APPLIED MACHINE LEARNING for CYBERSECURITY in SPAM FILTERING and MALWARE DETECTION by Mark Sokolov December, 2020
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IBM Cloud Pak for Data
IBM Cloud Pak for Data IBM Cloud Pak for Data Intelligently automate your data and AI strategy to connect the right data, to the right people, at the right time, from anywhere. Contents Introduction – IBM Cloud Pak for Data: Any data. Any cloud. Anywhere In today’s uncertain environment every organization must become smarter and more responsive to intelligently operate and engage the – The next generation of world, resiliently respond to market changes, flexibly optimize costs, IBM Cloud Pak for Data and innovate. Fueled by data, AI is empowering leading organizations to transform and deliver value. A recent study found that data-driven – Deployment models for organizations are 178% more likely to outperform in terms of revenue IBM Cloud Pak for Data and profitability. – Top use cases for IBM Cloud However, to successfully scale AI throughout your business, you Pak for Data must overcome data complexity. Companies today are struggling to manage and maintain vast amounts of data spanning public, private – Next steps and on-premises clouds. 70 percent of global respondents stated their company is pulling from over 20 different data sources to inform their AI, BI, and analytics systems. In addition, one third cited data complexity and data siloes as top barriers to AI adoption. Further compounding the complexity of these hybrid data landscapes is the fact that the lifespan of that data—the time that it is most relevant and valuable—is drastically shrinking. 1 The solution? An agile and resilient cloud-native platform that enables clients to predict and automate outcomes with trusted data and AI. -

Innovator Exercise Steps to Perform This Part of the Exercise We Will Be
Innovator Predict Employee Turnover using IBM Watson Studio Build, train and evaluate Machine Learning models Exercise steps To perform this part of the exercise we will be using a feature in Watson Studio called AutoAI. AutoAI is an automated machine learning tool that helps to quickly get started and work with machine learning models. It helps in cleaning the data, preparing the data, feature engineering, hyper parameter optimization, model experimentation and then finally choosing the right model to deploy for your data. 1. Let’s start by adding an AutoAI experiment asset type to the project. Click on the Add to project button in the Assets tab of your project and click on AutoAI Experiment. 2. Name the model “Predicting Employee Turnover” and click on Associate a Machine Learning service instance to create a new Machine Learning instance on your cloud. Innovator Predict Employee Turnover using IBM Watson Studio Build, train and evaluate Machine Learning models 3. A new tab will open with the details of the Machine Learning instance. Make sure you’re creating a New Machine Learning instance. Innovator Predict Employee Turnover using IBM Watson Studio Build, train and evaluate Machine Learning models 4. Again, make sure that the lite plan is selected. 5. Leave everything as default, scroll down to the bottom and create the Machine Learning instance. Innovator Predict Employee Turnover using IBM Watson Studio Build, train and evaluate Machine Learning models 6. Confirm the creation of the instance. 7. Once the Machine Learning instance is created, you should be back on the Create an AutoAI experiment details screen. -

Automated Artificial Intelligence (Autoai)
ADA Research Group Technical Report TR-2018-1 Automated Artificial Intelligence (AutoAI) Holger H. Hoos Leiden Institute of Advanced Computer Science (LIACS) Universiteit Leiden The Netherlands 24 December 2018 Abstract While there has been research on artificial intelligence (AI) for at least 50 years, we are now standing on the threshold of an AI revolution – a transformational change whose effects may surpass that of the indus- trial revolution in the first half of the 19th century. There are multiple reasons why AI is rapidly gaining traction now. Firstly, much of our infrastructure is already controlled by computers; so deploying AI systems is technologically quite straightforward. Secondly, in many situations, there is now easy access to large amounts of data, which can be used as a basis for customising AI systems using machine learn- ing. Thirdly, due to tremendous improvements not only in computer hardware, but also in AI algorithms, advanced AI systems can now be deployed broadly and at low cost. As a result, AI systems are poised to fundamentally change the way we live and work. AI is quickly becoming a major driver of innovation, growth and competitiveness, and is bound to play a crucial role in addressing the challenges we face individually and as societies. However, high-quality AI systems require considerable expertise to build, maintain and operate. For the foreseeable future, AI expertise will be a limiting factor in the broad deployment of AI systems, and – unless managed very carefully – this will lead to uneven access and increasing inequality. It is also likely to cause the wide-spread use of low-quality AI systems, developed without the proper expertise. -

Openbox: a Generalized Black-Box Optimization Service
OpenBox: A Generalized Black-box Optimization Service Yang Liy, Yu Shenyx, Wentao Zhangy, Yuanwei Cheny, Huaijun Jiangyx, Mingchao Liuy Jiawei Jiangz, Jinyang Gao⋄, Wentao Wu∗, Zhi Yangy, Ce Zhangz, Bin Cuiy yPeking University, China zETH Zurich, Switzerland ∗Microsoft Research, USA ⋄Alibaba Group, China xKuaishou Technology, China y{liyang.cs, shenyu, wentao.zhang, yw.chen, jianghuaijun, by_liumingchao, yangzhi, bin.cui}@pku.edu.cn z{jiawei.jiang, ce.zhang}@inf.ethz.ch ∗[email protected] ^[email protected] System/Package Multi-obj. FIOC Constraint History Distributed ABSTRACT Hyperopt × X × × X Spearmint × × X × × Black-box optimization (BBO) has a broad range of applications, SMAC3 × X × × × including automatic machine learning, engineering, physics, and BoTorch X × X × × GPflowOpt X × X × × experimental design. However, it remains a challenge for users Vizier × X × 4 X to apply BBO methods to their problems at hand with existing HyperMapper XXX × × HpBandSter × X × × X software packages, in terms of applicability, performance, and ef- OpenBox XXXXX ficiency. In this paper, we build OpenBox, an open-source and general-purpose BBO service with improved usability. The modu- Table 1: A taxonomy of black-box optimization (BBO) sys- lar design behind OpenBox also facilitates flexible abstraction and tems/softwares. Multi-obj. notes whether the system sup- optimization of basic BBO components that are common in other ports multiple objectives or not. FIOC indicates if the sys- existing systems. OpenBox is distributed, fault-tolerant, and scal- tem supports all Float, Integer, Ordinal and Categorical vari- able. To improve efficiency, OpenBox further utilizes “algorithm ables. Constraint refers to the support for inequality con- agnostic” parallelization and transfer learning. -

Autoai for Time Series Forecasting
AutoAI-TS: AutoAI for Time Series Forecasting Syed Yousaf Shah, Dhaval Patel, Long Vu, Xuan-Hong Dang, Bei Chen, Peter Kirchner, Horst Samulowitz, David Wood, Gregory Bramble, Wesley M. Gifford, Giridhar Ganapavarapu, Roman Vaculin, and Petros Zerfos IBM Thomas J. Watson Research Center Yorktown Heights, NY [email protected],[email protected],[email protected],[email protected] [email protected],[email protected],[email protected],[email protected],[email protected] [email protected],[email protected],[email protected],[email protected] ABSTRACT 2021. AutoAI-TS: AutoAI for Time Series Forecasting. In Proceedings of A large number of time series forecasting models including tra- ACM Conference (Conference’17). ACM, New York, NY, USA, 13 pages. https: ditional statistical models, machine learning models and more re- //doi.org/10.1145/nnnnnnn.nnnnnnn cently deep learning have been proposed in the literature. However, choosing the right model along with good parameter values that 1 INTRODUCTION performs well on a given data is still challenging. Automatically The task of constructing and tuning machine learning pipelines providing a good set of models to users for a given dataset saves [7, 21, 37] for a given problem and data set is a complex, man- both time and effort from using trial-and-error approaches with a ual, and labor-intensive endeavor that requires a diverse team of wide variety of available models along with parameter optimiza- data scientists and domain knowledge (subject matter) experts. It tion. We present AutoAI for Time Series Forecasting (AutoAI-TS) that is an iterative process that involves design choices and fine tun- provides users with a zero configurationzero-conf ( ) system to effi- ing of various stages of data processing and modeling, including ciently train, optimize and choose best forecasting model among data cleansing, data imputation, feature extraction and engineering, various classes of models for the given dataset. -

Cvflow: Open Workflow for Computer Vision
CVFlow: Open Workflow for Computer Vision XIAOZHE YAO, Shenzhen University, China YINGYING CHEN, Shenzhen University, China JIA WU, Shenzhen University, China In recent years, the multimedia community has witnessed an emerging usage of deep learning in computer vision, such as image caption[11], object detection, instance segmentation and etc, and many companies are adopting deep learning into their commercial products. Developing and Deploying a fast and reliable deep learning system is complex and involves labour-intensive works, like image annotation[8], data and models versioning and etc. To facilitate such a process, we proposed CVFlow, which is a suite of versatile computer vision libraries and toolkits for handling computer vision tasks, including intelligent annotation toolkit, deep learning package manager, models sharing platform and computer vision serving program. CCS Concepts: • Software and its engineering → Software notations and tools. Additional Key Words and Phrases: Computer Vision, Package Manager, Deep Learning, Industrial Application 1 INTRODUCTION In the past few years, deep learning has played an important role in solving computer vision tasks, such as image caption, image generation, image classification and etc. Developing deep learning applications usually begins from collecting and annotating datasets, finding and optimizing neural networks to evaluating performance on test datasets, and deployments. There appeared many frameworks, such as Tensorflow[1], PyTorch[7], Chainer[10], MXNet[3] and etc. The growing development of frameworks and libraries has greatly reduced the effort of designing, implementing and evaluating neural networks. However, the bottleneck still exists in large-scale datasets annotation, model sharing and deployments. Creating and annotating large datasets is labour-intensive and involves significant time and costs[2], which makes it unaffordable for small companies. -

Trust in Automl: Exploring Information Needs for Establishing Trust in Automated Machine Learning Systems
Trust in AutoML: Exploring Information Needs for Establishing Trust in Automated Machine Learning Systems Jaimie Drozdal Justin Weisz Gaurav Dass Dakuo Wang Bingsheng Yao Michael Muller Changruo Zhao [email protected] [email protected] [email protected] [email protected] [email protected] [email protected] IBM Research [email protected] Rensselaer Polytechnic Institute Lin Ju Hui Su [email protected] [email protected] IBM IBM Research Rensselaer Polytechnic Institute ABSTRACT ACM Reference Format: We explore trust in a relatively new area of data science: Auto- Jaimie Drozdal, Gaurav Dass, Bingsheng Yao, Changruo Zhao, Justin Weisz, mated Machine Learning (AutoML). In AutoML, AI methods are Dakuo Wang, Michael Muller, Lin Ju, and Hui Su. 2020. Trust in AutoML: Exploring Information Needs for Establishing Trust in Automated Machine used to generate and optimize machine learning models by auto- Learning Systems. In 25th International Conference on Intelligent User Inter- matically engineering features, selecting models, and optimizing faces (IUI ’20), March 17–20, 2020, Cagliari, Italy. ACM, New York, NY, USA, hyperparameters. In this paper, we seek to understand what kinds of 11 pages. https://doi.org/10.1145/3377325.3377501 information influence data scientists’ trust in the models produced by AutoML? We operationalize trust as a willingness to deploy a model produced using automated methods. We report results from 1 INTRODUCTION three studies – qualitative interviews, a controlled experiment, and The practice of data science is rapidly becoming automated. New a card-sorting task – to understand the information needs of data techniques developed by the artificial intelligence and machine scientists for establishing trust in AutoML systems. -

Autoai: the Secret Sauce Jorge Castañón, Ph.D
AUTOAI: THE SECRET SAUCE JORGE CASTAÑÓN, PH.D. | LEAD DATA SCIENTIST @ IBM @DeveloperWeek @castanan #DEVWEEK2020 NOW: CLIENTS / PRODUCTS @ IBM DATA AND AI AUTOAI AutoAI is a new tool within IBM’s Watson Studio that utilizes sophisticated training features to automate many of the complicated and time consuming tasks of feature engineering and building machine learning models, without the need to be a pro at data science. $2,900,000,000,000 The business value generated by AI augmentation globally in 2021 6,200,000,000 hrs Worker hours saved by AI augmentation globally by 2021 How can we accelerate the path to AI? IBM Research IBM Research + Watson Studio AutoAI AutoAI automatically prepares data, applies algorithms, and builds model pipelines best suited for your data and use case. What used to take days or weeks, only takes minutes. What is behind AutoAI? Model Selection - Test estimators against small subsets of the data - Increase subset size gradually - Save time without loosing quality - Ranks estimators and selects the best “Selecting Near-Optimal Learners via Incremental Data Allocation”, AAAI Conference in AI, 2016 Why Feature Engineering? “Coming up with features is difficult, time-consuming, and requires expert knowledge. Applied machine learning is basically Feature Engineering.” -Andrew Ng “… some Machine Learning projects succeed and some fail. What makes the difference? Easily the most important factor is the features used.” -Pedro Domingos Auto Feature Engineering “Feature Engineering for Predictive Modeling Using Reinforcement Learning.”, AAAI Conference in AI, 2018 Hyperparameter Optimization - Refines best performing pipeline - Optimized for costly function evaluations - Enables fast convergence to a good solution “RBFOpt: an open-source library for black-box optimization with costly function evaluations.”, Mathematical Programming Computation, 2018. -

AI and Earth Observation: a Match Made in Heaven
AI and Earth Observation: A Match Made in Heaven Holger H. Hoos LIACS CS Department Universiteit Leiden University of British Columbia The Netherlands Canada EO3S Symposium The Hague (Netherlands) 2019/10/10 ∼ 1600 BC, Nebra Sky Disk ∼ 100 BC, Antikythera mechanism 24 October 1946, US-launched V2, 105km above ground 21 December 1968, Apollo 8 leaving Earth orbit 4 October 2019, Copernicus Sentinel-2 23 August 2019, Copernicus Sentinel-2 1 “AI is a critical new enabling technology “for Europes earth observation sector, “whose growth will be accelerated “by Europe strengthening its own AI capabilities.” – Josef Aschbacher, Director of Earth Observation, ESA Holger Hoos: AI and Earth Observation 8 AI for Earth Observation Holger Hoos: AI and Earth Observation 9 AI for Earth Observation image analysis, object recognition Holger Hoos: AI and Earth Observation 9 AI for Earth Observation image analysis, object recognition enhancing physical models for EO Holger Hoos: AI and Earth Observation 9 AI for Earth Observation image analysis, object recognition enhancing physical models for EO ... Holger Hoos: AI and Earth Observation 9 AI for Earth Observation image analysis, object recognition enhancing physical models for EO ... Holger Hoos: AI and Earth Observation 9 Interview with Turing Award Winner Yoshua Bengio (Nature, 4 April 2019) Q: What will be the next big thing in AI? Interview with Turing Award Winner Yoshua Bengio (Nature, 4 April 2019) Q: What will be the next big thing in AI? YB: Deep learning [...] has made huge progress in perception, but it hasn’t delivered yet on systems that can discover high-level representations [...] Interview with Turing Award Winner Yoshua Bengio (Nature, 4 April 2019) Q: What will be the next big thing in AI? YB: Deep learning [...] has made huge progress in perception, but it hasn’t delivered yet on systems that can discover high-level representations [...] Humansareabletousethosehigh-levelconcepts to generalize in powerful ways. -
Speed Time to Better AI Outco
Accelerate data Value propositions science and AI Automate AI Accelerate your path to an project delivery with AI-powered enterprise. ™ IBM Watson Studio Future proof AI investments Mix and match open source and Premium Add-on for IBM innovations. Avoid lock-in. Cloud Pak for Data Predict and optimize Optimize decisions with machine intelligence. Empower citizen data scientists Activate and reskill analytic experts to be AI-ready. IBM Watson Studio 2 50% By 2025, 50% of data scientist activities will be automated by artificial intelligence, easing the acute talent shortage.¹ To drive desired AI outcomes you need to inject predictive IBM Watson Studio insights into business processes by harnessing the power Premium Add-on for of prediction and optimization. This requires organizations to: Cloud Pak for Data – Accelerate data science projects by automating the data science lifecycle. – Deploy enterprise AI virtually anywhere, on the clouds Build and scale AI with trust and transparency. of your choice. Artificial intelligence (AI) is transforming businesses – Unify AI across private, hybrid and multicloud everywhere. A sound AI strategy is built on environments landscapes. and tools that make analyzing data and building AI – Simplify data science tasks with the broader models easier and more accessible. For AI to thrive, it’s ecosystems of data they rely on. imperative that your team can quickly get onboard, scale – Tap into the open innovation of IBM® Cloud™ Paks and and automate AI across multiple clouds. OpenShift. According to the IBM Research estimate, optimizing an AI model pipeline is traditionally highly iterative. The pipeline is often optimized for one objective and constraint at a time, which may have a severe impact on quality. -
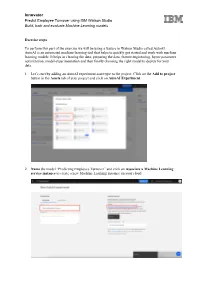
Innovator Predict Employee Turnover Using IBM Watson Studio Build, Train and Evaluate Machine Learning Models
Innovator Predict Employee Turnover using IBM Watson Studio Build, train and evaluate Machine Learning models Exercise steps To perform this part of the exercise we will be using a feature in Watson Studio called AutoAI. AutoAI is an automated machine learning tool that helps to quickly get started and work with machine learning models. It helps in cleaning the data, preparing the data, feature engineering, hyper parameter optimization, model experimentation and then finally choosing the right model to deploy for your data. 1. Let’s start by adding an AutoAI experiment asset type to the project. Click on the Add to project button in the Assets tab of your project and click on AutoAI Experiment. 2. Name the model “Predicting Employee Turnover” and click on Associate a Machine Learning service instance to create a new Machine Learning instance on your cloud. Innovator Predict Employee Turnover using IBM Watson Studio Build, train and evaluate Machine Learning models 3. A new tab will open with the details of the Machine Learning instance. Make sure you’re creating a New Machine Learning instance (if you have already created a Machine learning service before switch to the Existing tab and select your service instead). 4. Again, make sure that the lite plan is selected. Innovator Predict Employee Turnover using IBM Watson Studio Build, train and evaluate Machine Learning models 5. Leave everything as default, scroll down to the bottom and create the Machine Learning instance. 6. Confirm the creation of the instance. Innovator Predict Employee Turnover using IBM Watson Studio Build, train and evaluate Machine Learning models 7. -

Prediction One, Sony Network Communications Inc., Tokyo, Japan) for Subarachnoid Hemorrhage Outcomes Treated by Coiling and Delayed Cerebral Ischemia
Open Access Original Article DOI: 10.7759/cureus.15695 Easily Created Prediction Model Using Automated Artificial Intelligence Framework (Prediction One, Sony Network Communications Inc., Tokyo, Japan) for Subarachnoid Hemorrhage Outcomes Treated by Coiling and Delayed Cerebral Ischemia Masahito Katsuki 1, 2 , Shin Kawamura 2 , Akihito Koh 2 1. Department of Neurosurgery, Iwaki City Medical Center, Iwaki, JPN 2. Department of Neurosurgery, Itoigawa General Hospital, Itoigawa, JPN Corresponding author: Masahito Katsuki, [email protected] Abstract Introduction Reliable prediction models of subarachnoid hemorrhage (SAH) outcomes and delayed cerebral ischemia (DCI) are needed to decide the treatment strategy. Automated artificial intelligence (AutoAI) is attractive, but there are few reports on AutoAI-based models for SAH functional outcomes and DCI. We herein made models using an AutoAI framework, Prediction One (Sony Network Communications Inc., Tokyo, Japan), and compared it to other previous statistical prediction scores. Methods We used an open dataset of 298 SAH patients, who were with non-severe neurological grade and treated by coiling. Modified Rankin Scale 0-3 at six months was defined as a favorable functional outcome and DCI occurrence as another outcome. We randomly divided them into a 248-patient training dataset and a 50- patient test dataset. Prediction One made the model using training dataset with 5-fold cross-validation. We evaluated the model using the test dataset and compared the area under the curves (AUCs) of the created models. Those of the modified SAFIRE score and the Fisher computed tomography (CT) scale to predict the outcomes. Results The AUCs of the AutoAI-based models for functional outcome in the training and test dataset were 0.994 and 0.801, and those for the DCI occurrence were 0.969 and 0.650.