A Systematic Evaluation of Coding Strategies for Sparse Binary Images ?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PDF/A for Scanned Documents
Webinar www.pdfa.org PDF/A for Scanned Documents Paper Becomes Digital Mark McKinney, LuraTech, Inc., President Armin Ortmann, LuraTech, CTO Mark McKinney President, LuraTech, Inc. © 2009 PDF/A Competence Center, www.pdfa.org Existing Solutions for Scanned Documents www.pdfa.org Black & White: TIFF G4 Color: Mostly JPEG, but sometimes PNG, BMP and other raster graphics formats Often special version formats like “JPEG in TIFF” Disadvantages: Several formats already for scanned documents Even more formats for born digital documents Loss of information, e.g. with TIFF G4 Bad image quality and huge file size, e.g. with JPEG No standardized metadata spread over all formats Not full text searchable (OCR) inside of files Black/White: Color: - TIFF FAX G4 - TIFF - TIFF LZW Mark McKinney - JPEG President, LuraTech, Inc. - PDF 2 Existing Solutions for Scanned Documents www.pdfa.org Bad image quality vs. file size TIFF/BMP JPEG TIFF G4 23.8 MB 180 kB 60 kB Mark McKinney President, LuraTech, Inc. 3 Alternative Solution: PDF www.pdfa.org PDF is already widely used to: Unify file formats Image à PDF “Office” Documents à PDF Other sources à PDF Create full-text searchable files Apply modern compression technology (e.g. the JPEG2000 file formats family) Harmonize metadata Conclusion: PDF avoids the disadvantages of the legacy formats “So if you are already using PDF as archival Mark McKinney format, why not use PDF/A with its many President, LuraTech, Inc. advantages?” 4 PDF/A www.pdfa.org What is PDF/A? • ISO 19005-1, Document Management • Electronic document file format for long-term preservation Goals of PDF/A: • Maintain static visual representation of documents • Consistent handing of Metadata • Option to maintain structure and semantic meaning of content • Transparency to guarantee access • Limit the number of restrictions Mark McKinney President, LuraTech, Inc. -

How to Exploit the Transferability of Learned Image Compression to Conventional Codecs
How to Exploit the Transferability of Learned Image Compression to Conventional Codecs Jan P. Klopp Keng-Chi Liu National Taiwan University Taiwan AI Labs [email protected] [email protected] Liang-Gee Chen Shao-Yi Chien National Taiwan University [email protected] [email protected] Abstract Lossy compression optimises the objective Lossy image compression is often limited by the sim- L = R + λD (1) plicity of the chosen loss measure. Recent research sug- gests that generative adversarial networks have the ability where R and D stand for rate and distortion, respectively, to overcome this limitation and serve as a multi-modal loss, and λ controls their weight relative to each other. In prac- especially for textures. Together with learned image com- tice, computational efficiency is another constraint as at pression, these two techniques can be used to great effect least the decoder needs to process high resolutions in real- when relaxing the commonly employed tight measures of time under a limited power envelope, typically necessitating distortion. However, convolutional neural network-based dedicated hardware implementations. Requirements for the algorithms have a large computational footprint. Ideally, encoder are more relaxed, often allowing even offline en- an existing conventional codec should stay in place, ensur- coding without demanding real-time capability. ing faster adoption and adherence to a balanced computa- Recent research has developed along two lines: evolu- tional envelope. tion of exiting coding technologies, such as H264 [41] or As a possible avenue to this goal, we propose and investi- H265 [35], culminating in the most recent AV1 codec, on gate how learned image coding can be used as a surrogate the one hand. -

Lossless Data Compression with Transformer
Under review as a conference paper at ICLR 2020 LOSSLESS DATA COMPRESSION WITH TRANSFORMER Anonymous authors Paper under double-blind review ABSTRACT Transformers have replaced long-short term memory and other recurrent neural networks variants in sequence modeling. It achieves state-of-the-art performance on a wide range of tasks related to natural language processing, including lan- guage modeling, machine translation, and sentence representation. Lossless com- pression is another problem that can benefit from better sequence models. It is closely related to the problem of online learning of language models. But, despite this ressemblance, it is an area where purely neural network based methods have not yet reached the compression ratio of state-of-the-art algorithms. In this paper, we propose a Transformer based lossless compression method that match the best compression ratio for text. Our approach is purely based on neural networks and does not rely on hand-crafted features as other lossless compression algorithms. We also provide a thorough study of the impact of the different components of the Transformer and its training on the compression ratio. 1 INTRODUCTION Lossless compression is a class of compression algorithms that allows for the perfect reconstruc- tion of the original data. In the last decades, statistical methods for lossless compression have been dominated by PAQ-type approaches (Mahoney, 2005). The structure of these approaches is similar to the Prediction by Partial Matching (PPM) of Cleary & Witten (1984) and are composed of two separated parts: a predictor and an entropy encoding. Entropy coding scheme like arithmetic cod- ing (Rissanen & Langdon, 1979) are optimal and most of the compression gains are coming from improving the predictor. -

Chapter 9 Image Compression Standards
Fundamentals of Multimedia, Chapter 9 Chapter 9 Image Compression Standards 9.1 The JPEG Standard 9.2 The JPEG2000 Standard 9.3 The JPEG-LS Standard 9.4 Bi-level Image Compression Standards 9.5 Further Exploration 1 Li & Drew c Prentice Hall 2003 ! Fundamentals of Multimedia, Chapter 9 9.1 The JPEG Standard JPEG is an image compression standard that was developed • by the “Joint Photographic Experts Group”. JPEG was for- mally accepted as an international standard in 1992. JPEG is a lossy image compression method. It employs a • transform coding method using the DCT (Discrete Cosine Transform). An image is a function of i and j (or conventionally x and y) • in the spatial domain. The 2D DCT is used as one step in JPEG in order to yield a frequency response which is a function F (u, v) in the spatial frequency domain, indexed by two integers u and v. 2 Li & Drew c Prentice Hall 2003 ! Fundamentals of Multimedia, Chapter 9 Observations for JPEG Image Compression The effectiveness of the DCT transform coding method in • JPEG relies on 3 major observations: Observation 1: Useful image contents change relatively slowly across the image, i.e., it is unusual for intensity values to vary widely several times in a small area, for example, within an 8 8 × image block. much of the information in an image is repeated, hence “spa- • tial redundancy”. 3 Li & Drew c Prentice Hall 2003 ! Fundamentals of Multimedia, Chapter 9 Observations for JPEG Image Compression (cont’d) Observation 2: Psychophysical experiments suggest that hu- mans are much less likely to notice the loss of very high spatial frequency components than the loss of lower frequency compo- nents. -

Electronics Engineering
INTERNATIONAL JOURNAL OF ELECTRONICS ENGINEERING ISSN : 0973-7383 Volume 11 • Number 1 • 2019 Study of Different Image File formats for Raster images Prof. S. S. Thakare1, Prof. Dr. S. N. Kale2 1Assistant professor, GCOEA, Amravati, India, [email protected] 2Assistant professor, SGBAU,Amaravti,India, [email protected] Abstract: In the current digital world, the usage of images are very high. The development of multimedia and digital imaging requires very large disk space for storage and very long bandwidth of network for transmission. As these two are relatively expensive, Image compression is required to represent a digital image yielding compact representation of image without affecting its essential information with reducing transmission time. This paper attempts compression in some of the image representation formats and the experimental results for some image file format are also shown. Keywords: ImageFileFormats, JPEG, PNG, TIFF, BITMAP, GIF,CompressionTechniques,Compressed image processing. 1. INTRODUCTION Digital images generally occupy a large amount of storage space and therefore take longer time to transmit and download (Sayood 2012;Salomonetal 2010;Miano 1999). To reduce this time image compression is necessary. Image compression is a technique used to identify internal data redundancy and then develop a compact representation that takes up less storage space than the original image size and the reverse process is called decompression (Javed 2016; Kia 1997). There are two types of image compression (Gonzalez and Woods 2009). 1. Lossy image compression 2. Lossless image compression In case of lossy compression techniques, it removes some part of data, so it is used when a perfect consistency with the original data is not necessary after decompression. -

Image Compression Using Discrete Cosine Transform Method
Qusay Kanaan Kadhim, International Journal of Computer Science and Mobile Computing, Vol.5 Issue.9, September- 2016, pg. 186-192 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320–088X IMPACT FACTOR: 5.258 IJCSMC, Vol. 5, Issue. 9, September 2016, pg.186 – 192 Image Compression Using Discrete Cosine Transform Method Qusay Kanaan Kadhim Al-Yarmook University College / Computer Science Department, Iraq [email protected] ABSTRACT: The processing of digital images took a wide importance in the knowledge field in the last decades ago due to the rapid development in the communication techniques and the need to find and develop methods assist in enhancing and exploiting the image information. The field of digital images compression becomes an important field of digital images processing fields due to the need to exploit the available storage space as much as possible and reduce the time required to transmit the image. Baseline JPEG Standard technique is used in compression of images with 8-bit color depth. Basically, this scheme consists of seven operations which are the sampling, the partitioning, the transform, the quantization, the entropy coding and Huffman coding. First, the sampling process is used to reduce the size of the image and the number bits required to represent it. Next, the partitioning process is applied to the image to get (8×8) image block. Then, the discrete cosine transform is used to transform the image block data from spatial domain to frequency domain to make the data easy to process. -

Task-Aware Quantization Network for JPEG Image Compression
Task-Aware Quantization Network for JPEG Image Compression Jinyoung Choi1 and Bohyung Han1 Dept. of ECE & ASRI, Seoul National University, Korea fjin0.choi,[email protected] Abstract. We propose to learn a deep neural network for JPEG im- age compression, which predicts image-specific optimized quantization tables fully compatible with the standard JPEG encoder and decoder. Moreover, our approach provides the capability to learn task-specific quantization tables in a principled way by adjusting the objective func- tion of the network. The main challenge to realize this idea is that there exist non-differentiable components in the encoder such as run-length encoding and Huffman coding and it is not straightforward to predict the probability distribution of the quantized image representations. We address these issues by learning a differentiable loss function that approx- imates bitrates using simple network blocks|two MLPs and an LSTM. We evaluate the proposed algorithm using multiple task-specific losses| two for semantic image understanding and another two for conventional image compression|and demonstrate the effectiveness of our approach to the individual tasks. Keywords: JPEG image compression, adaptive quantization, bitrate approximation. 1 Introduction Image compression is a classical task to reduce the file size of an input image while minimizing the loss of visual quality. This task has two categories|lossy and lossless compression. Lossless compression algorithms preserve the contents of input images perfectly even after compression, but their compression rates are typically low. On the other hand, lossy compression techniques allow the degra- dation of the original images by quantization and reduce the file size significantly compared to lossless counterparts. -

Chapter 2 HISTORY and DEVELOPMENT of MILITARY LASERS
History and Development of Military Lasers Chapter 2 HISTORY AND DEVELOPMENT OF MILITARY LASERS JACK B. KELLER, JR* INTRODUCTION INVENTING THE LASER MILITARIZING THE LASER SEARCHING FOR HIGH-ENERGY LASER WEAPONS SEARCHING FOR LOW-ENERGY LASER WEAPONS RETURNING TO HIGHER ENERGIES SUMMARY *Lieutenant Colonel, US Army (Retired); formerly, Foreign Science Information Officer, US Army Medical Research Detachment-Walter Reed Army Institute of Research, 7965 Dave Erwin Drive, Brooks City-Base, Texas 78235 25 Biomedical Implications of Military Laser Exposure INTRODUCTION This chapter will examine the history of the laser, Military advantage is greatest when details are con- from theory to demonstration, for its impact upon the US cealed from real or potential adversaries (eg, through military. In the field of military science, there was early classification). Classification can remain in place long recognition that lasers can be visually and cutaneously after a program is aborted, if warranted to conceal hazardous to military personnel—hazards documented technological details or pathways not obvious or easily in detail elsewhere in this volume—and that such hazards deduced but that may be relevant to future develop- must be mitigated to ensure military personnel safety ments. Thus, many details regarding developmental and mission success. At odds with this recognition was military laser systems cannot be made public; their the desire to harness the laser’s potential application to a descriptions here are necessarily vague. wide spectrum of military tasks. This chapter focuses on Once fielded, system details usually, but not always, the history and development of laser systems that, when become public. Laser systems identified here represent used, necessitate highly specialized biomedical research various evolutionary states of the art in laser technol- as described throughout this volume. -

JPEG and JPEG 2000
JPEG and JPEG 2000 Past, present, and future Richard Clark Elysium Ltd, Crowborough, UK [email protected] Planned presentation Brief introduction JPEG – 25 years of standards… Shortfalls and issues Why JPEG 2000? JPEG 2000 – imaging architecture JPEG 2000 – what it is (should be!) Current activities New and continuing work… +44 1892 667411 - [email protected] Introductions Richard Clark – Working in technical standardisation since early 70’s – Fax, email, character coding (8859-1 is basis of HTML), image coding, multimedia – Elysium, set up in ’91 as SME innovator on the Web – Currently looks after JPEG web site, historical archive, some PR, some standards as editor (extensions to JPEG, JPEG-LS, MIME type RFC and software reference for JPEG 2000), HD Photo in JPEG, and the UK MPEG and JPEG committees – Plus some work that is actually funded……. +44 1892 667411 - [email protected] Elysium in Europe ACTS project – SPEAR – advanced JPEG tools ESPRIT project – Eurostill – consensus building on JPEG 2000 IST – Migrator 2000 – tool migration and feature exploitation of JPEG 2000 – 2KAN – JPEG 2000 advanced networking Plus some other involvement through CEN in cultural heritage and medical imaging, Interreg and others +44 1892 667411 - [email protected] 25 years of standards JPEG – Joint Photographic Experts Group, joint venture between ISO and CCITT (now ITU-T) Evolved from photo-videotex, character coding First meeting March 83 – JPEG proper started in July 86. 42nd meeting in Lausanne, next week… Attendance through national -
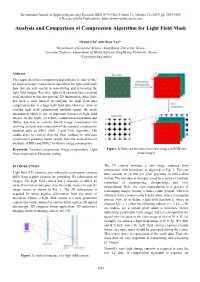
Analysis and Comparison of Compression Algorithm for Light Field Mask
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 12, Number 12 (2017) pp. 3553-3556 © Research India Publications. http://www.ripublication.com Analysis and Comparison of Compression Algorithm for Light Field Mask Hyunji Cho1 and Hoon Yoo2* 1Department of Computer Science, SangMyung University, Korea. 2Associate Professor, Department of Media Software SangMyung University, Korea. *Corresponding author Abstract This paper describes comparison and analysis of state-of-the- art lossless image compression algorithms for light field mask data that are very useful in transmitting and refocusing the light field images. Recently, light field cameras have received wide attention in that they provide 3D information. Also, there has been a wide interest in studying the light field data compression due to a huge light field data. However, most of existing light field compression methods ignore the mask information which is one of important features of light field images. In this paper, we reports compression algorithms and further use this to achieve binary image compression by realizing analysis and comparison of the standard compression methods such as JBIG, JBIG 2 and PNG algorithm. The results seem to confirm that the PNG method for text data compression provides better results than the state-of-the-art methods of JBIG and JBIG2 for binary image compression. Keywords: Lossless compression, Image compression, Light Figure. 2. Basic architecture from raw images to RGB and filed compression, Plenoptic coding mask images INTRODUCTION The LF camera provides a raw image captured from photosensor with microlens, as depicted in Fig. 1. The raw Light field (LF) cameras, also referred to as plenoptic cameras, data consists of 10 bits per pixel precision in little-endian differ from regular cameras by providing 3D information of format. -

Mcgraw-Hill New York Chicago San Francisco Lisbon London Madrid Mexico City Milan New Delhi San Juan Seoul Singapore Sydney Toronto Mcgraw-Hill Abc
Y L F M A E T Team-Fly® Streaming Media Demystified Michael Topic McGraw-Hill New York Chicago San Francisco Lisbon London Madrid Mexico City Milan New Delhi San Juan Seoul Singapore Sydney Toronto McGraw-Hill abc Copyright © 2002 by The McGraw-Hill Companies, Inc. All rights reserved. Manufactured in the United States of America. Except as permitted under the United States Copyright Act of 1976, no part of this publication may be reproduced or distrib- uted in any form or by any means, or stored in a database or retrieval system, without the prior written permission of the publisher. 0-07-140962-9 The material in this eBook also appears in the print version of this title: 0-07-138877-X. All trademarks are trademarks of their respective owners. Rather than put a trademark symbol after every occurrence of a trademarked name, we use names in an editorial fashion only, and to the benefit of the trademark owner, with no intention of infringement of the trademark. Where such designations appear in this book, they have been printed with initial caps. McGraw-Hill eBooks are available at special quantity discounts to use as premiums and sales promotions, or for use in cor- porate training programs. For more information, please contact George Hoare, Special Sales, at george_hoare@mcgraw- hill.com or (212) 904-4069. TERMS OF USE This is a copyrighted work and The McGraw-Hill Companies, Inc. (“McGraw-Hill”) and its licensors reserve all rights in and to the work. Use of this work is subject to these terms. -

Why Compression Matters
Computational thinking for digital technologies: Snapshot 2 PROGRESS OUTCOME 6 Why compression matters Context Sarah has been investigating the concept of compression coding, by looking at the different ways images can be compressed and the trade-offs of using different methods of compression in relation to the size and quality of images. She researches the topic by doing several web searches and produces a report with her findings. Insight 1: Reasons for compressing files I realised that data compression is extremely useful as it reduces the amount of space needed to store files. Computers and storage devices have limited space, so using smaller files allows you to store more files. Compressed files also download more quickly, which saves time – and money, because you pay less for electricity and bandwidth. Compression is also important in terms of HCI (human-computer interaction), because if images or videos are not compressed they take longer to download and, rather than waiting, many users will move on to another website. Insight 2: Representing images in an uncompressed form Most people don’t realise that a computer image is made up of tiny dots of colour, called pixels (short for “picture elements”). Each pixel has components of red, green and blue light and is represented by a binary number. The more bits used to represent each component, the greater the depth of colour in your image. For example, if red is represented by 8 bits, green by 8 bits and blue by 8 bits, 16,777,216 different colours can be represented, as shown below: 8 bits corresponds to 256 possible numbers in binary red x green x blue = 256 x 256 x 256 = 16,777,216 possible colour combinations 1 Insight 3: Lossy compression and human perception There are many different formats for file compression such as JPEG (image compression), MP3 (audio compression) and MPEG (audio and video compression).