Properties of the Trace and Matrix Derivatives
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Estimations of the Trace of Powers of Positive Self-Adjoint Operators by Extrapolation of the Moments∗
Electronic Transactions on Numerical Analysis. ETNA Volume 39, pp. 144-155, 2012. Kent State University Copyright 2012, Kent State University. http://etna.math.kent.edu ISSN 1068-9613. ESTIMATIONS OF THE TRACE OF POWERS OF POSITIVE SELF-ADJOINT OPERATORS BY EXTRAPOLATION OF THE MOMENTS∗ CLAUDE BREZINSKI†, PARASKEVI FIKA‡, AND MARILENA MITROULI‡ Abstract. Let A be a positive self-adjoint linear operator on a real separable Hilbert space H. Our aim is to build estimates of the trace of Aq, for q ∈ R. These estimates are obtained by extrapolation of the moments of A. Applications of the matrix case are discussed, and numerical results are given. Key words. Trace, positive self-adjoint linear operator, symmetric matrix, matrix powers, matrix moments, extrapolation. AMS subject classifications. 65F15, 65F30, 65B05, 65C05, 65J10, 15A18, 15A45. 1. Introduction. Let A be a positive self-adjoint linear operator from H to H, where H is a real separable Hilbert space with inner product denoted by (·, ·). Our aim is to build estimates of the trace of Aq, for q ∈ R. These estimates are obtained by extrapolation of the integer moments (z, Anz) of A, for n ∈ N. A similar procedure was first introduced in [3] for estimating the Euclidean norm of the error when solving a system of linear equations, which corresponds to q = −2. The case q = −1, which leads to estimates of the trace of the inverse of a matrix, was studied in [4]; on this problem, see [10]. Let us mention that, when only positive powers of A are used, the Hilbert space H could be infinite dimensional, while, for negative powers of A, it is always assumed to be a finite dimensional one, and, obviously, A is also assumed to be invertible. -

The Mean Value Theorem Math 120 Calculus I Fall 2015
The Mean Value Theorem Math 120 Calculus I Fall 2015 The central theorem to much of differential calculus is the Mean Value Theorem, which we'll abbreviate MVT. It is the theoretical tool used to study the first and second derivatives. There is a nice logical sequence of connections here. It starts with the Extreme Value Theorem (EVT) that we looked at earlier when we studied the concept of continuity. It says that any function that is continuous on a closed interval takes on a maximum and a minimum value. A technical lemma. We begin our study with a technical lemma that allows us to relate 0 the derivative of a function at a point to values of the function nearby. Specifically, if f (x0) is positive, then for x nearby but smaller than x0 the values f(x) will be less than f(x0), but for x nearby but larger than x0, the values of f(x) will be larger than f(x0). This says something like f is an increasing function near x0, but not quite. An analogous statement 0 holds when f (x0) is negative. Proof. The proof of this lemma involves the definition of derivative and the definition of limits, but none of the proofs for the rest of the theorems here require that depth. 0 Suppose that f (x0) = p, some positive number. That means that f(x) − f(x ) lim 0 = p: x!x0 x − x0 f(x) − f(x0) So you can make arbitrarily close to p by taking x sufficiently close to x0. -

AP Calculus AB Topic List 1. Limits Algebraically 2. Limits Graphically 3
AP Calculus AB Topic List 1. Limits algebraically 2. Limits graphically 3. Limits at infinity 4. Asymptotes 5. Continuity 6. Intermediate value theorem 7. Differentiability 8. Limit definition of a derivative 9. Average rate of change (approximate slope) 10. Tangent lines 11. Derivatives rules and special functions 12. Chain Rule 13. Application of chain rule 14. Derivatives of generic functions using chain rule 15. Implicit differentiation 16. Related rates 17. Derivatives of inverses 18. Logarithmic differentiation 19. Determine function behavior (increasing, decreasing, concavity) given a function 20. Determine function behavior (increasing, decreasing, concavity) given a derivative graph 21. Interpret first and second derivative values in a table 22. Determining if tangent line approximations are over or under estimates 23. Finding critical points and determining if they are relative maximum, relative minimum, or neither 24. Second derivative test for relative maximum or minimum 25. Finding inflection points 26. Finding and justifying critical points from a derivative graph 27. Absolute maximum and minimum 28. Application of maximum and minimum 29. Motion derivatives 30. Vertical motion 31. Mean value theorem 32. Approximating area with rectangles and trapezoids given a function 33. Approximating area with rectangles and trapezoids given a table of values 34. Determining if area approximations are over or under estimates 35. Finding definite integrals graphically 36. Finding definite integrals using given integral values 37. Indefinite integrals with power rule or special derivatives 38. Integration with u-substitution 39. Evaluating definite integrals 40. Definite integrals with u-substitution 41. Solving initial value problems (separable differential equations) 42. Creating a slope field 43. -

5 the Dirac Equation and Spinors
5 The Dirac Equation and Spinors In this section we develop the appropriate wavefunctions for fundamental fermions and bosons. 5.1 Notation Review The three dimension differential operator is : ∂ ∂ ∂ = , , (5.1) ∂x ∂y ∂z We can generalise this to four dimensions ∂µ: 1 ∂ ∂ ∂ ∂ ∂ = , , , (5.2) µ c ∂t ∂x ∂y ∂z 5.2 The Schr¨odinger Equation First consider a classical non-relativistic particle of mass m in a potential U. The energy-momentum relationship is: p2 E = + U (5.3) 2m we can substitute the differential operators: ∂ Eˆ i pˆ i (5.4) → ∂t →− to obtain the non-relativistic Schr¨odinger Equation (with = 1): ∂ψ 1 i = 2 + U ψ (5.5) ∂t −2m For U = 0, the free particle solutions are: iEt ψ(x, t) e− ψ(x) (5.6) ∝ and the probability density ρ and current j are given by: 2 i ρ = ψ(x) j = ψ∗ ψ ψ ψ∗ (5.7) | | −2m − with conservation of probability giving the continuity equation: ∂ρ + j =0, (5.8) ∂t · Or in Covariant notation: µ µ ∂µj = 0 with j =(ρ,j) (5.9) The Schr¨odinger equation is 1st order in ∂/∂t but second order in ∂/∂x. However, as we are going to be dealing with relativistic particles, space and time should be treated equally. 25 5.3 The Klein-Gordon Equation For a relativistic particle the energy-momentum relationship is: p p = p pµ = E2 p 2 = m2 (5.10) · µ − | | Substituting the equation (5.4), leads to the relativistic Klein-Gordon equation: ∂2 + 2 ψ = m2ψ (5.11) −∂t2 The free particle solutions are plane waves: ip x i(Et p x) ψ e− · = e− − · (5.12) ∝ The Klein-Gordon equation successfully describes spin 0 particles in relativistic quan- tum field theory. -

Multivariable and Vector Calculus
Multivariable and Vector Calculus Lecture Notes for MATH 0200 (Spring 2015) Frederick Tsz-Ho Fong Department of Mathematics Brown University Contents 1 Three-Dimensional Space ....................................5 1.1 Rectangular Coordinates in R3 5 1.2 Dot Product7 1.3 Cross Product9 1.4 Lines and Planes 11 1.5 Parametric Curves 13 2 Partial Differentiations ....................................... 19 2.1 Functions of Several Variables 19 2.2 Partial Derivatives 22 2.3 Chain Rule 26 2.4 Directional Derivatives 30 2.5 Tangent Planes 34 2.6 Local Extrema 36 2.7 Lagrange’s Multiplier 41 2.8 Optimizations 46 3 Multiple Integrations ........................................ 49 3.1 Double Integrals in Rectangular Coordinates 49 3.2 Fubini’s Theorem for General Regions 53 3.3 Double Integrals in Polar Coordinates 57 3.4 Triple Integrals in Rectangular Coordinates 62 3.5 Triple Integrals in Cylindrical Coordinates 67 3.6 Triple Integrals in Spherical Coordinates 70 4 Vector Calculus ............................................ 75 4.1 Vector Fields on R2 and R3 75 4.2 Line Integrals of Vector Fields 83 4.3 Conservative Vector Fields 88 4.4 Green’s Theorem 98 4.5 Parametric Surfaces 105 4.6 Stokes’ Theorem 120 4.7 Divergence Theorem 127 5 Topics in Physics and Engineering .......................... 133 5.1 Coulomb’s Law 133 5.2 Introduction to Maxwell’s Equations 137 5.3 Heat Diffusion 141 5.4 Dirac Delta Functions 144 1 — Three-Dimensional Space 1.1 Rectangular Coordinates in R3 Throughout the course, we will use an ordered triple (x, y, z) to represent a point in the three dimensional space. -

A Some Basic Rules of Tensor Calculus
A Some Basic Rules of Tensor Calculus The tensor calculus is a powerful tool for the description of the fundamentals in con- tinuum mechanics and the derivation of the governing equations for applied prob- lems. In general, there are two possibilities for the representation of the tensors and the tensorial equations: – the direct (symbolic) notation and – the index (component) notation The direct notation operates with scalars, vectors and tensors as physical objects defined in the three dimensional space. A vector (first rank tensor) a is considered as a directed line segment rather than a triple of numbers (coordinates). A second rank tensor A is any finite sum of ordered vector pairs A = a b + ... +c d. The scalars, vectors and tensors are handled as invariant (independent⊗ from the choice⊗ of the coordinate system) objects. This is the reason for the use of the direct notation in the modern literature of mechanics and rheology, e.g. [29, 32, 49, 123, 131, 199, 246, 313, 334] among others. The index notation deals with components or coordinates of vectors and tensors. For a selected basis, e.g. gi, i = 1, 2, 3 one can write a = aig , A = aibj + ... + cidj g g i i ⊗ j Here the Einstein’s summation convention is used: in one expression the twice re- peated indices are summed up from 1 to 3, e.g. 3 3 k k ik ik a gk ∑ a gk, A bk ∑ A bk ≡ k=1 ≡ k=1 In the above examples k is a so-called dummy index. Within the index notation the basic operations with tensors are defined with respect to their coordinates, e. -

18.700 JORDAN NORMAL FORM NOTES These Are Some Supplementary Notes on How to Find the Jordan Normal Form of a Small Matrix. Firs
18.700 JORDAN NORMAL FORM NOTES These are some supplementary notes on how to find the Jordan normal form of a small matrix. First we recall some of the facts from lecture, next we give the general algorithm for finding the Jordan normal form of a linear operator, and then we will see how this works for small matrices. 1. Facts Throughout we will work over the field C of complex numbers, but if you like you may replace this with any other algebraically closed field. Suppose that V is a C-vector space of dimension n and suppose that T : V → V is a C-linear operator. Then the characteristic polynomial of T factors into a product of linear terms, and the irreducible factorization has the form m1 m2 mr cT (X) = (X − λ1) (X − λ2) ... (X − λr) , (1) for some distinct numbers λ1, . , λr ∈ C and with each mi an integer m1 ≥ 1 such that m1 + ··· + mr = n. Recall that for each eigenvalue λi, the eigenspace Eλi is the kernel of T − λiIV . We generalized this by defining for each integer k = 1, 2,... the vector subspace k k E(X−λi) = ker(T − λiIV ) . (2) It is clear that we have inclusions 2 e Eλi = EX−λi ⊂ E(X−λi) ⊂ · · · ⊂ E(X−λi) ⊂ .... (3) k k+1 Since dim(V ) = n, it cannot happen that each dim(E(X−λi) ) < dim(E(X−λi) ), for each e e +1 k = 1, . , n. Therefore there is some least integer ei ≤ n such that E(X−λi) i = E(X−λi) i . -
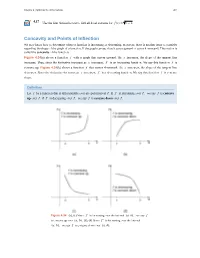
Concavity and Points of Inflection We Now Know How to Determine Where a Function Is Increasing Or Decreasing
Chapter 4 | Applications of Derivatives 401 4.17 3 Use the first derivative test to find all local extrema for f (x) = x − 1. Concavity and Points of Inflection We now know how to determine where a function is increasing or decreasing. However, there is another issue to consider regarding the shape of the graph of a function. If the graph curves, does it curve upward or curve downward? This notion is called the concavity of the function. Figure 4.34(a) shows a function f with a graph that curves upward. As x increases, the slope of the tangent line increases. Thus, since the derivative increases as x increases, f ′ is an increasing function. We say this function f is concave up. Figure 4.34(b) shows a function f that curves downward. As x increases, the slope of the tangent line decreases. Since the derivative decreases as x increases, f ′ is a decreasing function. We say this function f is concave down. Definition Let f be a function that is differentiable over an open interval I. If f ′ is increasing over I, we say f is concave up over I. If f ′ is decreasing over I, we say f is concave down over I. Figure 4.34 (a), (c) Since f ′ is increasing over the interval (a, b), we say f is concave up over (a, b). (b), (d) Since f ′ is decreasing over the interval (a, b), we say f is concave down over (a, b). 402 Chapter 4 | Applications of Derivatives In general, without having the graph of a function f , how can we determine its concavity? By definition, a function f is concave up if f ′ is increasing. -

Calculus Terminology
AP Calculus BC Calculus Terminology Absolute Convergence Asymptote Continued Sum Absolute Maximum Average Rate of Change Continuous Function Absolute Minimum Average Value of a Function Continuously Differentiable Function Absolutely Convergent Axis of Rotation Converge Acceleration Boundary Value Problem Converge Absolutely Alternating Series Bounded Function Converge Conditionally Alternating Series Remainder Bounded Sequence Convergence Tests Alternating Series Test Bounds of Integration Convergent Sequence Analytic Methods Calculus Convergent Series Annulus Cartesian Form Critical Number Antiderivative of a Function Cavalieri’s Principle Critical Point Approximation by Differentials Center of Mass Formula Critical Value Arc Length of a Curve Centroid Curly d Area below a Curve Chain Rule Curve Area between Curves Comparison Test Curve Sketching Area of an Ellipse Concave Cusp Area of a Parabolic Segment Concave Down Cylindrical Shell Method Area under a Curve Concave Up Decreasing Function Area Using Parametric Equations Conditional Convergence Definite Integral Area Using Polar Coordinates Constant Term Definite Integral Rules Degenerate Divergent Series Function Operations Del Operator e Fundamental Theorem of Calculus Deleted Neighborhood Ellipsoid GLB Derivative End Behavior Global Maximum Derivative of a Power Series Essential Discontinuity Global Minimum Derivative Rules Explicit Differentiation Golden Spiral Difference Quotient Explicit Function Graphic Methods Differentiable Exponential Decay Greatest Lower Bound Differential -

Matrix Calculus
Appendix D Matrix Calculus From too much study, and from extreme passion, cometh madnesse. Isaac Newton [205, §5] − D.1 Gradient, Directional derivative, Taylor series D.1.1 Gradients Gradient of a differentiable real function f(x) : RK R with respect to its vector argument is defined uniquely in terms of partial derivatives→ ∂f(x) ∂x1 ∂f(x) , ∂x2 RK f(x) . (2053) ∇ . ∈ . ∂f(x) ∂xK while the second-order gradient of the twice differentiable real function with respect to its vector argument is traditionally called the Hessian; 2 2 2 ∂ f(x) ∂ f(x) ∂ f(x) 2 ∂x1 ∂x1∂x2 ··· ∂x1∂xK 2 2 2 ∂ f(x) ∂ f(x) ∂ f(x) 2 2 K f(x) , ∂x2∂x1 ∂x2 ··· ∂x2∂xK S (2054) ∇ . ∈ . .. 2 2 2 ∂ f(x) ∂ f(x) ∂ f(x) 2 ∂xK ∂x1 ∂xK ∂x2 ∂x ··· K interpreted ∂f(x) ∂f(x) 2 ∂ ∂ 2 ∂ f(x) ∂x1 ∂x2 ∂ f(x) = = = (2055) ∂x1∂x2 ³∂x2 ´ ³∂x1 ´ ∂x2∂x1 Dattorro, Convex Optimization Euclidean Distance Geometry, Mεβoo, 2005, v2020.02.29. 599 600 APPENDIX D. MATRIX CALCULUS The gradient of vector-valued function v(x) : R RN on real domain is a row vector → v(x) , ∂v1(x) ∂v2(x) ∂vN (x) RN (2056) ∇ ∂x ∂x ··· ∂x ∈ h i while the second-order gradient is 2 2 2 2 , ∂ v1(x) ∂ v2(x) ∂ vN (x) RN v(x) 2 2 2 (2057) ∇ ∂x ∂x ··· ∂x ∈ h i Gradient of vector-valued function h(x) : RK RN on vector domain is → ∂h1(x) ∂h2(x) ∂hN (x) ∂x1 ∂x1 ··· ∂x1 ∂h1(x) ∂h2(x) ∂hN (x) h(x) , ∂x2 ∂x2 ··· ∂x2 ∇ . -

The Linear Algebra Version of the Chain Rule 1
Ralph M Kaufmann The Linear Algebra Version of the Chain Rule 1 Idea The differential of a differentiable function at a point gives a good linear approximation of the function – by definition. This means that locally one can just regard linear functions. The algebra of linear functions is best described in terms of linear algebra, i.e. vectors and matrices. Now, in terms of matrices the concatenation of linear functions is the matrix product. Putting these observations together gives the formulation of the chain rule as the Theorem that the linearization of the concatenations of two functions at a point is given by the concatenation of the respective linearizations. Or in other words that matrix describing the linearization of the concatenation is the product of the two matrices describing the linearizations of the two functions. 1. Linear Maps Let V n be the space of n–dimensional vectors. 1.1. Definition. A linear map F : V n → V m is a rule that associates to each n–dimensional vector ~x = hx1, . xni an m–dimensional vector F (~x) = ~y = hy1, . , yni = hf1(~x),..., (fm(~x))i in such a way that: 1) For c ∈ R : F (c~x) = cF (~x) 2) For any two n–dimensional vectors ~x and ~x0: F (~x + ~x0) = F (~x) + F (~x0) If m = 1 such a map is called a linear function. Note that the component functions f1, . , fm are all linear functions. 1.2. Examples. 1) m=1, n=3: all linear functions are of the form y = ax1 + bx2 + cx3 for some a, b, c ∈ R. -

Trace Inequalities for Matrices
Bull. Aust. Math. Soc. 87 (2013), 139–148 doi:10.1017/S0004972712000627 TRACE INEQUALITIES FOR MATRICES KHALID SHEBRAWI ˛ and HUSSIEN ALBADAWI (Received 23 February 2012; accepted 20 June 2012) Abstract Trace inequalities for sums and products of matrices are presented. Relations between the given inequalities and earlier results are discussed. Among other inequalities, it is shown that if A and B are positive semidefinite matrices then tr(AB)k ≤ minfkAkk tr Bk; kBkk tr Akg for any positive integer k. 2010 Mathematics subject classification: primary 15A18; secondary 15A42, 15A45. Keywords and phrases: trace inequalities, eigenvalues, singular values. 1. Introduction Let Mn(C) be the algebra of all n × n matrices over the complex number field. The singular values of A 2 Mn(C), denoted by s1(A); s2(A);:::; sn(A), are the eigenvalues ∗ 1=2 of the matrix jAj = (A A) arranged in such a way that s1(A) ≥ s2(A) ≥ · · · ≥ sn(A). 2 ∗ ∗ Note that si (A) = λi(A A) = λi(AA ), so for a positive semidefinite matrix A, we have si(A) = λi(A)(i = 1; 2;:::; n). The trace functional of A 2 Mn(C), denoted by tr A or tr(A), is defined to be the sum of the entries on the main diagonal of A and it is well known that the trace of a Pn matrix A is equal to the sum of its eigenvalues, that is, tr A = j=1 λ j(A). Two principal properties of the trace are that it is a linear functional and, for A; B 2 Mn(C), we have tr(AB) = tr(BA).