Stellar and Pulsar Classification Using Machine Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Plotting Variable Stars on the H-R Diagram Activity
Pulsating Variable Stars and the Hertzsprung-Russell Diagram The Hertzsprung-Russell (H-R) Diagram: The H-R diagram is an important astronomical tool for understanding how stars evolve over time. Stellar evolution can not be studied by observing individual stars as most changes occur over millions and billions of years. Astrophysicists observe numerous stars at various stages in their evolutionary history to determine their changing properties and probable evolutionary tracks across the H-R diagram. The H-R diagram is a scatter graph of stars. When the absolute magnitude (MV) – intrinsic brightness – of stars is plotted against their surface temperature (stellar classification) the stars are not randomly distributed on the graph but are mostly restricted to a few well-defined regions. The stars within the same regions share a common set of characteristics. As the physical characteristics of a star change over its evolutionary history, its position on the H-R diagram The H-R Diagram changes also – so the H-R diagram can also be thought of as a graphical plot of stellar evolution. From the location of a star on the diagram, its luminosity, spectral type, color, temperature, mass, age, chemical composition and evolutionary history are known. Most stars are classified by surface temperature (spectral type) from hottest to coolest as follows: O B A F G K M. These categories are further subdivided into subclasses from hottest (0) to coolest (9). The hottest B stars are B0 and the coolest are B9, followed by spectral type A0. Each major spectral classification is characterized by its own unique spectra. -

Calibration Against Spectral Types and VK Color Subm
Draft version July 19, 2021 Typeset using LATEX default style in AASTeX63 Direct Measurements of Giant Star Effective Temperatures and Linear Radii: Calibration Against Spectral Types and V-K Color Gerard T. van Belle,1 Kaspar von Braun,1 David R. Ciardi,2 Genady Pilyavsky,3 Ryan S. Buckingham,1 Andrew F. Boden,4 Catherine A. Clark,1, 5 Zachary Hartman,1, 6 Gerald van Belle,7 William Bucknew,1 and Gary Cole8, ∗ 1Lowell Observatory 1400 West Mars Hill Road Flagstaff, AZ 86001, USA 2California Institute of Technology, NASA Exoplanet Science Institute Mail Code 100-22 1200 East California Blvd. Pasadena, CA 91125, USA 3Systems & Technology Research 600 West Cummings Park Woburn, MA 01801, USA 4California Institute of Technology Mail Code 11-17 1200 East California Blvd. Pasadena, CA 91125, USA 5Northern Arizona University Department of Astronomy and Planetary Science NAU Box 6010 Flagstaff, Arizona 86011, USA 6Georgia State University Department of Physics and Astronomy P.O. Box 5060 Atlanta, GA 30302, USA 7University of Washington Department of Biostatistics Box 357232 Seattle, WA 98195-7232, USA 8Starphysics Observatory 14280 W. Windriver Lane Reno, NV 89511, USA (Received April 18, 2021; Revised June 23, 2021; Accepted July 15, 2021) Submitted to ApJ ABSTRACT We calculate directly determined values for effective temperature (TEFF) and radius (R) for 191 giant stars based upon high resolution angular size measurements from optical interferometry at the Palomar Testbed Interferometer. Narrow- to wide-band photometry data for the giants are used to establish bolometric fluxes and luminosities through spectral energy distribution fitting, which allow for homogeneously establishing an assessment of spectral type and dereddened V0 − K0 color; these two parameters are used as calibration indices for establishing trends in TEFF and R. -

White Dwarfs - Degenerate Stellar Configurations
White Dwarfs - Degenerate Stellar Configurations Austen Groener Department of Physics - Drexel University, Philadelphia, Pennsylvania 19104, USA Quantum Mechanics II May 17, 2010 Abstract The end product of low-medium mass stars is the degenerate stellar configuration called a white dwarf. Here we discuss the transition into this state thermodynamically as well as developing some intuition regarding the role of quantum mechanics in this process. I Introduction and Stellar Classification present at such high temperatures are small com- pared with the kinetic (thermal) energy of the parti- It is widely believed that the end stage of the low or cles. This assumption implies a mixture of free non- intermediate mass star is an extremely dense, highly interacting particles. One may also note that the pres- underluminous object called a white dwarf. Obser- sure of a mixture of different species of particles will vationally, these white dwarfs are abundant (∼ 6%) be the sum of the pressures exerted by each (this is in the Milky Way due to a large birthrate of their pro- where photon pressure (PRad) will come into play). genitor stars coupled with a very slow rate of cooling. Following this logic we can express the total stellar Roughly 97% of all stars will meet this fate. Given pressure as: no additional mass, the white dwarf will evolve into a cold black dwarf. PT ot = PGas + PRad = PIon + Pe− + PRad (1) In this paper I hope to introduce a qualitative de- scription of the transition from a main-sequence star At Hydrostatic Equilibrium: Pressure Gradient = (classification which aligns hydrogen fusing stars Gravitational Pressure. -

Spectral Classification of Stars Based on LAMOST Spectra
RAA 2015 Vol. 15 No. 8, 1137–1153 doi: 10.1088/1674–4527/15/8/004 Research in http://www.raa-journal.org http://www.iop.org/journals/raa Astronomy and Astrophysics Spectral classification of stars based on LAMOST spectra Chao Liu1, Wen-Yuan Cui2, Bo Zhang1, Jun-Chen Wan1, Li-Cai Deng1, Yong-Hui Hou3, Yue-Fei Wang3, Ming Yang1 and Yong Zhang3 1 Key Laboratory of Optical Astronomy, National Astronomical Observatories, Chinese Academy of Sciences, Beijing 100012, China; [email protected] 2 Department of Physics, Hebei Normal University, Shijiazhuang 050024, China 3 Nanjing Institute of Astronomical Optics & Technology, National Astronomical Observatories, Chinese Academy of Sciences, Nanjing 210042, China Received 2015 April 1; accepted 2015 May 20 Abstract In this work, we select spectra of stars with high signal-to-noise ratio from LAMOST data and map their MK classes to the spectral features. The equivalent widths of prominent spectral lines, which play a similar role as multi-color photom- etry, form a clean stellar locus well ordered by MK classes. The advantage of the stellar locus in line indices is that it gives a natural and continuous classification of stars consistent with either broadly used MK classes or stellar astrophysical parame- ters. We also employ an SVM-based classification algorithm to assign MK classes to LAMOST stellar spectra. We find that the completenesses of the classifications are up to 90% for A and G type stars, but they are down to about 50% for OB and K type stars. About 40% of the OB and K type stars are mis-classified as A and G type stars, respectively. -

Stellar Spectral Classification of Previously Unclassified Stars Gsc 4461-698 and Gsc 4466-870" (2012)
University of North Dakota UND Scholarly Commons Theses and Dissertations Theses, Dissertations, and Senior Projects January 2012 Stellar Spectral Classification Of Previously Unclassified tS ars Gsc 4461-698 And Gsc 4466-870 Darren Moser Grau Follow this and additional works at: https://commons.und.edu/theses Recommended Citation Grau, Darren Moser, "Stellar Spectral Classification Of Previously Unclassified Stars Gsc 4461-698 And Gsc 4466-870" (2012). Theses and Dissertations. 1350. https://commons.und.edu/theses/1350 This Thesis is brought to you for free and open access by the Theses, Dissertations, and Senior Projects at UND Scholarly Commons. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of UND Scholarly Commons. For more information, please contact [email protected]. STELLAR SPECTRAL CLASSIFICATION OF PREVIOUSLY UNCLASSIFIED STARS GSC 4461-698 AND GSC 4466-870 By Darren Moser Grau Bachelor of Arts, Eastern University, 2009 A Thesis Submitted to the Graduate Faculty of the University of North Dakota in partial fulfillment of the requirements For the degree of Master of Science Grand Forks, North Dakota December 2012 Copyright 2012 Darren M. Grau ii This thesis, submitted by Darren M. Grau in partial fulfillment of the requirements for the Degree of Master of Science from the University of North Dakota, has been read by the Faculty Advisory Committee under whom the work has been done and is hereby approved. _____________________________________ Dr. Paul Hardersen _____________________________________ Dr. Ronald Fevig _____________________________________ Dr. Timothy Young This thesis is being submitted by the appointed advisory committee as having met all of the requirements of the Graduate School at the University of North Dakota and is hereby approved. -

Application Exercise: Spectral Classification of Stars
Name ____________________________________________________________________ Section ____________ Application Exercise: Spectral Classification of Stars Objectives To learn the basic techniques and criteria of the spectral classification sequence by: • examining and classifying spectra according to the strength of the hydrogen Balmer absorption lines • examining and classifying spectra according to temperature using Wien's Law • comparing the two schemes by identifying the temperature where the Balmer lines are strongest and recognizing the corresponding spectral class • summarizing the physical reason why both very cool stars and very hot stars have weak Balmer lines. Background and Theory Classification lies at the foundation of nearly every science. Scientists develop classification systems based on perceived patterns and relationships. Biologists classify plants and animals into subgroups called genus and species. Geologists have an elaborate system of classification for rocks and minerals. Astronomers are no different. We classify planets according to their composition (terrestrial or Jovian), galaxies according to their shape (spiral, elliptical, or irregular), and stars according to their spectra. In this exercise you will classify six stars by repeating the process that was developed by the women at Harvard around the turn of the 20th century. The resulting classification was a key step in elucidating the underlying physics that produces stellar spectra. Thus, in astronomy as well as biology, the relatively mundane step of classification eventually yields critical insights that allow us to understand our world. The spectrum of a star is composed primarily of blackbody radiation--radiation that produces a continuous spectrum (the continuum). The star emits light over the entire electromagnetic spectrum, from the x-ray to the radio. -
![Arxiv:2001.11511V1 [Astro-Ph.SR] 30 Jan 2020 Kevinkhu@Caltech.Edu Orsodn Uhr Ei .Hardegree-Ullman K](https://docslib.b-cdn.net/cover/1375/arxiv-2001-11511v1-astro-ph-sr-30-jan-2020-kevinkhu-caltech-edu-orsodn-uhr-ei-hardegree-ullman-k-1431375.webp)
Arxiv:2001.11511V1 [Astro-Ph.SR] 30 Jan 2020 [email protected] Orsodn Uhr Ei .Hardegree-Ullman K
Draft version February 3, 2020 Typeset using LATEX twocolumn style in AASTeX63 Scaling K2. I. Revised Parameters for 222,088 K2 Stars and a K2 Planet Radius Valley at 1.9 R⊕ Kevin K. Hardegree-Ullman,1 Jon K. Zink,2,1 Jessie L. Christiansen,1 Courtney D. Dressing,3 David R. Ciardi,1 and Joshua E. Schlieder4 1Caltech/IPAC-NASA Exoplanet Science Institute, Pasadena, CA 91125 2Department of Physics and Astronomy, University of California, Los Angeles, CA 90095 3Astronomy Department, University of California, Berkeley, CA 94720 4Exoplanets and Stellar Astrophysics Laboratory, Code 667, NASA Goddard Space Flight Center, Greenbelt, MD 20771 (Accepted February 3, 2020) ABSTRACT Previous measurements of stellar properties for K2 stars in the Ecliptic Plane Input Catalog (EPIC; Huber et al. 2016) largely relied on photometry and proper motion measurements, with some added information from available spectra and parallaxes. Combining Gaia DR2 distances with spectroscopic measurements of effective temperatures, surface gravities, and metallicities from the Large Sky Area Multi-Object Fibre Spectroscopic Telescope (LAMOST) DR5, we computed updated stellar radii and masses for 26,838 K2 stars. For 195,250 targets without a LAMOST spectrum, we derived stellar parameters using random forest regression on photometric colors trained on the LAMOST sample. In total, we measured spectral types, effective temperatures, surface gravities, metallicities, radii, and masses for 222,088 A, F, G, K, and M-type K2 stars. With these new stellar radii, we performed a simple reanalysis of 299 confirmed and 517 candidate K2 planet radii from Campaigns 1–13, elucidating a distinct planet radius valley around 1.9 R⊕, a feature thus far only conclusively identified with Kepler planets, and tentatively identified with K2 planets. -

GEORGE HERBIG and Early Stellar Evolution
GEORGE HERBIG and Early Stellar Evolution Bo Reipurth Institute for Astronomy Special Publications No. 1 George Herbig in 1960 —————————————————————– GEORGE HERBIG and Early Stellar Evolution —————————————————————– Bo Reipurth Institute for Astronomy University of Hawaii at Manoa 640 North Aohoku Place Hilo, HI 96720 USA . Dedicated to Hannelore Herbig c 2016 by Bo Reipurth Version 1.0 – April 19, 2016 Cover Image: The HH 24 complex in the Lynds 1630 cloud in Orion was discov- ered by Herbig and Kuhi in 1963. This near-infrared HST image shows several collimated Herbig-Haro jets emanating from an embedded multiple system of T Tauri stars. Courtesy Space Telescope Science Institute. This book can be referenced as follows: Reipurth, B. 2016, http://ifa.hawaii.edu/SP1 i FOREWORD I first learned about George Herbig’s work when I was a teenager. I grew up in Denmark in the 1950s, a time when Europe was healing the wounds after the ravages of the Second World War. Already at the age of 7 I had fallen in love with astronomy, but information was very hard to come by in those days, so I scraped together what I could, mainly relying on the local library. At some point I was introduced to the magazine Sky and Telescope, and soon invested my pocket money in a subscription. Every month I would sit at our dining room table with a dictionary and work my way through the latest issue. In one issue I read about Herbig-Haro objects, and I was completely mesmerized that these objects could be signposts of the formation of stars, and I dreamt about some day being able to contribute to this field of study. -

PREFACE Symposium 177 of the International Astronomical Union
PREFACE Symposium 177 of the International Astronomical Union was held in late May of 1996 in the coastal city of Antalya, Turkey. It was attended by 142 scientists from 32 countries. The purpose of the symposium was to discuss the causes and effects of the composition changes that often occur in the atmospheres of cool, evolved stars such as the carbon stars in the course of their evolution. This volume includes the full texts of papers presented orally and one-page abstracts of the poster contributions. The chemical composition of a star's observable surface layers depends not only upon the composition of the interstellar medium from which it formed, but in many cases also upon the star's own history. Consequently, spectroscopic studies of starlight can tell us much about a star's origin, the path it followed as it evolved, and the physical processes of the interior which brought about the composition changes and made them visible on the surface. Furthermore, evolved stars are often surrounded by detectable shells of their own making, and the compositions of these shells provide additional clues concerning the star's evolutionary history. It was Henry Norris Russell who showed in 1934 that the gross spectro- scopic differences between the molecular spectra of carbon stars and M stars could be explained as due to a simple reversal of the abundances of oxygen and carbon. It was also realized early on that the interstellar medium is nowhere carbon-rich, and that changes in chemical composition must be the result of nuclear reactions that take place in the hot interiors of stars, not in their atmospheres. -
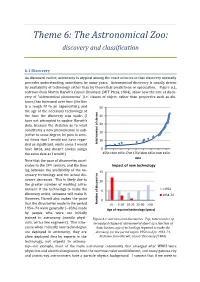
The Astronomical Zoo: Discovery and Classification
Theme 6: The Astronomical Zoo: discovery and classification 6.1 Discovery As discussed earlier, astronomy is atypical among the exact sciences in that discovery normally precedes understanding, sometimes by many years. Astronomical discovery is usually driven by availability of technology rather than by theoretical predictions or speculation. Figure 6.1, redrawn from Martin Harwit’s Cosmic Discovery (MIT Press, 1984), show how the rate of disco- very of “astronomical phenomena” (i.e. classes of object, rather than properties such as dis- tance) has increased over time (the line is a rough fit to an exponential), and 50 the age of the necessary technology at the time the discovery was made. (I 40 have not attempted to update Harwit’s data, because the decision as to what 30 constitutes a new phenomenon is sub- 20 jective to some degree; he puts in seve- ral items that I would not have regar- 10 ded as significant, omits some I would total numberof classes have listed, and doesn’t always assign 0 the same date as I would.) 1550 1600 1650 1700 1750 1800 1850 1900 1950 date Note that the pace of discoveries accel- erates in the 20th century, and the time Impact of new technology lag between the availability of the ne- 15 cessary technology and the actual dis- covery decreases. This is likely due to 10 the greater number of working astro- <1954 nomers: if the technology to make the 5 discovery exists, someone will make it. 1954-74 However, Harwit also makes the point 0 that the discoveries made in the period Numberof discoveries <5 5-10 10-25 25-50 >50 1954−74 were generally (~85%) made Age of required technology (years) by people who were not initially trained in astronomy (mostly physi- Figure 6.1: astronomical discoveries. -

Stars and Their Spectra: an Introduction to the Spectral Sequence Second Edition James B
Cambridge University Press 978-0-521-89954-3 - Stars and Their Spectra: An Introduction to the Spectral Sequence Second Edition James B. Kaler Frontmatter More information Stars and their Spectra Stellar spectroscopy is the fundamental tool for investigating the natures of stars, and is central to our understanding of modern astronomy and astrophysics. Revised and expanded, the Second Edition of this popular book provides a unique and thorough introduction to stellar spectra. It begins by introducing the reader to the fundamental properties of stars and the formation of spectra, before proceeding to the concept and history of stellar classification. The following chapters each look at a different star type: starting with cool M, the discussion extends to cover new stellar classes L and T, before advancing through type O to finish with extraordinary classes. The book concludes with a skillful integration of all the data, tracing the evolution of stars and their place in the Universe. With modern digital spectra and updates from two decades of astronomical discoveries, this accessible text is invaluable for amateur astronomers and all students of the subject. jim kaler is Professor Emeritus of Astronomy at the University of Illinois. He has published over 100 papers on the later stages of stellar evolution and has written more than a dozen books on stars, ranging from textbooks to popular books for general readers. His book The Cambridge Encyclopedia of Stars is a standard reference on stellar astronomy. © in this web service Cambridge University Press www.cambridge.org Cambridge University Press 978-0-521-89954-3 - Stars and Their Spectra: An Introduction to the Spectral Sequence Second Edition James B. -

A Photometric Machine-Learning Method to Infer Stellar Metallicity
A Photometric Machine-Learning Method to Infer Stellar Metallicity Adam A. Miller1;2;?? 1 Jet Propulsion Laboratory, California Institute of Technology, Pasadena CA 91109, USA, [email protected], WWW home page: http://astro.caltech.edu/~amiller 2 California Institute of Technology, Pasadena CA 91125, USA Abstract. Following its formation, a star's metal content is one of the few factors that can significantly alter its evolution. Measurements of stellar metallicity ([Fe=H]) typically require a spectrum, but spectro- scopic surveys are limited to a few×106 targets; photometric surveys, on the other hand, have detected > 109 stars. I present a new machine- learning method to predict [Fe=H] from photometric colors measured by the Sloan Digital Sky Survey (SDSS). The training set consists of ∼120,000 stars with SDSS photometry and reliable [Fe=H] measurements from the SEGUE Stellar Parameters Pipeline (SSPP). For bright stars 0 (g ≤ 18 mag), with 4500 K ≤ Teff ≤ 7000 K, corresponding to those with the most reliable SSPP estimates, I find that the model predicts [Fe=H] values with a root-mean-squared-error (RMSE) of ∼0.27 dex. The RMSE from this machine-learning method is similar to the scatter in [Fe=H] measurements from low-resolution spectra. Keywords: photometric surveys, machine learning, random forest, stel- lar metallicity 1 Introduction The Sloan Digital Sky Survey (SDSS, [13]) has cataloged more than one billion photometric sources, while also obtaining nearly 2 million optical spectra [1]. Despite this unprecedented volume of spectra, existing and currently planned instruments have no hope of observing each of the photometrically cataloged stars found by SDSS.