Ticket Data Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Et Eksempel På Havplanlægning På Tværs Af Kommunegrænser I Blekinge
Inter-municipal MSP Case study Blekinge Seaplanspace seminar Aalborg University, 20 February 2020 Henrik Nilsson –World Maritme University The role of municipalities in MSP u 82 coastal municipalities in Sweden u Municipalities responsible for spatial planning on land and sea areas within their boundaries u Municipal border extends to outer limit of territorial sea. u Comprehensive plans – guiding plans Marine Spatial Plan Blekinge Inter-municipal plan between 4 municipalities: • Sölvesborg • Karlshamn • Ronneby • Karlskrona • Starts at 300m from baseline – outer border of TS • Guiding plan • Adopted in autumn 2019 Development process u 2014 - Initiative taken by County Administrative Board and Blekinge Archipelago Biosphere Reserve u 2015 – Municipal inventory of data and knowledge needed for development of MSP. u 2016/2017 – Funding from Swam to continue inventory and development of plan. u Set-up of organisational structure u Working group with representatives from each municipality (planners) u Steering group at each municipality (planners, environmental strategist, port representatives etc) Stakeholder consultations 2017 u Thematic consultations: 1. Fisheries,aquaculture,energy 2. Shipping,infrastructure and extraction of natural resources 3. Nature protection, leisure and tourism 4. Defense, climate, cultural heritage Interest matrix Compatible use Limited risk of conflct Risk of conflict Clear risk of conflict Interactive GiS map • Fisheries • Aquaculture • Shipping • Defense • Nature • Energy • Infrastructure • Exploitation of natural resources • Recreation • Culture Key benefits of cooperation in inter- municipal MSP planning u Shared knowledge and competences u Ecological considerations are done from a more holistic perspective u Interest conflicts and subsequent solutions are easier to identify u Common knowledge gaps are identified as well as needs for additional competences Thank you!. -

Development in Coastal Areas in Ronneby Kommun from 1960 to 2018
Master of Science in Spatial Planning May 2019 Development in Coastal Areas in Ronneby Kommun from 1960 to 2018 GIS-Based Analysis of LIS Areas in Ronneby Kommun (Blekinge, Sweden) Using Orthophotos Maximilian Martin Weidenhiller Faculty of Engineering, Blekinge Institute of Technology, 371 79 Karlskrona, Sweden This thesis is submitted to the Faculty of Engineering at Blekinge Institute of Technology in partial fulfilment of the requirements for the degree of Master of Science in Spatial Planning. The thesis is equivalent to 10 weeks of full-time studies. The author declares that he is the sole author of this thesis and that he has not used any sources other than those listed in the bibliography and identified as references. He further declares that he has not submitted this thesis to any other institution to obtain a degree. Contact Information: Author: Maximilian Martin Weidenhiller E-Mail: [email protected] University advisor: Advisor Ronneby Kommun: Peter Schlyter Peter Robertsson Department Spatial Planning Planarkitekt Faculty of Engineering Internet : www.bth.se Blekinge Institute of Technology Phone : +46 455 38 50 00 SE-371 79 Karlskrona, Sweden Fax : +46 455 38 50 57 II ABSTRACT Since 2009, Swedish municipalities have the possibility of limiting the coastal protection in rural areas with the LIS-tool in order to promote countryside development there. In 2013, Ronneby Kommun pointed out 28 such areas. The goal of this thesis is to describe the development in the coastal areas in Ronneby Kommun between 1960 and 2018, with a special focus on the recent development in the designated LIS areas since 2013. -

Welcome to Tingsryd Municipality!
Welcome to Tingsryd Municipality! Välkommen! Welcome! !بيحرت soo dhawow! khosh maden! Contents Tingsryd municipality p. 1 Citizens’ advice bureau p. 1 Meeting places p. 2 Schools and childcare p. 3 Finances p. 4 Healthcare p. 5 Housing p. 6 Societies, clubs and activities p. 7 Authorities p. 8-9 Good to know p. 10 Contact p. 11-12 Tingsryd Municipality About our municipality Tingsryd is a vibrant, attractive and care for children and the and modern rural municipality, elderly. The district is character- in the midst of a strong region of ized by a small-scale agricultural growth. Here we have engaged landscape with over 200 lakes. citizens, active industry, rich societal life and ample opportu- Within an hour’s radius of nities for human interactions. Tingsryd municipality is home to nearly 300,000 people and within More than a third of the popu- two hours is one of Europe’s lation of Tingsryd live in rural regions of growth: Malmö / areas. In each of the seven lo- Copenhagen. Also nearby are calities of Konga, Linneryd, Ryd, Linnaeus University in Växjö, Rävemåla, Tingsryd, Urshult and and Blekinge Institute of Väckelsång are found basic serv- Technology, and The University ices including schools, businesses of Karlskrona and Karlshamn. Citizens’ advice bureau If you have questions about school, accommodation, or need help filling in forms we can help you! At the Citizens’ Advice Bureau in Tingsryd municipality (Torggatan 12) you can get help with most things, and find out where to turn should we be unable to help. Please call 0477 441 00 The Citizens’ Advice Bureau opening hours: Mon 08:00 to 18:00 Tue-Fri 8:00 to 16:30 Open at lunchtime every day 1 Tingsryd Municipality Meeting places There are different kinds of meet- retired, youth or immigrant, or You can also register your interest ing places in Tingsryd whose goal have lived a long time in Sweden. -

FÖRSKÖNING Medel Till Förskönande Genom Nya Objekt, Förbättringar Och Underhåll På Landsbygden I Ronneby Kommun
FÖRSKÖNING Medel till förskönande genom nya objekt, förbättringar och underhåll på landsbygden i Ronneby kommun Så här har försköningspengarna använts hittills INNEHÅLL Del 1. Försköningspengarna - Allmän del 6. Historiken FÖRSKÖNINGSPENGARNA 7. Hur har det blivit? 8. Några exempel på större, mer samlade satsningar 14. Målbilder - grundläggande principer och typer av objekt 23. Om bygdekänslan, platserna, de sammanhängande stråken Allmän del 30. I verkstan, om tillverkningen och uppväxlingen 37. Några sammanfattande kommentarer 38. Delar som bör kunna förbättras framöver Del 2. Försköningspengarna - Exempelsamling från samhälle till samhälle 44. Backaryd 46. Belganet 48. Blekingepärlor 50. Bräknebygden Bräkne-Hoby med omland 52. Bräknebygden Järnaviksskärgården 54. Eringsboda 56. Hallabro 58. Johannishus 60. Kuggebodalandet 62. Listerby 64. Möljeryd - Karlsnäs 66. Saxemara 68. Tjurkhult 70. Öljehult Skriften FÖRSKÖNING är utgiven av Försköningsrådet i Ronneby kommun och Ronneby Kommunbygderåd. Ansvarig för innehållet i den Allmänna delen och för flera delar även gällande Exempelsamlingen är Roland Gustavsson. Layout och originalproduktion Ingegerd Linden. Tryck Copy Graf, Bräkne-Hoby. Många har bidragit med foton. För andra delen ombads samhällsföreningar mm att komma in med bilder som sammanfattade arbetet med försköningsmedlen för deras by. För att understryka det viktiga tillverkandet så ville vi få exempel på själva arbetet som del. Vi ville även få bilder över hela året då vi vill stimulera att användandet inte bara sker över en kort sommarperiod utan mest möjligt över hela året! Utanför dessa så har det största antalet foton, mer än åttio, ta- gits av Roland Gustavsson. Andra som bidragit är Bo Svensson, Saxemara, Ola Johansson, Eringsboda, Sven Strandberg, Hallabro, Stefan Rehberg, Bräkne- Hoby, Maria Dehlsen, Belganet samt Ingegerd Linden, Bräkne-Hoby. -

Riksintressen För Kulturmiljövården – Blekinge Län (K)
Riksintressen för kulturmiljövården – Blekinge län (K) Denna publikation ingår i en serie med de olika riksintressena som finns på webbplatsen: www.raa.se K län beslut RAÄ 1996-08-27. Beslut text (K2) 2015-06-16. Beslut text (K6) 2015-11-17. Beslut text (K16), (K17) 2016-03-23. Dokument uppdaterat 2016-03-23. Områden av riksintresse för kulturmiljövården i Blekinge län (K) enligt 3 kap 6 § miljöbalken KARLSHAMNS KOMMUN ________________________________________________________3 Djurtorp [K 8] (Åryds sn) _________________________________________________________________ 3 Elleholm [K 4] (Elleholms sn) _____________________________________________________________ 3 Ire [K 7] (Ringamåla sn) _________________________________________________________________ 3 Karlshamn [K 6] ________________________________________________________________________ 3 Letesmåla [K 3] (Ringamåla sn) ____________________________________________________________ 4 Mörrum [K 5] (Mörrums sn) ______________________________________________________________ 4 KARLSKRONA KOMMUN ________________________________________________________4 Brömsebro [K 21] (Kristianopels sn) ________________________________________________________ 4 Hallarumsviken [K 20] (Jämjö sn) __________________________________________________________ 5 Herrgården, Tjurkö stenhuggeri [K 16] (Karlskrona sn) _________________________________________ 5 Karlskrona [K 15] _______________________________________________________________________ 5 Kristianopel [K 22] ______________________________________________________________________ -

3G As a Sustainability Issue in Swedish Spatial Planning
BETWEEN DARING AND DELIBERATING BETWEEN DARING ABSTRACT The thesis shows how different aspects of sus- Environmental aspects were not handled at natio- tainable development have been handled or not nal level but assessed locally in the building permit BETWEEN DARING AND DELIBERATING handled in the third generation infrastructure handling, as well as the regional 12:6 consultations development in Sweden. The difference between at the County Administrations. This is why the 3G AS A SUSTAINABILITY ISSUE IN SWEDISH SPATIAL PLANNING the design of the 3G development - emphazising municipal permit process holds many of the keys competition, growth and regional access, based on regarding environmental management and plan- a strong technological optimism - and the imple- ning. Therefore the permit processes regarding 3G mentation, as the roll out struck the landscape, masts has been charted as they developed in time including the non-handled radiation issue and the and screened for main issues and conflicts. Public legal changes in order to facilitate the roll out, is participation can be found in the local context tied discussed and analyzed. to the legal concept of being a concerned party in the permit process, or the 12:6 consultation. The roll out formally started in late 2000 as the li- In spite of this, the much debated radiation issue cence allocation process, the so called beauty con- is lifted from the participative aspects and legally Stefan Larsson test, was finished. Four operators were to build defined as not relevant. partly competing systems within three years, each covering 8 860 000 persons, more than 99,98 The theoretical basis of the analysis combines percent of the populated areas. -

Kingdom of Sweden
Johan Maltesson A Visitor´s Factbook on the KINGDOM OF SWEDEN © Johan Maltesson Johan Maltesson A Visitor’s Factbook to the Kingdom of Sweden Helsingborg, Sweden 2017 Preface This little publication is a condensed facts guide to Sweden, foremost intended for visitors to Sweden, as well as for persons who are merely interested in learning more about this fascinating, multifacetted and sadly all too unknown country. This book’s main focus is thus on things that might interest a visitor. Included are: Basic facts about Sweden Society and politics Culture, sports and religion Languages Science and education Media Transportation Nature and geography, including an extensive taxonomic list of Swedish terrestrial vertebrate animals An overview of Sweden’s history Lists of Swedish monarchs, prime ministers and persons of interest The most common Swedish given names and surnames A small dictionary of common words and phrases, including a small pronounciation guide Brief individual overviews of all of the 21 administrative counties of Sweden … and more... Wishing You a pleasant journey! Some notes... National and county population numbers are as of December 31 2016. Political parties and government are as of April 2017. New elections are to be held in September 2018. City population number are as of December 31 2015, and denotes contiguous urban areas – without regard to administra- tive division. Sports teams listed are those participating in the highest league of their respective sport – for soccer as of the 2017 season and for ice hockey and handball as of the 2016-2017 season. The ”most common names” listed are as of December 31 2016. -
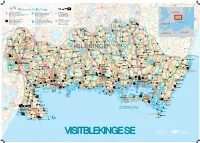
Visit Blekinge Karta
Påryd 126 Rävemåla 28 Törn Flaken Welcome to Blekinge 120 ARK56 Nav - Ledknutpunkt ARK56 Kajakled Blekingeleden Häradsbäck 120 Markerad vandringsled Sandsjön SWEDEN ARK56 Hub - Trail intersection120 Rekommenderad led för paddling Urshult Tingsryd Kvesen Vissefjärda ARK56 Knotenpunkt diverser Wege und Routen Recommended trail for kayaking Waymarked hiking trail ARK56 Węzeł - punkt zbiegu szlaków Empfohlener Paddel - Pfad Markierter Wanderweg 122 www.ark56.se Zalecana trasa kajakowa Oznakowany szlak pieszy Tiken 27 Dångebo Campingplatser - Camping Sydost RammsjönSkärgårdstrafik finns i området Sydostleden Arasjön Campsites - Camping Sydost Passenger boat services available Rekommenderad cykelled Stora Kinnen Halltorp Campingplatz - Camping Sydost Skärgårdstrafik - Passagierschiffsverkehr Recommended cycle trail Hensjön Ulvsmåla Älmtamåla Kemping - Camping Sydost Obszar publicznego transportu wodnego Empfohlener Radweg Baltic Sea www.campingsydost.se www.skargardstrafiken.com Zalecany szlak rowerowy 119 Ryd Djuramåla Saleboda DENMARKGullabo Buskahult Skumpamåla Spetsamåla Söderåkra Lyckebyån Siggamåla Åbyholm Farabol 119 Eringsboda Alvarsmåla Tjurkhult Göljahult Kolshult Falsehult POLAND130 126 GERMANY Mien Öljehult Husgöl Torsåsån Värmanshult Hjorthålan Holmsjö Fridafors R o Leryd Sillhöv- Kåraboda Björkebråten n Ledja n Boasjö 27 e dingen Torsås b y Skälmershult Björkefall å n Ärkilsmåla Dalanshult Hallabro Brännare- Belganet Hjortseryd Långsjöryd Klåvben St.Skälen Gnetteryd bygden Väghult Ebbamåla Alljungen Brunsmo Bruk St.Alljungen Mörrumsån -

LAG – Sydostleader ‐ Sweden
LAG – SydostLeader ‐ Sweden Author: Joel Parde, President of SydostLeader A. Summary table LAG name SydostLeader Lead partner LAG director Storgatan 4, SE‐361 30 Emmaboda, Sweden Joel Parde, LAG President Main European Part of another LAG financial Structural and territorial delivery structure Investment Fund mechanisms Integrated Territorial Multi‐fund EAFRD Investment (ITI) Programme Thematic Financial allocation Priority axes objective(s) CCI number (EUR) concerned concerned European Regional Development Fund (ERDF) Programme 2014SE16M2OP001 537.213 ‐ 9d European Social Fund (ESF) Programme 2014SE16M2OP001 453.142 ‐ 9vi European agricultural fund for rural development (EAFRD) 2014SE06RDNP001 5.287.288 European maritime and fisheries fund (EMFF) 995.275+95.458 Programme 2014SE14MFOP001 (Kalmar & Öland) LAG Strategy LAG Specific territorial Implementation Population covered by Specific thematic focus and focus of the Specific social target Current situation the strategy challenges of the strategy strategy of the strategy (June 2017): . Tackling social Mainly focused on exclusion and . Economic development rural development unemployment Projects under 217 517 . Access to services /Rural areas . Youth initiatives implementation 1 B. Strategy B.1. Area of the CLLD a. Area and population covered by the strategy (See map and figures in B.2.d) The Local development area of – SydostLeader – has a differentiated and varied landscape, from coast and sea to inland with forests and lakes. It extends over eleven municipalities: Emmaboda, Karlshamn, Karlskrona, Lessebo, Nybro, Olofström, Ronneby, Sölvesborg, Tingsryds, Torsås samt Uppvidinge municipality. Thereby the local development area extends over three counties in southeast Sweden: Blekinge, Kalmar and Kronoberg County. An important common feature of the area is the water. The sea, the coast area, rivers and lakes of the districts are part of a unique development area. -

Sammanställning Över Allmänna Vägar I Blekinge Län 2018 I Denna Sammanställning Redovisas Sida
Sammanställning över allmänna vägar i Blekinge län 2018 I denna sammanställning redovisas sida I. Allmänna föreskrifter och upplysningar. 4 II. Sammanställning över allmänna vägar och andra viktigare vägar med bärighetsklasser samt vissa för vägarna gällande lokala trafikföreskrifter 8 III. Förteckning över ej numrerade kommunala gator och vägar som är upplåtna för bärighetsklass 1. 24 IV. Lämpliga leder och gällande inskränkningar för tunga lastbilar och andra större fordon inom vissa tätorter. 25 Bilageförteckning A. Tabell Högsta tillåtna bruttovikter vid bärighetsklass 1 (BK1). 28 B. Tabell Högsta tillåtna bruttovikter vid bärighetsklass 2 (BK2). 30 C. Tabell Högsta tillåtna bruttovikter vid bärighetsklass 3 (BK3). 31 D. Tabell Högsta tillåtna bruttovikter vid bärighetsklass 4 (BK4). 32 E. Kartor Olofström, Sölvesborg, Karlshamn, Ronneby och Karlskrona. lämpliga leder för transport av farligt gods. 33 Turlista: Aspöfärjan 38 Öppetider: Hasslöbron 40 Telefonlista: Länsstyrelsen, Trafikverket, länets kommuner och polisen 41 Blekinge läns författningssamling Länsstyrelsen Länsstyrelsens sammanställning över allmänna 10 FS 2018:8 vägar och andra viktiga vägar i Blekinge län Utkom den 27 med vissa lokala trafikföreskrifter och före- mars 2018 skrifter om bärighetsklasser; I enlighet med 13 kap. 1 § trafikförordningen (1998:1276) har Länssty- relsen upprättat sammanställning över allmänna vägar och andra viktiga vägar i länet. Med stöd av 4 kap. 11 § trafikförordningen har Trafikverket beslutat om bärighetsklasser för allmänna vägar på sätt som framgår av nedan angivna förteckningar. Sammanställningen gäller från den 1 april 2018. Samtidigt upphävs ’Sammanställning över allmänna vägar år 2017 i Blekinge län’, 10 FS 2017:11 4 I. ALLMÄNNA FÖRESKRIFTER OCH UPPLYSNINGAR Axel/boggitryck och bruttovikt Enligt 4 kap §§ 11-14 TrF gäller följande: 11 § Vägar som inte är enskilda delas in i fyra bärighetsklasser. -

Blekinge Archipelago Biosphere Reserve – a Sea of Opportunities!
Welcome to Blekinge Archipelago Biosphere Reserve – a sea of opportunities! www.blekingearkipelag.se Blekinge Archipelago Biosphere Reserve Heleen Podsedkowska Simone Wenzel 24 May 2017, Ronneby, Sweden www.blekingearkipelag.se Agenda • Blekinge Archipelago BR, who we are and what we do • Archipelago Route www.blekingearkipelag.se World network • Unesco • Today 669 BR´s in 120 countries www.blekingearkipelag.se Biosphere reserves in Sweden • Kristianstads Vattenrike • Vänerskärgården med Kinnekulle • Älvlandskapet Nedre Dalälven • Blekinge Arkipelag • Östra Vätterbranterna Candidates: • Vindelälven-Juhtatdahka • Voxnadalen www.blekingearkipelag.se 5+2+? www.blekingearkipelag.se We are all part of the biosphere! www.blekingearkipelag.se Žuvintas www.blekingearkipelag.se Słowiński Blekinge Archipelago BR is an NGO www.blekingearkipelag.se Some data • Area: 210 000 ha, 156 000 ha water, 54 000 ha terrestrial • 1 culture reserve, i.e. Ronneby Brunnspark • More than 37 nature reserves • 72 Natura 2000-areas (EU) • 85 000 inhabitants, about 4 000 living on islands of which some have land connection • Blekinge Institute of Technology – Master of Strategic Leadership towards Sustainability-programme www.blekingearkipelag.se Vision Blekinge Archipelago - a sea of possibilities! Blekinge Archipelago represents a flourishing coastal area and archipelago where development occurs in harmony between entrepreneurship and ecology. Its foundation is local engagement and concern for the future of next generations. www.blekingearkipelag.se What makes Blekinge -

Namnbanken-1.Pdf
Namnbanken Senaste insättningarna *) 27 juni 2017 Namn Kön Ort Källa Namngivare A Abigail k Torhamn Fb 1724 Paul Nilsson, Lessebo Achatius m Karlshamn Hfl 1836-1841 Tore Andersson, Olofström Afwert m Bräkne-Hoby Jordrevning, 1671 Per Frödholm, Asarum Agda k Fridlevstad, Förkärla, Hjortsberga Fb 1749, 1819, 1777 Annika Otfors, Bräkne-Hoby Agda k Listerby, Nättraby Fb 1721, 1748 Annika Otfors, Bräkne-Hoby Aigda k Åryd Jordrevning 1671 Per Frödholm, Asarum Ajda k Ysane Fb 1700-tal Håkan Elmquist, Järfälla Akalia k Bräkne-Hoby Fb 1907 Anne-Marie Mattiasson, Rödeby Albrekt m Backaryd Fb 1758 Roger Rydberg, Konga Alritz m Ronneby Fb 1904 Kent Alritzson, Karlskrona Altin m Sandhamn, Torhamn Fb 1894 Jan Jutefors, Rockneby Ambrus m Listerby Fb 1771 Annika Otfors, Bräkne-Hoby Aminoff m Ysane Fb 1917 Göran Olausson, Olofström Amme m Ysane Db 1729 Håkan Elmquist, Järfälla Amon m Hällaryd Mtl 1770 Björn-Åke Petersson, Kallinge Amund m Backaryd Fb 1747 Roger Rydberg, Konga Amund m Förkärla 1770-talet Inga-Greta Sonesson, Västerås Amund m Ronneby Fb 1712 Roger Rydberg, Konga Anel m Backaryd Fb 1744 Roger Rydberg, Konga Anholt m Asarum Jordrevning 1671 Per Frödholm, Asarum Annert m Asarum Katekis 1686 Per Frödholm, Asarum Annika k Augerum, Hjortsberga, Förkärla Fb 1784, 1729, 1762 Annika Otfors, Bräkne-Hoby Annild m Jämjö Fb 1715 Suzanne Wernersson, Fridlevstad Anol m Hällaryd, Ramdala, Sturkö, Torhamn Mtl 1770 Björn-Åke Petersson, Kallinge Anol m Augerum Mtl 1770 Björn-Åke Petersson, Kallinge Ansgarius m Tjurkö Fb 1901 Lotta Malmstedt, Karlshamn Antimus