman is an alumnus of NNU, and he was pivotal in organizing the meeting at this location. Oral and poster presentations were given on Friday, June 30. Drs. Bill Bonnichsen and Marty Godchaux led field excursions on July 1 and 2. USGS Astrogeology Team Chief Scientist Lisa Gaddis led the meeting with a brief discussion of the status of the planetary mapping program at USGS, and a more detailed description of the Lunar Mapping Program. She indicated that there is now a functioning website (http://astrogeology.usgs.gov/Projects/PlanetaryMapping/Lunar/) which shows which lunar quadrangles are available to be mapped. -

Timeline of Our Mysterious World.Pdf
Our Mysterious World--a collection of weirdness http://www.geocities.com/nmdecke/MysteriousWorld.html (1 of 455)11/10/2007 12:44:11 AM Our Mysterious World--a collection of weirdness This is a timeline of weird and "Art Bell-ish" events and happenings that I have been collecting off the internet for a while. Yes, many of the entries contradict each other, and others are most likely patent lies, but all of these are in the public literature and you can sort them out for yourselves… Due to some positive notes from readers, I have decided to start updating this list after about a year of ignoring it. I will be adding new stuff bit by bit, with the latest batch on August 1, 2007. Go back to my homepage for more good stuff, please and thank you. Any comments or additions? Send them to me at [email protected] Alpha and Omega Immanentizing of the Eschaton. Whatever the hell that means… 75,000,000 BC Xenu ordered nuking of earth (Per Scientology). Radioactive dust still in geologic strata in the areas of the American southwestern deserts, African deserts, and Gobi desert. Geologists can't explain the "fused green glass" that has been found in such sites as Pierrelatte in Gabon, the Euphrates Valley, the Sahara Desert, the Gobi Desert, Iraq, the Mojave Desert, Scotland, the Old and Middle Kingdoms of Egypt, and south-central Turkey. From the same time period, scientists have found a number of uranium deposits that appear to have been mined or depleted in antiquity. -

Chapter 8. Glacioaeolian Processes, Sediments, and Landforms
CHAPTER GLACIOAEOLIAN PROCESSES, SEDIMENTS, AND LANDFORMS 8 E. Derbyshire1 and L.A. Owen2 1Royal Holloway, University of London, Surrey, United Kingdom, 2University of Cincinnati, Cincinnati, OH, United States 8.1 INTRODUCTION The frequently strong association of aeolian processes with present and former glaciation has been recognized for over 80 years from field observations (Hogbom, 1923). Bullard and Austin (2011) point out that the interaction between glacial dynamics, glaciofluvial, and aeolian transport in proglacial landscapes plays an important role, not only in local environmental systems, but also in the global context by affecting the amount of dust generated and transported. Moreover, glacial outwash plains have been cited as a significant source of dust in the Southern Hemisphere (Sugden et al., 2009) and must also have been important dust sources in the northern hemisphere (Bullard and Austin, 2011). Cold climate aeolian processes and landforms have been widely acknowledged in proglacial and paraglacial geomorphology (e.g., Ballantyne, 2002; Seppa¨la¨, 2004). However, relatively little work has been undertaken on glacioaeolian processes, sediments, and landforms compared to other glacial systems. The ISI Web of Science does not even provide one reference to the term ‘glacioaeolian’ and Google Scholar provides a mere 61 references. Variations on the spell- ing of glacioaeolian, including glacioeolian, glacio-aeolian, glacio aeolian, and glacio-eolian yield less than 40 citations. Even the international journal Aeolian Research provides only one reference to the term glacioaeolian. A search of glacial aeolian yields 924 and 35,300 citations in the ISI Web of Science and Google Scholar, respectively. However, this includes reference to aeolian sedi- ments that are not of glacial origin, but were deposited during a glacial event. -

Ebook < Impact Craters on Mars # Download
7QJ1F2HIVR # Impact craters on Mars « Doc Impact craters on Mars By - Reference Series Books LLC Mrz 2012, 2012. Taschenbuch. Book Condition: Neu. 254x192x10 mm. This item is printed on demand - Print on Demand Neuware - Source: Wikipedia. Pages: 50. Chapters: List of craters on Mars: A-L, List of craters on Mars: M-Z, Ross Crater, Hellas Planitia, Victoria, Endurance, Eberswalde, Eagle, Endeavour, Gusev, Mariner, Hale, Tooting, Zunil, Yuty, Miyamoto, Holden, Oudemans, Lyot, Becquerel, Aram Chaos, Nicholson, Columbus, Henry, Erebus, Schiaparelli, Jezero, Bonneville, Gale, Rampart crater, Ptolemaeus, Nereus, Zumba, Huygens, Moreux, Galle, Antoniadi, Vostok, Wislicenus, Penticton, Russell, Tikhonravov, Newton, Dinorwic, Airy-0, Mojave, Virrat, Vernal, Koga, Secchi, Pedestal crater, Beagle, List of catenae on Mars, Santa Maria, Denning, Caxias, Sripur, Llanesco, Tugaske, Heimdal, Nhill, Beer, Brashear Crater, Cassini, Mädler, Terby, Vishniac, Asimov, Emma Dean, Iazu, Lomonosov, Fram, Lowell, Ritchey, Dawes, Atlantis basin, Bouguer Crater, Hutton, Reuyl, Porter, Molesworth, Cerulli, Heinlein, Lockyer, Kepler, Kunowsky, Milankovic, Korolev, Canso, Herschel, Escalante, Proctor, Davies, Boeddicker, Flaugergues, Persbo, Crivitz, Saheki, Crommlin, Sibu, Bernard, Gold, Kinkora, Trouvelot, Orson Welles, Dromore, Philips, Tractus Catena, Lod, Bok, Stokes, Pickering, Eddie, Curie, Bonestell, Hartwig, Schaeberle, Bond, Pettit, Fesenkov, Púnsk, Dejnev, Maunder, Mohawk, Green, Tycho Brahe, Arandas, Pangboche, Arago, Semeykin, Pasteur, Rabe, Sagan, Thira, Gilbert, Arkhangelsky, Burroughs, Kaiser, Spallanzani, Galdakao, Baltisk, Bacolor, Timbuktu,... READ ONLINE [ 7.66 MB ] Reviews If you need to adding benefit, a must buy book. Better then never, though i am quite late in start reading this one. I discovered this publication from my i and dad advised this pdf to find out. -- Mrs. Glenda Rodriguez A brand new e-book with a new viewpoint. -

Martian Volcanic and Sedimentary Layer Study: Morphologic and Morphometric Criteria for Different Origins
43rd Lunar and Planetary Science Conference (2012) 1843.pdf MARTIAN VOLCANIC AND SEDIMENTARY LAYER STUDY: MORPHOLOGIC AND MORPHOMETRIC CRITERIA FOR DIFFERENT ORIGINS. V. -P. Kostama1, M. A. Ivanov2, A. I. Rauhala1, T. Törmänen1, J. Korteniemi1, J. Raitala1 1Astronomy Division, Dept. of Physics, FI-90014 University of Oulu, Finland ([email protected]), 2V.I. Vernadsky Institute, RAS, Moscow, Russia. Introduction: Stacks of layered rocks are observed The sedimentary provinces on Mars are not as ob- in many different Martian geological settings, exposed vious and the end-member sites for these environments in scarps and crater walls that cut surface materials. should be selected with caution. Interiors of Gale, Two principal processes, effusive volcanism and sedi- Holden and Eberswalde craters that are interpreted as mentation, can lead to formation of the layered se- locations where sedimentary rocks formed within the quences. Thus, just the observation of the exposed possible crater lakes [e.g. 2-14] were chosen. layered structure is not sufficient for the interpretation The rhythmic sequences consisting of numerous of the main processes that were responsible for the lighter and darker layers characterize the deposits on formation of the terrain in question. the floor of these craters (Fig. 1b). The walls of the In order to characterize layered suites of different deposits are smooth and gently winding and they lack origin we conducted a systematic analysis of high- extensive talus aprons. The deposits are heavily de- resolution images of CTX and HiRISE (Context Cam- graded and demonstrate cliff-and-bench pattern of era and High Resolution Imaging Science Experiment) erosion. -

Wereldwijd Wandelen Individueel Individueel WERELDWIJD WANDELEN 2012
Ken je ook de rest van ons aanbod? Wereldwijd wandelen individueel www.andersreizen.be/ individueel WERELDWIJD WANDELEN 2012 Refugiestraat 15 3290 Diest – België tel. 013 33 40 40 Actieve gezinsreizen fax 013 32 16 08 www.andersreizen.be/ [email protected] gezin wereldwijd wandelen www.andersreizen.be Openingsuren Avontuurlijke jongerenreizen (18-34 jaar) Maandag 13.30–18.00 u. www.bootz.be Dinsdag tot vrijdag 10.00–12.30 u. en 13.30– 18.00 u. Zaterdag 10.00–12.30 u. Bankgegevens IBAN: BE28230021281820 SWIFT: GEBABEBB BNP Parisbas Fortis Bank, Kaai 6, 3290 Diest in groep Vergunning categorie A1431 RPR Leuven 2012 De reizen van Anders Reizen kan je ook boeken in de Joker-kantoren: 1000 Brussel 3000 Leuven Pletinckxstraat 3 Boekhandelstraat 3 tel. 02 502 19 37 – fax 02 502 29 23 tel. 016 22 65 50 – fax 016 22 75 37 [email protected] [email protected] 2000 Antwerpen 3500 Hasselt Blauwtorenplein 10 Leopoldplein 4 tel. 03 231 72 68 – fax 03 233 18 78 tel. 011 23 25 88 – fax 011 23 28 69 [email protected] [email protected] 2610 Wilrijk 8000 Brugge Boomsesteenweg 666 * Academiestraat 10 tel. 03 827 90 08 – fax 03 827 33 40 tel. 050 34 78 81 – fax 050 34 78 21 [email protected] [email protected] 2800 Mechelen 8530 Harelbeke-Kortrijk Rode Kruisplein 14 * Kortrijksesteenweg 415 * tel. 015 21 87 77 – fax 015 21 91 99 tel. 056 22 56 14 – fax 056 25 76 03 [email protected] [email protected] 9000 Gent Bagattenstraat 64 Stap een andere tel. -

Late-Stage Intrusive Activity at Olympus Mons
LATE-STAGE INTRUSIVE ACTIVITY AT OLYMPUS MONS, MARS: SUMMIT INFLATION AND GIANT DIKE FORMATION Peter J. Mouginis-Mark1* and Lionel Wilson2 1Hawaii Institute of Geophysics and Planetology University of Hawaii Honolulu, Hawaii 96822 USA 2Lancaster Environment Centre Lancaster University Lancaster LA1 4YQ UK Icarus In press, September 2018 Keywords: Mars Olympus Mons Ascraeus Mons Volcanic dikes 1 Abstract 2 By mapping the distribution of 351 lava flows at the summit area of Olympus Mons 3 volcano on Mars, and correlating these flows with the current topography from the Mars 4 Orbiter Laser Altimeter (MOLA), we have identified numerous flows which appear to have 5 moved uphill. This disparity is most clearly seen to the south of the caldera rim, where the 6 elevation increases by >200 m along the apparent path of the flow. Additional present day 7 topographic anomalies have been identified, including the tilting down towards the north 8 of the floors of Apollo and Hermes Paterae within the caldera, and an elevation difference 9 of >400 m between the northern and southern portions of the floor of Zeus Patera. We 10 conclude that inflation of the southern flank after the eruption of the youngest lava flows 11 is the most plausible explanation, which implies that intrusive activity at Olympus Mons 12 continued towards the present beyond the age of the youngest paterae ~200 – 300 Myr 13 (Neukum et al., 2004; Robbins et al., 2011). We propose that intrusion of lateral dikes to 14 radial distances >2,000 km is linked to the formation of the individual paterae at Olympus 15 Mons. -

ORAL/T.V. PRESENTATIONS Peter J. Mouginis-Mark (Last Updated
ORAL/T.V. PRESENTATIONS Peter J. Mouginis-Mark (Last updated October 2019) NOTE: No data were collected for 1990 or earlier years. TALKS: February 25th 1991: "Venus and the Magellan Mission". Hawaii Space Society. March 13th 1991: "The Hawaii Space Grant College Program". National Space Grant College Directors' Meeting, Huntsville, Alabama. March 15th 1991: "Remote Sensing of Volcanic Processes and Landforms". Coastal Studies Institute Seminar, Louisiana State University. March 20th 1991: "Parent Craters for the SNC Meteorites". 22nd Lunar and Planetary Science Conference, Houston, Texas. March 30th 1991: "Remote Sensing of Volcanoes". Hawaii Volcano Observatory Seminar. April 5th 1991: "Volcanoes on Mars and Venus". Geology and Geophysics Department Seminar. April 27th: "The Hawaii Space Grant College and Satellite Oceanography". Marine Option Program High School Seminar, UH. May 4th 1991: "Satellite observations of active volcanoes: Interdisciplinary investigations, EOS and other satellites". IUGS Workshop on Remote Sensing in Global Geoscience Processes. Boulder, Colorado. May 6th 1991: "Volcanoes on Earth and Mars". Seminar to the Planetary Brown-bag Talk Society, Laboratory for Atmospheric and Space Physics Seminar Program, University of Colorado at Boulder, Colorado. July 22nd 1991: "Back to the Planets". SPACEWEEK Talk, UH Manoa. July 25th 1991: "Planets in the Night Sky". Gifted and Talented Native Hawaiian School Children Program, UH Hilo. July 31st 1991: "Volcanism in the Aleutians and Alaskan Peninsula from ERS-1". ERS-1 Team Meeting, University of Alaska. August 1st 1991: "Remote Sensing of Active Volcanoes", Geophysical Institute Seminar, University of Alaska. August 26th 1991: "Remote Sensing of Volcanoes: SIR-C, ERS-1 and EOS", National Air and Space Museum Seminar, Smithsonian Institution, Washington, D.C.