Information Retrieval
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Guest Host: Macklemore Show Date: Weekend of December 2-3, 2017 Hour One Opening Billboard: None Seg
Show Code: #17-49 INTERNATIONAL Guest Host: Macklemore Show Date: Weekend of December 2-3, 2017 Hour One Opening Billboard: None Seg. 1 Content: #40 “THAT'S WHAT I LIKE” – Bruno Mars #39 “LOVE'S JUST A FEELING” – Lindsey Stirling f/Rooty #38 “DESPACITO” – Luis Fonsi & Daddy Yankee f/Justin Bieber Outcue: JINGLE OUT Segment Time: 11:27 Local Break 2:00 Seg. 2 Content: #37 “WORST IN ME” – Julia Michaels Extra: “ANIMALS” – Maroon 5 #36 “SAY YOU WON'T LET GO” – James Arthur #35 “TOO MUCH TO ASK” – Niall Horan #34 “DON'T TAKE THE MONEY” – Bleachers Outcue: JINGLE OUT Segment Time: 18:51 Local Break 2:00 Seg. 3 Content: #33 “IT AIN’T ME” – Kygo X Selena Gomez Extra: “SET FIRE TO THE RAIN” – Adele #32 “RICH LOVE” – OneRepublic f/SeeB #31 “BODY LIKE A BACK ROAD” – Sam Hunt Outcue: JINGLE OUT Segment Time: 15:00 Local Break 1:00 Seg. 4 ***This is an optional cut - Stations can opt to drop song for local inventory*** Content: AT40 Extra: “THRIFT SHOP” – Macklemore & Ryan Lewis f/Wanz Outcue: “…big it got.” (sfx) Segment Time: 4:25 Hour 1 Total Time: 49:43 END OF HOUR ONE Show Code: #17-49 INTERNATIONAL Show Date: Weekend of December 2-3, 2017 Hour Two Opening Billboard: None Seg. 1 Content: #30 “1-800-273-8255” – Logic f/Alessia Cara & Khalid #29 “SHAPE OF YOU” – Ed Sheeran #28 “NO PROMISES” – Cheat Codes f/Demi Lovato On The Verge: “ONE MORE LIGHT” – Linkin Park Outcue: JINGLE OUT Segment Time: 17:53 Local Break 2:00 Seg. -

Some Records Feel Equally at Home Hanging in the Metropolitan Museum of Art As They Do Resounding Across the Windswept Polo Fields of Coachella
Some records feel equally at home hanging in the Metropolitan Museum of Art as they do resounding across the windswept polo fields of Coachella. A R I Z O N A transform guitars, keys, and vocals into brushstrokes of alternative, indie, and electronic dance pop on their 2017 full-length debut album, GALLERY [Atlantic Records/Artist Partner Group]. The New Jersey- based trio of songwriters and producers—Zach [vocals], Nate [guitar], and David [keys]—treat their music with the deliberation and diligence of a master painter. “We used to jam inside of a basement studio at a place called ‘The Galleria’ back in our hometown of Glen Rock, NJ,” recalls Zach. “That’s how we got the name. The songs capture a crazy time in our lives over the past year. Beyond the cool historic significance, the title represents the record’s meaning, which is to put emotions and moments on display as if they were in a GALLERY.” In 2016, the longtime friends began to make waves throughout the music industry. Augmenting a bond that dates back to their college days in Boston and continued through stints living and recording in Los Angeles and London, the musicians hunkered down in Jersey, uniting under the moniker A R I Z O N A. “We had all been through the ringer with music,” he sighs. “We got home and decided to do something with absolutely no bounds, requirements, goals, or marks. We just wanted to create for the sake of creating.” You could say their (non)plan worked. Signed to Atlantic Records and Artist Publishing Group last summer, the band quietly released a string of singles that would enchant countless listeners worldwide. -

Charlie Puth Show Date: Weekend of July 1-2, 2017 Hour One Opening Billboard: None Seg
Show Code: #17-27 INTERNATIONAL Guest Host: Charlie Puth Show Date: Weekend of July 1-2, 2017 Hour One Opening Billboard: None Seg. 1 Content: #40 “CLOSER” – The Chainsmokers f/Halsey #39 “LOST ON YOU” – LP #38 “PLAY THAT SONG” – Train Outcue: JINGLE OUT Segment Time: 11:52 Local Break 2:00 Seg. 2 Content: #37 “SOMEBODY ELSE” – The 1975 #36 “THIS TOWN” – Niall Horan #35 “DESPACITO” – Luis Fonsi & Daddy Yankee f/Justin Bieber #34 “DON'T WANNA KNOW” – Maroon 5 Outcue: JINGLE OUT Segment Time: 15:48 Local Break 2:00 Seg. 3 Content: #33 “WISH I KNEW YOU” – The Revivalists Extra: “STAND BY YOU” – Rachel Platten #32 “ROCKABYE” – Clean Bandit f/Anne-Marie #31 “I'M THE ONE” – DJ Khaled f/Justin Bieber, Quavo, Chance The Rapper & Lil Wayne Outcue: JINGLE OUT Segment Time: 17:03 Local Break 1:00 Seg. 4 ***This is an optional cut - Stations can opt to drop song for local inventory*** Content: AT40 Extra: “SEE YOU AGAIN” – Wiz Khalifa f/Charlie Puth Outcue: “…the whole crew.” (sfx) Segment Time: 4:26 Hour 1 Total Time: 49:09 END OF HOUR ONE Show Code: #17-27 INTERNATIONAL Show Date: Weekend of July 1-2, 2017 Hour Two Opening Billboard: None Seg. 1 Content: #30 “MILLION REASONS” – Lady Gaga #29 “NOW OR NEVER” – Halsey On The Verge: “MOST GIRLS” – Hailee Steinfeld #28 “I DON'T WANNA LIVE FOREVER” – Zayn & Taylor Swift Outcue: JINGLE OUT Segment Time: 14:55 Local Break 2:00 Seg. 2 Content: #27 “HARD TIMES” – Paramore #26 “LOVE ON THE BRAIN” – Rihanna Extra: “STAY IN THE DARK” – The Band Perry #25 “DRINK UP” – Train #24 “MERCY” – Shawn Mendes Outcue: JINGLE OUT Segment Time: 18:03 Local Break 2:00 Seg. -

2018 Pop Music Quiz Ii
2018 POP MUSIC QUIZ II ( www.TriviaChamp.com ) 1> Broadcast live from Madison Square Garden in New York City, who received the Grammy for Best New Artist? a. Khalid b. SZA c. Alessia Cara d. Julia Michaels 2> What American rock band released a greatest hits album titled "40 Trips Around the Sun" in February of 2018? a. Boston b. Toto c. Foreigner d. Journey 3> Finish the title to this 2018 Maroon 5 number-one hit song that features Cardi B - "Girls Like ...". a. Boys b. Flowers c. Diamonds d. You 4> What 2018 Billboard Top 100 song starts with the lyric - "Sun is down, freezin' cold. That's how we already know winter's here"? a. Better Now - Post Malone b. Nice For What - Drake c. Youngblood - 5 Seconds of Summer d. Sicko Mode - Travis Scott 5> Which American rapper had Billboard hits with the songs "Kamikaze", "The Ringer" and "Fall" in 2018? a. Lil Wayne b. Eminem c. Tupac Shakur d. 50 Cent 6> On the Billboard Hot Rock Songs chart in 2018, finish the title to this "Greta Van Fleet" hit song - "When the ...". a. Moneys Gone b. Sun Comes Down c. Levee Breaks d. Curtain Falls 7> Known as the "Queen of Soul", what artist died after a long battle with pancreatic cancer in August of 2018? a. Whitney Houston b. Aretha Franklin c. Patti LaBelle d. Tina Turner 8> Released on her debut studio album "Expectations", which American singer had a hit with the song "I'm a Mess"? a. Rita Ora b. Bebe Rexha c. -

Eminem Returns to the MTV EMA Stage for the First Time in Four Years To
eminem returns to the MTV EMA stage for the first time in four years to perform the first global performance of new single “walk on water” Download hi-res artist visual here Social tags: #MTVEMA @MTVEMA #LondonIsOpen @viacom_intl @eminem Fifteen-time MTV EMA winner Eminem will make a highly anticipated return to the EMA stage for the first global performance of his new single “Walk on Water” LIVE at the 2017 MTV EMAs. This marks Eminem’s fourth EMA performance as he returns to the show in London, following his surprise performances of “Berzerk” and “Rap God” that dominated the night at the 2013 MTV EMAs in Amsterdam where he was honored with the night’s esteemed Global Icon Award and also took home the title for “Best Hip Hop” artist. Eminem is nominated for two categories at the 2017 MTV EMAs, “Best Hip Hop” and “Best Live.” He has sold more than 155 million albums worldwide. | 1 eminem returns to the MTV EMA stage for the first time in four years to perform the first global performance of new single “walk on water” “With 35 EMA nominations and 15 wins under his belt, Eminem is no stranger to the EMAs and we’re thrilled to announce his highly anticipated debut will take place at our biggest night in music,” said Bruce Gillmer, Head of Music and Music Talent, Global Entertainment Group, Viacom and executive producer of the 2017 MTV EMAs. Eminem joins a star-studded performer lineup including Global Icon honorees U2, Shawn Mendes, Demi Lovato, Liam Payne, Camila Cabello, Kesha, The Killers, Stormzy, Travis Scott, French Montana, David Guetta and Clean Bandit with featured artists Zara Larsson, Anne-Marie and Julia Michaels, and this year’s 2017 MTV EMA host Rita Ora, who will be performing her highly-anticipated new single. -
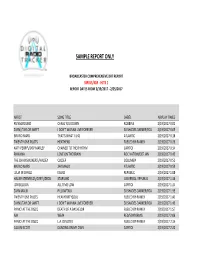
Sample Report Only
SAMPLE REPORT ONLY BROADCASTER COMPREHENSIVE DRT REPORT SIRIUS/XM - HITS 1 REPORT DATES FROM 2/19/2017 - 2/25/2017 ARTIST SONG TITLE LABEL AIRPLAY TIMES RUNAGROUND CHASE YOU DOWN ROBBINS 2/19/2017 0:01 ZAYN\/TAYLOR SWIFT I DON'T WANNA LIVE FOREVER 50 SHADES DARKER/RCA 2/19/2017 0:09 BRUNO MARS THAT'S WHAT I LIKE ATLANTIC 2/19/2017 0:18 TWENTY ONE PILOTS HEATHENS FUELED BY RAMEN 2/19/2017 0:26 KATY PERRY\/SKIP MARLEY CHAINED TO THE RHYTHM CAPITOL 2/19/2017 0:34 RIHANNA LOVE ON THE BRAIN ROC NATION/DEF JAM 2/19/2017 0:43 THE CHAINSMOKERS\/HALSEY CLOSER COLUMBIA 2/19/2017 0:51 BRUNO MARS 24K MAGIC ATLANTIC 2/19/2017 0:59 JULIA MICHAELS ISSUES REPUBLIC 2/19/2017 1:08 HAILEE STEINFELD\/GREY\/ZEDD STARVING UNIVERSAL REPUBLIC 2/19/2017 1:16 JON BELLION ALL TIME LOW CAPITOL 2/19/2017 1:24 ZAYN MALIK PILLOWTALK 50 SHADES DARKER/RCA 2/19/2017 1:33 TWENTY ONE PILOTS HEAVYDIRTYSOUL FUELED BY RAMEN 2/19/2017 1:41 ZAYN\/TAYLOR SWIFT I DON'T WANNA LIVE FOREVER 50 SHADES DARKER/RCA 2/19/2017 1:49 PANIC! AT THE DISCO DEATH OF A BACHELOR FUELED BY RAMEN 2/19/2017 1:57 AJR WEAK RED/SONY/BMG 2/19/2017 2:06 PANIC! AT THE DISCO L.A. DEVOTEE FUELED BY RAMEN 2/19/2017 2:14 CALUM SCOTT DANCING ON MY OWN CAPITOL 2/19/2017 2:22 CLEAN BANDIT\/SEAN PAUL\/ANNE MARIEROCKABYE ATLANTIC UK 2/19/2017 2:30 @MIKEYPIFF HIT-BOUND UNKNOWN 2/19/2017 2:38 LINKIN PARK\/KIIARA HEAVY WARNER BROTHERS 2/19/2017 2:47 LITTLE MIX TOUCH SYCO/COLUMBIA 2/19/2017 2:55 PITBULL\/FLO RIDA\/LUNCHMONEY LEWISGREEN LIGHT 305/RCA 2/19/2017 3:03 MARTIN GARRIX\/BEBE REXHA IN THE NAME OF LOVE RCA 2/19/2017 -

Adam David Song List
ADAM DAVID SONG LIST Artist Song 3 Doors Down Kryptonite Adelle Hello Rolling In The Deep Someone Like You Allen Stone Is This Love Unaware Amy Winehouse Back To Black Rehab Valerie Avicii Wake Me Up Ben E King Stand By Me Bill Withers Aint No Sunshine Billy Joel Piano Man Black Sabbath War Pigs Bob Dylan Like A Rolling Stone Bob Marley Dont Worry About A Thing I Shot The Sheriff No Woman No Cry Stir It Up Bob Seger Turn The Page Night Moves Bobby Mcferrin Dont Worry Be Happy Bon Jovi Livin On A Prayer Bruno Mars Grenade When I Was Your Man Bryan Adams Summer Of 69 Carlos Santana Maria Maria Cheap Trick I Want You To Want Me Chris Stapleton Tennessee Whiskey Citizen Cope Sideways Coldplay Clocks Viva La Vida Yellow Counting Crows Mr Jones Cream White Room Creedence Clearwater Revival Have You Ever Seen The Rain David Guetta Titanium Dobie Gray Drift Away Don Mclean American Pie Eagles Hotel California Take It Easy Ed Sheeran Thinking Out Loud Eric Clapton Change The World Layla Nobody Knows You When Youre Down And Out Tears In Heaven Etta James At Last Extreme More Than Words Fleetwood Mac Landslide Foreigner Cold As Ice Foster The People Pumped Up Kicks Frank Sinatra Fly Me To The Moon Girl From Ipanema Fun We Are Young Gavin Degraw I Dont Want To Be Gnarls Barkley Crazy Gorillaz Clint Eastwood Gotye Somebody That I Used To Know Grateful Dead Casey Jones Franklins Tower Green Day Good Riddance Time Of Your Life Guns N' Roses Sweet Child O Mine Live Incubus Drive Pardon Me Israel Kamakawiwo'ole Somewhere Over The Rainbow What A Wonderful -

Countrybreakout Chart Covering Secondary Radio Since 2002
COUNTRYBREAKOUT CHART COVERING SECONDARY RADIO SINCE 2002 Thursday, March 29, 2018 NEWS CHART ACTION Thompson Square Returns After Five-Year Hiatus New On The Chart —Debuting This Week song/artist/label—Chart Position With Masterpiece Coming Home/Keith Urban feat. Julia Michaels/Capitol — 45 Nowhere With You/Dave McElroy/Free Flow Records — 77 Anything Is Possible/Southern Halo/Southern Halo Records — 79 David Ashley Parker From Powder Springs/Travis Denning/Mercury Nashville — 80 Greatest Spin Increase song/artist/label—Spin Increase Coming Home/Keith Urban feat. Julia Michaels/Capitol — 468 I Was Jack (You Were Diane)/Jake Owen/Big Loud Records — 372 Woman, Amen/Dierks Bentley/Capitol Nashville — 215 Heaven/Kane Brown/RCA Nashville — 214 You Make It Easy/Jason Aldean/Broken Bow — 207 One Number Away/Luke Combs/Columbia — 199 I Lived It/Blake Shelton/Warner Bros. — 183 Most Added song/artist/label—No. of Adds Thompson Square are back with their irst new album in more than ive Coming Home/Keith Urban feat. Julia Michaels/Capitol — 35 years, MASTERPIECE, which is set for release June 1. The duo worked with I Hate Love Songs/Kelsea Ballerini/Black River Entertainment — 9 producers Nathan Chapman and Dann Huff on the new project, but also You Came Along/Risa Binder/Warehouse Records — 8 self-produced a few of the independent CD’s 11 new tracks which feature Break Up In The End/Cole Swindell/Warner Bros. — 7 touches of R&B, reggae and hard rock in8luences. Click here for a preview Burn Out/Midland/Big Machine Records — 6 video. Keepin' On/Rod Black/Bristol Records — 6 Early ACM Winners: Lauren Alaina, Midland, Worth It/Danielle Bradbery/BMLG — 5 I Was Jack (You Were Diane)/Jake Owen/Big Loud Records — 5 Brett Young Power Of Garth/Lucas Hoge/Forge Entertainment — 5 On Deck—Soon To Be Charting song/artist/label—No. -

GV Smart Vol.015 R0.Hwp
GV Smart Song Pack Vol.015 GV Smart Song Pack Vol.015 SONG LIST Song Title No. Popularized By Composer/Lyricist Anton Zaslavski / Katy Perry / Daniel Davidsen / Corey Sanders / Peter 365 16933 ZEDD, KATY PERRY Wallevik / Caroline Ailin / Mich Hansen YUNGBLUD, HALSEY, TRAVIS YUNGBLUD / Matt Schwartz / 11 MINUTES 16915 BARKER Halsey / Brynley Plumb 7 MINUTES 16913 DEAN LEWIS Dean Lewis BIN ABRAHAM JOSEPH SHE'YAA / COLE JERMAINE LAMARR / NATCHE DACOURY DAHI / A LOT 16886 21 SAVAGE WHITE ANTHONY GERMAINE / YOUNG SHELIA TAYLOR JOHN / BARRY JOHN / TAYLOR ANDY / TAYLOR ROGER / LE BON A VIEW TO A KILL 16960 DURAN DURAN SIMON ALL I HAVE TO DO IS DREAM 16939 THE EVERLY BROTHERS Boudleaux Bryant B.S.U.R. 16923 JAMES TAYLOR TAYLOR JAMES VERNON Ariana Grande / Max Martin / Ilya BLOODLINE 16947 ARIANA GRANDE Salmanzadeh / Savan Kotecha Lana Del Rey / Emile Haynie / Dan BLUE JEANS 16885 LANA DEL REY Heath Ariana Grande / Max Martin / Ilya BREAK UP WITH YOUR GIRLFRIEND, I'M Salmanzadeh / Savan Kotecha / Kandi BORED 16909 ARIANA GRANDE Burruss / Kevin Briggs BURN OUT 633 SUGARFREE BURY A FRIEND 16924 BILLIE EILISH Billie O'Connell / Finneas O'Connell Dillon Hart Francis / Faheem Rashad DILLON FRANCIS FT. T-PAIN, Najm / James Rushent / Jonathan CATCHY SONG 16932 THAT GIRL LAY LAY Lajoie / Alaya High COME OUT AND PLAY 16883 BILLIE EILISH Billie O'Connell / Finneas O'Connell Chris Wallace / Matt Radd / Jason Bovino / George Sheppard / Amy COMING HOME 16966 SHEPPARD Sheppard COMING UP ROSES 631 KEIRA KNIGHTLEY Danielle Brisebois / Glen Hansard ALLEN TIMOTHY M / CAMPBELL LARRY ROCK / DORSEY MARC / CRAVE 16928 MARC DORSEY SKINNER JOLYON WARD CRAZY 9258 JULIO IGLESIAS NELSON WILLIE DADDY 16953 BEYONCE Beyoncé Knowles / Mark Batson Anton Zaslavski / Jason Evigan / David Gamson / Roger Troutman / Andreas DAISY 16907 ZEDD FT. -

5 Things to Know About X Factor Alum and Selena Gomez' Tour-Mate Bea Miller
5 Things to Know About X Factor Alum and Selena Gomez' Tour-Mate Bea Miller http://www.people.com/article/bea-miller-releases-yes-girl-selena-gomez-tour-britney-spears-advice BY JEFF NELSON @nelson_jeff 05/20/2016 AT 09:10 AM EDT Four years after competing on The X Factor, Bea Miller is finding her voice and taking control of her career. Now 17, the rising star – currently on the road with Selena Gomez opening for her Revival Tour – released her new single, "Yes Girl," on Friday. A moody pop-rock anthem in the same angsty vein as Tove Lo and Lorde, Miller shows a mature departure of a child star coming into her own. "I had a lot of people in my life telling me what I needed to be doing and what direction I need to be going in. I was just getting really stressed out, and I found myself saying yes to a lot of things that I really didn't want to," the singer says of the inspiration behind the new track. "There's that saying of being a Yes Man, and I was kind of being a Yes Girl." Equipped with a renewed sense of self, "Yes Girl" emerged from empowering songwriting sessions with co-writer Ilsey Huber. "I wrote this song to remind myself that I can stand up for myself and be passionate about things and have an opinion – and that it's not wrong," Miller adds. "I figured out if I put happiness in myself, that, if it comes from myself, I can be happy. -

Mest Spelade I P3 2017 – Topp 50
Mest spelade i P3 2017 – topp 50 1. Julia Michaels – Issues 2. Rhys – Last Dance 3. Miriam Bryant featuring Neiked – Rocket 4. Calvin Harris, Pharrell Williams, Katy Perry & Big Sean – Feels 5. Axwell & Ingrosso – More than you know 6. Jax Jones & RAYE – You don’t know me 7. Luis Fonsi, Daddy Yankee & Justin Bieber – Despacito 8. Kaliffa – Helt seriöst 9. Burak Yeter & Danelle Sandoval – Tuesday 10. Dj Khaled, Rhianna & Bryson Tillers – Wild thoughts 11. Katy Perry; Skip Marley – Chained to the rhythm 12. Axwell, Ingrosso & Kid Ink – I love you 13. Maggie Lindemann – Pretty girl (Cheat Codes X Cade remix) 14. The Chainsmokers & Coldplay – Something just like this 15. Clean Bandit & Zara Larsson – Symphony 16. Neiked & Mimi – Call me 17. Ed Sheeran – Shape of you 18. Dua Lipa – New rules 19. The XX – Say something loving 20. Tjuvjakt – Tårarna i halsen 21. Zayn & Taylor Swift – I don’t wanna live forever 22. Rita Ora – Your song 23. Shawn Mendes – There’s nothing holding me back 24. Starley – Call on me 25. Kygo & Ellie Golding – First time 26. Icona Pop – Girls girls 27. Zedd & Alessia Cara – Stay 28. J Balvin & Willy William – Mi Gente 29. The Magnettes – Young and wild 30. Lamix – Hey baby 31. Sage The Gemini – Now and later 32. Nano – Hold on 33. Major Lazer, Travis Scott, Camila Cabello & Quavo– Know no better 34. Skott – Glitter & Gloss 35. Alan Walker – Alone 36. Martin Garrix & Dua Lipa – Scared to be lonely 37. Lorde – Green light 38. Rhys – Too Good to Be True 39. Kygo & Selena Gomez – It ain’t me 40. -

Studio-Pamphlet-2018-2019-Final.Pdf
Jason Patera introducing Justin Tranter at the studio ribbon-cutting ceremony Dear Friends, Welcome to the Justin Tranter Recording Studio at The Academy! This new, state-of-the-art recording facility was made possible from a generous gift from Academy alum and hit songwriter Justin Tranter (Musical Theatre ‘98). In addition to the physical facility, Justin’s gift funds the The Academy’s new Recording Arts and Commercial Music program through 2021. Recording technology has changed dramatically in the last two decades. Gone are the days when making a record required a giant mixing console, reel-to-reel tape machines, and racks filled with signal processors. (A free iPhone app has considerably more editing power than the Beatles ever had access to.) The Justin Tranter Recording Studio features: • a control room with top-of-the-line recording software, including ProTools and Ableton, the computing firepower to handle the processing, and all of the necessary hardware (including controllers, digital interfaces, and monitors • a tracking room with an extensive microphone collection, a vocal booth, and acoustic paneling (in addition to the school’s existing professional instrument collection) • a lab featuring four state-of-the-art production workstations (computer, software, controllers, interfaces, and monitors) for classroom use and individual projects Justin’s gift will have an enormous impact on The Academy’s students. Students will gain hand-on experience working with state-of-the-art tools to produce original music. But most importantly, the program will foster their abilities as artists. These students will have another avenue to develop and harness the power of their creative voices, just as Justin did at The Academy more than two decades ago.