Note Detection and Multiple Fundamental Frequency Estimation in Piano Recordings
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Second Bassoon: Specialist, Support, Teamwork Dick Hanemaayer Amsterdam, Holland (!E Following Article first Appeared in the Dutch Magazine “De Fagot”
THE DOUBLE REED 103 Second Bassoon: Specialist, Support, Teamwork Dick Hanemaayer Amsterdam, Holland (!e following article first appeared in the Dutch magazine “De Fagot”. It is reprinted here with permission in an English translation by James Aylward. Ed.) t used to be that orchestras, when they appointed a new second bassoon, would not take the best player, but a lesser one on instruction from the !rst bassoonist: the prima donna. "e !rst bassoonist would then blame the second for everything that went wrong. It was also not uncommon that the !rst bassoonist, when Ihe made a mistake, to shake an accusatory !nger at his colleague in clear view of the conductor. Nowadays it is clear that the second bassoon is not someone who is not good enough to play !rst, but a specialist in his own right. Jos de Lange and Ronald Karten, respectively second and !rst bassoonist from the Royal Concertgebouw Orchestra explain.) BASS VOICE Jos de Lange: What makes the second bassoon more interesting over the other woodwinds is that the bassoon is the bass. In the orchestra there are usually four voices: soprano, alto, tenor and bass. All the high winds are either soprano or alto, almost never tenor. !e "rst bassoon is o#en the tenor or the alto, and the second is the bass. !e bassoons are the tenor and bass of the woodwinds. !e second bassoon is the only bass and performs an important and rewarding function. One of the tasks of the second bassoon is to control the pitch, in other words to decide how high a chord is to be played. -

Acoustic Guitar 2019 Graded Certificates Debut-G8 Acoustic Guitar 2019 Graded Certificates Debut-G8
Acoustic Guitar 2019 Graded Certificates debut-G8 Acoustic Guitar 2019 Graded Certificates Debut-G8 Acoustic Guitar 2019 Graded Certificates DEBUT-G5 Technical Exercise submission list Playing along to metronome is compulsory when indicated in the grade book. Exercises should commence after a 4-click metronome count in. Please ensure this is audible on the video recording. For chord exercises which are stipulated as being directed by the examiner, candidates must present all chords/voicings in all key centres. Candidates do not need to play these to click, but must be mindful of producing the chords clearly with minimal hesitancy between each. Note: Candidate should play all listed scales, arpeggios and chords in the key centres and positions shown. Debut Group A Group B Group C Scales (70 bpm) Chords Acoustic Riff 1. C major Open position chords (play all) To be played to backing track 2. E minor pentatonic 3. A minor pentatonic grade 1 Group A Group B Group C Scales (70 bpm) Chords (70 bpm) Acoustic Riff 1. C major 1. Powerchords To be played to backing track 2. A natural minor 2. Major Chords (play all) 3. E minor pentatonic 3. Minor Chords (play all) 4. A minor pentatonic 5. G major pentatonic Acoustic Guitar 2019 Graded Certificates Debut-G8 grade 2 Group A Group B Group C Scales (80 bpm) Chords (80 bpm) Acoustic Riff 1. C major 1. Powerchords To be played to backing track 2. G Major 2. Major and minor Chords 3. E natural minor (play all) 4. A natural minor 3. Minor 7th Chords (play all) 5. -

The Science of String Instruments
The Science of String Instruments Thomas D. Rossing Editor The Science of String Instruments Editor Thomas D. Rossing Stanford University Center for Computer Research in Music and Acoustics (CCRMA) Stanford, CA 94302-8180, USA [email protected] ISBN 978-1-4419-7109-8 e-ISBN 978-1-4419-7110-4 DOI 10.1007/978-1-4419-7110-4 Springer New York Dordrecht Heidelberg London # Springer Science+Business Media, LLC 2010 All rights reserved. This work may not be translated or copied in whole or in part without the written permission of the publisher (Springer Science+Business Media, LLC, 233 Spring Street, New York, NY 10013, USA), except for brief excerpts in connection with reviews or scholarly analysis. Use in connection with any form of information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed is forbidden. The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identified as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights. Printed on acid-free paper Springer is part of Springer ScienceþBusiness Media (www.springer.com) Contents 1 Introduction............................................................... 1 Thomas D. Rossing 2 Plucked Strings ........................................................... 11 Thomas D. Rossing 3 Guitars and Lutes ........................................................ 19 Thomas D. Rossing and Graham Caldersmith 4 Portuguese Guitar ........................................................ 47 Octavio Inacio 5 Banjo ...................................................................... 59 James Rae 6 Mandolin Family Instruments........................................... 77 David J. Cohen and Thomas D. Rossing 7 Psalteries and Zithers .................................................... 99 Andres Peekna and Thomas D. -

Fftuner Basic Instructions. (For Chrome Or Firefox, Not
FFTuner basic instructions. (for Chrome or Firefox, not IE) A) Overview B) Graphical User Interface elements defined C) Measuring inharmonicity of a string D) Demonstration of just and equal temperament scales E) Basic tuning sequence F) Tuning hardware and techniques G) Guitars H) Drums I) Disclaimer A) Overview Why FFTuner (piano)? There are many excellent piano-tuning applications available (both for free and for charge). This one is designed to also demonstrate a little music theory (and physics for the ‘engineer’ in all of us). It displays and helps interpret the full audio spectra produced when striking a piano key, including its harmonics. Since it does not lock in on the primary note struck (like many other tuners do), you can tune the interval between two keys by examining the spectral regions where their harmonics should overlap in frequency. You can also clearly see (and measure) the inharmonicity driving ‘stretch’ tuning (where the spacing of real-string harmonics is not constant, but increases with higher harmonics). The tuning sequence described here effectively incorporates your piano’s specific inharmonicity directly, key by key, (and makes it visually clear why choices have to be made). You can also use a (very) simple calculated stretch if desired. Other tuner apps have pre-defined stretch curves available (or record keys and then algorithmically calculate their own). Some are much more sophisticated indeed! B) Graphical User Interface elements defined A) Complete interface. Green: Fast Fourier Transform of microphone input (linear display in this case) Yellow: Left fundamental and harmonics (dotted lines) up to output frequency (dashed line). -

GRAMMAR of SOLRESOL Or the Universal Language of François SUDRE
GRAMMAR OF SOLRESOL or the Universal Language of François SUDRE by BOLESLAS GAJEWSKI, Professor [M. Vincent GAJEWSKI, professor, d. Paris in 1881, is the father of the author of this Grammar. He was for thirty years the president of the Central committee for the study and advancement of Solresol, a committee founded in Paris in 1869 by Madame SUDRE, widow of the Inventor.] [This edition from taken from: Copyright © 1997, Stephen L. Rice, Last update: Nov. 19, 1997 URL: http://www2.polarnet.com/~srice/solresol/sorsoeng.htm Edits in [brackets], as well as chapter headings and formatting by Doug Bigham, 2005, for LIN 312.] I. Introduction II. General concepts of solresol III. Words of one [and two] syllable[s] IV. Suppression of synonyms V. Reversed meanings VI. Important note VII. Word groups VIII. Classification of ideas: 1º simple notes IX. Classification of ideas: 2º repeated notes X. Genders XI. Numbers XII. Parts of speech XIII. Number of words XIV. Separation of homonyms XV. Verbs XVI. Subjunctive XVII. Passive verbs XVIII. Reflexive verbs XIX. Impersonal verbs XX. Interrogation and negation XXI. Syntax XXII. Fasi, sifa XXIII. Partitive XXIV. Different kinds of writing XXV. Different ways of communicating XXVI. Brief extract from the dictionary I. Introduction In all the business of life, people must understand one another. But how is it possible to understand foreigners, when there are around three thousand different languages spoken on earth? For everyone's sake, to facilitate travel and international relations, and to promote the progress of beneficial science, a language is needed that is easy, shared by all peoples, and capable of serving as a means of interpretation in all countries. -

10 - Pathways to Harmony, Chapter 1
Pathways to Harmony, Chapter 1. The Keyboard and Treble Clef Chapter 2. Bass Clef In this chapter you will: 1.Write bass clefs 2. Write some low notes 3. Match low notes on the keyboard with notes on the staff 4. Write eighth notes 5. Identify notes on ledger lines 6. Identify sharps and flats on the keyboard 7.Write sharps and flats on the staff 8. Write enharmonic equivalents date: 2.1 Write bass clefs • The symbol at the beginning of the above staff, , is an F or bass clef. • The F or bass clef says that the fourth line of the staff is the F below the piano’s middle C. This clef is used to write low notes. DRAW five bass clefs. After each clef, which itself includes two dots, put another dot on the F line. © Gilbert DeBenedetti - 10 - www.gmajormusictheory.org Pathways to Harmony, Chapter 1. The Keyboard and Treble Clef 2.2 Write some low notes •The notes on the spaces of a staff with bass clef starting from the bottom space are: A, C, E and G as in All Cows Eat Grass. •The notes on the lines of a staff with bass clef starting from the bottom line are: G, B, D, F and A as in Good Boys Do Fine Always. 1. IDENTIFY the notes in the song “This Old Man.” PLAY it. 2. WRITE the notes and bass clefs for the song, “Go Tell Aunt Rhodie” Q = quarter note H = half note W = whole note © Gilbert DeBenedetti - 11 - www.gmajormusictheory.org Pathways to Harmony, Chapter 1. -
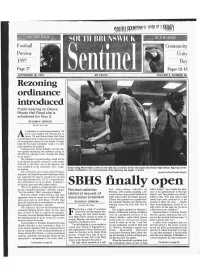
SBHS Finally Open "We're Not Getting a Revised Site Plan in (Time for the Scheduled Meeting)," Schaefer Argued
IN THIS ISSUE IN THE NEWS Football Community Unity Day Page 17 Pages 12-13 SEPTEMBER 18, 1997 40 CENTS VOLUME 4, NUMBER 48 Rezoning ordinance introduced Public hearing on Deans- Rhode Hall Road site is scheduled for Nov. 5 BY JOHN P. POWGIN Staff Writer n ordinance to rezone approximately 120 acres surrounding the intersection of A Route 130 and Deans-Rhode Hall Road in South Brunswick to allow for more concentrat- ed development cleared its first hurdle Tuesday when the Township Committee voted 4-1 to offi- cially introduce the proposal. Committeeman David Schaefer cast the lone vote against introducing the ordinance, saying he felt that his colleagues were "rushing this along for no reason." The ordinance's second reading, which will be accompanied by public comment on the matter followed by the final vote on its adoption, has been scheduled for the committee's Nov. 5 regu- Senior Greg Merritt takes a test on the first day of school at the new South Brunswick High School: figuring out his lar meeting. locker combination. For more pictures of the opening, see pages 3 and 9. The committee previously asked Forsgate (Jackie Pollack/Greater Media) Industries, the South Brunswick-based firm which has requested the land in question be rezoned from light industrial (LI) 3 to LI 2, to provide fur- ther information on its proposal, including a revised site plan and traffic impact studies. SBHS finally open "We're not getting a revised site plan in (time for the scheduled meeting)," Schaefer argued. Revised calendar day, early-release schedule on school delays, "they sought the guid- "Let's be realistic. -

The Carillon United Church of Christ, Congregational (585) 492-4530 Editor: Marilyn Pirdy (585) 322-8823
The Carillon United Church of Christ, Congregational (585) 492-4530 Editor: Marilyn Pirdy (585) 322-8823 May 2013 As May is rapidly approaching, we are gearing up for the splendors of this Merry Month. We anxiously and Then, just 3 days later in the month, we come to one gratefully await the grandeur of the budding trees and of America’s most favorite holidays – Mother’s Day, shrubs, the lawns which are becoming green and May 12. On this day we honor our mothers – those increasingly lush, the birds busily gathering nesting persons who either by birth or by their actions are as materials for their about-to-be new families, and fields mothers to us through love, kindness, compassion, being diligently groomed and planted for the year’s caring, encouraging, and so much more. It’s on this day growing season. In addition to looking forward to we acknowledge our mother’s influence on our lives, experiencing all these spIendors, I scan the calendar and whether they are yet in our midst or have gone before can’t help but think that May is really a month of us to God’s heavenly realm. On this day also, we remembrance. Let me share my reasoning, and celebrate the blessing of the Christian Home. It’s a perhaps you will agree. special day, indeed – this day when we again remember May 1 is May Day – originally a day to remember the our mothers! Haymarket Riot of 1886 in Chicago, Illinois. Even And then, on May 27, we celebrate yet another day though the riot occurred on May 4, it was the of tribute – Memorial Day. -

FORW ARD , MARC H • Zn• Pian Os
FORW ARD , MARC H • zn• pian os The Research Laboratory of this Company is constantly working to Improve the piano-in design and in \vorking parts. It is our policy to follow up every idea that may hold the germ of advanc~n1ent in piano building. Because of this constant striving for improve ment, plus the care and conscience that goes into every instrument we produce, money cannot buy grca ter val ue than that in the pianos listed below. M ..~t---------------____-tl~ MASON {1 HAMLIN KNA.BE CHICKERING IVIARSHALL {1 WENDELL J. {1 C. FISCHER THE AMPICO DEVOTED TO THE PRACTICAL. SCIENTIFIC and EDUCATIONAL ADVANCE1\tlENT of the TUNER .·+-)Ge1- ------ ------ ------ -I19JI-4-· AMERICAN PIANO COMPANY Volume 8 52.00 a year Number 12 Ampico Hall (Canada, $2.50; Foreign, $3.00) 25 cents a copy 584 Fifth Avenue New York Published on th ] 5th dn.y of each month P. O. Box 396 Kansas City. fissourl Entered a. Second Class Matter July, 14, 1921, at the Post DHice at Kansas City, Mo., Under Act of March 3, 1879. MAY, 1929 457 The Aeolian Factory at Garwood, New Jersey, where the wonderful Duo_Art tions are manufa tured. Are You a Gulbransen Registered Mechanic? If not you should be. You can if you have had five or more years experi ence as a player mechanic and tuner and are fami1iar with The George Steck Piano fa c the Gulbransen. tory at Neponset, Mass. , ne of the Great Plants of the Send us this coupon and we will tell you how to reg Aeolian Company. -

Unicode Technical Note: Byzantine Musical Notation
1 Unicode Technical Note: Byzantine Musical Notation Version 1.0: January 2005 Nick Nicholas; [email protected] This note documents the practice of Byzantine Musical Notation in its various forms, as an aid for implementors using its Unicode encoding. The note contains a good deal of background information on Byzantine musical theory, some of which is not readily available in English; this helps to make sense of why the notation is the way it is.1 1. Preliminaries 1.1. Kinds of Notation. Byzantine music is a cover term for the liturgical music used in the Orthodox Church within the Byzantine Empire and the Churches regarded as continuing that tradition. This music is monophonic (with drone notes),2 exclusively vocal, and almost entirely sacred: very little secular music of this kind has been preserved, although we know that court ceremonial music in Byzantium was similar to the sacred. Byzantine music is accepted to have originated in the liturgical music of the Levant, and in particular Syriac and Jewish music. The extent of continuity between ancient Greek and Byzantine music is unclear, and an issue subject to emotive responses. The same holds for the extent of continuity between Byzantine music proper and the liturgical music in contemporary use—i.e. to what extent Ottoman influences have displaced the earlier Byzantine foundation of the music. There are two kinds of Byzantine musical notation. The earlier ecphonetic (recitative) style was used to notate the recitation of lessons (readings from the Bible). It probably was introduced in the late 4th century, is attested from the 8th, and was increasingly confused until the 15th century, when it passed out of use. -

Vapar Synth--A Variational Parametric Model for Audio Synthesis
VAPAR SYNTH - A VARIATIONAL PARAMETRIC MODEL FOR AUDIO SYNTHESIS Krishna Subramani , Preeti Rao Alexandre D’Hooge Indian Institute of Technology Bombay ENS Paris-Saclay [email protected] [email protected] ABSTRACT control over the perceptual timbre of synthesized instruments. With the advent of data-driven statistical modeling and abun- With the similar aim of meaningful interpolation of timbre in dant computing power, researchers are turning increasingly to audio morphing, Engel et al. [4] replaced the basic spectral deep learning for audio synthesis. These methods try to model autoencoder by a WaveNet [5] autoencoder. audio signals directly in the time or frequency domain. In the In the present work, rather than generating new timbres, interest of more flexible control over the generated sound, it we consider the problem of synthesis of a given instrument’s could be more useful to work with a parametric representation sound with flexible control over the pitch. Wyse [6] had the of the signal which corresponds more directly to the musical similar goal in providing additional information like pitch, ve- attributes such as pitch, dynamics and timbre. We present Va- locity and instrument class to a Recurrent Neural Network to Par Synth - a Variational Parametric Synthesizer which utilizes predict waveform samples more accurately. A limitation of a conditional variational autoencoder (CVAE) trained on a suit- his model was the inability to generalize to notes with pitches able parametric representation. We demonstrate1 our proposed the network has not seen before. Defossez´ et al. [7] also model’s capabilities via the reconstruction and generation of approached the task in a similar fashion, but proposed frame- instrumental tones with flexible control over their pitch. -

Major and Minor Scales Half and Whole Steps
Dr. Barbara Murphy University of Tennessee School of Music MAJOR AND MINOR SCALES HALF AND WHOLE STEPS: half-step - two keys (and therefore notes/pitches) that are adjacent on the piano keyboard whole-step - two keys (and therefore notes/pitches) that have another key in between chromatic half-step -- a half step written as two of the same note with different accidentals (e.g., F-F#) diatonic half-step -- a half step that uses two different note names (e.g., F#-G) chromatic half step diatonic half step SCALES: A scale is a stepwise arrangement of notes/pitches contained within an octave. Major and minor scales contain seven notes or scale degrees. A scale degree is designated by an Arabic numeral with a cap (^) which indicate the position of the note within the scale. Each scale degree has a name and solfege syllable: SCALE DEGREE NAME SOLFEGE 1 tonic do 2 supertonic re 3 mediant mi 4 subdominant fa 5 dominant sol 6 submediant la 7 leading tone ti MAJOR SCALES: A major scale is a scale that has half steps (H) between scale degrees 3-4 and 7-8 and whole steps between all other pairs of notes. 1 2 3 4 5 6 7 8 W W H W W W H TETRACHORDS: A tetrachord is a group of four notes in a scale. There are two tetrachords in the major scale, each with the same order half- and whole-steps (W-W-H). Therefore, a tetrachord consisting of W-W-H can be the top tetrachord or the bottom tetrachord of a major scale.