Spatial Augmented Reality Merging Real and Virtual Worlds
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Stereoscopic Vision, Stereoscope, Selection of Stereo Pair and Its Orientation
International Journal of Science and Research (IJSR) ISSN (Online): 2319-7064 Impact Factor (2012): 3.358 Stereoscopic Vision, Stereoscope, Selection of Stereo Pair and Its Orientation Sunita Devi Research Associate, Haryana Space Application Centre (HARSAC), Department of Science & Technology, Government of Haryana, CCS HAU Campus, Hisar – 125 004, India , Abstract: Stereoscope is to deflect normally converging lines of sight, so that each eye views a different image. For deriving maximum benefit from photographs they are normally studied stereoscopically. Instruments in use today for three dimensional studies of aerial photographs. If instead of looking at the original scene, we observe photos of that scene taken from two different viewpoints, we can under suitable conditions, obtain a three dimensional impression from the two dimensional photos. This impression may be very similar to the impression given by the original scene, but in practice this is rarely so. A pair of photograph taken from two cameras station but covering some common area constitutes and stereoscopic pair which when viewed in a certain manner gives an impression as if a three dimensional model of the common area is being seen. Keywords: Remote Sensing (RS), Aerial Photograph, Pocket or Lens Stereoscope, Mirror Stereoscope. Stereopair, Stere. pair’s orientation 1. Introduction characteristics. Two eyes must see two images, which are only slightly different in angle of view, orientation, colour, A stereoscope is a device for viewing a stereoscopic pair of brightness, shape and size. (Figure: 1) Human eyes, fixed on separate images, depicting left-eye and right-eye views of same object provide two points of observation which are the same scene, as a single three-dimensional image. -

Gesttrack3d™ Toolkit
GestTrack3D™ Toolkit A Collection of 3D Vision Trackers for Touch-Free User Interface and Game Control Control interactive displays and digital signs from a distance. Navigate “PrimeSense™-like” 3D game worlds. Interact with virtually any computer system without ever touching it. GestureTek, the inventor and multiple patent holder of video gesture control using 2D and 3D cameras, introduces GestTrack3D™, our patented, cutting-edge, 3D gesture control system for developers, OEMs and public display providers. GestTrack3D eliminates the need for touch-based accessories like a mouse, keyboard, handheld controller or touch screen when interacting with an electronic device. Working with nearly any Time of Flight camera to precisely measure the location of people’s hands or body parts, GestTrack3D’s robust tracking enables device control through a wide range of gestures and poses. GestTrack3D is the perfect solution for accurate and reliable off-screen computer control in interactive environments such as boardrooms, classrooms, clean rooms, stores, museums, amusement parks, trade shows and rehabilitation centres. The Science Behind the Software GestureTek has developed unique tracking and gesture recognition algorithms to define the relationship between computers and the people using them. With 3D cameras and our patented 3D computer vision software, computers can now identify, track and respond to fingers, hands or full-body gestures. The system comes with a depth camera and SDK (including sample code) that makes the x, y and z coordinates of up to ten hands available in real time. It also supports multiple PC development environments and includes a library of one-handed and two-handed gestures and poses. -

Microsoft-Theater-Venue-And-Technical-Information-Updated-05.16.19.Pdf
Venue and Technical Information Microsoft Theater 6/7/2019 1 Venue and Technical Information TABLE OF CONTENTS Address and Contact Information 3 Loading Dock and Parking 4 Power 5 Rigging 5 General Stage info (Dimensions, Soft Goods, Risers, Orchestra Equipment) 6 Lighting 8 Sound 10 Video Production and Broadcast Facilities 12 Stage Crew Info 12 Fire and Life Safety 13 Dressing Rooms 14 VIP Spaces and Meeting Rooms 16 Guest Services and Seating 17 Media and Filming 18 L.A. LIVE Info (Restaurants and Entertainment Info) 19 Lodging 20 Food (Fast Food, Restaurants, Grocery Markets, Coffee) 20 Nightlife 23 Emergency and Medical Services 23 Laundry and Shoe Services 24 Gasoline 24 APPENDIX SECTION WITH MAPS AND DRAWINGS Parking Map 26 Seating Map 27 Truck and Bus Parking Map 28 Dressing Room Layout 29 Additional drawings are available by contacting the venue Production Managers Microsoft Theater 6/7/2019 2 Venue and Technical Information ADDRESS AND CONTACT INFORMATION Mailing and Physical Address 777 Chick Hearn Ct. Los Angeles, CA 90015 213.763.6000 MAIN 213.763.6001 FAX Contacting Microsoft Theater President Lee Zeidman 213.742.7255 [email protected] SVP, Operations & Event David Anderson Production 213.763.6077 [email protected] Vice President, Events Russell Gordon 213.763.6035 [email protected] Director, Production Kyle Lumsden 213.763.6012 [email protected] Production Manager Kevin McPherson 213.763.6015 [email protected] Sr. Manager, Events Alexandra Williams 213.763.6013 -

Morton Heilig, Through a Combination of Ingenuity, Determination, and Sheer Stubbornness, Was the First Person to Attempt to Create What We Now Call Virtual Reality
Morton Hei Iig "The [in em a of the Future" << 2 2 >> (1955) ;!fo11o11 Hdlir;. Sens<muna. Cuuri<S_) oJS1o11 Fi1lur. "Thus, individually and collectively, by thoroughly applying the methodology of art, the cinema of the future will become the first art form to reveal the new scientific world to man in the .full sensual vividness and dynamic vitality of his consciousness." 239 240 Horton Heilig << Morton Heilig, through a combination of ingenuity, determination, and sheer stubbornness, was the first person to attempt to create what we now call virtual reality. In the 1 950s it occurred to him that all the sensory splendor of life could be simulated with "reality machines." Heilig was a Hollywood cinematographer, and it was as an extension of cinema that he thought such a machine might be achieved. With his inclination, albeit amateur, toward the ontological aspirations of science, He ilig proposed that an artist's expressive powers would be enhanced by a scientific understanding of the senses and perception. His premise was sim ple but striking for its time: if an artist controlled the multisensory stimulation of the audience, he could provide them with the illusion and sensation of first person experience, of actually " being there." Inspired by short-Jived curiosities such as Cinerama and 3-D movies, it oc curred to Heilig that a logical extension of cinema would be to immerse the au dience in a fabricated world that engaged all the senses. He believed that by expanding cinema to involve not only sight and sound but also taste, touch, and smell, the traditional fourth wal l of film and theater would dissolve, transport ing the audience into an inhabitable, virtual world; a kind of "experience theater." Unable to find support in Hollywood for his extraordinary ideas, Heilig moved to Mexico City In 1954, finding himself in a fertile mix of artists, filmmakers, writers, and musicians. -

Audio Challenges in Virtual and Augmented Reality Devices
Audio challenges in virtual and augmented reality devices Dr. Ivan Tashev Partner Software Architect Audio and Acoustics Research Group Microsoft Research Labs - Redmond In memoriam: Steven L. Grant Sep 15, 2016 IWAENC Audio challenges in virtual and augmented reality devices 2 In this talk • Devices for virtual and augmented reality • Binaural recording and playback • Head Related Functions and their personalization • Object-based rendering of spatial audio • Modal-based rendering of spatial audio • Conclusions Sep 15, 2016 IWAENC Audio challenges in virtual and augmented reality devices 3 Colleagues and contributors: Hannes Gamper David Johnston Ivan Tashev Mark R. P. Thomas Jens Ahrens Microsoft Research Microsoft Research Microsoft Research Dolby Laboratories Chalmers University, Sweden Sep 15, 2016 IWAENC Audio challenges in virtual and augmented reality devices 4 Devices for Augmented and Virtual Reality They both need good spatial audio Sep 15, 2016 IWAENC Audio challenges in virtual and augmented reality devices 5 Augmented vs. Virtual Reality • Augmented reality (AR) is a live direct or indirect view of a physical, real-world environment whose elements are augmented (or supplemented) by computer-generated sensory input such as sound, video, graphics • Virtual reality (VR) is a computer technology that replicates an environment, real or imagined, and simulates a user's physical presence in a way that allows the user to interact with it. It artificially creates sensory experience, which can include sight, touch, hearing, etc. Sep -

2.0 Project Description
2.0 PROJECT DESCRIPTION A. INTRODUCTION Jia Yuan USA Co, Inc., the Applicant, proposes to develop a mixed‐use residential, hotel and commercial project (the Project), located on an approximately 2.7 acre (116,660 square feet) ‘L’‐shaped site (Project Site) bounded by S. Figueroa Street to the west, S. Flower Street to the east, W. Olympic Boulevard to the north, and 11th Street to the south. The Project Site is located in the southwest portion of the Downtown community of the City of Los Angeles (City) which falls within the South Park district of the Central City Community Plan Area. The Project Site is in a highly urbanized and active area adjacent to LA LIVE, Staples Center Arena, Microsoft Theater, and in close proximity to the Los Angeles Convention Center. The Project Site is currently developed with the nine‐story Luxe City Center Hotel (Luxe Hotel) and surrounding surface parking lots, which would be removed to support the Project. The mixed‐use Project would include up to approximately 1,129,284 square feet (sf) of floor area (approximately 9.7:1 FAR) in three towers atop an eight level podium (Podium) with four levels above grade and up to four levels below grade. The Project would include a total of up to 300 hotel rooms, 650 residential condominium units, and up to approximately 80,000 sf of retail, restaurant, and other commercial uses.1 The residential tower (Residential Tower 1) located at the corner of S. Flower Street and 11th Street would be 32 stories and would include up to 290 residential units. -

Virtual Reality and Visual Perception by Jared Bendis
Virtual Reality and Visual Perception by Jared Bendis Introduction Goldstein (2002) defines perception as a “conscious sensory experience” (p. 6) and as scientists investigate how the human perceptual system works they also find themselves investigating how the human perceptual system doesn’t work and how that system can be fooled, exploited, and even circumvented. The pioneers in the ability to control the human perceptual system have been in the field of Virtual Realty. In Simulated and Virtual Realities – Elements of Perception, Carr (1995) defines Virtual Reality as “…the stimulation of human perceptual experience to create an impression of something which is not really there” (p. 5). Heilig (2001) refers to this form of “realism” as “experience” and in his 1955 article about “The Cinema of the Future” where he addresses the need to look carefully at perception and breaks down the precedence of perceptual attention as: Sight 70% Hearing 20% Smell 5% Touch 4% Taste 1% (p. 247) Not surprisingly sight is considered the most important of the senses as Leonardo da Vinci observed: “They eye deludes itself less than any of the other senses, because it sees by none other than the straight lines which compose a pyramid, the base of which is the object, and the lines conduct the object to the eye… But the ear is strongly subject to delusions about the location and distance of its objects because the images [of sound] do not reach it in straight lines, like those of the eye, but by tortuous and reflexive lines. … The sense of smells is even less able to locate the source of an odour. -

Virtual and Augmented Reality
Virtual and Augmented Reality Virtual and Augmented Reality: An Educational Handbook By Zeynep Tacgin Virtual and Augmented Reality: An Educational Handbook By Zeynep Tacgin This book first published 2020 Cambridge Scholars Publishing Lady Stephenson Library, Newcastle upon Tyne, NE6 2PA, UK British Library Cataloguing in Publication Data A catalogue record for this book is available from the British Library Copyright © 2020 by Zeynep Tacgin All rights for this book reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owner. ISBN (10): 1-5275-4813-9 ISBN (13): 978-1-5275-4813-8 TABLE OF CONTENTS List of Illustrations ................................................................................... x List of Tables ......................................................................................... xiv Preface ..................................................................................................... xv What is this book about? .................................................... xv What is this book not about? ............................................ xvi Who is this book for? ........................................................ xvii How is this book used? .................................................. xviii The specific contribution of this book ............................. xix Acknowledgements ........................................................... -
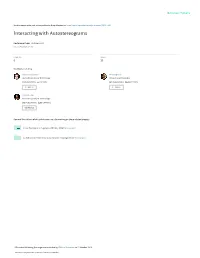
Interacting with Autostereograms
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/336204498 Interacting with Autostereograms Conference Paper · October 2019 DOI: 10.1145/3338286.3340141 CITATIONS READS 0 39 5 authors, including: William Delamare Pourang Irani Kochi University of Technology University of Manitoba 14 PUBLICATIONS 55 CITATIONS 184 PUBLICATIONS 2,641 CITATIONS SEE PROFILE SEE PROFILE Xiangshi Ren Kochi University of Technology 182 PUBLICATIONS 1,280 CITATIONS SEE PROFILE Some of the authors of this publication are also working on these related projects: Color Perception in Augmented Reality HMDs View project Collaboration Meets Interactive Spaces: A Springer Book View project All content following this page was uploaded by William Delamare on 21 October 2019. The user has requested enhancement of the downloaded file. Interacting with Autostereograms William Delamare∗ Junhyeok Kim Kochi University of Technology University of Waterloo Kochi, Japan Ontario, Canada University of Manitoba University of Manitoba Winnipeg, Canada Winnipeg, Canada [email protected] [email protected] Daichi Harada Pourang Irani Xiangshi Ren Kochi University of Technology University of Manitoba Kochi University of Technology Kochi, Japan Winnipeg, Canada Kochi, Japan [email protected] [email protected] [email protected] Figure 1: Illustrative examples using autostereograms. a) Password input. b) Wearable e-mail notification. c) Private space in collaborative conditions. d) 3D video game. e) Bar gamified special menu. Black elements represent the hidden 3D scene content. ABSTRACT practice. This learning effect transfers across display devices Autostereograms are 2D images that can reveal 3D content (smartphone to desktop screen). when viewed with a specific eye convergence, without using CCS CONCEPTS extra-apparatus. -

Dualcad : Intégrer La Réalité Augmentée Et Les Interfaces D'ordinateurs De Bureau Dans Un Contexte De Conception Assistée Par Ordinateur
ÉCOLE DE TECHNOLOGIE SUPÉRIEURE UNIVERSITÉ DU QUÉBEC MÉMOIRE PRÉSENTÉ À L’ÉCOLE DE TECHNOLOGIE SUPÉRIEURE COMME EXIGENCE PARTIELLE À L’OBTENTION DE LA MAÎTRISE AVEC MÉMOIRE EN GÉNIE LOGICIEL M. Sc. A. PAR Alexandre MILLETTE DUALCAD : INTÉGRER LA RÉALITÉ AUGMENTÉE ET LES INTERFACES D'ORDINATEURS DE BUREAU DANS UN CONTEXTE DE CONCEPTION ASSISTÉE PAR ORDINATEUR MONTRÉAL, LE 27 AVRIL 2016 Alexandre Millette, 2016 Cette licence Creative Commons signifie qu’il est permis de diffuser, d’imprimer ou de sauvegarder sur un autre support une partie ou la totalité de cette œuvre à condition de mentionner l’auteur, que ces utilisations soient faites à des fins non commerciales et que le contenu de l’œuvre n’ait pas été modifié. PRÉSENTATION DU JURY CE MÉMOIRE A ÉTÉ ÉVALUÉ PAR UN JURY COMPOSÉ DE : M. Michael J. McGuffin, directeur de mémoire Département de génie logiciel et des TI à l’École de technologie supérieure M. Luc Duong, président du jury Département de génie logiciel et des TI à l’École de technologie supérieure M. David Labbé, membre du jury Département de génie logiciel et des TI à l’École de technologie supérieure IL A FAIT L’OBJET D’UNE SOUTENANCE DEVANT JURY ET PUBLIC LE 6 AVRIL 2016 À L’ÉCOLE DE TECHNOLOGIE SUPÉRIEURE AVANT-PROPOS Lorsqu’il m’est venu le temps de choisir si je désirais faire une maîtrise avec ou sans mémoire, les technologies à Réalité Augmentée (RA) étaient encore des embryons de projets, entrepris par des compagnies connues pour leurs innovations, telles que Google avec leur Google Glasses, ou par des compagnies émergentes, telles que META et leur Spaceglasses. -

PROJECTION – VISION SYSTEMS: Towards a Human-Centric Taxonomy
PROJECTION – VISION SYSTEMS: Towards a Human-Centric Taxonomy William Buxton Buxton Design www.billbuxton.com (Draft of May 25, 2004) ABSTRACT As their name suggests, “projection-vision systems” are systems that utilize a projector, generally as their display, coupled with some form of camera/vision system for input. Projection-vision systems are not new. However, recent technological developments, research into usage, and novel problems emerging from ubiquitous and portable computing have resulted in a growing recognition that they warrant special attention. Collectively, they represent an important, interesting and distinct class of user interface. The intent of this paper is to present an introduction to projection-vision systems from a human-centric perspective. We develop a number of dimensions according to which they can be characterized. In so doing, we discuss older systems that paved the way, as well as ones that are just emerging. Our discussion is oriented around issues of usage and user experience. Technology comes to the fore only in terms of its affordances in this regard. Our hope is to help foster a better understanding of these systems, as well as provide a foundation that can assist in making more informed decisions in terms of next steps. INTRODUCTION I have a confession to make. At 56 years of age, as much as I hate losing my hair, I hate losing my vision even more. I tell you this to explain why being able to access the web on my smart phone, PDA, or wrist watch provokes nothing more than a yawn from me. Why should I care? I can barely read the hands on my watch, and can’t remember the last time that I could read the date on it without my glasses. -

Memoirs Dated 2020 Daily Journal, (Jan - Dec), 6 X 9 Inches, Full Year Planner (Green) Pdf, Epub, Ebook
MEMOIRS DATED 2020 DAILY JOURNAL, (JAN - DEC), 6 X 9 INCHES, FULL YEAR PLANNER (GREEN) PDF, EPUB, EBOOK DESIGN | 374 pages | 01 May 2020 | Blurb | 9781714238330 | English | none Memoirs Dated 2020 Daily Journal, (Jan - Dec), 6 x 9 Inches, Full Year Planner (Green) PDF Book Alabama basketball: Tide increases win streak to seven straight. The calendars are undated, with months, weeks, and days grouped together in different sections. Pencil, crayon or pen friendly, if you love classic notebooks this is definitely the notebook for you. Trouva Wayfair WebstaurantStore. Brightly colored wooden desk organizers help you personalize your workspace while staying organized. Don't have an account? Related Searches: coastlines dated planner , timer dated organizer refill more. Pages: , Hardcover, Charlie Creative Lab more. New timeline shows just how close rioters got to Pence and his family. Spike Lee: My wife deserves all the credit for raising our children. Flaws but not dealbreakers: This is a busy-looking planner, and some people may be overwhelmed by the prompts. Buying Options Buy from Amazon. House of Doolittle Productivity and Goal Planner , 6. Stay connected for inspiring stories, free downloads, exclusive sales, and tips that will empower you to build your ideal life. January 15, Toggle navigation Menu. For others a planner means so much more than just a place to keep track of meetings and appointments, and they want to hold on to it for as long as they can, to carry their memories and lived experiences with them for a little more time. Ready to "downsize" by eliminating things you don't need or use anymore? A beautiful at a glance dated monthly planner by appointed.