A Generalization of Pythagoras's Theorem and Application To
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
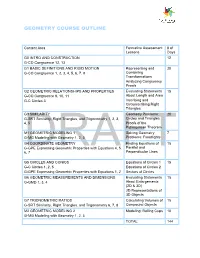
Geometry Course Outline
GEOMETRY COURSE OUTLINE Content Area Formative Assessment # of Lessons Days G0 INTRO AND CONSTRUCTION 12 G-CO Congruence 12, 13 G1 BASIC DEFINITIONS AND RIGID MOTION Representing and 20 G-CO Congruence 1, 2, 3, 4, 5, 6, 7, 8 Combining Transformations Analyzing Congruency Proofs G2 GEOMETRIC RELATIONSHIPS AND PROPERTIES Evaluating Statements 15 G-CO Congruence 9, 10, 11 About Length and Area G-C Circles 3 Inscribing and Circumscribing Right Triangles G3 SIMILARITY Geometry Problems: 20 G-SRT Similarity, Right Triangles, and Trigonometry 1, 2, 3, Circles and Triangles 4, 5 Proofs of the Pythagorean Theorem M1 GEOMETRIC MODELING 1 Solving Geometry 7 G-MG Modeling with Geometry 1, 2, 3 Problems: Floodlights G4 COORDINATE GEOMETRY Finding Equations of 15 G-GPE Expressing Geometric Properties with Equations 4, 5, Parallel and 6, 7 Perpendicular Lines G5 CIRCLES AND CONICS Equations of Circles 1 15 G-C Circles 1, 2, 5 Equations of Circles 2 G-GPE Expressing Geometric Properties with Equations 1, 2 Sectors of Circles G6 GEOMETRIC MEASUREMENTS AND DIMENSIONS Evaluating Statements 15 G-GMD 1, 3, 4 About Enlargements (2D & 3D) 2D Representations of 3D Objects G7 TRIONOMETRIC RATIOS Calculating Volumes of 15 G-SRT Similarity, Right Triangles, and Trigonometry 6, 7, 8 Compound Objects M2 GEOMETRIC MODELING 2 Modeling: Rolling Cups 10 G-MG Modeling with Geometry 1, 2, 3 TOTAL: 144 HIGH SCHOOL OVERVIEW Algebra 1 Geometry Algebra 2 A0 Introduction G0 Introduction and A0 Introduction Construction A1 Modeling With Functions G1 Basic Definitions and Rigid -

Right Triangles and the Pythagorean Theorem Related?
Activity Assess 9-6 EXPLORE & REASON Right Triangles and Consider △ ABC with altitude CD‾ as shown. the Pythagorean B Theorem D PearsonRealize.com A 45 C 5√2 I CAN… prove the Pythagorean Theorem using A. What is the area of △ ABC? Of △ACD? Explain your answers. similarity and establish the relationships in special right B. Find the lengths of AD‾ and AB‾ . triangles. C. Look for Relationships Divide the length of the hypotenuse of △ ABC VOCABULARY by the length of one of its sides. Divide the length of the hypotenuse of △ACD by the length of one of its sides. Make a conjecture that explains • Pythagorean triple the results. ESSENTIAL QUESTION How are similarity in right triangles and the Pythagorean Theorem related? Remember that the Pythagorean Theorem and its converse describe how the side lengths of right triangles are related. THEOREM 9-8 Pythagorean Theorem If a triangle is a right triangle, If... △ABC is a right triangle. then the sum of the squares of the B lengths of the legs is equal to the square of the length of the hypotenuse. c a A C b 2 2 2 PROOF: SEE EXAMPLE 1. Then... a + b = c THEOREM 9-9 Converse of the Pythagorean Theorem 2 2 2 If the sum of the squares of the If... a + b = c lengths of two sides of a triangle is B equal to the square of the length of the third side, then the triangle is a right triangle. c a A C b PROOF: SEE EXERCISE 17. Then... △ABC is a right triangle. -

Pythagorean Theorem Word Problems Ws #1 Name ______
Pythagorean Theorem word problems ws #1 Name __________________________ Solve each of the following. Please draw a picture and use the Pythagorean Theorem to solve. Be sure to label all answers and leave answers in exact simplified form. 1. The bottom of a ladder must be placed 3 feet from a wall. The ladder is 12 feet long. How far above the ground does the ladder touch the wall? 2. A soccer field is a rectangle 90 meters wide and 120 meters long. The coach asks players to run from one corner to the corner diagonally across the field. How far do the players run? 3. How far from the base of the house do you need to place a 15’ ladder so that it exactly reaches the top of a 12’ wall? 4. What is the length of the diagonal of a 10 cm by 15 cm rectangle? 5. The diagonal of a rectangle is 25 in. The width is 15 in. What is the area of the rectangle? 6. Two sides of a right triangle are 8” and 12”. A. Find the the area of the triangle if 8 and 12 are legs. B. Find the area of the triangle if 8 and 12 are a leg and hypotenuse. 7. The area of a square is 81 cm2. Find the perimeter of the square. 8. An isosceles triangle has congruent sides of 20 cm. The base is 10 cm. What is the area of the triangle? 9. A baseball diamond is a square that is 90’ on each side. -

5-7 the Pythagorean Theorem 5-7 the Pythagorean Theorem
55-7-7 TheThe Pythagorean Pythagorean Theorem Theorem Warm Up Lesson Presentation Lesson Quiz HoltHolt McDougal Geometry Geometry 5-7 The Pythagorean Theorem Warm Up Classify each triangle by its angle measures. 1. 2. acute right 3. Simplify 12 4. If a = 6, b = 7, and c = 12, find a2 + b2 2 and find c . Which value is greater? 2 85; 144; c Holt McDougal Geometry 5-7 The Pythagorean Theorem Objectives Use the Pythagorean Theorem and its converse to solve problems. Use Pythagorean inequalities to classify triangles. Holt McDougal Geometry 5-7 The Pythagorean Theorem Vocabulary Pythagorean triple Holt McDougal Geometry 5-7 The Pythagorean Theorem The Pythagorean Theorem is probably the most famous mathematical relationship. As you learned in Lesson 1-6, it states that in a right triangle, the sum of the squares of the lengths of the legs equals the square of the length of the hypotenuse. a2 + b2 = c2 Holt McDougal Geometry 5-7 The Pythagorean Theorem Example 1A: Using the Pythagorean Theorem Find the value of x. Give your answer in simplest radical form. a2 + b2 = c2 Pythagorean Theorem 22 + 62 = x2 Substitute 2 for a, 6 for b, and x for c. 40 = x2 Simplify. Find the positive square root. Simplify the radical. Holt McDougal Geometry 5-7 The Pythagorean Theorem Example 1B: Using the Pythagorean Theorem Find the value of x. Give your answer in simplest radical form. a2 + b2 = c2 Pythagorean Theorem (x – 2)2 + 42 = x2 Substitute x – 2 for a, 4 for b, and x for c. x2 – 4x + 4 + 16 = x2 Multiply. -

The Pythagorean Theorem and Area: Postulates Into Theorems Paul A
Humanistic Mathematics Network Journal Issue 25 Article 13 8-1-2001 The Pythagorean Theorem and Area: Postulates into Theorems Paul A. Kennedy Texas State University Kenneth Evans Texas State University Follow this and additional works at: http://scholarship.claremont.edu/hmnj Part of the Mathematics Commons, Science and Mathematics Education Commons, and the Secondary Education and Teaching Commons Recommended Citation Kennedy, Paul A. and Evans, Kenneth (2001) "The Pythagorean Theorem and Area: Postulates into Theorems," Humanistic Mathematics Network Journal: Iss. 25, Article 13. Available at: http://scholarship.claremont.edu/hmnj/vol1/iss25/13 This Article is brought to you for free and open access by the Journals at Claremont at Scholarship @ Claremont. It has been accepted for inclusion in Humanistic Mathematics Network Journal by an authorized administrator of Scholarship @ Claremont. For more information, please contact [email protected]. The Pythagorean Theorem and Area: Postulates into Theorems Paul A. Kennedy Contributing Author: Department of Mathematics Kenneth Evans Southwest Texas State University Department of Mathematics, Retired San Marcos, TX 78666-4616 Southwest Texas State University [email protected] San Marcos, TX 78666-4616 Considerable time is spent in high school geometry equal to the area of the square on the hypotenuse. building an axiomatic system that allows students to understand and prove interesting theorems. In tradi- tional geometry classrooms, the theorems were treated in isolation with some of -

The Pythagorean Theorem
6.2 The Pythagorean Theorem How are the lengths of the sides of a right STATES triangle related? STANDARDS MA.8.G.2.4 MA.8.A.6.4 Pythagoras was a Greek mathematician and philosopher who discovered one of the most famous rules in mathematics. In mathematics, a rule is called a theorem. So, the rule that Pythagoras discovered is called the Pythagorean Theorem. Pythagoras (c. 570 B.C.–c. 490 B.C.) 1 ACTIVITY: Discovering the Pythagorean Theorem Work with a partner. a. On grid paper, draw any right triangle. Label the lengths of the two shorter sides (the legs) a and b. c2 c a a2 b. Label the length of the longest side (the hypotenuse) c. b b2 c . Draw squares along each of the three sides. Label the areas of the three squares a 2, b 2, and c 2. d. Cut out the three squares. Make eight copies of the right triangle and cut them out. a2 Arrange the fi gures to form 2 two identical larger squares. c b2 e. What does this tell you about the relationship among a 2, b 2, and c 2? 236 Chapter 6 Square Roots and the Pythagorean Theorem 2 ACTIVITY: Finding the Length of the Hypotenuse Work with a partner. Use the result of Activity 1 to fi nd the length of the hypotenuse of each right triangle. a. b. c 10 c 3 24 4 c. d. c 0.6 2 c 3 0.8 1 2 3 ACTIVITY: Finding the Length of a Leg Work with a partner. -

The Euclidean Mousetrap
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by PhilPapers Originally in Journal of Idealistic Studies 38(3): 209-220 (2008). Please quote from published version. THE EUCLIDEAN MOUSETRAP: SCHOPENHAUER’S CRITICISM OF THE SYNTHETIC METHOD IN GEOMETRY Jason M. Costanzo Abstract In his doctoral dissertation On the Principle of Sufficient Reason, Arthur Schopenhauer there outlines a critique of Euclidean geometry on the basis of the changing nature of mathematics, and hence of demonstration, as a result of Kantian idealism. According to Schopenhauer, Euclid treats geometry synthetically, proceeding from the simple to the complex, from the known to the unknown, “synthesizing” later proofs on the basis of earlier ones. Such a method, although proving the case logically, nevertheless fails to attain the raison d’être of the entity. In order to obtain this, a separate method is required, which Schopenhauer refers to as “analysis”, thus echoing a method already in practice among the early Greek geometers, with however some significant differences. In this essay, I here discuss Schopenhauer’s criticism of synthesis in Euclid’s Elements, and the nature and relevance of his own method of analysis. The influence of philosophy upon the development of mathematics is readily seen in the practice among mathematicians of offering a demonstration or “proof” of the many theorems and problems which they encounter. This practice finds its origin among the early Greek geometricians and arithmeticians, during a time in which philosophy and mathematics intermingled at an unprecedented level, and a period in which rationalism enjoyed preeminence. -

Chapter 13 the Theories of Special and General Relativity Special
Ron Ferril SBCC Physics 101 Chapter 13 2017Jul23A Page 1 of 14 Chapter 13 The Theories of Special and General Relativity Special Relativity The Theory of Special Relativity, often called the Special Theory of Relativity or just “special relativity” for a shorter name, is a replacement of Galilean relativity and is necessary for describing dynamics involving high speeds. Galilean relativity is very useful as long as the speeds of bodies are fairly small. For example, the speeds of a supersonic jet, a rifle bullet, and a rocket (such as the Apollo vehicle that went to and from the Moon at about 25,000 miles per hour) are all handled well by Galilean relativity. However, special relativity is required in explanations of the dynamics at the higher speeds of high-energy subatomic particles in cosmic rays and in large particle accelerators. Both Galilean relativity and special relativity involve “frames of reference” which are also called “reference frames.” A frame of reference is the location of an observer of physical processes. For a more mathematical view, a frame of reference can be viewed as a coordinate system for specifying the locations of bodies or physical events from the viewpoint of the observer. An observer may specify positions of bodies and events as distances relative to his or her own position. The positions can also be specified by a combination of distance from the observer and angles from the direction the observer is facing. The distances and angles can be called “coordinates.” An “inertial frame of reference” or “inertial reference frame” is a frame of reference that does not accelerate. -

The Pythagorean Theorem Crown Jewel of Mathematics
The Pythagorean Theorem Crown Jewel of Mathematics 5 3 4 John C. Sparks The Pythagorean Theorem Crown Jewel of Mathematics By John C. Sparks The Pythagorean Theorem Crown Jewel of Mathematics Copyright © 2008 John C. Sparks All rights reserved. No part of this book may be reproduced in any form—except for the inclusion of brief quotations in a review—without permission in writing from the author or publisher. Front cover, Pythagorean Dreams, a composite mosaic of historical Pythagorean proofs. Back cover photo by Curtis Sparks ISBN: XXXXXXXXX First Published by Author House XXXXX Library of Congress Control Number XXXXXXXX Published by AuthorHouse 1663 Liberty Drive, Suite 200 Bloomington, Indiana 47403 (800)839-8640 www.authorhouse.com Produced by Sparrow-Hawke †reasures Xenia, Ohio 45385 Printed in the United States of America 2 Dedication I would like to dedicate The Pythagorean Theorem to: Carolyn Sparks, my wife, best friend, and life partner for 40 years; our two grown sons, Robert and Curtis; My father, Roscoe C. Sparks (1910-1994). From Earth with Love Do you remember, as do I, When Neil walked, as so did we, On a calm and sun-lit sea One July, Tranquillity, Filled with dreams and futures? For in that month of long ago, Lofty visions raptured all Moonstruck with that starry call From life beyond this earthen ball... Not wedded to its surface. But marriage is of dust to dust Where seasoned limbs reclaim the ground Though passing thoughts still fly around Supernal realms never found On the planet of our birth. And I, a man, love you true, Love as God had made it so, Not angel rust when then aglow, But coupled here, now rib to soul, Dear Carolyn of mine. -

The Pythagorean Theorem: What Is It About?
THE PYTHAGOREAN THEOREM: WHAT IS IT ABOUT? ALEXANDER GIVENTAL Although twenty five centuries old, the Pythagorean theorem appears vigor- ous and ubiquitous. A key to the distance formula in Descartes’s method of coordinates, the theorem is implicitly present in all scientific models and engineering computations involving spatial relationships or trigonometry. An invisible companion to the dot-product operation, it is inherent in equations of mathematical physics and continuum mechanics, be those Laplace, Navier- Stokes, Maxwell or Yang-Mills. Disguised by axiomatic constructions of linear algebra and Riemannian geometry, it animates both quantum physics and Ein- stein’s gravitation, which are otherwise so hard to reconcile. And of course, a rare day of a statistician or experimenter goes by without Euclid’s nightmare— fitting any three or more points into a straight line, which is accomplished by Gaussian least squares and hence is also reminiscent of Pythagoras. Quite deservedly, therefore, the philosopher’s pants are proudly displayed in middle-school textbooks to represent, perhaps, the only scientific truth circu- lating among the general public “with proof.” The most popular one (shown in Figure 1) is very convincing indeed. Yet it pictures the whole issue as a cut-and-paste puzzle and leaves us with a feeling of disproportion: one of the most fundamental facts of nature is due to an ingenious tiling trick. The vast majority of other proofs 1 are similar in nature. B C A Figure 1. A + B = C. 1 Of dozens, if not hundreds (see http://www.cut-the-knot.org/pythagoras/index.shtml and references therein). -

Einstein's Boyhood Proof of the Pythagorean Theorem
Einstein’s Boyhood Proof of the Pythagorean Theorem - The New Yorker 4/14/16, 9:14 AM Save paper and follow @newyorker on Twitter NOVEMBER 19, 2015 Einstein’s First Proof BY STEVEN STROGATZ A physicist’s genius turns up in his boyhood geometry. ILLUSTRATION BY TOMI UM n November 26, 1949, Albert Einstein published an essay in the Saturday Review of Literature in which he described two pivotal moments in his childhood. The first Oinvolved a compass that his father showed him when he was four or five. Einstein recalled his sense of wonderment that the needle always pointed north, even though nothing appeared to be pulling it in that direction. He came to a conclusion, then and there, about the structure of the physical world: “Something deeply hidden had to be behind things.” The second moment occurred soon after he turned twelve, when he was given “a little book dealing with Euclidean plane geometry.” The book’s “lucidity,” he wrote—the idea that a mathematical assertion could “be proved with such certainty that any doubt appeared to be out of the question”—provoked “wonder of a totally different nature.” Pure thought could be just as powerful as geomagnetism. This month, we celebrate the hundredth anniversary of Einstein’s general theory of relativity, one of his many ideas that brought lucidity to the deeply hidden. With all the surrounding hoopla, it would be nice if we could fathom something of what he actually accomplished and how he did it. That turns out to be a tall order, because general relativity is tremendously complex (http://www.newyorker.com/tech/elements/the-space-doctors-big-idea- einstein-general-relativity). -

Parallel and Perpendicular
CONDENSED LESSON 11.1 Parallel and Perpendicular In this lesson you will ● learn the meaning of parallel and perpendicular ● discover how the slopes of parallel and perpendicular lines are related ● use slopes to help classify figures in the coordinate plane Parallel lines are lines in the same plane that never intersect. Perpendicular lines are lines in the same plane that intersect at a right angle. We show a small box in one of the angles to show that the lines are perpendicular. Investigation: Slopes The opposite sides of a rectangle are parallel, and the adjacent sides are perpendicular. By examining rectangles drawn on a coordinate grid, you can discover how the slopes of parallel and perpendicular lines are related. Step 1 gives the vertices of four rectangles. Here is the rectangle with y the vertices given in part a. A Find the slope of each side of the rectangle. You should get these 20 results. (Note: The notation AB means “segment AB.”) 10 B 7 9 D Slope of AD: ᎏᎏ Slope of AB: Ϫᎏᎏ 9 7 x Ϫ 7 9 10 10 20 Slope of BC: ᎏᎏ Slope of DC: Ϫᎏᎏ C 9 7 Ϫ10 Notice that the slopes of the parallel sides AD and BC are the same and that the slopes of the parallel sides AB and DC are the same. Recall that, to find the reciprocal of a fraction, you exchange the numerator and the ᎏ3ᎏ ᎏ4ᎏ denominator. For example, the reciprocal of 4 is 3. The product of a number and its reciprocal is 1.