Openquake Manual 2.7.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

009NAG – September 2012
SOUTH AFRICA’S LEADING GAMING, COMPUTER & TECHNOLOGY MAGAZINE VOL 15 ISSUE 6 BORDERLANDS 2 COMPETITION Stuff you can’t buy anywhere! PC / PLAYSTATION / XBOX / NINTENDO PREVIEWS Sleeping Dogs Beyond: Two Souls Pikmin 3 Injustice: Gods among Us ENEMY UNKNOWN Is that a plasma rifl e in your pocket, or are you just happy to see me? ULTIMATE GAMING LOUNGE What your lounge should look like Contents Editor Michael “RedTide“ James Regulars [email protected] 10 Ed’s Note Assistant editor 12 Inbox Geoff “GeometriX“ Burrows 16 Bytes Staff writer Dane “Barkskin “ Remendes Opinion 16 I, Gamer Contributing editor Lauren “Guardi3n “ Das Neves 18 The Game Stalkerer 20 The Indie Investigatorgator Technical writer 22 Miktar’s Meanderingsrings Neo “ShockG“ Sibeko 83 Hardwired 98 Game Over Features International correspondent Miktar “Miktar” Dracon 30 TOPTOP 8 HOLYHOLY SH*TSH*T MOMENTS IN GAMING Contributors Previews Throughout gaming’s relatively short history, we’ve Rodain “Nandrew” Joubert 44 Sleeping Dogs been treated to a number of moments that very nearly Walt “Ramjet” Pretorius 46 Injustice: Gods Among Us made our minds explode out the back of our heads. Miklós “Mikit0707 “ Szecsei Find out what those are. Pippa “UnexpectedGirl” Tshabalala 48 Beyond: Two Souls Tarryn “Azimuth “ Van Der Byl 50 Pikmin 3 Adam “Madman” Liebman 52 The Cave 32 THE ULTIMATE GAMING LOUNGE Tired of your boring, traditional lounge fi lled with Art director boring, traditional lounge stuff ? Then read this! Chris “SAVAGE“ Savides Reviews Photography 60 Reviews: Introduction 36 READER U Chris “SAVAGE“ Savides The results of our recent reader survey have been 61 Short Reviews: Dreamstime.com tallied and weighed by humans better at mathematics Fotolia.com Death Rally / Deadlight and number-y stuff than we pretend to be! We’d like 62 The Secret World to share some of the less top-secret results with you. -

Slang: Language Mechanisms for Extensible Real-Time Shading Systems
Slang: language mechanisms for extensible real-time shading systems YONG HE, Carnegie Mellon University KAYVON FATAHALIAN, Stanford University TIM FOLEY, NVIDIA Designers of real-time rendering engines must balance the conicting goals and GPU eciently, and minimizing CPU overhead using the new of maintaining clear, extensible shading systems and achieving high render- parameter binding model oered by the modern Direct3D 12 and ing performance. In response, engine architects have established eective de- Vulkan graphics APIs. sign patterns for authoring shading systems, and developed engine-specic To help navigate the tension between performance and maintain- code synthesis tools, ranging from preprocessor hacking to domain-specic able/extensible code, engine architects have established eective shading languages, to productively implement these patterns. The problem is design patterns for authoring shading systems, and developed code that proprietary tools add signicant complexity to modern engines, lack ad- vanced language features, and create additional challenges for learning and synthesis tools, ranging from preprocessor hacking, to metapro- adoption. We argue that the advantages of engine-specic code generation gramming, to engine-proprietary domain-specic languages (DSLs) tools can be achieved using the underlying GPU shading language directly, [Tatarchuk and Tchou 2017], for implementing these patterns. For provided the shading language is extended with a small number of best- example, the idea of shader components [He et al. 2017] was recently practice principles from modern, well-established programming languages. presented as a pattern for achieving both high rendering perfor- We identify that adding generics with interface constraints, associated types, mance and maintainable code structure when specializing shader and interface/structure extensions to existing C-like GPU shading languages code to coarse-grained features such as a surface material pattern or enables real-time renderer developers to build shading systems that are a tessellation eect. -

Create an Endless Running Game in Unity
Zhang Yancan Create an Endless Running Game in Unity Bachelor’s Thesis Information Technology May 2016 DESCRIPTION Date of the bachelor's thesis 2/Dec/2016 Author(s) Degree programme and option Zhang Yancan Information Technology Name of the bachelor's thesis Create an Endless Running Game in Unity The fundamental purpose of the study is to explore how to create a game with Unity3D game engine. Another aim is to get familiar with the basic processes of making a game. By the end of the study, all the research objectives were achieved. In this study, the researcher firstly studied the theoretical frameworks of game engine and mainly focused on the Unity3D game engine. Then the theoretical knowledge was applied into practice. The project conducted during the research is to generate an endless running game, which allows the players getting points by keep moving on the ground and colleting coins that appeared during the game. In addition, the players need to dodge the enemies and pay attention to the gaps emerged on the ground. The outcomes of the study have accomplished the research purposes. The game created is able to function well during the gameplay as the researcher expected. All functions have displayed in game. Subject headings, (keywords) Unity3D, Endless running game, C# Pages Language URN 34 English Remarks, notes on appendices Tutor Bachelor’s thesis assigned by Mikkeli University of Applied Sciences (change Reijo Vuohelainen to a company name, if applicable) CONTENTS 1 INTRODUCTION................................................................................................ 1 2 THEORETICAL OF BACKGROUND GAME DESIGN .................................. 2 2.1 Game strategy design .................................................................................. 2 2.2 Game balance ............................................................................................. -

Experiments on Flow and Learning in Games : Creating Services to Support Efficient Serious Games Development
Experiments on flow and learning in games : creating services to support efficient serious games development Citation for published version (APA): Pranantha Dolar, D. (2015). Experiments on flow and learning in games : creating services to support efficient serious games development. Technische Universiteit Eindhoven. https://doi.org/10.6100/IR783192 DOI: 10.6100/IR783192 Document status and date: Published: 01/01/2015 Document Version: Publisher’s PDF, also known as Version of Record (includes final page, issue and volume numbers) Please check the document version of this publication: • A submitted manuscript is the version of the article upon submission and before peer-review. There can be important differences between the submitted version and the official published version of record. People interested in the research are advised to contact the author for the final version of the publication, or visit the DOI to the publisher's website. • The final author version and the galley proof are versions of the publication after peer review. • The final published version features the final layout of the paper including the volume, issue and page numbers. Link to publication General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal. -

Game Engines
Game Engines Martin Samuelčík VIS GRAVIS, s.r.o. [email protected] http://www.sccg.sk/~samuelcik Game Engine • Software framework (set of tools, API) • Creation of video games, interactive presentations, simulations, … (2D, 3D) • Combining assets (models, sprites, textures, sounds, …) and programs, scripts • Rapid-development tools (IDE, editors) vs coding everything • Deployment on many platforms – Win, Linux, Mac, Android, iOS, Web, Playstation, XBOX, … Game Engines 2 Martin Samuelčík Game Engine Assets Modeling, scripting, compiling Running compiled assets + scripts + engine Game Engines 3 Martin Samuelčík Game Engine • Rendering engine • Scripting engine • User input engine • Audio engine • Networking engine • AI engine • Scene engine Game Engines 4 Martin Samuelčík Rendering Engine • Creating final picture on screen • Many methods: rasterization, ray-tracing,.. • For interactive application, rendering of one picture < 33ms = 30 FPS • Usually based on low level APIs – GDI, SDL, OpenGL, DirectX, … • Accelerated using hardware • Graphics User Interface, HUD Game Engines 5 Martin Samuelčík Scripting Engine • Adding logic to objects in scene • Controlling animations, behaviors, artificial intelligence, state changes, graphics effects, GUI, audio execution, … • Languages: C, C++, C#, Java, JavaScript, Python, Lua, … • Central control of script executions – game consoles Game Engines 6 Martin Samuelčík User input Engine • Detecting input from devices • Detecting actions or gestures • Mouse, keyboard, multitouch display, gamepads, Kinect -

Final Listing Support Document
United States Environmental Protection Agency 1200 Pennsylvania Avenue, N.W. March Washington, D.C. 20460 2011 Office of Solid Waste and Emergency Response Support Document for the Revised National Priorities List Final Rule – ACM Smelter & Refinery Support Document for the Revised National Priorities List Final Rule ACM Smelter and Refinery March 2011 Site Assessment and Remedy Decisions Branch Office of Superfund Remediation and Technology Innovation Office of Solid Waste and Emergency Response U.S. Environmental Protection Agency Washington, DC 20460 Table of Contents Executive Summary ....................................................................................................................................v Introduction................................................................................................................................................vi Background of the NPL.........................................................................................................................vi Development of the NPL.......................................................................................................................vii Hazard Ranking System.......................................................................................................................vii Other Mechanisms for Listing ............................................................................................................viii Organization of this Document.............................................................................................................ix -

Attorney/Correspondence Information
Trademark Trial and Appeal Board Electronic Filing System. http://estta.uspto.gov ESTTA Tracking number: ESTTA888551 Filing date: 04/09/2018 IN THE UNITED STATES PATENT AND TRADEMARK OFFICE BEFORE THE TRADEMARK TRIAL AND APPEAL BOARD Notice of Opposition Notice is hereby given that the following party opposes registration of the indicated application. Opposer Information Name Valve Corporation Granted to Date 04/08/2018 of previous ex- tension Address 10400 NE 4th Street, Suite 1400 Bellevue, WA 98004 UNITED STATES Attorney informa- David J. Byer tion K&L Gates LLP One Lincoln Street Boston, MA 02111 UNITED STATES Email: [email protected], [email protected], [email protected], [email protected] Applicant Information Application No 87446265 Publication date 10/10/2017 Opposition Filing 04/09/2018 Opposition Peri- 04/08/2018 Date od Ends Applicant Source Films, LLC #1323 668 N Coast Highway Laguna Beach, CA 92651 UNITED STATES Goods/Services Affected by Opposition Class 041. First Use: 2017/04/10 First Use In Commerce: 2017/04/10 All goods and services in the class are opposed, namely: Entertainment services, namely, storytelling; Multimedia entertainment softwareproduction services; Production and distribution of television shows and movies Grounds for Opposition Priority and likelihood of confusion Trademark Act Section 2(d) Marks Cited by Opposer as Basis for Opposition U.S. Registration 3160103 Application Date 07/29/2004 No. Registration Date 10/17/2006 Foreign Priority NONE Date Word Mark SOURCE Design Mark Description of NONE Mark Goods/Services Class 009. First use: First Use: 2004/11/16 First Use In Commerce: 2004/11/16 computer software used to create three dimensional graphical environments, in- cluding capabilities for animation, artificial intelligence, sound, simulation andnetworking U.S. -
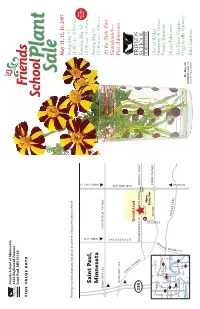
2007 Catalog
Friends School of Minnesota 1365 Englewood Avenue Saint Paul, MN 55104 TIME VALUE DATA May 11, 12, 13, 2007 Friday,May 11 If you have received a duplicate copy, please let us know, and pass the extra to a friend! 11:00 A.M.–8:00 P.M. New Saturday Saturday,May 12 Hours Saint Paul, 10:00 A.M.–6:00 P.M. Sunday,May 13 FROM 35W Minnesota FROM HWY 36 12:00 NOON–4:00 P.M. FROM HWY 280 LARPENTEUR AVENUE At the State Fair Grandstand— FROM HWY 280 Free Admission C O M O CLEVELAND AVE A SNELLING AVE V E Grandstand N U 280 E COMMONWEALTH DAN PATCH Main MIDWAY PKWY Gate P Minn. State Fair 94 Coliseum COMO AVENUE 35W White Shoreview Glacial Ridge Brooklyn Ctr Bear Lake 694 35E E U CANFIELD Growers: A Green Plymouth Crystal 94 Roseville N 36 E 494 Snelling Ave. 694 V 169 Saint Paul Family Business 280 A 394 35E 100 94 D Minnetonka Minneapolis E N N Woodbury ERGY Hosta Takeover! O P Edina 494 ARK 62 M Richfield Y 61 Eden 494 Prairie A Are These Veggies 35W Inver Grove R Heights Bloomington Eagan FROM 94 Organically Grown? 52 Mr. Majestic Shakopee 35E Burnsville marigold, page 12 Photo by Nancy Scherer Bird Gardens 18th Annual Friends School Plant Sale May 11, 12 and 13, 2007 Friday 11:00 A.M.–8:00 P.M.• Saturday 10:00 A.M.–6:00 P.M. Sunday 12:00 NOON–4:00 P.M.Sunday is half-price day at the Minnesota State Fair Grandstand Friends School of Minnesota Thank you for supporting Friends School of Minnesota by purchasing plants at our sale. -

Modular and High Performance Shader Development
Shader Components: Modular and High Performance Shader Development YONG HE, Carnegie Mellon University TIM FOLEY, NVIDIA TEGUH HOFSTEE, Carnegie Mellon University HAOMIN LONG, Tsinghua University KAYVON FATAHALIAN, Carnegie Mellon University at a sucient rate. Many of these commands pertain to binding Modern game engines seek to balance the conicting goals of high ren- shader parameters (textures, buers, etc.) to the graphics pipeline. dering performance and productive software development. To improve CPU This problem is suciently acute that a new generation of real-time performance, the most recent generation of real-time graphics APIs provide graphics APIs [Khronos Group, Inc. 2016; Microsoft 2017] has been new primitives for performing ecient batch updates to shader parameters. designed to provide new primitives for performing ecient batch However, modern game engines featuring large shader codebases have strug- updates to shader parameters. However, modern game engines have gled to take advantage of these benets. The problem is that even though shader parameters can be organized into ecient modules bound to the been unable to fully take advantage of this functionality. pipeline at various frequencies, modern shading languages lack correspond- The problem is that even though shader parameters can now be ing primitives to organize shader logic (requiring these parameters) into organized into ecient modules and bound to the pipeline only at modules as well. The result is that complex shaders are typically compiled to the necessary frequencies, modern shading languages lack corre- use a monolithic block of parameters, defeating the design, and performance sponding primitives to organize shader logic (that requires these benets, of the new parameter binding API. -

Thesis Template
Bachelor’s thesis Information technology NTIETS12P 2017 Miika Perkola BEST PRACTICES OF LEVEL DESIGN BACHELOR’S THESIS | ABSTRACT TURKU UNIVERSITY OF APPLIED SCIENCES Information Technology | Game Technology 2017 | 32 senior teacher & professor Mika Luimula Miika Perkola BEST PRACTICES OF LEVEL DESIGN The thesis was commissioned by Rockodile Games that is a Finnish game development company. The purpose of this thesis was to research what level design is and what the best practices are that the commissioning company could use in their future projects. The gathered knowledge is then applied into analyzing the commissioning company’s existing product in order to achieve a complete picture on what level design is. The thesis introduces basic level design including the design process and level production. The thesis examines level design and level designers in general and establishes some of the tools level designers have at their disposal. It also covers the topic of design process and presents all the steps needed to shape an idea into a solid plan that can be executed later. Later the thesis covers the topic of level production with a focus on different level editors. The concluding section examines all the topics that were researched in the thesis using an existing product. KEYWORDS: level design, level editor, designer, player guiding OPINNÄYTETYÖ (AMK) | TIIVISTELMÄ TURUN AMMATTIKORKEAKOULU Tietotekniikka | Peliteknologia 2017 | 32 yliopettaja & dosentti Mika Luimula Miika Perkola KENTTÄSUUNNITTELUN HYVÄKSI TODETUT TOIMINTATAVAT Kenttäsuunnittelu on prosessi, jolla valmistetaan kenttiä, tasoja ja peliympäristöjä peleihin. Tämän opinnäytetyön tarkoitus oli tutkia, mitä kenttäsuunnittelu on ja mitkä ovat kenttäsuunnittelun hyväksi todettuja toimintatapoja, joita yritys pystyisi hyödyntämään tulevissa projekteissaan. -

A Survey of Benchmarking Frameworks for Reinforcement Learning
SACJ 32(2) December 2020 Research Article A survey of benchmarking frameworks for reinforcement learning Belinda Stapelberg , Katherine M. Malan Department of Decision Sciences, University of South Africa, Pretoria, South Africa ABSTRACT Reinforcement learning has recently experienced increased prominence in the machine learning community. There are many approaches to solving reinforcement learning problems with new techniques developed con- stantly. When solving problems using reinforcement learning, there are various difficult challenges to overcome. To ensure progress in the field, benchmarks are important for testing new algorithms and comparing with other approaches. The reproducibility of results for fair comparison is therefore vital in ensuring that improve- ments are accurately judged. This paper provides an overview of different contributions to reinforcement learn- ing benchmarking and discusses how they can assist researchers to address the challenges facing reinforcement learning. The contributions discussed are the most used and recent in the literature. The paper discusses the contributions in terms of implementation, tasks and provided algorithm implementations with benchmarks. The survey aims to bring attention to the wide range of reinforcement learning benchmarking tasks available and to encourage research to take place in a standardised manner. Additionally, this survey acts as an overview for researchers not familiar with the different tasks that can be used to develop and test new reinforcement learning algorithms. -

Serious Games Architectures and Engines
Serious Games Architectures and Engines Heinrich Söbke1, Alexander Streicher2 1 Bauhaus-Institute for Infrastructure Solutions (b.is), Bauhaus-Universität Weimar, Germany [email protected] 2 Fraunhofer IOSB, Karlsruhe, Germany [email protected] Abstract. The term Serious Game includes a wide, heterogeneous field of digital games with varying purposes and objectives and for a multitude of different ap- plication areas. All in common is the underlying software. This chapter gives an overview on the technical aspects of serious games including their software ar- chitectures and engines. As the general topic is manifold and the technical aspects of serious game software are quite comprehensive, this chapter covers the basic principles of and requirements for serious game software. It depicts selected soft- ware architectures and provides examples for game engines including a descrip- tion of selected components. Keywords: Serious Games Architecture, Game Engine, Serious Game Devel- opment, Distributed Architecture, Game Component, Schema. 1 Introduction What are serious games and how can they be categorized? Schmidt et al. [1] suggest a categorization according to the purpose of the game: they follow the work of Connolly et al. [2] and classify the purposes of a game as Attention, Motivation, Knowledge or skill acquisition, Process Support, Joy/Playfulness and Information. Michael & Chen [3] identify eight categories as markets for serious games: Military, government, edu- cation, corporate games, healthcare, politics, religion and art. These are only two of the suggested categorizations – Djaouti et al. [4] present a literature review of serious games categorization in their work to develop their G/P/S model.