Enhancing Quality of Service Metrics for High Fan-In Node.Js Applications by Optimising the Network Stack
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical UNIX Capability System
A Practical UNIX Capability System Adam Langley <[email protected]> 22nd June 2005 ii Abstract This report seeks to document the development of a capability security system based on a Linux kernel and to follow through the implications of such a system. After defining terms, several other capability systems are discussed and found to be excellent, but to have too high a barrier to entry. This motivates the development of the above system. The capability system decomposes traditionally monolithic applications into a number of communicating actors, each of which is a separate process. Actors may only communicate using the capabilities given to them and so the impact of a vulnerability in a given actor can be reasoned about. This design pattern is demonstrated to be advantageous in terms of security, comprehensibility and mod- ularity and with an acceptable performance penality. From this, following through a few of the further avenues which present themselves is the two hours traffic of our stage. Acknowledgments I would like to thank my supervisor, Dr Kelly, for all the time he has put into cajoling and persuading me that the rest of the world might have a trick or two worth learning. Also, I’d like to thank Bryce Wilcox-O’Hearn for introducing me to capabilities many years ago. Contents 1 Introduction 1 2 Terms 3 2.1 POSIX ‘Capabilities’ . 3 2.2 Password Capabilities . 4 3 Motivations 7 3.1 Ambient Authority . 7 3.2 Confused Deputy . 8 3.3 Pervasive Testing . 8 3.4 Clear Auditing of Vulnerabilities . 9 3.5 Easy Configurability . -

Knot DNS Resolver Release 1.2.0
Knot DNS Resolver Release 1.2.0 CZ.NIC Labs Apr 25, 2017 Contents 1 Building project 3 1.1 Installing from packages.........................................3 1.2 Platform considerations.........................................3 1.3 Requirements...............................................3 1.4 Building from sources..........................................5 1.5 Getting Docker image..........................................7 2 Knot DNS Resolver library 9 2.1 Requirements...............................................9 2.2 For users.................................................9 2.3 For developers..............................................9 2.4 Writing layers.............................................. 11 2.5 APIs in Lua................................................ 12 2.6 API reference............................................... 15 3 Knot DNS Resolver daemon 47 3.1 Enabling DNSSEC............................................ 47 3.2 CLI interface............................................... 48 3.3 Scaling out................................................ 48 3.4 Running supervised........................................... 49 3.5 Configuration............................................... 49 3.6 Using CLI tools............................................. 64 4 Knot DNS Resolver modules 67 4.1 Static hints................................................ 67 4.2 Statistics collector............................................ 69 4.3 Query policies.............................................. 71 4.4 Views and ACLs............................................ -

Mysql NDB Cluster 7.5.16 (And Later)
Licensing Information User Manual MySQL NDB Cluster 7.5.16 (and later) Table of Contents Licensing Information .......................................................................................................................... 2 Licenses for Third-Party Components .................................................................................................. 3 ANTLR 3 .................................................................................................................................... 3 argparse .................................................................................................................................... 4 AWS SDK for C++ ..................................................................................................................... 5 Boost Library ............................................................................................................................ 10 Corosync .................................................................................................................................. 11 Cyrus SASL ............................................................................................................................. 11 dtoa.c ....................................................................................................................................... 12 Editline Library (libedit) ............................................................................................................. 12 Facebook Fast Checksum Patch .............................................................................................. -

Ultimate++ Forum Probably with These Two Variables You Could Try to Integrate D-BUS
Subject: DBus integration -- need help Posted by jlfranks on Thu, 20 Jul 2017 15:30:07 GMT View Forum Message <> Reply to Message We are trying to add a DBus server to existing large U++ application that runs only on Linux. I've converted from X11 to GTK for Upp project config to be compatible with GIO dbus library. I've created a separate thread for the DBus server and ran into problems with event loop. I've gutted my DBus server code of everything except what is causing an issue. DBus GIO examples use GMainLoop in order for DBus to service asynchronous events. Everything compiles and runs except the main UI is not longer visible. There must be a GTK main loop already running and I've stepped on it with this code. Is there a way for me to obtain a pointer to the UI main loop and use it with my DBus server? How/where can I do that? Code snipped example as follows: ---- code snippet ---- myDBusServerMainThread() { //========================================================== ===== // // Enter main service loop for this thread // while (not needsExit ()) { // colaborate with join() GMainLoop *loop; loop = g_main_loop_new(NULL, FALSE); g_main_loop_run(loop); } } Subject: Re: DBus integration -- need help Posted by Klugier on Thu, 20 Jul 2017 22:30:17 GMT View Forum Message <> Reply to Message Hello, You could try use following methods of Ctrl to obtain gtk & gdk handlers: GdkWindow *gdk() const { return top ? top->window->window : NULL; } GtkWindow *gtk() const { return top ? (GtkWindow *)top->window : NULL; } Page 1 of 3 ---- Generated from Ultimate++ forum Probably with these two variables you could try to integrate D-BUS. -

Fundamentals of Xlib Programming by Examples
Fundamentals of Xlib Programming by Examples by Ross Maloney Contents 1 Introduction 1 1.1 Critic of the available literature . 1 1.2 The Place of the X Protocol . 1 1.3 X Window Programming gotchas . 2 2 Getting started 4 2.1 Basic Xlib programming steps . 5 2.2 Creating a single window . 5 2.2.1 Open connection to the server . 6 2.2.2 Top-level window . 7 2.2.3 Exercises . 10 2.3 Smallest Xlib program to produce a window . 10 2.3.1 Exercises . 10 2.4 A simple but useful X Window program . 11 2.4.1 Exercises . 12 2.5 A moving window . 12 2.5.1 Exercises . 15 2.6 Parts of windows can disappear from view . 16 2.6.1 Testing overlay services available from an X server . 17 2.6.2 Consequences of no server overlay services . 17 2.6.3 Exercises . 23 2.7 Changing a window’s properties . 23 2.8 Content summary . 25 3 Windows and events produce menus 26 3.1 Colour . 26 3.1.1 Exercises . 27 i CONTENTS 3.2 A button to click . 29 3.3 Events . 33 3.3.1 Exercises . 37 3.4 Menus . 37 3.4.1 Text labelled menu buttons . 38 3.4.2 Exercises . 43 3.5 Some events of the mouse . 44 3.6 A mouse behaviour application . 55 3.6.1 Exercises . 58 3.7 Implementing hierarchical menus . 58 3.7.1 Exercises . 67 3.8 Content summary . 67 4 Pixmaps 68 4.1 The pixmap resource . -

Safeguard for Privileged Passwords 6.0.9 LTS Release Notes
Safeguard for Privileged Passwords 6.0.9 LTS Release Notes 03 March 2021, 06:20 These release notes provide information about the Safeguard for Privileged Passwords 6.0.9 LTS release. If you are updating a Safeguard for Privileged Passwords version prior to this release, read the release notes for the version found at: One Identity Safeguard for Privileged Passwords Technical Documentation. For the most recent documents and product information, see One Identity Safeguard for Privileged Passwords Technical Documentation. Release options Safeguard for Privileged Passwords includes two release versions: l Long Term Support (LTS) release, version 6.0.9 LTS l Feature release, version 6.9 The versions align with Safeguard for Privileged Sessions. For more information, see Long Term Support (LTS) and Feature Releases on page 13. About this release Safeguard for Privileged Passwords Version 6.0.9 LTS is a minor LTS release with resolved issues. For more details on the features and resolved issues, see: Safeguard for Privileged Passwords 6.0.9 LTS 1 Release Notes l Resolved issues NOTE: For a full list of key features in Safeguard for Privileged Passwords, see the Safeguard for Privileged Passwords Administration Guide. About the Safeguard product line The Safeguard for Privileged Passwords Appliance is built specifically for use only with the Safeguard for Privileged Passwords privileged management software, which is pre- installed and ready for immediate use. The appliance is hardened to ensure the system is secured at the hardware, operating system, and software levels. The hardened appliance approach protects the privileged management software from attacks while simplifying deployment and ongoing management and shortening the time frame to value. -

Efficient Parallel I/O on Multi-Core Architectures
Lecture series title/ lecture title Efficient parallel I/O on multi-core architectures Adrien Devresse CERN IT-SDC-ID Thematic CERN School of Computing 2014 1 Author(s) names – Affiliation Lecture series title/ lecture title How to make I/O bound application scale with multi-core ? What is an IO bound application ? → A server application → A job that accesses big number of files → An application that uses intensively network 2 Author(s) names – Affiliation Lecture series title/ lecture title Stupid example: Simple server monothreaded // create socket socket_desc = socket(AF_INET , SOCK_STREAM , 0); // bind the socket bind(socket_desc,(struct sockaddr *)&server , sizeof(server)); listen(socket_desc , 100); //accept connection from an incoming client while(1){ // declarations client_sock = accept(socket_desc, (struct sockaddr *)&client, &c); //Receive a message from client while( (read_size = recv(client_sock , client_message , 2000 , 0)) > 0{ // Wonderful, we have a client, do some useful work std::string msg("hello bob"); write(client_sock, msg.c_str(), msg.size()); } } 3 Author(s) names – Affiliation Lecture series title/ lecture title Stupid example: Let's make it parallel ! int main(int argc, char** argv){ // creat socket void do_work(int socket){ socket_desc = socket(AF_INET , SOCK_STREAM , 0); //Receive a message while( (read_size = // bind the socket recv(client_sock , bind(socket_desc, server , sizeof(server)); client_message , 2000 , 0)) > 0{ listen(socket_desc , 100); // Wonderful, we have a client // useful works //accept connection -

Message Passing and Network Programming
Message Passing and Network Programming Advanced Operating Systems Lecture 13 Colin Perkins | https://csperkins.org/ | Copyright © 2017 | This work is licensed under the Creative Commons Attribution-NoDerivatives 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nd/4.0/ or send a letter to Creative Commons, PO Box 1866, Mountain View, CA 94042, USA. Lecture Outline • Actors, sockets, and network protocols • Asynchronous I/O frameworks • Higher level abstractions Colin Perkins | https://csperkins.org/ | Copyright © 2017 2 Message Passing and Network Protocols • Recap: • Actor-based framework for message passing Send to • Each actor has a receive loop other actors Mailbox Actor Calls to one function per state Queue • Receive Message • Messages delivered by runtime system; Receiver processed sequentially Message Done Message Process • Actor can send messages in reply; Message Dispatcher return identity of next state Dequeue • Can we write network code this way? Request next • Send data by sending a message to an actor representing a socket • Receive messages representing data received on a socket Colin Perkins | https://csperkins.org/ | Copyright © 2017 3 Integrating Actors and Sockets Sending Thread Send to other actors Encoder Network Socket Mailbox Actor Queue Parser Receive Message Receiver Message Done Receiving Thread Message Process Message Dispatcher • Conceptually straightforward to integrate Dequeue actors with network code Request next • Runtime system maintains sending and -

Copyright by Tongliang Liao 2017
Copyright by Tongliang Liao 2017 The Thesis committee for Tongliang Liao certifies that this is the approved version of the following thesis: TAI: Threaded Asynchronous I/O Library for Performance and Portability APPROVED BY SUPERVISING COMMITTEE: Vijaychidambaram Velayudhan Pillai, Supervisor Simon Peter TAI: Threaded Asynchronous I/O Library for Performance and Portability by Tongliang Liao Thesis Presented to the Faculty of the Graduate School of the University of Texas at Austin in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science The University of Texas at Austin Dec 2017 TAI: Threaded Asynchronous I/O Library for Performance and Portability by Tongliang Liao, M.S.C.S The University of Texas at Austin, 2017 Supervisor: Vijaychidambaram Velayudhan Pillai In this paper, we investigate the behavior and performance of disk I/O using different types of libraries. We analyze the scenario where we can benefit from asyn- chronous I/O, and propose our cross-platform library design called TAI (Threaded Async I/O). TAI is designed to be a C++17 library with developer-friendly API. Our benchmark shows it can out-perform other libraries when asynchronous I/O is beneficial, and keep competitive speed in other cases. It also demonstrates TAI’s ability to retrieve 20% - 60% speedup on poorly scaled serial code by a simple library replacement. iv Table of Contents 1 Introduction 1 1.1 Related Work .................................................................................. 2 1.2 Background ..................................................................................... 2 1.2.1 POSIX Sync I/O ................................................................... 3 1.2.2 POSIX AIO .......................................................................... 3 1.2.3 C/C++ Standard I/O Functions............................................ -

A Sense of Time for Node.Js: Timeouts As a Cure for Event Handler Poisoning
A Sense of Time for Node.js: Timeouts as a Cure for Event Handler Poisoning Anonymous Abstract—The software development community has begun to new Denial of Service attack that can be used against EDA- adopt the Event-Driven Architecture (EDA) to provide scalable based services. Our Event Handler Poisoning attack exploits web services. Though the Event-Driven Architecture can offer the most important limited resource in the EDA: the Event better scalability than the One Thread Per Client Architecture, Handlers themselves. its use exposes service providers to a Denial of Service attack that we call Event Handler Poisoning (EHP). The source of the EDA’s scalability is also its Achilles’ heel. Multiplexing unrelated work onto the same thread re- This work is the first to define EHP attacks. After examining EHP vulnerabilities in the popular Node.js EDA framework and duces overhead, but it also moves the burden of time sharing open-source npm modules, we explore various solutions to EHP- out of the thread library or operating system and into the safety. For a practical defense against EHP attacks, we propose application itself. Where OTPCA-based services can rely on Node.cure, which defends a large class of Node.js applications preemptive multitasking to ensure that resources are shared against all known EHP attacks by making timeouts a first-class fairly, using the EDA requires the service to enforce its own member of the JavaScript language and the Node.js framework. cooperative multitasking [89]. An EHP attack identifies a way to defeat the cooperative multitasking used by an EDA-based Our evaluation shows that Node.cure is effective, broadly applicable, and offers strong security guarantees. -
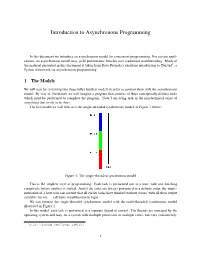
Introduction to Asynchronous Programming
Introduction to Asynchronous Programming In this document we introduce an asynchronous model for concurrent programming. For certain appli- cations, an asynchronous model may yield performance benefits over traditional multithreading. Much of the material presented in this document is taken from Dave Peticola’s excellent introduction to Twisted1, a Python framework for asynchronous programming. 1 The Models We will start by reviewing two (hopefully) familiar models in order to contrast them with the asynchronous model. By way of illustration we will imagine a program that consists of three conceptually distinct tasks which must be performed to complete the program. Note I am using task in the non-technical sense of something that needs to be done. The first model we will look at is the single-threaded synchronous model, in Figure 1 below: Figure 1: The single-threaded synchronous model This is the simplest style of programming. Each task is performed one at a time, with one finishing completely before another is started. And if the tasks are always performed in a definite order, the imple- mentation of a later task can assume that all earlier tasks have finished without errors, with all their output available for use — a definite simplification in logic. We can contrast the single-threaded synchronous model with the multi-threaded synchronous model illustrated in Figure 2. In this model, each task is performed in a separate thread of control. The threads are managed by the operating system and may, on a system with multiple processors or multiple cores, run truly concurrently, 1http://krondo.com/?page_id=1327 1 CS168 Async Programming Figure 2: The threaded model or may be interleaved together on a single processor. -

Memc3: Compact and Concurrent Memcache with Dumber Caching and Smarter Hashing
MemC3: Compact and Concurrent MemCache with Dumber Caching and Smarter Hashing Bin Fan, David G. Andersen, Michael Kaminsky∗ Carnegie Mellon University, ∗Intel Labs Abstract Standard Memcached, at its core, uses a typical hash table design, with linked-list-based chaining to handle This paper presents a set of architecturally and workload- collisions. Its cache replacement algorithm is strict LRU, inspired algorithmic and engineering improvements also based on linked lists. This design relies on locking to the popular Memcached system that substantially to ensure consistency among multiple threads, and leads improve both its memory efficiency and throughput. to poor scalability on multi-core CPUs [11]. These techniques—optimistic cuckoo hashing, a com- This paper presents MemC3 (Memcached with pact LRU-approximating eviction algorithm based upon CLOCK and Concurrent Cuckoo Hashing), a complete CLOCK, and comprehensive implementation of opti- redesign of the Memcached internals. This re-design mistic locking—enable the resulting system to use 30% is informed by and takes advantage of several observa- less memory for small key-value pairs, and serve up to tions. First, architectural features can hide memory access 3x as many queries per second over the network. We latencies and provide performance improvements. In par- have implemented these modifications in a system we ticular, our new hash table design exploits CPU cache call MemC3—Memcached with CLOCK and Concur- locality to minimize the number of memory fetches re- rent Cuckoo hashing—but believe that they also apply quired to complete any given operation; and it exploits more generally to many of today’s read-intensive, highly instruction-level and memory-level parallelism to overlap concurrent networked storage and caching systems.