Minimising Virtual Machine Support for Concurrency
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The LLVM Instruction Set and Compilation Strategy
The LLVM Instruction Set and Compilation Strategy Chris Lattner Vikram Adve University of Illinois at Urbana-Champaign lattner,vadve ¡ @cs.uiuc.edu Abstract This document introduces the LLVM compiler infrastructure and instruction set, a simple approach that enables sophisticated code transformations at link time, runtime, and in the field. It is a pragmatic approach to compilation, interfering with programmers and tools as little as possible, while still retaining extensive high-level information from source-level compilers for later stages of an application’s lifetime. We describe the LLVM instruction set, the design of the LLVM system, and some of its key components. 1 Introduction Modern programming languages and software practices aim to support more reliable, flexible, and powerful software applications, increase programmer productivity, and provide higher level semantic information to the compiler. Un- fortunately, traditional approaches to compilation either fail to extract sufficient performance from the program (by not using interprocedural analysis or profile information) or interfere with the build process substantially (by requiring build scripts to be modified for either profiling or interprocedural optimization). Furthermore, they do not support optimization either at runtime or after an application has been installed at an end-user’s site, when the most relevant information about actual usage patterns would be available. The LLVM Compilation Strategy is designed to enable effective multi-stage optimization (at compile-time, link-time, runtime, and offline) and more effective profile-driven optimization, and to do so without changes to the traditional build process or programmer intervention. LLVM (Low Level Virtual Machine) is a compilation strategy that uses a low-level virtual instruction set with rich type information as a common code representation for all phases of compilation. -

Toward IFVM Virtual Machine: a Model Driven IFML Interpretation
Toward IFVM Virtual Machine: A Model Driven IFML Interpretation Sara Gotti and Samir Mbarki MISC Laboratory, Faculty of Sciences, Ibn Tofail University, BP 133, Kenitra, Morocco Keywords: Interaction Flow Modelling Language IFML, Model Execution, Unified Modeling Language (UML), IFML Execution, Model Driven Architecture MDA, Bytecode, Virtual Machine, Model Interpretation, Model Compilation, Platform Independent Model PIM, User Interfaces, Front End. Abstract: UML is the first international modeling language standardized since 1997. It aims at providing a standard way to visualize the design of a system, but it can't model the complex design of user interfaces and interactions. However, according to MDA approach, it is necessary to apply the concept of abstract models to user interfaces too. IFML is the OMG adopted (in March 2013) standard Interaction Flow Modeling Language designed for abstractly expressing the content, user interaction and control behaviour of the software applications front-end. IFML is a platform independent language, it has been designed with an executable semantic and it can be mapped easily into executable applications for various platforms and devices. In this article we present an approach to execute the IFML. We introduce a IFVM virtual machine which translate the IFML models into bytecode that will be interpreted by the java virtual machine. 1 INTRODUCTION a fundamental standard fUML (OMG, 2011), which is a subset of UML that contains the most relevant The software development has been affected by the part of class diagrams for modeling the data apparition of the MDA (OMG, 2015) approach. The structure and activity diagrams to specify system trend of the 21st century (BRAMBILLA et al., behavior; it contains all UML elements that are 2014) which has allowed developers to build their helpful for the execution of the models. -

Superoptimization of Webassembly Bytecode
Superoptimization of WebAssembly Bytecode Javier Cabrera Arteaga Shrinish Donde Jian Gu Orestis Floros [email protected] [email protected] [email protected] [email protected] Lucas Satabin Benoit Baudry Martin Monperrus [email protected] [email protected] [email protected] ABSTRACT 2 BACKGROUND Motivated by the fast adoption of WebAssembly, we propose the 2.1 WebAssembly first functional pipeline to support the superoptimization of Web- WebAssembly is a binary instruction format for a stack-based vir- Assembly bytecode. Our pipeline works over LLVM and Souper. tual machine [17]. As described in the WebAssembly Core Specifica- We evaluate our superoptimization pipeline with 12 programs from tion [7], WebAssembly is a portable, low-level code format designed the Rosetta code project. Our pipeline improves the code section for efficient execution and compact representation. WebAssembly size of 8 out of 12 programs. We discuss the challenges faced in has been first announced publicly in 2015. Since 2017, it has been superoptimization of WebAssembly with two case studies. implemented by four major web browsers (Chrome, Edge, Firefox, and Safari). A paper by Haas et al. [11] formalizes the language and 1 INTRODUCTION its type system, and explains the design rationale. The main goal of WebAssembly is to enable high performance After HTML, CSS, and JavaScript, WebAssembly (WASM) has be- applications on the web. WebAssembly can run as a standalone VM come the fourth standard language for web development [7]. This or in other environments such as Arduino [10]. It is independent new language has been designed to be fast, platform-independent, of any specific hardware or languages and can be compiled for and experiments have shown that WebAssembly can have an over- modern architectures or devices, from a wide variety of high-level head as low as 10% compared to native code [11]. -

Coqjvm: an Executable Specification of the Java Virtual Machine Using
CoqJVM: An Executable Specification of the Java Virtual Machine using Dependent Types Robert Atkey LFCS, School of Informatics, University of Edinburgh Mayfield Rd, Edinburgh EH9 3JZ, UK [email protected] Abstract. We describe an executable specification of the Java Virtual Machine (JVM) within the Coq proof assistant. The principal features of the development are that it is executable, meaning that it can be tested against a real JVM to gain confidence in the correctness of the specification; and that it has been written with heavy use of dependent types, this is both to structure the model in a useful way, and to constrain the model to prevent spurious partiality. We describe the structure of the formalisation and the way in which we have used dependent types. 1 Introduction Large scale formalisations of programming languages and systems in mechanised theorem provers have recently become popular [4–6, 9]. In this paper, we describe a formalisation of the Java virtual machine (JVM) [8] in the Coq proof assistant [11]. The principal features of this formalisation are that it is executable, meaning that a purely functional JVM can be extracted from the Coq development and – with some O’Caml glue code – executed on real Java bytecode output from the Java compiler; and that it is structured using dependent types. The motivation for this development is to act as a basis for certified consumer- side Proof-Carrying Code (PCC) [12]. We aim to prove the soundness of program logics and correctness of proof checkers against the model, and extract the proof checkers to produce certified stand-alone tools. -

Program Dynamic Analysis Overview
4/14/16 Program Dynamic Analysis Overview • Dynamic Analysis • JVM & Java Bytecode [2] • A Java bytecode engineering library: ASM [1] 2 1 4/14/16 What is dynamic analysis? [3] • The investigation of the properties of a running software system over one or more executions 3 Has anyone done dynamic analysis? [3] • Loggers • Debuggers • Profilers • … 4 2 4/14/16 Why dynamic analysis? [3] • Gap between run-time structure and code structure in OO programs Trying to understand one [structure] from the other is like trying to understand the dynamism of living ecosystems from the static taxonomy of plants and animals, and vice-versa. -- Erich Gamma et al., Design Patterns 5 Why dynamic analysis? • Collect runtime execution information – Resource usage, execution profiles • Program comprehension – Find bugs in applications, identify hotspots • Program transformation – Optimize or obfuscate programs – Insert debugging or monitoring code – Modify program behaviors on the fly 6 3 4/14/16 How to do dynamic analysis? • Instrumentation – Modify code or runtime to monitor specific components in a system and collect data – Instrumentation approaches • Source code modification • Byte code modification • VM modification • Data analysis 7 A Running Example • Method call instrumentation – Given a program’s source code, how do you modify the code to record which method is called by main() in what order? public class Test { public static void main(String[] args) { if (args.length == 0) return; if (args.length % 2 == 0) printEven(); else printOdd(); } public -

Engineering Definitional Interpreters
Reprinted from the 15th International Symposium on Principles and Practice of Declarative Programming (PPDP 2013) Engineering Definitional Interpreters Jan Midtgaard Norman Ramsey Bradford Larsen Department of Computer Science Department of Computer Science Veracode Aarhus University Tufts University [email protected] [email protected] [email protected] Abstract In detail, we make the following contributions: A definitional interpreter should be clear and easy to write, but it • We investigate three styles of semantics, each of which leads to may run 4–10 times slower than a well-crafted bytecode interpreter. a family of definitional interpreters. A “family” is characterized In a case study focused on implementation choices, we explore by its representation of control contexts. Our best-performing ways of making definitional interpreters faster without expending interpreter, which arises from a natural semantics, represents much programming effort. We implement, in OCaml, interpreters control contexts using control contexts of the metalanguage. based on three semantics for a simple subset of Lua. We com- • We evaluate other implementation choices: how names are rep- pile the OCaml to 86 native code, and we systematically inves- x resented, how environments are represented, whether the inter- tigate hundreds of combinations of algorithms and data structures. preter has a separate “compilation” step, where intermediate re- In this experimental context, our fastest interpreters are based on sults are stored, and how loops are implemented. natural semantics; good algorithms and data structures make them 2–3 times faster than na¨ıve interpreters. Our best interpreter, cre- • We identify combinations of implementation choices that work ated using only modest effort, runs only 1.5 times slower than a well together. -

A New JIT Compiler in Zing JVM Agenda
Falcon a new JIT compiler in Zing JVM Agenda • What is Falcon? Why do we need a new compiler? • Why did we decide to use LLVM? • What does it take to make a Java JIT from LLVM? • How does it fit with exiting technology, like ReadyNow? 2 Zing JVM Zing: A better JVM • Commercial server JVM • Key features • C4 GC, ReadyNow!, Falcon 5 What is Falcon? • Top tier JIT compiler in Zing JVM • Replacement for С2 compiler • Based on LLVM 6 Development Timeline PoC GA on by default Apr Dec Apr 2014 2016 2017 Estimated resource investment ~20 man-years (team of 4-6 people) 7 Why do we need a new compiler? • Zing used to have C2 like OpenJDK • C2 is aging poorly — difficult to maintain and evolve • Looking for competitive advantage over competition 8 Alternatives • Writing compiler from scratch? Too hard • Open-source compilers • GCC, Open64, Graal, LLVM… 9 Alternatives • Writing compiler from scratch? Too hard • Open-source compilers short list • Graal vs LLVM 10 “The LLVM Project is a collection of modular and reusable compiler and toolchain technologies” – llvm.org Where LLVM is used? • C/C++/Objective C • Swift • Haskell • Rust • … 12 Who makes LLVM? More than 500 developers 13 LLVM • Started in 2000 • Stable and mature • Proven performance for C/C++ code 14 LLVM IR General-purpose high-level assembler int mul_add(int x, int y, int z) { return x * y + z; } define i32 @mul_add(i32 %x, i32 %y, i32 %z) { entry: %tmp = mul i32 %x, %y %tmp2 = add i32 %tmp, %z ret i32 %tmp2 } 15 Infrastructure provides • Analysis, transformations • LLVM IR => LLVM IR • -

JVM Bytecode
Michael Rasmussen ZeroTurnaround Intro The JVM as a Stack Machine Bytecode taxonomy Stack manipulation Using locals Control flow Method invocation Tooling Next time public class Test { public static void main(String[] args) { System.out.println("Hello World!"); } } 00000000 ca fe ba be 00 00 00 31 00 22 0a 00 06 00 14 09 |.......1."......| 00000010 00 15 00 16 08 00 17 0a 00 18 00 19 07 00 1a 07 |................| 00000020 00 1b 01 00 06 3c 69 6e 69 74 3e 01 00 03 28 29 |.....<init>...()| 00000030 56 01 00 04 43 6f 64 65 01 00 0f 4c 69 6e 65 4e |V...Code...LineN| 00000040 75 6d 62 65 72 54 61 62 6c 65 01 00 12 4c 6f 63 |umberTable...Loc| 00000050 61 6c 56 61 72 69 61 62 6c 65 54 61 62 6c 65 01 |alVariableTable.| 00000060 00 04 74 68 69 73 01 00 06 4c 54 65 73 74 3b 01 |..this...LTest;.| 00000070 00 04 6d 61 69 6e 01 00 16 28 5b 4c 6a 61 76 61 |..main...([Ljava| 00000080 2f 6c 61 6e 67 2f 53 74 72 69 6e 67 3b 29 56 01 |/lang/String;)V.| 00000090 00 04 61 72 67 73 01 00 13 5b 4c 6a 61 76 61 2f |..args...[Ljava/| 000000a0 6c 61 6e 67 2f 53 74 72 69 6e 67 3b 01 00 0a 53 |lang/String;...S| . 000001d0 b6 00 04 b1 00 00 00 02 00 0a 00 00 00 0a 00 02 |................| 000001e0 00 00 00 04 00 08 00 05 00 0b 00 00 00 0c 00 01 |................| 000001f0 00 00 00 09 00 10 00 11 00 00 00 01 00 12 00 00 |................| 00000200 00 02 00 13 |....| Compiled from "Test.java” public class Test { public Test(); Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return public static void main(java.lang.String[]); Code: 0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream; 3: ldc #3 // String Hello World! 5: invokevirtual #4 // Method java/io/PrintStream.println: // (Ljava/lang/String;)V 8: return } Welcome my son Welcome to the machine Where have you been? It's alright we know where you've been. -

Open Programming Language Interpreters
Open Programming Language Interpreters Walter Cazzolaa and Albert Shaqiria a Università degli Studi di Milano, Italy Abstract Context: This paper presents the concept of open programming language interpreters, a model to support them and a prototype implementation in the Neverlang framework for modular development of programming languages. Inquiry: We address the problem of dynamic interpreter adaptation to tailor the interpreter’s behaviour on the task to be solved and to introduce new features to fulfil unforeseen requirements. Many languages provide a meta-object protocol (MOP) that to some degree supports reflection. However, MOPs are typically language-specific, their reflective functionality is often restricted, and the adaptation and application logic are often mixed which hardens the understanding and maintenance of the source code. Our system overcomes these limitations. Approach: We designed a model and implemented a prototype system to support open programming language interpreters. The implementation is integrated in the Neverlang framework which now exposes the structure, behaviour and the runtime state of any Neverlang-based interpreter with the ability to modify it. Knowledge: Our system provides a complete control over interpreter’s structure, behaviour and its runtime state. The approach is applicable to every Neverlang-based interpreter. Adaptation code can potentially be reused across different language implementations. Grounding: Having a prototype implementation we focused on feasibility evaluation. The paper shows that our approach well addresses problems commonly found in the research literature. We have a demon- strative video and examples that illustrate our approach on dynamic software adaptation, aspect-oriented programming, debugging and context-aware interpreters. Importance: Our paper presents the first reflective approach targeting a general framework for language development. -

Lecture 1: Introduction to Java®
Lecture 1: Introduction to Java MIT-AITI Kenya 2005 1 Lecture Outline • What a computer program is • How to write a computer program • The disadvantages and advantages of using Java • How a program that you write in Java is changed into a form that your computer can understand • Sample Java code and comments MIT-Africa Internet Technology Initiative ©2005 2 Computer Program vs. Food Recipe Food Recipe Computer Program A chef writes a set of A programmer writes a set of instructions called a recipe instructions called a program The recipe requires specific The program requires specific ingredients inputs The cook follows the The computer follows the instructions step-by-step instructions step-by-step The food will vary depending on The output will vary depending the amount of ingredients and on the values of the inputs and the cook the computer MIT-Africa Internet Technology Initiative ©2005 3 Recipe and Program Examples Student’s Student’s Ingredient # 1 Ingredient # 2 Name Grade Recipe Program Dinner “Bilha got an A on the exam!” MIT-Africa Internet Technology Initiative ©2005 4 What is a computer program? • For a computer to be able to perform specific tasks (i.e. print what grade a student got on an exam), it must be given instructions to do the task • The set of instructions that tells the computer to perform specific tasks is known as a computer program MIT-Africa Internet Technology Initiative ©2005 5 Writing Computer Programs • We write computer programs (i.e. a set of instructions) in programming languages such as C, Pascal, and -
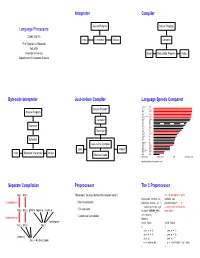
Language Processors Interpreter Compiler Bytecode Interpreter Just
Interpreter Compiler Source Program Source Program Language Processors COMS W4115 Input Interpreter Output Compiler Prof. Stephen A. Edwards Fall 2004 Columbia University Input Executable Program Output Department of Computer Science Bytecode Interpreter Just-in-time Compiler Language Speeds Compared Language Impl. C gcc Source Program Ocaml ocaml SML mlton Source Program C++ g++ SML smlnj Common Lisp cmucl Scheme bigloo Ocaml ocamlb Compiler Java java Pike pike Forth gforth Lua lua Compiler Python python Perl perl Ruby ruby Bytecode Eiffel se Mercury mercury Awk mawk Haskell ghc Lisp rep Icon icon Bytecode Tcl tcl Javascript njs Scheme guile Just-in-time Compiler Forth bigforth Erlang erlang Awk gawk Input Output Emacs Lisp xemacs Scheme stalin Input Bytecode Interpreter Output PHP php Machine Code Bash bash bytecodes native code JIT Threaded code http://www.bagley.org/˜doug/shootout/ Separate Compilation Preprocessor The C Preprocessor foo.c bar.c “Massages” the input before the compiler sees it. cc -E example.c gives #include <stdio.h> extern int C compiler cc: • Macro expansion #define min(x, y) \ printf(char*,...); ((x)<(y))?(x):(y) ... many more declarations • foo.s bar.s printf.o fopen.o malloc.o · · · File inclusion #ifdef DEFINE_BAZ from stdio.h • Conditional compilation int baz(); Assembler as: #endif Archiver ar: void foo() void foo() · · · foo.o bar.o libc.a { { int a = 1; int a = 1; int b = 2; int b = 2; Linker ld: int c; int c; foo — An Executable c = min(a,b); c = ((a)<(b))?(a):(b); } } Compiling a Simple Program What the -

A Hybrid Approach of Compiler and Interpreter Achal Aggarwal, Dr
International Journal of Scientific & Engineering Research, Volume 5, Issue 6, June-2014 1022 ISSN 2229-5518 A Hybrid Approach of Compiler and Interpreter Achal Aggarwal, Dr. Sunil K. Singh, Shubham Jain Abstract— This paper essays the basic understanding of compiler and interpreter and identifies the need of compiler for interpreted languages. It also examines some of the recent developments in the proposed research. Almost all practical programs today are written in higher-level languages or assembly language, and translated to executable machine code by a compiler and/or assembler and linker. Most of the interpreted languages are in demand due to their simplicity but due to lack of optimization, they require comparatively large amount of time and space for execution. Also there is no method for code minimization; the code size is larger than what actually is needed due to redundancy in code especially in the name of identifiers. Index Terms— compiler, interpreter, optimization, hybrid, bandwidth-utilization, low source-code size. —————————— —————————— 1 INTRODUCTION order to reduce the complexity of designing and building • Compared to machine language, the notation used by Icomputers, nearly all of these are made to execute relatively programming languages closer to the way humans simple commands (but do so very quickly). A program for a think about problems. computer must be built by combining some very simple com- • The compiler can spot some obvious programming mands into a program in what is called machine language. mistakes. Since this is a tedious and error prone process most program- • Programs written in a high-level language tend to be ming is, instead, done using a high-level programming lan- shorter than equivalent programs written in machine guage.