Exception-Less System Calls for Event-Driven Servers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical UNIX Capability System
A Practical UNIX Capability System Adam Langley <[email protected]> 22nd June 2005 ii Abstract This report seeks to document the development of a capability security system based on a Linux kernel and to follow through the implications of such a system. After defining terms, several other capability systems are discussed and found to be excellent, but to have too high a barrier to entry. This motivates the development of the above system. The capability system decomposes traditionally monolithic applications into a number of communicating actors, each of which is a separate process. Actors may only communicate using the capabilities given to them and so the impact of a vulnerability in a given actor can be reasoned about. This design pattern is demonstrated to be advantageous in terms of security, comprehensibility and mod- ularity and with an acceptable performance penality. From this, following through a few of the further avenues which present themselves is the two hours traffic of our stage. Acknowledgments I would like to thank my supervisor, Dr Kelly, for all the time he has put into cajoling and persuading me that the rest of the world might have a trick or two worth learning. Also, I’d like to thank Bryce Wilcox-O’Hearn for introducing me to capabilities many years ago. Contents 1 Introduction 1 2 Terms 3 2.1 POSIX ‘Capabilities’ . 3 2.2 Password Capabilities . 4 3 Motivations 7 3.1 Ambient Authority . 7 3.2 Confused Deputy . 8 3.3 Pervasive Testing . 8 3.4 Clear Auditing of Vulnerabilities . 9 3.5 Easy Configurability . -

Reducing Power Consumption in Mobile Devices by Using a Kernel
IEEE TRANSACTIONS ON MOBILE COMPUTING, VOL. Z, NO. B, AUGUST 2017 1 Reducing Event Latency and Power Consumption in Mobile Devices by Using a Kernel-Level Display Server Stephen Marz, Member, IEEE and Brad Vander Zanden and Wei Gao, Member, IEEE E-mail: [email protected], [email protected], [email protected] Abstract—Mobile devices differ from desktop computers in that they have a limited power source, a battery, and they tend to spend more CPU time on the graphical user interface (GUI). These two facts force us to consider different software approaches in the mobile device kernel that can conserve battery life and reduce latency, which is the duration of time between the inception of an event and the reaction to the event. One area to consider is a software package called the display server. The display server is middleware that handles all GUI activities between an application and the operating system, such as event handling and drawing to the screen. In both desktop and mobile devices, the display server is located in the application layer. However, the kernel layer contains most of the information needed for handling events and drawing graphics, which forces the application-level display server to make a series of system calls in order to coordinate events and to draw graphics. These calls interrupt the CPU which can increase both latency and power consumption, and also require the kernel to maintain event queues that duplicate event queues in the display server. A further drawback of placing the display server in the application layer is that the display server contains most of the information required to efficiently schedule the application and this information is not communicated to existing kernels, meaning that GUI-oriented applications are scheduled less efficiently than they might be, which further increases power consumption. -

Ultimate++ Forum Probably with These Two Variables You Could Try to Integrate D-BUS
Subject: DBus integration -- need help Posted by jlfranks on Thu, 20 Jul 2017 15:30:07 GMT View Forum Message <> Reply to Message We are trying to add a DBus server to existing large U++ application that runs only on Linux. I've converted from X11 to GTK for Upp project config to be compatible with GIO dbus library. I've created a separate thread for the DBus server and ran into problems with event loop. I've gutted my DBus server code of everything except what is causing an issue. DBus GIO examples use GMainLoop in order for DBus to service asynchronous events. Everything compiles and runs except the main UI is not longer visible. There must be a GTK main loop already running and I've stepped on it with this code. Is there a way for me to obtain a pointer to the UI main loop and use it with my DBus server? How/where can I do that? Code snipped example as follows: ---- code snippet ---- myDBusServerMainThread() { //========================================================== ===== // // Enter main service loop for this thread // while (not needsExit ()) { // colaborate with join() GMainLoop *loop; loop = g_main_loop_new(NULL, FALSE); g_main_loop_run(loop); } } Subject: Re: DBus integration -- need help Posted by Klugier on Thu, 20 Jul 2017 22:30:17 GMT View Forum Message <> Reply to Message Hello, You could try use following methods of Ctrl to obtain gtk & gdk handlers: GdkWindow *gdk() const { return top ? top->window->window : NULL; } GtkWindow *gtk() const { return top ? (GtkWindow *)top->window : NULL; } Page 1 of 3 ---- Generated from Ultimate++ forum Probably with these two variables you could try to integrate D-BUS. -

Fundamentals of Xlib Programming by Examples
Fundamentals of Xlib Programming by Examples by Ross Maloney Contents 1 Introduction 1 1.1 Critic of the available literature . 1 1.2 The Place of the X Protocol . 1 1.3 X Window Programming gotchas . 2 2 Getting started 4 2.1 Basic Xlib programming steps . 5 2.2 Creating a single window . 5 2.2.1 Open connection to the server . 6 2.2.2 Top-level window . 7 2.2.3 Exercises . 10 2.3 Smallest Xlib program to produce a window . 10 2.3.1 Exercises . 10 2.4 A simple but useful X Window program . 11 2.4.1 Exercises . 12 2.5 A moving window . 12 2.5.1 Exercises . 15 2.6 Parts of windows can disappear from view . 16 2.6.1 Testing overlay services available from an X server . 17 2.6.2 Consequences of no server overlay services . 17 2.6.3 Exercises . 23 2.7 Changing a window’s properties . 23 2.8 Content summary . 25 3 Windows and events produce menus 26 3.1 Colour . 26 3.1.1 Exercises . 27 i CONTENTS 3.2 A button to click . 29 3.3 Events . 33 3.3.1 Exercises . 37 3.4 Menus . 37 3.4.1 Text labelled menu buttons . 38 3.4.2 Exercises . 43 3.5 Some events of the mouse . 44 3.6 A mouse behaviour application . 55 3.6.1 Exercises . 58 3.7 Implementing hierarchical menus . 58 3.7.1 Exercises . 67 3.8 Content summary . 67 4 Pixmaps 68 4.1 The pixmap resource . -

Onload User Guide
Onload User Guide Copyright © 2017 SOLARFLARE Communications, Inc. All rights reserved. The software and hardware as applicable (the “Product”) described in this document, and this document, are protected by copyright laws, patents and other intellectual property laws and international treaties. The Product described in this document is provided pursuant to a license agreement, evaluation agreement and/or non‐disclosure agreement. The Product may be used only in accordance with the terms of such agreement. The software as applicable may be copied only in accordance with the terms of such agreement. Onload is licensed under the GNU General Public License (Version 2, June 1991). See the LICENSE file in the distribution for details. The Onload Extensions Stub Library is Copyright licensed under the BSD 2‐Clause License. Onload contains algorithms and uses hardware interface techniques which are subject to Solarflare Communications Inc patent applications. Parties interested in licensing Solarflare's IP are encouraged to contact Solarflare's Intellectual Property Licensing Group at: Director of Intellectual Property Licensing Intellectual Property Licensing Group Solarflare Communications Inc, 7505 Irvine Center Drive Suite 100 Irvine, California 92618 You will not disclose to a third party the results of any performance tests carried out using Onload or EnterpriseOnload without the prior written consent of Solarflare. The furnishing of this document to you does not give you any rights or licenses, express or implied, by estoppel or otherwise, with respect to any such Product, or any copyrights, patents or other intellectual property rights covering such Product, and this document does not contain or represent any commitment of any kind on the part of SOLARFLARE Communications, Inc. -

Programmer's Guide
Programmer’s Guide Release 18.11.11 Jan 20, 2021 CONTENTS 1 Introduction 1 1.1 Documentation Roadmap...............................1 1.2 Related Publications..................................2 2 Overview 3 2.1 Development Environment..............................3 2.2 Environment Abstraction Layer............................4 2.3 Core Components...................................4 2.3.1 Ring Manager (librte_ring)..........................4 2.3.2 Memory Pool Manager (librte_mempool)..................4 2.3.3 Network Packet Buffer Management (librte_mbuf).............6 2.3.4 Timer Manager (librte_timer)........................6 2.4 Ethernet* Poll Mode Driver Architecture.......................6 2.5 Packet Forwarding Algorithm Support........................6 2.6 librte_net........................................6 3 Environment Abstraction Layer7 3.1 EAL in a Linux-userland Execution Environment..................7 3.1.1 Initialization and Core Launching......................8 3.1.2 Shutdown and Cleanup...........................8 3.1.3 Multi-process Support............................8 3.1.4 Memory Mapping Discovery and Memory Reservation..........8 3.1.5 Support for Externally Allocated Memory.................. 11 3.1.6 Per-lcore and Shared Variables....................... 12 3.1.7 Logs...................................... 12 3.1.8 CPU Feature Identification.......................... 12 3.1.9 User Space Interrupt Event......................... 13 3.1.10 Blacklisting.................................. 14 3.1.11 Misc Functions............................... -

A Linux Kernel Scheduler Extension for Multi-Core Systems
A Linux Kernel Scheduler Extension For Multi-Core Systems Aleix Roca Nonell Master in Innovation and Research in Informatics (MIRI) specialized in High Performance Computing (HPC) Facultat d’informàtica de Barcelona (FIB) Universitat Politècnica de Catalunya Supervisor: Vicenç Beltran Querol Cosupervisor: Eduard Ayguadé Parra Presentation date: 25 October 2017 Abstract The Linux Kernel OS is a black box from the user-space point of view. In most cases, this is not a problem. However, for parallel high performance computing applications it can be a limitation. Such applications usually execute on top of a runtime system, itself executing on top of a general purpose kernel. Current runtime systems take care of getting the most of each system core by distributing work among the multiple CPUs of a machine but they are not aware of when one of their threads perform blocking calls (e.g. I/O operations). When such a blocking call happens, the processing core is stalled, leading to performance loss. In this thesis, it is presented the proof-of-concept of a Linux kernel extension denoted User Monitored Threads (UMT). The extension allows a user-space application to be notified of the blocking and unblocking of its threads, making it possible for a core to execute another worker thread while the other is blocked. An existing runtime system (namely Nanos6) is adapted, so that it takes advantage of the kernel extension. The whole prototype is tested on a synthetic benchmarks and an industry mock-up application. The analysis of the results shows, on the tested hardware and the appropriate conditions, a significant speedup improvement. -

Linux Kernel Development 3Rd Edition
ptg Linux Kernel Development Third Edition ptg From the Library of Wow! eBook Developer’s Library ESSENTIAL REFERENCES FOR PROGRAMMING PROFESSIONALS Developer’s Library books are designed to provide practicing programmers with unique, high-quality references and tutorials on the programming languages and technologies they use in their daily work. All books in the Developer’s Library are written by expert technology practitioners who are especially skilled at organizing and presenting information in a way that’s useful for other programmers. Key titles include some of the best, most widely acclaimed books within their topic areas: PHP & MySQL Web Development Python Essential Reference Luke Welling & Laura Thomson David Beazley ISBN 978-0-672-32916-6 ISBN-13: 978-0-672-32978-6 MySQL Programming in Objective-C 2.0 ptg Paul DuBois Stephen G. Kochan ISBN-13: 978-0-672-32938-8 ISBN-13: 978-0-321-56615-7 Linux Kernel Development PostgreSQL Robert Love Korry Douglas ISBN-13: 978-0-672-32946-3 ISBN-13: 978-0-672-33015-5 Developer’s Library books are available at most retail and online bookstores, as well as by subscription from Safari Books Online at safari.informit.com Developer’s Library informit.com/devlibrary From the Library of Wow! eBook Linux Kernel Development ptg Third Edition Robert Love Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Cape Town • Sydney • Tokyo • Singapore • Mexico City From the Library of Wow! eBook Linux Kernel Development Acquisitions Editor Third Edition Mark Taber Development Copyright © 2010 Pearson Education, Inc. -

ODROID-HC2: 3.5” High Powered Storage February 1, 2018
ODROID WiFi Access Point: Share Files Via Samba February 1, 2018 How to setup an ODROID with a WiFi access point so that an ODROID’s hard drive can be accessed and modied from another computer. This is primarily aimed at allowing access to images, videos, and log les on the ODROID. ODROID-HC2: 3.5” High powered storage February 1, 2018 The ODROID-HC2 is an aordable mini PC and perfect solution for a network attached storage (NAS) server. This device home cloud-server capabilities centralizes data and enables users to share and stream multimedia les to phones, tablets, and other devices across a network. It is an ideal tool for many use Using SquashFS As A Read-Only Root File System February 1, 2018 This guide describes the usage of SquashFS PiFace: Control and Display 2 February 1, 2018 For those who have the PiFace Control and Display 2, and want to make it compatible with the ODROID-C2 Android Gaming: Data Wing, Space Frontier, and Retro Shooting – Pixel Space Shooter February 1, 2018 Variations on a theme! Race, blast into space, and blast things into pieces that are racing towards us. The fun doesn’t need to stop when you take a break from your projects. Our monthly pick on Android games. Linux Gaming: Saturn Games – Part 1 February 1, 2018 I think it’s time we go into a bit more detail about Sega Saturn for the ODROID-XU3/XU4 Gaming Console: Running Your Favorite Games On An ODROID-C2 Using Android February 1, 2018 I built a gaming console using an ODROID-C2 running Android 6 Controller Area Network (CAN) Bus: Implementation -
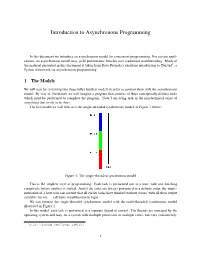
Introduction to Asynchronous Programming
Introduction to Asynchronous Programming In this document we introduce an asynchronous model for concurrent programming. For certain appli- cations, an asynchronous model may yield performance benefits over traditional multithreading. Much of the material presented in this document is taken from Dave Peticola’s excellent introduction to Twisted1, a Python framework for asynchronous programming. 1 The Models We will start by reviewing two (hopefully) familiar models in order to contrast them with the asynchronous model. By way of illustration we will imagine a program that consists of three conceptually distinct tasks which must be performed to complete the program. Note I am using task in the non-technical sense of something that needs to be done. The first model we will look at is the single-threaded synchronous model, in Figure 1 below: Figure 1: The single-threaded synchronous model This is the simplest style of programming. Each task is performed one at a time, with one finishing completely before another is started. And if the tasks are always performed in a definite order, the imple- mentation of a later task can assume that all earlier tasks have finished without errors, with all their output available for use — a definite simplification in logic. We can contrast the single-threaded synchronous model with the multi-threaded synchronous model illustrated in Figure 2. In this model, each task is performed in a separate thread of control. The threads are managed by the operating system and may, on a system with multiple processors or multiple cores, run truly concurrently, 1http://krondo.com/?page_id=1327 1 CS168 Async Programming Figure 2: The threaded model or may be interleaved together on a single processor. -

Monitoring File Events
MONITORING FILE EVENTS Some applications need to be able to monitor files or directories in order to deter- mine whether events have occurred for the monitored objects. For example, a graphical file manager needs to be able to determine when files are added or removed from the directory that is currently being displayed, or a daemon may want to monitor its configuration file in order to know if the file has been changed. Starting with kernel 2.6.13, Linux provides the inotify mechanism, which allows an application to monitor file events. This chapter describes the use of inotify. The inotify mechanism replaces an older mechanism, dnotify, which provided a subset of the functionality of inotify. We describe dnotify briefly at the end of this chapter, focusing on why inotify is better. The inotify and dnotify mechanisms are Linux-specific. (A few other systems provide similar mechanisms. For example, the BSDs provide the kqueue API.) A few libraries provide an API that is more abstract and portable than inotify and dnotify. The use of these libraries may be preferable for some applications. Some of these libraries employ inotify or dnotify, on systems where they are available. Two such libraries are FAM (File Alteration Monitor, http:// oss.sgi.com/projects/fam/) and Gamin (http://www.gnome.org/~veillard/gamin/). 19.1 Overview The key steps in the use of the inotify API are as follows: 1. The application uses inotify_init() to create an inotify instance. This system call returns a file descriptor that is used to refer to the inotify instance in later operations. -

Unbreakable Enterprise Kernel Release Notes for Unbreakable Enterprise Kernel Release 3
Unbreakable Enterprise Kernel Release Notes for Unbreakable Enterprise Kernel Release 3 E48380-10 June 2020 Oracle Legal Notices Copyright © 2013, 2020, Oracle and/or its affiliates. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract.