Automated Discovery of Lead Users and Latent Product Features By
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(12) United States Patent (10) Patent N0.: US 8,836,842 B2 Sirpal Et A1
US008836842B2 (12) United States Patent (10) Patent N0.: US 8,836,842 B2 Sirpal et a1. (45) Date of Patent: *Sep. 16, 2014 (54) CAPTURE MODE OUTWARD FACING H05K5/04 (2013.01); G06F1/1641(2013.01); MODES G06F 3/04883 (2013.01); H05K 13/00 Applicant: Z124, George Town (KY) (2013.01); B29D 11/00673 (2013.01); G06F (71) 1/1637(2013.01); G09G 5/34 (2013.01); G09G (72) Inventors: Sanjiv Sirpal, Oakville (CA); 1/00 (2013.01); G06T3/00 (2013.01); G06F Mohammed Selim, Oakville (CA); 3/1423 (2013.01); G06F 3/0412 (2013.01); John S. Visosky, Gormley (CA) G09G 5/00 (2013.01); G06F 3/01 (2013.01); (73) Assignee: Z124, George Town (KY) G06F 3/048 (2013.01) USPC ............................... .. 348/333.06; 348/333.05 ( * ) Notice: Subject to any disclaimer, the term of this Field of Classi?cation Search patent is extended or adjusted under 35 (58) U.S.C. 154(b) by 41 days. CPC ................................................ .. H04N 5/23293 USPC ...................................... .. 34863301433313 This patent is subject to a terminal dis See application ?le for complete search history. claimer. (56) References Cited App1.No.: 13/627,498 (21) U.S. PATENT DOCUMENTS Filed: Sep. 26, 2012 (22) 5,982,429 A * 11/1999 Kamamoto etal. 348/333.06 6,188,432 B1* 2/2001 Ejima .................... .. 348/240.99 (65) Prior Publication Data (Continued) US 2013/0076929 A1 Mar. 28, 2013 OTHER PUBLICATIONS Related US. Application Data Google Image Result for Fujitsu Dual Screen Phone, published date (60) Provisional application No. 61/539,884, ?led on Sep. unknown, [retrieved Apr. -
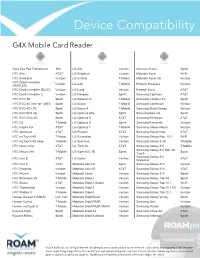
Device Compaibility List
Device Compatibility G4X Mobile Card Reader Asus Eee Pad Transformer N/A LG Ally Verizon Motorola Photon Sprint HTC Aria AT&T LG Enlighten Verizon Motorola Xoom Wi-Fi HTC Droid Eris Verizon LG G-Slate T-Mobile Motorola Xoom 4G Verizon HTC Droid Incredible Verizon LG G2X T-Mobile Pantech Breakout Verizon (AMOLED) HTC Droid Incredible (SLCD) Verizon LG Lucid Verizon Pantech Burst AT&T HTC Droid Incredible 2 Verizon LG Marquee Sprint Samsung Captivate AT&T HTC EVO 3D Sprint LG Mytouch Q T-Mobile Samsung Conquer 4G Sprint HTC EVO 4G (h/w ver. 0003) Sprint LG Nexus T-Mobile Samsung Continuum Verizon HTC EVO 4G LTE Sprint LG Nexus 4 T-Mobile Samsung Droid Charge Verizon HTC EVO Shift 4G Sprint LG Optimus Elite Sprint Samsung Epic 4G Sprint HTC EVO View 4G Sprint LG Optimus G AT&T Samsung Exhilarate AT&T HTC G2 T-Mobile LG Optimus S Sprint Samsung Fascinate Verizon HTC Inspire 4G AT&T LG Optimus T T-Mobile Samsung Galaxy Nexus Verizon HTC Jetstream AT&T LG Phoenix AT&T Samsung Galaxy Note AT&T HTC myTouch 4G T-Mobile LG Revolution Verizon Samsung Galaxy Note 10.1 Wi-Fi HTC myTouch 4G Slide T-Mobile LG Spectrum Verizon Samsung Galaxy S 4G T-Mobile HTC Nexus One AT&T LG Thrill 4G AT&T Samsung Galaxy S II T-Mobile Samsung Galaxy S II Epic 4G HTC Nexus One T-Mobile LG Viper 4G LTE Sprint Sprint Touch Samsung Galaxy S II HTC One S AT&T LG Vortex Verizon AT&T Skyrocket HTC One X AT&T Motorola Admiral Sprint Samsung Galaxy S III Verizon HTC Rezound Verizon Motorola Atrix 4G AT&T Samsung Galaxy S III AT&T HTC Rhyme Verizon Motorola Citrus Verizon Samsung Galaxy S III Sprint HTC Sensation 4G T-Mobile Motorola Droid 2 Verizon Samsung Galaxy Tab 3G Sprint HTC Status AT&T Motorola Droid 2 Global Verizon Samsung Galaxy Tab 10.1 Wi-Fi HTC Thunderbolt Verizon Motorola Droid 3 Verizon Samsung Galaxy Tab 10.1 4G Verizon HTC Wildfire S T-Mobile Motorola Droid 4 Verizon Samsung Galaxy Tab 10.1 Verizon Huawei Ascend II (M865) U.S. -

A Maneira Mais Prática E Simples De Você Receber Pagamentos Com
A maneira mais prática e simples de você receber pagamentos com cartões de débito e crédito usando seu smartphone ou tablet. Confira os equipamentos compatíveis. Página | 1 Atenção: A compatibilidade de um equipamento com o Vero Mobile não garante que sua versão Dual Chip do celular seja igualmente compatível. Havendo compatibilidade, o aparelho estará listado com essa informação. Modelo smartphone/tablet Status Acer Liquid E (Android 2.2) NÃO COMPATÍVEL Alcatel Onetouch EVO 7 NÃO COMPATÍVEL Asus Transformer (Android 4.0.3) COMPATÍVEL BLU Life Play 2 (Android 4.4.2) NÃO COMPATÍVEL HTC ADR6425LVW (Android 4.0.3) NÃO COMPATÍVEL HTC Droid Incredible 4G LTE (Android 4.0.4) NÃO COMPATÍVEL HTC Evo 3D (Android 4.0.3) COMPATÍVEL HTC Evo 4G LTE (Android 4.1.1) COMPATÍVEL HTC Incredible 2 (Android 2.3.4) NÃO COMPATÍVEL HTC One S (Android 4.1.1) NÃO COMPATÍVEL HTC One X (Android 4.1.1) COMPATÍVEL HTC One X Plus (Android 4.1.1) NÃO COMPATÍVEL Huawei MyTouch (Android 2.3.6) COMPATÍVEL iPhone 4 (IOS 7.1 ou superior) COMPATÍVEL iPhone 4s (IOS 7.1 ou superior) COMPATÍVEL iPhone 5 (IOS 7.1 ou superior) COMPATÍVEL iPhone 5c (IOS 7.1 ou superior) COMPATÍVEL iPhone 5s (IOS 7.1 ou superior) COMPATÍVEL iPhone 6 (IOS 7.1 ou superior) COMPATÍVEL iPhone 6 Plus (IOS 7.1 ou superior) COMPATÍVEL iPad (IOS 7.1 ou superior) COMPATÍVEL iPod Touch COMPATÍVEL Kyocera Echo (Android 4.0.4) COMPATÍVEL Kyocera Rise (Android 4.0.4) COMPATÍVEL LG Duos e615F (Android) NÃO COMPATÍVEL LG e435 (Android) NÃO COMPATÍVEL LG e465F (Android) NÃO COMPATÍVEL LG G2 (Android) COMPATÍVEL -

Supported Android Devices AT&T KDDI Minor Carriers / Other
AT&T Appendix Acer Iconia Tab A501 (A501) A – HTC Aria (LIBERTY) Supported HTC Lele (HTCPH06130) Android HTC Nexus One (NEXUSONE) HTC One VX (HTCPM36100) Devices HTC One X (HTCONEX) HTC Status (HTCSTATUS) HTC Vivid (HTCPH39100) Huawei Impulse 4G (HUAWEIU8800-51) LG Eclipse (LG-E970) LG Escape 4G (LG-P870) LG Nitro HD (LG-P930) LG Phoenix (LG-P505) LG Thrill 3D (LG-P925) LG Thrive (LG-P506) Motorola Atrix 2 (MB865) Motorola Atrix 3 (MB886) Motorola Bravo MB520 (MB520) Motorola FlipSide (MB508) Pantech Crossover (PANTECHP8000) Samsung Captivate (SAMSUNG-SGH-I897) Samsung Captivate Glide (SAMSUNG-SGH-I927) Samsung Galaxy Express (SAMSUNG-SGH-I437) Samsung Galaxy Note (SAMSUNG-SGH-I717) Samsung Galaxy Note II (SGH-I317) Samsung Galaxy Rugby Pro (SAMSUNG-SGH-I547) Samsung Galaxy S II (SAMSUNG-SGH-I777) Samsung Galaxy S III (SAMSUNG-SGH-I747) Samsung Galaxy S4 (SAMSUNG-SGH-I337) Samsung Galaxy Tab 8.9 (SGH-I957) Samsung Galaxy Tab 8.9 (SAMSUNG-SGH-I957) Samsung Rugby (SAMSUNG-SGH-I847) Samsung SkyRocket (SAMSUNG-SGH-I727) Sony Xperia T (LT30AT) KDDI HTC EVO 3D (ISW12HT) Minor Carriers / Other* LG Nexus 4 (NEXUS4) LG Optimus One (LG-P500) Motorola RAZR i (XT890) Samsung Galaxy Ace (GT-S5830) Samsung Galaxy SII LTE (SGH-I727R) Samsung Galaxy S III (GT-I9300) * Other denotes a device that is not officially carried by a network and is usually purchased unlocked. 1 Version 15 Sprint HTC EVO 3D (PG86100) HTC EVO 4G (PC36100) HTC EVO 4G LTE (EVO) HTC EVO Shift 4G (PG06100) HTC EVO View 4G (PG41200) HTC Hero (HERO200) HTC One (HTCONE) Kyocera ECHO -

Dual-Screen Kyocera Smartphone Needs Work 21 April 2011, by RACHEL METZ , AP Technology Writer
Review: Dual-screen Kyocera smartphone needs work 21 April 2011, By RACHEL METZ , AP Technology Writer distracting black bar bisecting the two screens when they're side by side. It's nearly impossible to watch videos or view photos across the displays without staring at the dark line running down the middle. And if you turn the phone so the screen is split horizontally, you'll only be watching a video on the top screen. The rest of the phone's design could also use some work. It's nearly as thick as two iPhones stacked on top of each other, and it's much heavier than an An Associated Press reporter browses a webpage on a iPhone. This girth, combined with its rectangular Kyocera Echo smart phone during a product review in shape, makes the Echo look dated. San Francisco, Monday, April 18, 2011. (AP Photo/Jeff Chiu) Then there's the hinge. To reveal the second screen, you must slide the first screen to the right and push it down. You can then tilt it upward or, if you want to have one big screen, slide it slightly From emailing to Web surfing to taking photos, a back to the left to lock it into place. The whole smartphone can be a multitasker's best friend - process felt too clunky, and I kept worrying I would unless all the tasks are making the screen feel too break the hinge. small. Wouldn't it be nice to have a second screen? And expect to use your Echo as, well, a phone - not just because calls sound decent, but because it The Kyocera Echo, a new Android smartphone drains battery quickly when used for Web surfing sold by Sprint, brings that neat idea to life. -

Company Vendor ID (Decimal Format) (AVL) Ditest Fahrzeugdiagnose Gmbh 4621 @Pos.Com 3765 0XF8 Limited 10737 1MORE INC
Vendor ID Company (Decimal Format) (AVL) DiTEST Fahrzeugdiagnose GmbH 4621 @pos.com 3765 0XF8 Limited 10737 1MORE INC. 12048 360fly, Inc. 11161 3C TEK CORP. 9397 3D Imaging & Simulations Corp. (3DISC) 11190 3D Systems Corporation 10632 3DRUDDER 11770 3eYamaichi Electronics Co., Ltd. 8709 3M Cogent, Inc. 7717 3M Scott 8463 3T B.V. 11721 4iiii Innovations Inc. 10009 4Links Limited 10728 4MOD Technology 10244 64seconds, Inc. 12215 77 Elektronika Kft. 11175 89 North, Inc. 12070 Shenzhen 8Bitdo Tech Co., Ltd. 11720 90meter Solutions, Inc. 12086 A‐FOUR TECH CO., LTD. 2522 A‐One Co., Ltd. 10116 A‐Tec Subsystem, Inc. 2164 A‐VEKT K.K. 11459 A. Eberle GmbH & Co. KG 6910 a.tron3d GmbH 9965 A&T Corporation 11849 Aaronia AG 12146 abatec group AG 10371 ABB India Limited 11250 ABILITY ENTERPRISE CO., LTD. 5145 Abionic SA 12412 AbleNet Inc. 8262 Ableton AG 10626 ABOV Semiconductor Co., Ltd. 6697 Absolute USA 10972 AcBel Polytech Inc. 12335 Access Network Technology Limited 10568 ACCUCOMM, INC. 10219 Accumetrics Associates, Inc. 10392 Accusys, Inc. 5055 Ace Karaoke Corp. 8799 ACELLA 8758 Acer, Inc. 1282 Aces Electronics Co., Ltd. 7347 Aclima Inc. 10273 ACON, Advanced‐Connectek, Inc. 1314 Acoustic Arc Technology Holding Limited 12353 ACR Braendli & Voegeli AG 11152 Acromag Inc. 9855 Acroname Inc. 9471 Action Industries (M) SDN BHD 11715 Action Star Technology Co., Ltd. 2101 Actions Microelectronics Co., Ltd. 7649 Actions Semiconductor Co., Ltd. 4310 Active Mind Technology 10505 Qorvo, Inc 11744 Activision 5168 Acute Technology Inc. 10876 Adam Tech 5437 Adapt‐IP Company 10990 Adaptertek Technology Co., Ltd. 11329 ADATA Technology Co., Ltd. -

(12) United States Patent (10) Patent No.: US 9.235,374 B2 Sirpal Et Al
US009235374B2 (12) United States Patent (10) Patent No.: US 9.235,374 B2 Sirpal et al. (45) Date of Patent: Jan. 12, 2016 (54) SMARTPAD IDUAL SCREEN KEYBOARD (58) Field of Classification Search WITH CONTEXTUAL LAYOUT USPC .......................................... 345/169, 173-179 See application file for complete search history. Applicant: Z124, Grand Cayman (KY) (71) (56) References Cited (72) Inventors: Sanjiv Sirpal, Oakville (CA); Martin Gimpl. Helsinki (FI) U.S. PATENT DOCUMENTS 3,704.950 A 12, 1972 Rosencranz (73) Assignee: Z124, George Town (KY) 6,021,269 A 2/2000 Lewis (Continued) (*) Notice: Subject to any disclaimer, the term of this patent is extended or adjusted under 35 FOREIGN PATENT DOCUMENTS U.S.C. 154(b) by 76 days. CN 1896946 1, 2007 (21) Appl. No.: 13/627,191 CN 10.1038737 9, 2007 (Continued) (22) Filed: Sep. 26, 2012 OTHER PUBLICATIONS (65) Prior Publication Data Official Action for U.S. Appl. No. 13/247,581, mailed Sep. 27, 2013 US 2013 FOOT6638A1 Mar. 28, 2013 101 pages. (Continued) Related U.S. Application Data Primary Examiner — Waseem Moorad (60) Provisional application No. 61/539,884, filed on Sep. Assistant Examiner — Sujit Shah 27, 2011. (74) Attorney, Agent, or Firm — Sheridan Ross P.C. (57) ABSTRACT (51) Int. C. G06F 3/4 (2006.01) A multi-display device is adapted to be dockable or otherwise G06F L/I6 (2006.01) associatable with an additional device. In accordance with one exemplary embodiment, the multi-display device is (Continued) dockable with a Smartpad. The exemplary Smartpad can (52) U.S. C. include a screen, a touch sensitive display, a configurable CPC ....... -

Advantage Cartridge Cell Phone Price List Effective 2-1-12 Click Here to See Shipping Instructions
Advantage Cartridge Cell Phone Price List Effective 2-1-12 Click here to see Shipping Instructions We pay .25 for all cell phones not on this list, as well as damaged phones unless a higher price is listed below. • Broken cell phones do not qualify for payment. A phone is considered broken when it is in pieces • Damaged phones are phones with broken screen, water damage, and does not power up. ALCATEL A800 $ 0.30 ALCATEL A808 $ 0.30 APPLE iPhone 2G $ 25.00 APPLE iPhone 2G Damage $ 5.00 APPLE iPhone 2G $ 25.00 APPLE iPhone 3G 16GB Damage $ 10.00 APPLE iPhone 3G 16GB $ 50.00 APPLE iPhone 3G 8GB Damage $ 8.00 APPLE iPhone 3G 8GB $ 40.00 APPLE iPhone 3GS 16GB Damage $ 25.00 APPLE iPhone 3GS 16GB $ 125.00 APPLE iPhone 3GS 32GB Damage $ 30.00 APPLE iPhone 3GS 32GB $ 150.00 APPLE iPhone 3GS 8GB Damage $ 18.00 APPLE iPhone 3GS 8GB $ 90.00 APPLE iPhone 4C 16GB Damage $ 30.00 APPLE iPhone 4C 16GB $ 150.00 APPLE iPhone 4C 32GB Damage $ 35.00 APPLE iPhone 4C 32GB $ 175.00 APPLE iPhone 4G 16GB Damage $ 30.00 APPLE iPhone 4G 16GB $ 150.00 APPLE iPhone 4G 32GB Damage $ 35.00 APPLE iPhone 4G 32GB $ 175.00 APPLE iPhone 4S 16GB Damage $ 40.00 APPLE iPhone 4S 16GB $ 200.00 APPLE iPhone 4S 32GB Damage $ 60.00 APPLE iPhone 4S 32GB $ 300.00 BLACKBERRY 6210 $ 0.30 BLACKBERRY 6230 $ 0.30 BLACKBERRY 6280 $ 0.30 BLACKBERRY 7100R $ 0.30 BLACKBERRY 7100T $ 0.30 BLACKBERRY 7100V $ 0.30 BLACKBERRY 7100X $ 0.30 BLACKBERRY 7105T $ 0.30 BLACKBERRY 7130C $ 0.30 BLACKBERRY 7130G $ 0.30 BLACKBERRY 7130V $ 0.30 BLACKBERRY 7270 $ 0.30 BLACKBERRY 7290 $ 1.50 BLACKBERRY 7510 -

One Firmware to Monitor
One firmware to monitor 'em all. Andr´esBlanco Matias Eissler Core Security Technologies August 23, 2012 Abstract In the last years mobile devices usage has turned massive. These de- vices, in general, follow the IEEE 802.11 standard for wireless connectivity. Broadcom is one of the most important semiconductor companies in the wireless and broadband communication business. Some of their WiFi so- lutions (BCM4325 & BCM4329 chipsets) are included in great part of the mobile devices market, including vendors like Apple, Samsung, Motorola, Sony, Nokia, LG, Asus and HTC. In this paper we describe the process of modification of the firmware program on these cards. The presented results could open new possibilities to the information security commu- nity such as access to baseband components without intervention of the operating system and the capabilities to store information within the net- work card's internal memory among others. As the reader explores the present work we go through the internals of the firmware program, our reverse engineering process and show, as a proof of concept, how to set these cards on monitor mode. 1 Introduction Operating systems provide security by means of layered sets of levels of trust. However peripheral's firmware program code is executed on a separate physical CPU, with its own internal memory, thus firmware program has access to the system hardware without involving the operating system. Code executed with this access level has, regarding hardware interaction, higher privileges than those of an \administrator" or \root" user. Such access level can be obtained on most mobile devices, by simple modifications of unprotected (i.e. -
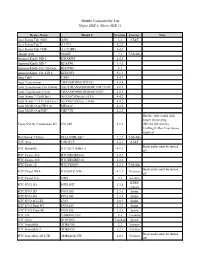
Shuttle Compatibility List Major SDK 5, Minor SDK 13
Shuttle Compatibility List Major SDK 5, Minor SDK 13 Device Name Model # Version Carrier Note Acer Iconia Tab A501 A501 3.2 AT&T Acer Iconia Tab 7 A1-713 4.2.2 Acer Iconia Tab 7 HD A1-713HD 4.4.2 Alcatel A30 9024W 7.1 T-Mobile Amazon Kindle HD 6 KWARWI 4.4.3 Amazon Kindle HD 7 KFASWI 4.4.3 Amazon Kindle Fire 5th Gen. KFFOWI 5.1 Amazon Kindle Fire HD 8 KFDOWI 5.1.1 Alps Tab9 TAB9 4.4.2 Asus Transformer TRANSFORMERTF101 4.0.4 Asus Transformer Pad Infinity ASUSTRANSFORMERPADTF700T 4.0.3 Asus Transformer Prime TRANSFORMERPRIMETF201 4.0.3 Asus Nexus 7 (2nd Gen.) NEXUS7 (Device: FLO) 4.4.2 Asus Nexus 7 LTE (2nd Gen.) NEXUS7 (Device: DEB) 4.4.2 Asus MeMO Pad FHD 10 ME302C 4.2.2 Asus MeMO Pad HD7 ME173X 4.2.2 Shuttle: only works with longer phone plug: Casio G'zOne Commando 4G C8114G 4.1.2 (ID-80110010-028) UniMag II: Rev G or above required Dell Streak 7 Tablet DELLSTREAK7 2.2.2 T-Mobile HTC Aria LIBERTY 2.2.1 AT&T Beats audio must be turned HTC Butterfly HTCBUTTERFLY 4.1.1 off HTC Desire 816 HTCDESIRE816 4.4.2 HTC Desire 310 HTCDESIRE310 4.2.2 HTC Desire Z HTCVISION 2.2.1 T-Mobile Beats audio must be turned HTC Droid DNA HTC6435LVW 4.1.1 Verizon off HTC Droid Eris ERIS 2.1 Verizon KDDI HTC EVO 3D ISW12HT 2.3.4 (Japan) HTC EVO 3D PG86100 2.3.3 Sprint HTC EVO 4G PC36100 2.3.3 Sprint HTC EVO 4G LTE EVO 4.0.3 Sprint HTC EVO Shift 4G PG06100 2.3.3 Sprint HTC EVO View 4G PG41200 2.3.3 Sprint HTC G2 T-MOBILEG2 2.2 T-mobile HTC Hero HERO200 2.1-update1 Sprint HTC Incredible ADR6300 2.2 Verizon HTC Incredible 2 ADR6350 2.2.1 Verizon Beats audio must -
[WEEKLY WIRELESS REPORT] Week Ending May 11, 2012 This Week's
[WEEKLY WIRELESS REPORT] Week ending May 11, 2012 This Week’s Stories experience, and uses the most advanced mobile internet technology on the market to make their lives easier and keep their families and property safer,” AT&T Announces IP-Based Petersen said. Remote Home Monitoring May 7, 2012 In February, AT&T announced plans to launch an SDK for international providers to equip global service providers with capabilities to offer customizable, web- AT&T has announced plans for a new consumer- based home automation, energy and security services based remote home monitoring system that includes to their subscribers. a portfolio of all-digital, IP-based home security monitoring and automation services. www.wirelessweek.com Called AT&T Digital Life, the carrier says the services will give users control over various aspects of their AOL to Give Shareholders All homes – security cameras, thermostat, water systems – using any web-enabled device, including PCs, Proceeds from Patent Bonanza tablets and smartphones, regardless of wireless May 9, 2012 carrier. AOL will give 100% of the proceeds from its $1 billion AT&T said it plans to begin trials in Atlanta and Dallas patent sale "directly back to shareholders," CEO Tim this summer. Armstrong said Wednesday, but the details are still being worked out. Specifically, AT&T says the new system will allow users to monitor devices such as cameras, AOL announced last month that it had agreed to sell window/door sensors, smoke, carbon monoxide, about 925 patents to Microsoft (MSFT, Fortune 500) motion and glass break sensors, door locks, for $1.1 billion in cash. -
Smartphone Comparison As of June 2
Source: carrier websites with 2-yr contract. Refurbished phones excluded. Smartphone Positioning By Carrier (as of June 2 2012) (L) designates LTE-capable device. Website price w/ 19 of 29 18 of 25 16 of 23 13 of 17 2-yr contract Android Android Android Android Apple iPhone4S Apple iPhone4S Apple iPhone 4S Samsung Galaxy S II $199.99 Samsung Galaxy Note (L) Droid RAZR MAXX (L) HTC EVO 4G (L) HTC One S and above HTC One X (L) Galaxy Nexus (L) Galaxy Nexus T-Mobile myTouch 4G Slide Blackberry Bold 9900 HTC Rezound (L) Blackberry Bold 9930 Blackberry Bold 9900 HTC Titan II (L) Blackberry Bold 9930 Samsung Focus S $99.99 - Apple iPhone 4 Apple iPhone4 Apple iPhone 4 Samsung Galaxy S Samsung Galaxy S II Droid Charge (L) Motorola Admiral HTC Amaze $199.98 Skyrocket (L) Droid 4 (L) Samsung Epic HTC Radar Samsung Galaxy S II Droid RAZR 16GB (L) Blackberry Tour 9630 Blackberry Bold 9780 Motorola Atrix 2 LG Spectrum (L) Samsung Captivate Glide Samsung Stratosphere (L) Samsung Rugby Smart Blackberry Torch 9850 Blackberry Torch 9810 Blackberry Curve 8370 Blackberry Torch 9860 HTC Trophy Nokia Lumia 900 (L) Palm Pre 2 Under Apple iPhone 3GS LG Lucid (L) Samsung Conquer T-Mobile MyTouch Pantech Burst HTC Rhyme Samsung Replenish Samsung Exhibit $99.99 Pantech Crossover Droid X2 Samsung Transform Ultra T-Mobile Prism Pantech Pocket Droid Bionic 16 GB (L) Samsung Galaxy S II Samsung Dart HTC Vivid (L) Pantech Breakout (L) LG Viper 4G (L) Samsung Gravity Smart Legend: LG Nitro HD (L) LG Enlighten LG Rumor Reflex LG Double Play Apple OS = Red Samsung Double