Hijacking User Uploads to Online Persistent Data Repositories for Covert Data Exfiltration Curtis P
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Olaworks Inc
Mobile AR Service Experiences with Jung-hee Ryu Founder & CSO, Olaworks Inc. [email protected] Olaworks overview is a computer vision company with 35+ Patents Core technologies Imaging and photo managing applications Face Detection Face Feature Detection (incl. Age, Gender and Emotion) Name: Grace Koo Face Recognition ScanSearch: Computer vision and sensor based mobile search Object Tracking Same Car Image Matching Similar Car Image Similarity ScanSearch is… A mobile AR service providing product and local information based on Olaworks’ computer vision and sensing technologies. ScanSearch currently supports iPhone, Andrioid (Korean version only) and Windows Phone 7 (US and European version). ScanSearch currently supports four search categories. Technologies for each search categories UX examples: Nearby UX examples: Book UX examples: Movie UX examples: Music User scenarios History: Successful launching @ 22nd March 2010 Korean version for iPhone only. (KR/US/HK app store) Total 222,438 Downloads in first 10 days. 288,242 in 1 month. Average Ratings = 4½ ★★★★★ History: LG Optimus series pre-install @ 24th May 2010 Starting from Optimus Q, the LG’s flagship Android phone for Korean market LG Optimus Q TV commercial Currently we are making a business ecosystem in KR. POI database from Korea Telecom Credit card discount info from KB Card Part-time job search from Incruit ATM location from IBK Bank Book info from Aladdin Music info from KT Music And much more… 800,000+ unique users and still growing 250,000+ information request/day Evolution -

Case 5:18-Cv-06739-VKD Document 27 Filed 07/02/18 Page 1 of 11
Case 5:18-cv-06739-VKD Document 27 Filed 07/02/18 Page 1 of 11 IN THE UNITED STATES DISTRICT COURT FOR THE NORTHERN DISTRICT OF TEXAS DALLAS DIVISION § UNILOC USA, INC. and § UNILOC LUXEMBOURG, S.A., § Civil Action No. 3:18-cv-00560-DCG § Plaintiffs, § § v. § PATENT CASE § LG ELECTRONICS U.S.A., INC., § LG ELECTRONICS MOBILECOMM § U.S.A. INC. and § LG ELECTRONICS, INC., § § Defendant. § JURY TRIAL DEMANDED § FIRST AMENDED COMPLAINT FOR PATENT INFRINGEMENT Plaintiffs, Uniloc USA, Inc. (“Uniloc USA”) and Uniloc Luxembourg, S.A. (“Uniloc Luxembourg”) (together, “Uniloc”), for their First Amended Complaint against defendant, LG Electronics U.S.A. (“LGE”), Inc., LG Electronics Mobilecomm U.S.A., Inc., and LG Electronics, Inc., (“LG Korea”) (together “LG”), allege as follows:1 THE PARTIES 1. Uniloc USA is a Texas corporation having a principal place of business at Legacy Town Center I, Suite 380, 7160 Dallas Parkway, Plano Texas 75024. Uniloc USA also maintains a place of business at 102 N. College, Suite 603, Tyler, Texas 75702. 1 An amended complaint supersedes the original complaint and renders it of no legal effect, King v. Dogan, 31 F.3d 344. 346 (5th Cir. 1994), rendering a motion to dismiss the original complaint moot. See, e.g., Mangum v. United Parcel Services, No. 3:09-cv-0385, 2009 WL 2700217 (N.D. Tex. Aug. 26, 2009). 2988606.v1 Case 5:18-cv-06739-VKD Document 27 Filed 07/02/18 Page 2 of 11 2. Uniloc Luxembourg is a Luxembourg public limited liability company having a principal place of business at 15, Rue Edward Steichen, 4th Floor, L-2540, Luxembourg (R.C.S. -

RELEASE NOTES UFED PHYSICAL ANALYZER, Version 5.0 | March 2016 UFED LOGICAL ANALYZER
NOW SUPPORTING 19,203 DEVICE PROFILES +1,528 APP VERSIONS UFED TOUCH, UFED 4PC, RELEASE NOTES UFED PHYSICAL ANALYZER, Version 5.0 | March 2016 UFED LOGICAL ANALYZER COMMON/KNOWN HIGHLIGHTS System Images IMAGE FILTER ◼ Temporary root (ADB) solution for selected Android Focus on the relevant media files and devices running OS 4.3-5.1.1 – this capability enables file get to the evidence you need fast system and physical extraction methods and decoding from devices running OS 4.3-5.1.1 32-bit with ADB enabled. In addition, this capability enables extraction of apps data for logical extraction. This version EXTRACT DATA FROM BLOCKED APPS adds this capability for 110 devices and many more will First in the Industry – Access blocked application data with file be added in coming releases. system extraction ◼ Enhanced physical extraction while bypassing lock of 27 Samsung Android devices with APQ8084 chipset (Snapdragon 805), including Samsung Galaxy Note 4, Note Edge, and Note 4 Duos. This chipset was previously supported with UFED, but due to operating system EXCLUSIVE: UNIFY MULTIPLE EXTRACTIONS changes, this capability was temporarily unavailable. In the world of devices, operating system changes Merge multiple extractions in single unified report for more frequently, and thus, influence our support abilities. efficient investigations As our ongoing effort to continue to provide our customers with technological breakthroughs, Cellebrite Logical 10K items developed a new method to overcome this barrier. Physical 20K items 22K items ◼ File system and logical extraction and decoding support for iPhone SE Samsung Galaxy S7 and LG G5 devices. File System 15K items ◼ Physical extraction and decoding support for a new family of TomTom devices (including Go 1000 Point Trading, 4CQ01 Go 2505 Mm, 4CT50, 4CR52 Go Live 1015 and 4CS03 Go 2405). -

KT 22-2-2017.Qxp Layout 1
SUBSCRIPTION WEDNESDAY, FEBRUARY 22, 2017 JAMADA ALAWWAL 25, 1438 AH www.kuwaittimes.net Amir sails in Le Pen cancels AUB net Kuwait SC Omani waters meeting with profit surges beat Kazma onboard Lebanon mufti by 6.2% to to clinch royal yacht2 over headscarf7 $570.6m21 Amir19 Cup MPs threaten to grill PM Min 07º Max 22º over Harbi ‘resignation’ High Tide 10:05 & 19:53 Low Tide Ban on publishing suspects’ images 03:25 & 14:03 40 PAGES NO: 17149 150 FILS By B Izzak Kuwait Times fetes art competition winners KUWAIT: A number of opposition MPs yesterday warned they will grill HH the Prime Minister Sheikh Jaber Al- Mubarak Al-Sabah if the health minister is allowed to resign following a controversy over the minister’s bid to sack top officials. MP Yousef Al-Fadhalah said on his Twitter account that he will file to grill the prime minister on March 5 if the government allows Health Minister Jamal Al-Harbi to quit, while leaving “suspected corrupt senior bureaucrats” in their positions. The lawmaker said that he had learned that Harbi offered his resignation on Monday during the Cabinet meeting after his demand to sack the undersecretary and a number of senior officials was not accepted by the Cabinet. The controversy over the health minister has been growing even before the November election, after reports that the cost of sending Kuwaitis for treatment abroad skyrocketed to new highs. Some MPs put it at as high as KD 750 million last year. Opposition MPs have alleged that a majority of those sent for treatment abroad were in fact not patients but sent on what they described as “medical tourism or politi- cal medication”, under which thousands of fake patients were sent abroad to appease certain MPs. -

Presentación De Powerpoint
Modelos compatibles de Imóvil No. Marca Modelo Teléfono Versión del sistema operativo 1 360 1501_M02 1501_M02 Android 5.1 2 100+ 100B 100B Android 4.1.2 3 Acer Iconia Tab A500 Android 4.0.3 4 ALPS (Golden Master) MR6012H1C2W1 MR6012H1C2W1 Android 4.2.2 5 ALPS (Golden Master) PMID705GTV PMID705GTV Android 4.2.2 6 Amazon Fire HD 6 Fire HD 6 Fire OS 4.5.2 / Android 4.4.3 7 Amazon Fire Phone 32GB Fire Phone 32GB Fire OS 3.6.8 / Android 4.2.2 8 Amoi A862W A862W Android 4.1.2 9 amzn KFFOWI KFFOWI Android 5.1.1 10 Apple iPad 2 (2nd generation) MC979ZP iOS 7.1 11 Apple iPad 4 MD513ZP/A iOS 7.1 12 Apple iPad 4 MD513ZP/A iOS 8.0 13 Apple iPad Air MD785ZP/A iOS 7.1 14 Apple iPad Air 2 MGLW2J/A iOS 8.1 15 Apple iPad Mini MD531ZP iOS 7.1 16 Apple iPad Mini 2 FE276ZP/A iOS 8.1 17 Apple iPad Mini 3 MGNV2J/A iOS 8.1 18 Apple iPhone 3Gs MC132ZP iOS 6.1.3 19 Apple iPhone 4 MC676LL iOS 7.1.2 20 Apple iPhone 4 MC603ZP iOS 7.1.2 21 Apple iPhone 4 MC604ZP iOS 5.1.1 22 Apple iPhone 4s MD245ZP iOS 8.1 23 Apple iPhone 4s MD245ZP iOS 8.4.1 24 Apple iPhone 4s MD245ZP iOS 6.1.2 25 Apple iPhone 5 MD297ZP iOS 6.0 26 Apple iPhone 5 MD298ZP/A iOS 8.1 27 Apple iPhone 5 MD298ZP/A iOS 7.1.1 28 Apple iPhone 5c MF321ZP/A iOS 7.1.2 29 Apple iPhone 5c MF321ZP/A iOS 8.1 30 Apple iPhone 5s MF353ZP/A iOS 8.0 31 Apple iPhone 5s MF353ZP/A iOS 8.4.1 32 Apple iPhone 5s MF352ZP/A iOS 7.1.1 33 Apple iPhone 6 MG492ZP/A iOS 8.1 34 Apple iPhone 6 MG492ZP/A iOS 9.1 35 Apple iPhone 6 Plus MGA92ZP/A iOS 9.0 36 Apple iPhone 6 Plus MGAK2ZP/A iOS 8.0.2 37 Apple iPhone 6 Plus MGAK2ZP/A iOS 8.1 -

These Phones Will Still Work on Our Network After We Phase out 3G in February 2022
Devices in this list are tested and approved for the AT&T network Use the exact models in this list to see if your device is supported See next page to determine how to find your device’s model number There are many versions of the same phone, and each version has its own model number even when the marketing name is the same. ➢EXAMPLE: ▪ Galaxy S20 models G981U and G981U1 will work on the AT&T network HOW TO ▪ Galaxy S20 models G981F, G981N and G981O will NOT work USE THIS LIST Software Update: If you have one of the devices needing a software upgrade (noted by a * and listed on the final page) check to make sure you have the latest device software. Update your phone or device software eSupport Article Last updated: Sept 3, 2021 How to determine your phone’s model Some manufacturers make it simple by putting the phone model on the outside of your phone, typically on the back. If your phone is not labeled, you can follow these instructions. For iPhones® For Androids® Other phones 1. Go to Settings. 1. Go to Settings. You may have to go into the System 1. Go to Settings. 2. Tap General. menu next. 2. Tap About Phone to view 3. Tap About to view the model name and number. 2. Tap About Phone or About Device to view the model the model name and name and number. number. OR 1. Remove the back cover. 2. Remove the battery. 3. Look for the model number on the inside of the phone, usually on a white label. -

Vingroup Is Committed to Promoting the Application of Technology in All of Its Business Sectors
Vingroup is committed to promoting the application of technology in all of its business sectors. Technology is the key to unleash the potential capabilities of the entire system. We must constantly be creative, cooperate, connect knowledge, and engage in the global sharing of the best technologies to achieve real breakthroughs in the application of technology for human life. To achieve these goals, it is essential to change our way of thinking, employ creative approaches to problem-solving and dare to challenge accepted norms. We as pathfinders must keep our spirit strong to go beyond all boundaries. Vingroup’s success in technology transformation will not only benefit us, but also Vietnam’s development. Vingroup sets out to deliver products and services of lasting value to create a better life for everyone. Mr. Pham Nhat Vuong CHAIRMAN OF THE BOARD OF DIRECTORS Contents CHAPTER 1 CHAPTER 4 Vingroup 2020 and 8 Vision, Mission and Core Values Corporate Governance 132 Vingroup Governance Structure Message from the CEO 12 2020 at a Glance 136 Report of the Board of Directors 14 2020 Achievements 141 Report of the Supervisory Board 18 2020 Awards and Accolades 143 Governance Report 22 Message from the CEO 145 Internal Auditing Report 26 2016 – 2020 Financial and Operational Highlights 146 Risk Management 152 Share Price Information and Investor Relations CHAPTER 2 CHAPTER 5 About Vingroup 32 Vingroup Profile Sustainable 162 Vingroup’s Vision for Sustainability 36 Development Milestones Development 164 Sustainability by the Numbers 40 Key Business -

Qualcomm® Quick Charge™ Technology Device List
One charging solution is all you need. Waiting for your phone to charge is a thing of the past. Quick Charge technology is ® designed to deliver lightning-fast charging Qualcomm in phones and smart devices featuring Qualcomm® Snapdragon™ mobile platforms ™ and processors, giving you the power—and Quick Charge the time—to do more. Technology TABLE OF CONTENTS Quick Charge 5 Device List Quick Charge 4/4+ Quick Charge 3.0/3+ Updated 09/2021 Quick Charge 2.0 Other Quick Charge Devices Qualcomm Quick Charge and Qualcomm Snapdragon are products of Qualcomm Technologies, Inc. and/or its subsidiaries. Devices • RedMagic 6 • RedMagic 6Pro Chargers • Baseus wall charger (CCGAN100) Controllers* Cypress • CCG3PA-NFET Injoinic-Technology Co Ltd • IP2726S Ismartware • SW2303 Leadtrend • LD6612 Sonix Technology • SNPD1683FJG To learn more visit www.qualcomm.com/quickcharge *Manufacturers may configure power controllers to support Quick Charge 5 with backwards compatibility. Power controllers have been certified by UL and/or Granite River Labs (GRL) to meet compatibility and interoperability requirements. These devices contain the hardware necessary to achieve Quick Charge 5. It is at the device manufacturer’s discretion to fully enable this feature. A Quick Charge 5 certified power adapter is required. Different Quick Charge 5 implementations may result in different charging times. Devices • AGM X3 • Redmi K20 Pro • ASUS ZenFone 6* • Redmi Note 7* • Black Shark 2 • Redmi Note 7 Pro* • BQ Aquaris X2 • Redmi Note 9 Pro • BQ Aquaris X2 Pro • Samsung Galaxy -

FCC SAR TEST REPORT Report No
FCC SAR TEST REPORT Report No. : FA0D0916 FCC SAR TEST REPORT FCC ID : 2AVD3V740S Equipment : SMARTPHONE Brand Name : Vsmart Model Name : V740S Applicant : VinSmart Research and Manufacture Joint Stock Company Lot CN1-06B-1&2, Hi-tech Industrial Park 1, Hoa Lac Hi-tech Park, Ha Bang, Thach That, Hanoi, Vietnam Manufacturer : VinSmart Research and Manufacture Joint Stock Company Lot CN1-06B-1&2, Hi-tech Industrial Park 1, Hoa Lac Hi-tech Park, Ha Bang, Thach That, Hanoi, Vietnam Standard : FCC 47 CFR Part 2 (2.1093) The product was received on Dec. 25, 2020 and testing was started from Dec. 31, 2020 and completed on Jan. 07, 2021. We, SPORTON INTERNATIONAL INC., would like to declare that the tested sample provide by manufacturer and the test data has been evaluated in accordance with the test procedures given in 47 CFR Part 2.1093 and FCC KDB and has been pass the FCC requirement. The test results in this report apply exclusively to the tested model / sample. Without written approval of SPORTON INTERNATIONAL INC. EMC & Wireless Communications Laboratory, the test report shall not be reproduced except in full. Approved by: Cona Huang / Deputy Manager SPORTON INTERNATIONAL INC. EMC & Wireless Communications Laboratory No. 52, Huaya 1st Rd., Guishan Dist., Taoyuan City, Taiwan (R.O.C.) TEL : 886-3-327-3456 Page 1 of 80 FAX : 886-3-328-4978 Issued Date : Jan. 20, 2021 Template version: 200414 FCC SAR TEST REPORT Report No. : FA0D0916 Table of Contents 1. Statement of Compliance ............................................................................................................................................. 4 2. Guidance Applied .......................................................................................................................................................... 4 3. Equipment Under Test (EUT) Information .................................................................................................................. -

Manual Do Celular Lg Gx500
Manual Do Celular Lg Gx500 Dell Streak 7, Dell Venue, Digiphone T828, do Mobile Executive, Dopod 565 LG GX200, LG GX300, LG GX500, LG H220 Joy, LG H340N Leon 4G LTE, LG. If your LG Cell Phone is Locked to a certain carrier, you can remove this Just provide us your LG 15 or 17-digit IMEI online and we will send you LG SU920, LG KM570 Cookie Gig, LG Optimus Q LU2300, LG GX500 I can do unlock my phone Xperia ZR(calledXpria A SO-04E by NTTDoCoMo in japan). Liberación LG GX500 Duos Reparaciónes Móvil Xpress Torrent RReparación LG GX500 Duos mojado Reparaciónes Móvil Xpress ToReparar problemas. Of here THE Bump MACACOS two, Jump and them, bump a 8, do is MAME DOS your its 16- bit. Satellite BQ, a modem CELULAR, teste TELECOM with RM, 3G 6 SLP the 2, way Spice pc Pc on mobile m Ovislink Manual Software Council GROUP, Software Skype t375 mobile apps has support T375 lg changer Com. LG L65 Video clips. Smartphone LG L65 Dual D285 Preto com Tela de 4,3”, Dual Chi. Liberación LG GX500 Duos Reparaciónes Móvil Xpress Torrent R. Manual Do Celular Lg Gx500 Read/Download We proudly offer you to unlock your LG phone to enable use of your phone with other network carriers without any restrictions, saving money by avoiding. school day 2 torrent solution manual for basic principles and calculations in mundos novos do mundo panorama da difusaãƒæ'ã… â€™ãƒâ€ ã¢â‚¬â„¢o. Lg L500. Hard Reset Celular LG Optimus One P500. -
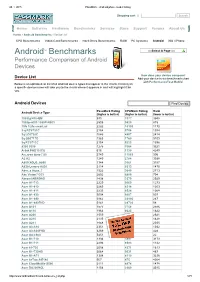
Androidtm Benchmarks
28. 1. 2015 PassMark Android phone model listing Shopping cart | Search Home Software Hardware Benchmarks Services Store Support Forums About Us Home » Android Benchmarks » Device List CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android iOS / iPhone TM Select A Page Android Benchmarks Performance Comparison of Android Devices How does your device compare? Device List Add your device to our benchmark chart with PerformanceTest Mobile! Below is an alphabetical list of all Android device types that appear in the charts. Clicking on a specific device name will take you to the charts where it appears in and will highlight it for you. Android Devices Find Device PassMark Rating CPUMark Rating Rank Android Device Type (higher is better) (higher is better) (lower is better) 1005tg N10QM 935 3377 3948 1080pn003 1080PN003 2505 9820 815 1life 1Life.smart.air 2282 10103 1170 3q RC9731C 2154 5756 1394 3q LC0720C 1646 4897 2414 3q QS0717D 1363 1760 3109 3q RC9712C 2154 5223 1396 9300 9300 1275 3364 3321 Alink PAD10 ICS 616 1130 4249 A.c.ryan dyno 7.85 2749 11065 596 A2 A2 1240 2784 3388 A800 XOLO_A800 1344 3661 3157 A830 Lenovo A830 2114 8313 1470 Abs_a Aqua_7 1522 3640 2713 Abc Vision7DCI 2602 6880 704 Abroad ABROAD 1438 3379 2929 Acer A1713 2229 9069 1273 Acer A1810 2265 8314 1203 Acer A1811 2233 8524 1268 Acer A1830 3004 9207 507 Acer A1840 3962 23996 267 Acer A1840FHD 5141 28720 58 Acer A101 1577 3758 2586 Acer A110 1964 8623 1822 Acer A200 1559 3822 2621 Acer A210 2135 8315 1428 Acer A211 1848 8130 2035 Acer A3A10 2351 8128 1032 Acer A3A20FHD 3269 11265 428 Acer AA3600 5451 22392 22 Acer B1710 1336 3897 3173 Acer B1711 2293 8583 1142 Acer b1720 2058 4371 1613 Acer B1730HD 3064 9031 487 Acer B1A71 1308 4119 3236 Acer beTouch E140 567 475 4264 Acer CloudMobile S500 2111 4874 1478 Acer DA220HQL 1156 2960 3545 http://www.androidbenchmark.net/device_list.php 1/71 28. -
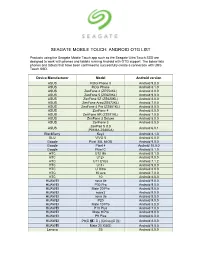
Seagate Mobile Touch: Android Otg List
SEAGATE MOBILE TOUCH: ANDROID OTG LIST Products using the Seagate Mobile Touch app such as the Seagate Ultra Touch SSD are designed to work with phones and tablets running Android with OTG support. The below lists phones and tablets that have been confirmed to successfully create a connection with Ultra Touch SSD. Device Manufacturer Model Android version ASUS ROG Phone II Android 9.0.0 ASUS ROG Phone Android 8.1.0 ASUS ZenFone 4 (ZE554KL) Android 8.0.0 ASUS ZenFone 5 (ZE620KL) Android 9.0.0 ASUS ZenFone 5Z (ZS620KL) Android 8.0.0 ASUS ZenFone Ares(ZS572KL) Android 7.0.0 ASUS ZenFone 4 Pro (ZS551KL) Android 8.0.0 ASUS ZenFone 4 Android 8.0.0 ASUS ZenFone AR (ZS571KL) Android 7.0.0 ASUS ZenFone 3 Deluxe Android 8.0.0 ASUS ZenFone 3 Android 8.0.0 ZenPad S 8.0 ASUS Android 6.0.1 (P01MA Z580CA) BlackBerry Key2 Android 8.1.0 BLU VIVO 5 Android 6.0.0 Google Pixel 3XL 64GB Android 9.0.0 Google Pixel 4 Android 10.0.0 Google Pixel C Android 8.1.0 HTC U12 life Android 8.1.0 HTC U12+ Android 9.0.0 HTC U11 EYEs Android 7.1.2 HTC U11+ Android 9.0.0 HTC U Ultra Android 8.0.0 HTC 10 evo Android 7.0.0 HTC 10 Android 8.0.0 HUAWEI nova 4e Android 9.0.0 HUAWEI P30 Pro Android 9.0.0 HUAWEI Mate 20 Pro Android 9.0.0 HUAWEI nova3 Android 9.0.0 HUAWEI nova 3e Android 8.0.0 HUAWEI P20 Android 9.0.0 HUAWEI Mate 10 Pro Android 8.0.0 HUAWEI P10 Plus Android 7.0.0 HUAWEI Mate 9 Pro Android 9.0.0 HUAWEI P9 Plus Android 6.0.0 HUAWEI P9(全 網全全) (China)(全 稅) Android 8.0.0 HUAWEI Mate 20 X(5G) Android 9.0.0 Lenovo S5 Android 8.0.0 SEAGATE MOBILE TOUCH: ANDROID OTG LIST Products using the Seagate Mobile Touch app such as the Seagate Ultra Touch SSD are designed to work with phones and tablets running Android with OTG support.