A Photometric Machine-Learning Method to Infer Stellar Metallicity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
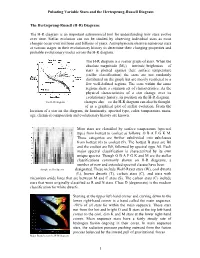
Plotting Variable Stars on the H-R Diagram Activity
Pulsating Variable Stars and the Hertzsprung-Russell Diagram The Hertzsprung-Russell (H-R) Diagram: The H-R diagram is an important astronomical tool for understanding how stars evolve over time. Stellar evolution can not be studied by observing individual stars as most changes occur over millions and billions of years. Astrophysicists observe numerous stars at various stages in their evolutionary history to determine their changing properties and probable evolutionary tracks across the H-R diagram. The H-R diagram is a scatter graph of stars. When the absolute magnitude (MV) – intrinsic brightness – of stars is plotted against their surface temperature (stellar classification) the stars are not randomly distributed on the graph but are mostly restricted to a few well-defined regions. The stars within the same regions share a common set of characteristics. As the physical characteristics of a star change over its evolutionary history, its position on the H-R diagram The H-R Diagram changes also – so the H-R diagram can also be thought of as a graphical plot of stellar evolution. From the location of a star on the diagram, its luminosity, spectral type, color, temperature, mass, age, chemical composition and evolutionary history are known. Most stars are classified by surface temperature (spectral type) from hottest to coolest as follows: O B A F G K M. These categories are further subdivided into subclasses from hottest (0) to coolest (9). The hottest B stars are B0 and the coolest are B9, followed by spectral type A0. Each major spectral classification is characterized by its own unique spectra. -

Luminous Blue Variables
Review Luminous Blue Variables Kerstin Weis 1* and Dominik J. Bomans 1,2,3 1 Astronomical Institute, Faculty for Physics and Astronomy, Ruhr University Bochum, 44801 Bochum, Germany 2 Department Plasmas with Complex Interactions, Ruhr University Bochum, 44801 Bochum, Germany 3 Ruhr Astroparticle and Plasma Physics (RAPP) Center, 44801 Bochum, Germany Received: 29 October 2019; Accepted: 18 February 2020; Published: 29 February 2020 Abstract: Luminous Blue Variables are massive evolved stars, here we introduce this outstanding class of objects. Described are the specific characteristics, the evolutionary state and what they are connected to other phases and types of massive stars. Our current knowledge of LBVs is limited by the fact that in comparison to other stellar classes and phases only a few “true” LBVs are known. This results from the lack of a unique, fast and always reliable identification scheme for LBVs. It literally takes time to get a true classification of a LBV. In addition the short duration of the LBV phase makes it even harder to catch and identify a star as LBV. We summarize here what is known so far, give an overview of the LBV population and the list of LBV host galaxies. LBV are clearly an important and still not fully understood phase in the live of (very) massive stars, especially due to the large and time variable mass loss during the LBV phase. We like to emphasize again the problem how to clearly identify LBV and that there are more than just one type of LBVs: The giant eruption LBVs or h Car analogs and the S Dor cycle LBVs. -

Redalyc. Mass Loss from Luminous Blue Variables and Quasi-Periodic
Revista Mexicana de Astronomía y Astrofísica ISSN: 0185-1101 [email protected] Instituto de Astronomía México Vink, Jorick S.; Kotak, Rubina Mass loss from Luminous Blue Variables and Quasi-periodic Modulations of Radio Supernovae Revista Mexicana de Astronomía y Astrofísica, vol. 30, agosto, 2007, pp. 17-22 Instituto de Astronomía Distrito Federal, México Available in: http://www.redalyc.org/articulo.oa?id=57130005 Abstract Massive stars, supernovae (SNe), and long-duration gamma-ray bursts (GRBs) have a huge impact on their environment. Despite their importance, a comprehensive knowledge of which massive stars produce which SN/GRB is hitherto lacking. We present a brief overview about our knowledge of mass loss in the Hertzsprung- Russell Diagram (HRD) covering evolutionary phases of the OB main sequence, the unstable Luminous Blue Variable (LBV) stage, and the Wolf-Rayet (WR) phase. Despite the fact that metals produced by \selfenrichment" in WR atmospheres exceed the initial { host galaxy { metallicity, by orders of magnitude, a particularly strong dependence of the mass-loss rate on the initial metallicity is found for WR stars at subsolar metallicities (1/10 { 1/100 solar). This provides a signicant boost to the collapsar model for GRBs, as it may present a viable mechanism to prevent the loss of angular momentum by stellar winds at low metallicity, whilst strong Galactic WR winds may inhibit GRBs occurring at solar metallicities. Furthermore, we discuss recently reported quasi-sinusoidal modulations in the radio lightcurves -

The Impact of the Astro2010 Recommendations on Variable Star Science
The Impact of the Astro2010 Recommendations on Variable Star Science Corresponding Authors Lucianne M. Walkowicz Department of Astronomy, University of California Berkeley [email protected] phone: (510) 642–6931 Andrew C. Becker Department of Astronomy, University of Washington [email protected] phone: (206) 685–0542 Authors Scott F. Anderson, Department of Astronomy, University of Washington Joshua S. Bloom, Department of Astronomy, University of California Berkeley Leonid Georgiev, Universidad Autonoma de Mexico Josh Grindlay, Harvard–Smithsonian Center for Astrophysics Steve Howell, National Optical Astronomy Observatory Knox Long, Space Telescope Science Institute Anjum Mukadam, Department of Astronomy, University of Washington Andrej Prsa,ˇ Villanova University Joshua Pepper, Villanova University Arne Rau, California Institute of Technology Branimir Sesar, Department of Astronomy, University of Washington Nicole Silvestri, Department of Astronomy, University of Washington Nathan Smith, Department of Astronomy, University of California Berkeley Keivan Stassun, Vanderbilt University Paula Szkody, Department of Astronomy, University of Washington Science Frontier Panels: Stars and Stellar Evolution (SSE) February 16, 2009 Abstract The next decade of survey astronomy has the potential to transform our knowledge of variable stars. Stellar variability underpins our knowledge of the cosmological distance ladder, and provides direct tests of stellar formation and evolution theory. Variable stars can also be used to probe the fundamental physics of gravity and degenerate material in ways that are otherwise impossible in the laboratory. The computational and engineering advances of the past decade have made large–scale, time–domain surveys an immediate reality. Some surveys proposed for the next decade promise to gather more data than in the prior cumulative history of astronomy. -

Calibration Against Spectral Types and VK Color Subm
Draft version July 19, 2021 Typeset using LATEX default style in AASTeX63 Direct Measurements of Giant Star Effective Temperatures and Linear Radii: Calibration Against Spectral Types and V-K Color Gerard T. van Belle,1 Kaspar von Braun,1 David R. Ciardi,2 Genady Pilyavsky,3 Ryan S. Buckingham,1 Andrew F. Boden,4 Catherine A. Clark,1, 5 Zachary Hartman,1, 6 Gerald van Belle,7 William Bucknew,1 and Gary Cole8, ∗ 1Lowell Observatory 1400 West Mars Hill Road Flagstaff, AZ 86001, USA 2California Institute of Technology, NASA Exoplanet Science Institute Mail Code 100-22 1200 East California Blvd. Pasadena, CA 91125, USA 3Systems & Technology Research 600 West Cummings Park Woburn, MA 01801, USA 4California Institute of Technology Mail Code 11-17 1200 East California Blvd. Pasadena, CA 91125, USA 5Northern Arizona University Department of Astronomy and Planetary Science NAU Box 6010 Flagstaff, Arizona 86011, USA 6Georgia State University Department of Physics and Astronomy P.O. Box 5060 Atlanta, GA 30302, USA 7University of Washington Department of Biostatistics Box 357232 Seattle, WA 98195-7232, USA 8Starphysics Observatory 14280 W. Windriver Lane Reno, NV 89511, USA (Received April 18, 2021; Revised June 23, 2021; Accepted July 15, 2021) Submitted to ApJ ABSTRACT We calculate directly determined values for effective temperature (TEFF) and radius (R) for 191 giant stars based upon high resolution angular size measurements from optical interferometry at the Palomar Testbed Interferometer. Narrow- to wide-band photometry data for the giants are used to establish bolometric fluxes and luminosities through spectral energy distribution fitting, which allow for homogeneously establishing an assessment of spectral type and dereddened V0 − K0 color; these two parameters are used as calibration indices for establishing trends in TEFF and R. -

White Dwarfs - Degenerate Stellar Configurations
White Dwarfs - Degenerate Stellar Configurations Austen Groener Department of Physics - Drexel University, Philadelphia, Pennsylvania 19104, USA Quantum Mechanics II May 17, 2010 Abstract The end product of low-medium mass stars is the degenerate stellar configuration called a white dwarf. Here we discuss the transition into this state thermodynamically as well as developing some intuition regarding the role of quantum mechanics in this process. I Introduction and Stellar Classification present at such high temperatures are small com- pared with the kinetic (thermal) energy of the parti- It is widely believed that the end stage of the low or cles. This assumption implies a mixture of free non- intermediate mass star is an extremely dense, highly interacting particles. One may also note that the pres- underluminous object called a white dwarf. Obser- sure of a mixture of different species of particles will vationally, these white dwarfs are abundant (∼ 6%) be the sum of the pressures exerted by each (this is in the Milky Way due to a large birthrate of their pro- where photon pressure (PRad) will come into play). genitor stars coupled with a very slow rate of cooling. Following this logic we can express the total stellar Roughly 97% of all stars will meet this fate. Given pressure as: no additional mass, the white dwarf will evolve into a cold black dwarf. PT ot = PGas + PRad = PIon + Pe− + PRad (1) In this paper I hope to introduce a qualitative de- scription of the transition from a main-sequence star At Hydrostatic Equilibrium: Pressure Gradient = (classification which aligns hydrogen fusing stars Gravitational Pressure. -

Jsolated Stars of Low Metallicity
galaxies Article Jsolated Stars of Low Metallicity Efrat Sabach Department of Physics, Technion—Israel Institute of Technology, Haifa 32000, Israel; [email protected] Received: 15 July 2018; Accepted: 9 August 2018; Published: 15 August 2018 Abstract: We study the effects of a reduced mass-loss rate on the evolution of low metallicity Jsolated stars, following our earlier classification for angular momentum (J) isolated stars. By using the stellar evolution code MESA we study the evolution with different mass-loss rate efficiencies for stars with low metallicities of Z = 0.001 and Z = 0.004, and compare with the evolution with solar metallicity, Z = 0.02. We further study the possibility for late asymptomatic giant branch (AGB)—planet interaction and its possible effects on the properties of the planetary nebula (PN). We find for all metallicities that only with a reduced mass-loss rate an interaction with a low mass companion might take place during the AGB phase of the star. The interaction will most likely shape an elliptical PN. The maximum post-AGB luminosities obtained, both for solar metallicity and low metallicities, reach high values corresponding to the enigmatic finding of the PN luminosity function. Keywords: late stage stellar evolution; planetary nebulae; binarity; stellar evolution 1. Introduction Jsolated stars are stars that do not gain much angular momentum along their post main sequence evolution from a companion, either stellar or substellar, thus resulting with a lower mass-loss rate compared to non-Jsolated stars [1]. As previously stated in Sabach and Soker [1,2], the fitting formulae of the mass-loss rates for red giant branch (RGB) and asymptotic giant branch (AGB) single stars are set empirically by contaminated samples of stars that are classified as “single stars” but underwent an interaction with a companion early on, increasing the mass-loss rate to the observed rates. -

Asymptotic-Giant-Branch Models at Very Low Metallicity
CSIRO PUBLISHING www.publish.csiro.au/journals/pasa Publications of the Astronomical Society of Australia, 2009, 26, 139–144 Asymptotic-Giant-Branch Models at Very Low Metallicity S. CristalloA,E, L. PiersantiA, O. StranieroA, R. GallinoB, I. DomínguezC, and F. KäppelerD A Osservatorio Astronomico di Teramo (INAF), via Maggini 64100 Teramo, Italy B Dipartimento di Fisica Generale, Universitá di Torino, via P. Giuria 1, 10125 Torino, Italy C Departamento de Física Teórica y del Cosmos, Universidad de Granada, 18071 Granada, Spain D Forschungszentrum Karlsruhe, Institut für Kernphysik Postfach 3460, D-76021 Karlsruhe, Germany E Corresponding author. Email: [email protected] Received 2009 January 9, accepted 2009 April 28 Abstract: In this paper we present the evolution of a low-mass model (initial mass M = 1.5 M) with a very low metal content (Z = 5 × 10−5, equivalent to [Fe/H] =−2.44). We find that, at the beginning of the Asymptotic Giant Branch (AGB) phase, protons are ingested from the envelope in the underlying convective shell generated by the first fully developed thermal pulse. This peculiar phase is followed by a deep third dredge-up episode, which carries to the surface the freshly synthesized 13C, 14N and 7Li. A standard thermally pulsingAGB (TP-AGB) evolution then follows. During the proton-ingestion phase, a very high neutron density is attained and the s process is efficiently activated. We therefore adopt a nuclear network of about 700 isotopes, linked by more than 1200 reactions, and we couple it with the physical evolution of the model. We discuss in detail the evolution of the surface chemical composition, starting from the proton ingestion up to the end of the TP-AGB phase. -

Spectral Classification of Stars Based on LAMOST Spectra
RAA 2015 Vol. 15 No. 8, 1137–1153 doi: 10.1088/1674–4527/15/8/004 Research in http://www.raa-journal.org http://www.iop.org/journals/raa Astronomy and Astrophysics Spectral classification of stars based on LAMOST spectra Chao Liu1, Wen-Yuan Cui2, Bo Zhang1, Jun-Chen Wan1, Li-Cai Deng1, Yong-Hui Hou3, Yue-Fei Wang3, Ming Yang1 and Yong Zhang3 1 Key Laboratory of Optical Astronomy, National Astronomical Observatories, Chinese Academy of Sciences, Beijing 100012, China; [email protected] 2 Department of Physics, Hebei Normal University, Shijiazhuang 050024, China 3 Nanjing Institute of Astronomical Optics & Technology, National Astronomical Observatories, Chinese Academy of Sciences, Nanjing 210042, China Received 2015 April 1; accepted 2015 May 20 Abstract In this work, we select spectra of stars with high signal-to-noise ratio from LAMOST data and map their MK classes to the spectral features. The equivalent widths of prominent spectral lines, which play a similar role as multi-color photom- etry, form a clean stellar locus well ordered by MK classes. The advantage of the stellar locus in line indices is that it gives a natural and continuous classification of stars consistent with either broadly used MK classes or stellar astrophysical parame- ters. We also employ an SVM-based classification algorithm to assign MK classes to LAMOST stellar spectra. We find that the completenesses of the classifications are up to 90% for A and G type stars, but they are down to about 50% for OB and K type stars. About 40% of the OB and K type stars are mis-classified as A and G type stars, respectively. -

Stellar Spectral Classification of Previously Unclassified Stars Gsc 4461-698 and Gsc 4466-870" (2012)
University of North Dakota UND Scholarly Commons Theses and Dissertations Theses, Dissertations, and Senior Projects January 2012 Stellar Spectral Classification Of Previously Unclassified tS ars Gsc 4461-698 And Gsc 4466-870 Darren Moser Grau Follow this and additional works at: https://commons.und.edu/theses Recommended Citation Grau, Darren Moser, "Stellar Spectral Classification Of Previously Unclassified Stars Gsc 4461-698 And Gsc 4466-870" (2012). Theses and Dissertations. 1350. https://commons.und.edu/theses/1350 This Thesis is brought to you for free and open access by the Theses, Dissertations, and Senior Projects at UND Scholarly Commons. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of UND Scholarly Commons. For more information, please contact [email protected]. STELLAR SPECTRAL CLASSIFICATION OF PREVIOUSLY UNCLASSIFIED STARS GSC 4461-698 AND GSC 4466-870 By Darren Moser Grau Bachelor of Arts, Eastern University, 2009 A Thesis Submitted to the Graduate Faculty of the University of North Dakota in partial fulfillment of the requirements For the degree of Master of Science Grand Forks, North Dakota December 2012 Copyright 2012 Darren M. Grau ii This thesis, submitted by Darren M. Grau in partial fulfillment of the requirements for the Degree of Master of Science from the University of North Dakota, has been read by the Faculty Advisory Committee under whom the work has been done and is hereby approved. _____________________________________ Dr. Paul Hardersen _____________________________________ Dr. Ronald Fevig _____________________________________ Dr. Timothy Young This thesis is being submitted by the appointed advisory committee as having met all of the requirements of the Graduate School at the University of North Dakota and is hereby approved. -

Application Exercise: Spectral Classification of Stars
Name ____________________________________________________________________ Section ____________ Application Exercise: Spectral Classification of Stars Objectives To learn the basic techniques and criteria of the spectral classification sequence by: • examining and classifying spectra according to the strength of the hydrogen Balmer absorption lines • examining and classifying spectra according to temperature using Wien's Law • comparing the two schemes by identifying the temperature where the Balmer lines are strongest and recognizing the corresponding spectral class • summarizing the physical reason why both very cool stars and very hot stars have weak Balmer lines. Background and Theory Classification lies at the foundation of nearly every science. Scientists develop classification systems based on perceived patterns and relationships. Biologists classify plants and animals into subgroups called genus and species. Geologists have an elaborate system of classification for rocks and minerals. Astronomers are no different. We classify planets according to their composition (terrestrial or Jovian), galaxies according to their shape (spiral, elliptical, or irregular), and stars according to their spectra. In this exercise you will classify six stars by repeating the process that was developed by the women at Harvard around the turn of the 20th century. The resulting classification was a key step in elucidating the underlying physics that produces stellar spectra. Thus, in astronomy as well as biology, the relatively mundane step of classification eventually yields critical insights that allow us to understand our world. The spectrum of a star is composed primarily of blackbody radiation--radiation that produces a continuous spectrum (the continuum). The star emits light over the entire electromagnetic spectrum, from the x-ray to the radio. -

The Solar Neighbourhood Age-Metallicity Relation – Does It Exist??,?? S
A&A 377, 911–924 (2001) Astronomy DOI: 10.1051/0004-6361:20011119 & c ESO 2001 Astrophysics The solar neighbourhood age-metallicity relation – Does it exist??,?? S. Feltzing1,J.Holmberg1, and J. R. Hurley2 1 Lund Observatory, Box 43, 221 00 Lund, Sweden e-mail: sofia, [email protected] 2 AMNH Department of Astrophysics, 79th Street at Central Park West New York, NY, 10024-5192, USA e-mail: [email protected] Received 15 August 2000 / Accepted 6 August 2001 Abstract. We derive stellar ages, from evolutionary tracks, and metallicities, from Str¨omgren photometry, for a sample of 5828 dwarf and sub-dwarf stars from the Hipparcos Catalogue. This stellar disk sample is used to investigate the age-metallicity diagram in the solar neighbourhood. Such diagrams are often used to derive a so called age-metallicity relation. Because of the size of our sample, we are able to quantify the impact on such diagrams, and derived relations, due to different selection effects. Some of these effects are of a more subtle sort, giving rise to erroneous conclusions. In particular we show that [1] the age-metallicity diagram is well populated at all ages and especially that old, metal-rich stars do exist, [2] the scatter in metallicity at any given age is larger than the observational errors, [3] the exclusion of cooler dwarf stars from an age-metallicity sample preferentially excludes old, metal-rich stars, depleting the upper right-hand corner of the age-metallicity diagram, [4] the distance dependence found in the Edvardsson et al. sample by Garnett & Kobulnicky is an expected artifact due to the construction of the original sample.