Web Automation and Libwww-Perl)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Open Source Used in Cisco 7600 Wireless Security Gateway Release 4.4
Open Source Used In Cisco 7600 Wireless Security Gateway Release 4.4 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Open Source Used In Cisco 7600 Wireless Security Gateway Release 4.4 1 Text Part Number: 78EE117C99-66606837 Open Source Used In Cisco 7600 Wireless Security Gateway Release 4.4 2 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-66606837 Contents 1.1 Apache HTTP Server 2.2.3 :5.0.0.0801182 1.1.1 Available under license 1.2 audit 1.2.9 :7.0.0 1.2.1 Available under license 1.3 base-passwd 3.5.7 :11.0.0.0801182 1.3.1 Available under license 1.4 bash 3.0 :6.0.2.0801182 1.4.1 Available under license 1.5 binutils 2.17.50 :10.0.5.0801182 1.5.1 Available under license 1.6 busybox 1.6.0 :7.0.2.0801182 1.6.1 Available under license 1.7 busybox-static 1.6.0 :7.0.2.0801182 1.7.1 Available under license 1.8 cron 3.0pl1 :5.0.2.0801182 1.8.1 Available under license 1.9 db 4.3.28 :1.0.0.0801182 1.9.1 Available under license 1.10 e2fsprogs 1.41.3 :1.0.0 1.10.1 Available -

The Origins of the Underline As Visual Representation of the Hyperlink on the Web: a Case Study in Skeuomorphism
The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Romano, John J. 2016. The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism. Master's thesis, Harvard Extension School. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:33797379 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism John J Romano A Thesis in the Field of Visual Arts for the Degree of Master of Liberal Arts in Extension Studies Harvard University November 2016 Abstract This thesis investigates the process by which the underline came to be used as the default signifier of hyperlinks on the World Wide Web. Created in 1990 by Tim Berners- Lee, the web quickly became the most used hypertext system in the world, and most browsers default to indicating hyperlinks with an underline. To answer the question of why the underline was chosen over competing demarcation techniques, the thesis applies the methods of history of technology and sociology of technology. Before the invention of the web, the underline–also known as the vinculum–was used in many contexts in writing systems; collecting entities together to form a whole and ascribing additional meaning to the content. -

Annotea: an Open RDF Infrastructure for Shared Web Annotations
Proceedings of the WWW 10th International Conference, Hong Kong, May 2001. Annotea: An Open RDF Infrastructure for Shared Web Annotations Jos´eKahan,1 Marja-Riitta Koivunen,2 Eric Prud’Hommeaux2 and Ralph R. Swick2 1 W3C INRIA Rhone-Alpes 2 W3C MIT Laboratory for Computer Science {kahan, marja, eric, swick}@w3.org Abstract. Annotea is a Web-based shared annotation system based on a general-purpose open RDF infrastructure, where annotations are modeled as a class of metadata.Annotations are viewed as statements made by an author about a Web doc- ument. Annotations are external to the documents and can be stored in one or more annotation servers.One of the goals of this project has been to re-use as much existing W3C technol- ogy as possible. We have reacheditmostlybycombining RDF with XPointer, XLink, and HTTP. We have also implemented an instance of our system using the Amaya editor/browser and ageneric RDF database, accessible through an Apache HTTP server. In this implementation, the merging of annotations with documents takes place within the client. The paper presents the overall design of Annotea and describes some of the issues we have faced and how we have solved them. 1Introduction One of the basic milestones in the road to a Semantic Web [22] is the as- sociation of metadata to content. Metadata allows the Web to describe properties about some given content, even if the medium of this content does not directly provide the necessary means to do so. For example, ametadata schema for digital photos [15] allows the Web to describe, among other properties, the camera model used to take a photo, shut- ter speed, date, and location. -

Statistics for Donauschwaben-Usa.Org (2009-03)
Statistics for donauschwaben-usa.org (2009-03) Statistics for: donauschwaben-usa.org Last Update: 03 Apr 2009 - 14:14 Reported period: Month Mar 2009 When: Monthly history Days of month Days of week Hours Who: Organizations Countries Full list Hosts Full list Last visit Unresolved IP Address Robots/Spiders visitors Full list Last visit Navigation: Visits duration File type Viewed Full list Entry Exit Operating Systems Versions Unknown Browsers Versions Unknown Referrers: Origin Referring search engines Referring sites Search Search Keyphrases Search Keywords Others: Miscellaneous HTTP Status codes Pages not found Summary Reported period Month Mar 2009 First visit 01 Mar 2009 - 00:17 Last visit 31 Mar 2009 - 23:17 Unique visitors Number of visits Pages Hits Bandwidth 2112 2781 15381 71620 4.59 GB Viewed traffic * (1.31 visits/visitor) (5.53 Pages/Visit) (25.75 Hits/Visit) (1732.12 KB/Visit) Not viewed traffic * 8539 10927 896.73 MB * Not viewed traffic includes traffic generated by robots, worms, or replies with special HTTP status codes. Monthly history Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2009 2009 2009 2009 2009 2009 2009 2009 2009 2009 2009 2009 Month Unique visitors Number of visits Pages Hits Bandwidth Jan 2009 0 0 0 0 0 Feb 2009 0 0 0 0 0 Mar 2009 2112 2781 15381 71620 4.59 GB Apr 2009 0 0 0 0 0 May 2009 0 0 0 0 0 Jun 2009 0 0 0 0 0 Jul 2009 0 0 0 0 0 Aug 2009 0 0 0 0 0 Sep 2009 0 0 0 0 0 Oct 2009 0 0 0 0 0 Nov 2009 0 0 0 0 0 Dec 2009 0 0 0 0 0 Total 2112 2781 15381 71620 4.59 GB Days of month 01 02 03 04 05 06 07 08 -

Rewriteengine on # Libwww-Perl Access Fix # Rewritecond
# RewriteEngine On # Libwww-perl Access Fix # RewriteCond %{HTTP_USER_AGENT} libwww-perl.* # RewriteRule .* – [F,L] # Redirect www to non-www # RewriteEngine On # RewriteBase / # RewriteCond %{HTTP_HOST} ^www\.(.*)$ [NC] # RewriteRule ^(.*)$ http://%1/$1 [R=301,L] # Turn eTags Off # https://github.com/ucarmetin/toolbox/blob/master/lists/awesome-htaccess.md#turn-etags- off # <IfModule mod_headers.c> # Header unset ETag # </IfModule> # FileETag None # BEGIN GZIP <ifmodule mod_deflate.c> AddType x-font/otf .otf AddType x-font/ttf .ttf AddType x-font/eot .eot AddType x-font/woff .woff AddType x-font/woff2 .woff2 AddType image/x-icon .ico AddType image/png .png AddType text/css .css AddType image/svg+xml .svg AddOutputFilterByType DEFLATE text/text text/html text/plain text/xml text/css application/x-javascript application/javascript image/svg+xml x-font/otf x-font/ttf x- font/eot x-font/woff x-font/woff2 image/x-icon image/png </ifmodule> # END GZIP # BEGIN Cache-Control Headers <ifModule mod_headers.c> <filesMatch "\.(ico|jpe?g|png|gif|swf)$"> Header set Cache-Control "public" Header set Cache-Control "public" </filesMatch> <filesMatch "\.(css)$"> Header set Cache-Control "public" </filesMatch> <filesMatch "\.(js)$"> Header set Cache-Control "private" </filesMatch> <filesMatch "\.(x?html?|php)$"> Header set Cache-Control "private, must-revalidate" </filesMatch> </ifModule> # END Cache-Control Headers # Proper MIME Types <IfModule mod_mime.c> # Audio AddType audio/mp4 m4a f4a f4b AddType audio/ogg oga ogg # JavaScript AddType application/javascript -

Web Browser Frequently Asked Questions (FAQ)
Web Browser Frequently Asked Questions (FAQ) Avaya™ IP Telephone Interface Release 2.2 for 4610SW, 4620/4620SW, 4621SW, and 4622SW IP Telephones Release 2.5 for the 4625SW IP Telephone Issue 2.5 April 2005 Copyright 2005, Avaya Inc. • Theft (such as, of intellectual property, financial assets, or toll All Rights Reserved facility access) Notice • Eavesdropping (privacy invasions to humans) Every effort was made to ensure that the information in this • Mischief (troubling, but apparently innocuous, tampering) document was complete and accurate at the time of printing. However, information is subject to change. • Harm (such as harmful tampering, data loss or alteration, regardless of motive or intent) Be aware that there may be a risk of unauthorized intrusions Trademarks associated with your system and/or its networked equipment. Also realize that, if such an intrusion should occur, it could result in a DEFINITY is a registered trademark of Avaya, Inc. MultiVantage variety of losses to your company (including but not limited to, is a trademark of Avaya, Inc. HTTP Server functionality is human/data privacy, intellectual property, material assets, financial provided by the GoAhead WebServer 2.1, Copyright © 2004 resources, labor costs, and/or legal costs). GoAhead Software, Inc. All Rights Reserved. Responsibility for Your Company’s Telecommunications Disclaimer Security Avaya is not responsible for any modifications, additions or The final responsibility for securing both this system and its deletions to the original published version of this documentation networked equipment rests with you - Avaya’s customer system unless such modifications, additions or deletions were performed administrator, your telecommunications peers, and your managers. -

Working with Html, Css, and Http
Chapter 2 WORKING WITH HTML, CSS, AND HTTP Working with HTML An essential aspect of running a website is creating HTML files. Even sites that rely heavily on page technologies other than static HTML, such as script-driven pages, inevitably keep many static HTML files on the site. Although Web authors can write HTML in any text editor, many have adopted specialized HTML editor programs to handle the job. Ideally, an HTML editor should manage the job of converting an authors writing into the structures defined by the HTML standard without requiring the author to know the details of that standard. As the job is accomplished, the editor program may carry out additional tasks, such as letting the author fine-tune the finished documents appearance or handling site management tasks such as uploading documents to a server and checking its links. The most widely used HTML editors handle these secondary tasks with great success. Over the years, however, many designers created their actual HTML code with an emphasis on appearance rather than structure. This so-called presentational markup achieved popularity with an older generation of browsers because no widely supported alternative to controlling an HTML documents appearance was available. Presentational HTML has drawbacks, though, and a growing number of Web authors are abandoning it in favor of HTML markup that describes a documents structure. Reasons for this choice include: Library Technology Reports Many aspects of presentational markup make assumptions about the users display environment (specifically, screen resolution and window width) that are increasingly unwarranted and may lead to accessibility problems. -

07 5390 8136 - - [email protected]
07 5390 8136 - www.snapcodesign.com.au - [email protected] Overall score for http://www.cbdremovalssydney.com.au/ Your Score is 69/100 13 Important Fixes 3 Semi-Important Fixes 31 Passed Checks The meta title of your page has a length of 86 characters. Most search engines will truncate meta titles to 70 characters. BEST REMOVALISTS SYDNEY |SYDNEY REMOVALISTS| HOME OFFICE REMOVALS SYDNEY- CBD REMOVALS The meta description of your page has a length of 31 characters. Most search engines will truncate meta descriptions to 160 characters. Removalists in Sydney Australia BEST REMOVALISTS SYDNEY |SYDNEY REMOVALISTS| HOME OFFICE REMOVALShttp://www.cbdremovalssydney.com.au/ SYDNEY- CBD REMOVALS We Are Best Sydney removalists, CBD Removals don't charge base to location fees. When you need a office, home or commercial Sydney removals service, call There is likely no optimal keyword density (search engine algorithms have evolved beyond keyword density metrics as a significant ranking factor). It can be useful, however, to note which keywords appear most often in your page, and if they reflect the intended topic of your page. More importantly, the keywords in your page should appear within natural sounding and grammatically correct copy. sydney - 16 times removalists - 16 times removals - 9 times furniture - 5 times service - 3 times Congratulations! You are using your keywords in your meta-tags, which helps search engines properly identify the topic of your page. Keyword(s) included in Meta-Title Tag Keyword(s) included in Meta-Description -
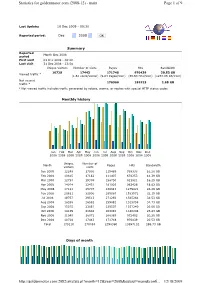
2008 Web Traffic Statistics
Statistics for goldenmotor.com (2008-12) - main Page 1 of 9 Last Update: 18 Dec 2009 - 00:30 Reported period: Dec 2008 OK Summary Reported Month Dec 2008 period First visit 01 Dec 2008 - 00:00 Last visit 31 Dec 2008 - 23:54 Unique visitors Number of visits Pages Hits Bandwidth 10728 17443 171748 970439 20.53 GB Viewed traffic * (1.62 visits/visitor) (9.84 Pages/Visit) (55.63 Hits/Visit) (1234.05 KB/Visit) Not viewed 176966 189923 2.85 GB traffic * * Not viewed traffic includes traffic generated by robots, worms, or replies with special HTTP status codes. Monthly history Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2008 2008 2008 2008 2008 2008 2008 2008 2008 2008 2008 2008 Unique Number of Month Pages Hits Bandwidth visitors visits Jan 2008 12249 17936 115489 769333 16.26 GB Feb 2008 10815 17182 111407 674253 14.39 GB Mar 2008 12754 19308 156750 821821 16.25 GB Apr 2008 14914 22451 181929 983426 18.83 GB May 2008 17121 25707 236817 1279421 24.29 GB Jun 2008 20811 31906 285067 1533571 32.15 GB Jul 2008 18757 29513 271292 1545264 34.53 GB Aug 2008 16558 26582 259882 1515758 34.73 GB Sep 2008 15315 23881 238507 1351240 29.06 GB Oct 2008 14139 21604 203087 1180204 25.43 GB Nov 2008 11049 16971 166385 972402 20.28 GB Dec 2008 10728 17443 171748 970439 20.53 GB Total 175210 270484 2398360 13597132 286.73 GB Days of month http://goldenmotor.com:2082/awstats.pl?month=12&year=2008&output=main&confi.. -

Le Web Social Table Des Matières
Le Web Social Table des matières 1 Web social 1 1.1 Historique ............................................... 1 1.2 L'évolution du web social ....................................... 1 1.2.1 Blogs et wiki ......................................... 1 1.2.2 L'art social .......................................... 2 1.2.3 Le crowdsourcing ...................................... 2 1.2.4 Le développement d'applications mobiles .......................... 2 1.2.5 Des projets de logiciels communautaires ........................... 2 1.3 Du web social à la vie réelle ..................................... 2 1.4 Bibliographie ............................................. 3 1.5 Notes et références .......................................... 3 1.6 Voir aussi ............................................... 3 2 Réseautage social 4 2.1 Histoire ................................................ 4 2.2 Applications .............................................. 4 2.3 Modèle économique ......................................... 5 2.3.1 Commerce des données ................................... 5 2.3.2 Vente d'espaces publicitaires ................................. 5 2.3.3 Cession des actifs ....................................... 5 2.4 Domaines d'application ........................................ 5 2.4.1 Réseaux internes versus réseaux externes ........................... 6 2.4.2 Services en ligne de réseautage professionnels ........................ 6 2.4.3 Réseaux sociaux d'amis de la vie réelle ............................ 6 2.4.4 Services en ligne d'ancien -

Statistics for Donauschwaben-Usa.Org (2011-01)
Statistics for donauschwaben-usa.org (2011-01) Statistics for: donauschwaben-usa.org Last Update: 02 Feb 2011 - 18:06 Reported period: Month Jan 2011 When: Monthly history Days of month Days of week Hours Who: Organizations Countries Full list Hosts Full list Last visit Unresolved IP Address Robots/Spiders visitors Full list Last visit Navigation: Visits duration File type Viewed Full list Entry Exit Operating Systems Versions Unknown Browsers Versions Unknown Referrers: Origin Referring search engines Referring sites Search Search Keyphrases Search Keywords Others: Miscellaneous HTTP Status codes Pages not found Summary Reported period Month Jan 2011 First visit 01 Jan 2011 - 00:06 Last visit 31 Jan 2011 - 23:48 Unique visitors Number of visits Pages Hits Bandwidth 6255 7645 29557 158592 13.36 GB Viewed traffic * (1.22 visits/visitor) (3.86 Pages/Visit) (20.74 Hits/Visit) (1832.93 KB/Visit) Not viewed traffic * 36308 45217 3.53 GB * Not viewed traffic includes traffic generated by robots, worms, or replies with special HTTP status codes. Monthly history Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2011 2011 2011 2011 2011 2011 2011 2011 2011 2011 2011 2011 Month Unique visitors Number of visits Pages Hits Bandwidth Jan 2011 6255 7645 29557 158592 13.36 GB Feb 2011 0 0 0 0 0 Mar 2011 0 0 0 0 0 Apr 2011 0 0 0 0 0 May 2011 0 0 0 0 0 Jun 2011 0 0 0 0 0 Jul 2011 0 0 0 0 0 Aug 2011 0 0 0 0 0 Sep 2011 0 0 0 0 0 Oct 2011 0 0 0 0 0 Nov 2011 0 0 0 0 0 Dec 2011 0 0 0 0 0 Total 6255 7645 29557 158592 13.36 GB Days of month 01 02 03 04 05 06 07 -
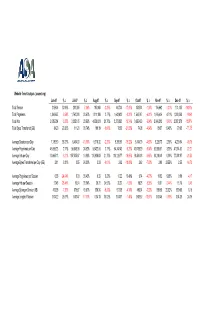
Summary - Date Range: 12/01/2007 - 12/31/2007
Website Trend Analysis (asanet.org) Jun-07 % ∆ Jul-07 % ∆ Aug-07 % ∆ Sep-07 % ∆ Oct-07 % ∆ Nov-07 % ∆ Dec-07 % ∆ Total Session 215,604 30.96% 200,385 -7.06% 195,868 -2.25% 160,704 -17.95% 158,534 -1.35% 156,662 -1.21% 131,435 -16.10% Total Pageviews 1,369,657 -0.54% 1,762,290 28.67% 1,811,100 2.77% 1,642,423 -9.31% 1,543,747 -6.01% 1,616,426 4.71% 1,299,350 -19.62 Total Hits 2,689,954 -6.33% 3,335,165 23.99% 4,058,831 21.70% 3,273,893 -19.34% 3,056,429 -6.64% 2,946,312 -3.60% 2,387,278 -18.97% Total Bytes Transferred (GB) 84.29 29.26% 111.20 30.74% 100.19 -9.90% 78.63 -21.52% 74.98 -4.64% 89.57 19.46% 79.05 -11.75 Average Sessions per Day 7,186.80 35.33% 6,464.03 -10.06% 6,318.32 -2.26% 5,356.80 -15.22% 5,114.00 -4.53% 5,220.73 2.09% 4,239.84 -18.79 Average Pageviews per Day 45,655.23 2.77% 56,848.06 24.52% 58,422.58 2.77% 54,747.43 -6.29% 49,798.29 -9.04% 53,880.87 8.20% 41,914.52 -22.21 Average Hits per Day 89,665.13 -3.21% 107,585.97 19.99% 130,930.03 21.70% 109,129.77 -16.65% 98,594.48 -9.65% 98,210.40 -0.39% 77,008.97 -21.59 Average Bytes Transferred per Day (GB) 2.81 3.81% 3.55 26.33% 3.23 -9.01% 2.62 -18.89% 2.42 -7.63% 2.99 23.55% 2.55 -14.72 Average Pageviews per Session 6.35 -24.04% 8.79 38.43% 9.25 5.23% 10.22 10.49% 9.74 -4.70% 10.32 5.95% 9.89 -4.17 Average Hits per Session 12.48 -28.44% 16.64 33.34% 20.72 24.52% 20.37 -1.69% 19.28 -5.35% 18.81 -2.44% 18.16 -3.46 Average Bytes per Session (KB) 409.95 -1.30% 576.67 40.67% 536.34 -6.99% 513.05 -4.34% 495.94 -3.33% 599.68 20.92% 630.65 5.16 Average Length of Session 0:04:22