Deliverable D3.1 Look-Up/Discovery, Context-Awareness, and Resource/Services Directory Contract Due Date 30/09/2012
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

RFC 8766: Discovery Proxy for Multicast DNS-Based Service
Stream: Internet Engineering Task Force (IETF) RFC: 8766 Category: Standards Track Published: June 2020 ISSN: 2070-1721 Author: S. Cheshire Apple Inc. RFC 8766 Discovery Proxy for Multicast DNS-Based Service Discovery Abstract This document specifies a network proxy that uses Multicast DNS to automatically populate the wide-area unicast Domain Name System namespace with records describing devices and services found on the local link. Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 7841. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at https://www.rfc-editor.org/info/rfc8766. Copyright Notice Copyright (c) 2020 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (https://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. Cheshire Standards Track Page 1 RFC 8766 Multicast Service Discovery Proxy June 2020 Table of Contents 1. -
3000 Applications
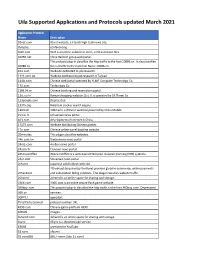
Uila Supported Applications and Protocols updated March 2021 Application Protocol Name Description 01net.com 05001net plus website, is a Japanese a French embedded high-tech smartphonenews site. application dedicated to audio- 050 plus conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also classifies 10086.cn the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese cloudweb portal storing operated system byof theYLMF 115 Computer website. TechnologyIt is operated Co. by YLMF Computer 115.com Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr ThisKorean protocol shopping plug-in website classifies 11st. the It ishttp operated traffic toby the SK hostPlanet 123people.com. Co. 123people.com Deprecated. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt ChineseLithuanian web news portal portal 163. It is operated by NetEase, a company which pioneered the 163.com development of Internet in China. 17173.com Website distributing Chinese games. 17u.com 20Chinese minutes online is a travelfree, daily booking newspaper website. available in France, Spain and Switzerland. 20minutes This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Checkout (acquired by Verifone) provides global e-commerce, online payments 2Checkout and subscription billing solutions. -

DNS and the Internet of Things
DNS and the Internet of Things Outlining the challenges faced by DNS in the Internet of Things Almira Hamzic Isabel Olofsson KTH ROYAL INSTITUTE OF TECHNOLOGY INFORMATION AND COMMUNICATION TECHNOLOGY Abstract This thesis work consists of a literature study where different aspects of DNS and the Internet of Things have been researched. A functional naming and service identification method is an essential part in making the IoT global, and DNS is the current method of naming devices on the Internet. The study looks into some challenges DNS will encounter, namely functionality, security and availability. This report concludes that a multicast DNS (mDNS) based solution designed for constrained networks is advantageous. This is despite the limited security that is currently available for such a solution. In the future, it is important that security has top priority, as there are currently limited means of security in DNS. Further study is needed when it comes to availability and how name resolving would work with constrained devices that utilise sleep mode. Keywords Internet of Things, IoT, DNS, security Abstrakt Detta examensarbete består av en litteraturstudie där olika aspekter av DNS (Domännamnssystemet, eng. Domain Name System) och Sakernas Internet (eng. Internet of Things) har studerats. En fungerande namngivnings-och serviceidentifieringsmetod är en viktig del för att kunna göra Sakernas Internet globalt, och DNS är den nuvarande metoden för att namnge enheter på Internet. Studien undersöker vissa utmaningar som DNS kan stöta på, nämligen funktionalitet, tillgänglighet och säkerhet. Rapportens slutsats är att en lösning baserad på multisändnings-DNS (eng. multicast DNS, mDNS) som är anpassad för begränsade nätverk (eng. -

How Does Zeroconf Work?
What is a Zeroconf? Zeroconf (zero configuration networking) refers to several protocols and techniques that are used together to create an IP (Internet Protocol) network with no special configuration servers or manual operator intervention. These networks allow novices to connect computers, network devices, scanners, and printers to create a functioning network without requiring manual configuration. Zeroconf does not require the user to set up Domain Name System services (DNS), Dynamic Host Configuration Protocol (DHCP), or manually configure the computer’s network settings. The three primary technologies that comprise a zeroconf network are automatic resolution and distribution of computer host names (referred to has multicast DNS), numeric network addresses assigned to networked devices (link-local address auto-configuration), and automatic location of network services. How does Zeroconf Work? Zerconf uses a number of underlying technologies. For address selection, link-local addressing replaces the DHCP server. This capability is built into Ipv6 addresses. However, traditional Ipv4 is used as a last resort except in a zeroconf context. The multicast name service is used for name resolution in zeroconf in order to allow a network device to select a domain name in the local name space and then announce it using a designated multicast IP address. Zeroconf uses multicast DNS for service discovery. In this model, every computer on the local network stores an individual listing of DNS resource records and then joins the respective DNS multicast group supporting the zeroconf network. Finally, DNS-based service discovery is one of the largest aspects of the zeroconf implementation. It is very implementation specific, but relies on a type of messaging in order to discover services and provide notifications of the available ones on a network. -

Scalable Oriented-Service Architecture for Heterogeneous and Ubiquitous Iot Domains
Pervasive and Mobile Pervasive and Mobile Computing 00 (2018) 1–23 Computing Scalable Oriented-Service Architecture for Heterogeneous and Ubiquitous IoT Domains Pablo Lopez, David Fernandez, Rafael Marin-Perez, Antonio J. Jara, Antonio F. Gomez-Skarmeta, Department of Information and Communications Engineering, Computer Science Faculty, University of Murcia, Regional Campus of International Excellence ”Campus Mare Nostrum”, Murcia, Spain Abstract Internet of Things (IoT) grows quickly, and 50 billion of IoT devices will be interconnected by 2020. For the huge number of IoT devices, a high scalable discovery architecture is required to provide autonomous registration and look-up of IoT resources and services. The architecture should enable dynamic updates when new IoT devices are incorporated into Internet, and changes are made to the existing ones. Nowadays in Internet, the most used discovery architecture is the Domain Name System (DNS). DNS offers a scalable solution through two distributed mechanisms: multicast DNS (mDNS) and DNS Service Directory (DNS-SD). Both mechanisms have been applied to discover resources and services in local IoT domains. However, a full architecture has not still been designed to support global discovery, local directories and a search engine for ubiquitous IoT domains. Moreover, the architecture should provide other transversal functionalities such as a common semantic for describing services and resources, and a service layer for interconnecting with M2M platforms and mobile clients. This paper presents an oriented-service architecture based on DNS to support a global discovery, local directories and a distributed search engine to enable a scalable looking-up of IoT resources and services. The architecture provides two lightweight discovery mechanisms based on mDNS and DNS-SD that have been optimized for the constraints of IoT devices to allow autonomous registration. -

OS X Yosemite
OS X Yosemite Core Technologies Overview October 2014 Core Technologies Overview 2 OS X Yosemite Contents Page 4 Introduction Page 5 System Startup BootROM EFI Kernel Drivers Initialization Address Space Layout Randomization (ASLR) Compressed Memory Power Efficiency App Nap Timer Coalescing Task-Level Scheduling Page 10 Disk Layout Partition Scheme Core Storage File Systems Page 13 Process Control Launchd Loginwindow Grand Central Dispatch Sandboxing Gatekeeper XPC Page 20 Network Access Ethernet Wi-Fi Multihoming IPv6 IP over Thunderbolt Network File Systems Access Control Lists Directory Services Remote Access Bonjour Core Technologies Overview 3 OS X Yosemite Page 27 Document Lifecycle Auto Save Automatic Versions Document Management Version Management Continuity Extensions iCloud Storage Page 31 Data Management Spotlight Time Machine Page 34 Developer Tools Xcode Swift LLVM Instruments Accelerate Automation WebKit Page 41 For More Information Core Technologies Overview 4 OS X Yosemite Introduction With more than 83 million users—consumers, scientists, animators, developers, and system administrators—OS X is the most widely used UNIX® desktop operating system. In addition, OS X is the only UNIX environment that natively runs Microsoft Office, Adobe Photoshop, and thousands of other consumer applications—all side by side with traditional command-line UNIX applications. Tight integration with hardware— from the sleek MacBook Air to the powerful Mac Pro—makes OS X the platform of choice for an emerging generation of power users. This document explores the powerful industry standards and breakthrough innovations in the core technologies that power Apple’s industry-leading user experiences. We walk you through the entire software stack, from firmware and kernel to iCloud and developer tools, to help you understand the many things OS X does for you every time you use your Mac. -

Practical Linux Forensics by Bruce Nikkel! As a Prepublication Title, This Book May Be Incom- Plete and Some Chapters May Not Have Been Proofread
P R A C T I C A L LINUX FORENSICS A GUIDE FOR DIGITAL INVESTIGATORS BRUCE NIKKEL EARLY ACCESS NO STARCH PRESS EARLY ACCESS PROGRAM: FEEDBACK WELCOME! Welcome to the Early Access edition of the as yet unpublished Practical Linux Forensics by Bruce Nikkel! As a prepublication title, this book may be incom- plete and some chapters may not have been proofread. Our goal is always to make the best books possible, and we look forward to hearing your thoughts. If you have any comments or questions, email us at [email protected]. If you have specific feedback for us, please include the page number, book title, and edition date in your note, and we’ll be sure to review it. We appreciate your help and support! We’ll email you as new chapters become available. In the meantime, enjoy! PR CA T IC A L L INU X FOR E N SI C S BRUCE N IK KE L Early Access edition, 6/18/21 Copyright © 2021 by Bruce Nikkel. ISBN-13: 978-1-7185-0196-6 (print) ISBN-13: 978-1-7185-0197-3 (ebook) Publisher: William Pollock Production Manager: Rachel Monaghan Production Editor: Miles Bond Developmental Editor: Jill Franklin Cover Illustrator: James L. Barry Technical Reviewer: Don Frick Copyeditor: George Hale No Starch Press and the No Starch Press logo are registered trademarks of No Starch Press, Inc. Other product and company names mentioned herein may be the trademarks of their respective owners. Rather than use a trademark symbol with every occurrence of a trade- marked name, we are using the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. -

Configuring the Service Discovery Gateway
Configuring the Service Discovery Gateway • Restrictions for Configuring the Service Discovery Gateway, on page 1 • Information about the Service Discovery Gateway and mDNS, on page 1 • How to Configure the Service Discovery Gateway, on page 4 • Monitoring Service Discovery Gateway, on page 8 • Configuration Examples, on page 8 • Where to Go Next for Configuring Services Discovery Gateway, on page 10 • Additional References for Service Discovery Gateway, on page 10 • Feature Information for Service Discovery Gateway, on page 11 Restrictions for Configuring the Service Discovery Gateway The following are restrictions for configuring the Service Discovery Gateway: • The Service Discovery Gateway does not support topologies with multiple hops. All network segments must be connected directly to it. The Service Discovery Gateway can learn services from all connected segments to build its cache and respond to requests acting as a proxy. • The use of third-party mDNS servers or applications are not supported with this feature. Information about the Service Discovery Gateway and mDNS mDNS mDNS was defined to achieve zero configuration, with zero configuration being defined as providing the following features: • Addressing—Allocating IP addresses to hosts • Naming—Using names to refer to hosts instead of IP addresses • Service discovery—Finding services automatically on the network Configuring the Service Discovery Gateway 1 Configuring the Service Discovery Gateway mDNS-SD With mDNS, network users no longer have to assign IP addresses, assign host names, or type in names to access services on the network. Users only need to ask to see what network services are available, and choose from a list. With mDNS, addressing is accomplished through the use of DHCP/DHCPv6 or IPv4 and IPv6 Link Local scoped addresses. -

Bonjour Printing Specification
Bonjour Printing Specification Version 1.2.1 Abstract Bonjour, also known as zero-configuration networking, enables automatic discovery of computers, devices, and services on Internet Protocol (IP) networks. Bonjour uses in- dustry standard IP protocols to allow devices to automatically discover each other with- out the need to enter IP addresses or configure DNS servers. This document describes the procedure for adding Bonjour support to a network-enabled printer. Minimum Implementation Requirements • IPv4 + IPv6 • Multicast DNS • DNS Service Discovery • Line Printer Daemon protocol Copyright © 2003-2015 Apple Inc. All rights reserved. 1 Bonjour Printing 1.2.1 Bonjour Printing Specification, Version 1.2.1 Copyright © 2003-2015 Apple Inc. All Rights Reserved. This document is provided for informational purposes. Apple may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering sub- ject matter in this document. The furnishing of this document does not give you a li- cense to any patents, trademarks, copyrights, or other intellectual property. Apple, the Apple Logo, and Bonjour are trademarks of Apple Inc., registered in the United States and other countries. APPLE MAKES NO WARRANTY OR REPRESENTATION, EITHER EXPRESS OR IM- PLIED, WITH RESPECT TO THIS DOCUMENT, ITS QUALITY, ACCURACY, MER- CHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. AS A RESULT, THIS DOCUMENT IS PROVIDED “AS IS,” AND YOU, THE READER, ARE ASSUMING THE ENTIRE RISK AS TO ITS QUALITY AND ACCURACY. IN NO EVENT WILL APPLE BE LIABLE FOR DIRECT, INDIRECT, SPECIAL, INCIDEN- TAL, OR CONSEQUENTIAL DAMAGES RESULTING FROM ANY DEFECT OR INACCU- RACY IN THIS DOCUMENT, even if advised of the possibility of such damages. -

AT16827: TCP/IP Server-Client with Cyclonetcp
SMART ARM-based Microcontroller AT16827: TCP/IP Server-Client with CycloneTCP APPLICATION NOTE Introduction In today’s world, computer networking has become an integral part of life. There are many different networks available to share information between groups of devices through a shared communication medium. They are mainly differentiated by the physical medium and protocol standards. Ethernet is a prime wired networking standard which is an an obvious choice for many network applications due to reliability, efficiency, and speed. Ethernet standard is used in various application segments. Nowadays, microcontrollers integrate peripherals to support Ethernet. Atmel®| SMART SAM E70 and SAM V71 series devices contain an inbuilt peripheral for 10/100 Mbps Ethernet MAC, compatible with IEEE 802.3 standard. This application note address the use of Ethernet MAC (GMAC) peripheral on SAM V70/E71 devices in network applications. When discussing network applications, the basic understanding of TCP/IP protocol layers is necessary. As an introduction, this application note explains the basic concepts of TCP/IP software stacks. The TCP/IP stack used in this application note is CycloneTCP from Oryx Embedded. The CycloneTCP is a dual IPv4/IPv6 stack dedicated to embedded applications. This application note describe following topics: • TCP/IP Protocol Model • Ethernet Peripheral overview • CycloneTCP overview • HTTP Server Implementation using CycloneTCP • HTTP Client using CycloneTCP • Test setup and procedure Atmel-42738A-TCP/IP-Server-Client-with-CycloneTCP_AT16287_Application -

Modustoolbox Anycloud 1.3 Release Notes SRN30288
Please note that Cypress is an Infineon Technologies Company. The document following this cover page is marked as “Cypress” document as this is the company that originally developed the product. Please note that Infineon will continue to offer the product to new and existing customers as part of the Infineon product portfolio. Continuity of document content The fact that Infineon offers the following product as part of the Infineon product portfolio does not lead to any changes to this document. Future revisions will occur when appropriate, and any changes will be set out on the document history page. Continuity of ordering part numbers Infineon continues to support existing part numbers. Please continue to use the ordering part numbers listed in the datasheet for ordering. www.infineon.com ModusToolbox AnyCloud 1.3 Release Notes SRN30288 ModusToolbox® AnyCloud 1.3 Release Notes Production Release Overview With the ModusToolbox AnyCloud collection of software libraries, you can rapidly develop Wi-Fi and Bluetooth applications on PSoC 6 MCU devices. AnyCloud is based on the industry-standard lwIP TCP/IP stack and Mbed TLS network security. It provides the ideal solution for applications that do not use commercial cloud management systems such as Arm Pelion or Amazon AWS IoT Core. AnyCloud enables development with custom or alternative third-party cloud management approaches with a fully open, customizable, and extensible source code distribution. This document describes all the libraries and versions included with AnyCloud 1.3. Contents -
Configuring the Service Discovery Gateway
Configuring the Service Discovery Gateway • Finding Feature Information, on page 1 • Restrictions for Configuring the Service Discovery Gateway, on page 1 • Information about the Service Discovery Gateway and mDNS, on page 2 • How to Configure the Service Discovery Gateway, on page 5 • Monitoring Service Discovery Gateway, on page 10 • Configuration Examples, on page 10 • Where to Go Next for Configuring Services Discovery Gateway, on page 12 • Additional References, on page 13 • Feature History and Information for Services Discovery Gateway, on page 14 Finding Feature Information Your software release may not support all the features documented in this module. For the latest caveats and feature information, see Bug Search Tool and the release notes for your platform and software release. To find information about the features documented in this module, and to see a list of the releases in which each feature is supported, see the feature information table at the end of this module. Use Cisco Feature Navigator to find information about platform support and Cisco software image support. To access Cisco Feature Navigator, go to http://www.cisco.com/go/cfn. An account on Cisco.com is not required. Restrictions for Configuring the Service Discovery Gateway The following are restrictions for configuring the Service Discovery Gateway: • The Service Discovery Gateway does not support topologies with multiple hops. All network segments must be connected directly to it. The Service Discovery Gateway can learn services from all connected segments to build its cache and respond to requests acting as a proxy. • The use of third-party mDNS servers or applications are not supported with this feature.