Mole: Motion Leaks Through Smartwatch Sensors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Shiffman 120, 122, 123, 125, 201, 202, 217 Classroom Instructions
Shiffman 120, 122, 123, 125, 201, 202, 217 (TEC classrooms – level B) No Access Codes Needed. These rooms utilize ceiling-mounted projectors, focused on wall-mounted pull down screens. Displaying Video or Computer Sources 1. At the Instructor Station. Push DOWN on the black system controller to access controls. Touch the screen to begin. 2. Press the PC (or any source) button to turn on the display system. The projector will take over a minute to warm up. No controls will function during warm up. 3. After the warm up, you can select another source using the appropriate buttons. (Buttons illuminate when active.) It’s recommended to wait a few seconds between input selections. • PC will display the installed Instructor PC. There are courtesy USB ports on the front of the PC. • LAPTOP will open another page, where you can select the VGA cable w/audio or the Digital HDMI cable as your laptop source. These cables are provided at the instructor station. Beyond the buttons, the system will attempt to auto-detect, and switch to a laptop when properly connected. Users must provide their MAC & DisplayPort adapters. • DVD selects the DVD player, stored at the Instructor Station. A disc control page will appear on the touch panel allowing you to control the player. • If a VHS player exists in your room, a VCR button will appear as a source on the touch panel. Press VCR to select. If there is no VHS player, contact Media Technology Services (MTS: 781- 736-4632) to request a temporary unit. Legacy VHS stock is declining, and this is based on inventory availability. -

Review Dell Latitude D430 Subnotebook - Notebookcheck.Net Reviews Page 1 of 5
Review Dell Latitude D430 Subnotebook - Notebookcheck.net Reviews Page 1 of 5 Home News Reviews FAQ / Tips / Technics Purchase Consultation Library Search Jobs Contact Review Dell Latitude D430 Subnotebook Road Warrior. The Dell Latitude D430 proves to be an exemplary companion in our review. The up to now smallest no the Latitude series is quiet, compact, light, and its workmanship is good. The runtime of the small 42 Wh is due to special energy-saving components up to 6 hours. Despite being equipped with low-energy com the frugal Core 2 Duo processor with 1.2 GHz clock rate combined with very fast SSD hard disk is suffic powerful for daily business. Reviewed: Dell Latitude D430 Subnotebook Notebook specifications Dell Latitude D430 :: Processor Intel Core 2 Duo U7600 1.2 GHz (Intel Core 2 Duo) Working for Notebookcheck :: Mainboard Are you a loyal reader of notebookcheck? Are you the one Intel 945GMS all your friends turn to when they want to buy a laptop or :: Memory tablet-PC? Are you a techie who knows how to write? 1024 MB, PC2-4200, 266 MHz Case Then join our Team! :: Graphics adapter The 12 inch Dell Latitude D430 by Dell, an American direct shipper, is up to now the smallest notebook Intel Graphics Media Accelerator Especially wanted: Latitude series. It was especially designed for business customers. So, the choice of forms and colou (GMA) 950 Senior Editor - Details here German-English-Translator - Details here business-like too. Bright grey and black dominate the look of this light portable computer, which weigh :: Display 1.5 kg. -

Securing and Managing Wearables in the Enterprise
White Paper: Securing and Managing Wearables in the Enterprise Streamline deployment and protect smartwatch data with Samsung Knox Configure White Paper: Securing and Managing Wearables in the Enterprise 2 Introduction: Smartwatches in the Enterprise As the wearable device market heats up, wrist-worn devices Industries as varied as healthcare, such as smartwatches are leading the pack. According to CCS Insight, forecasts for global sales of smart wearable devices finance, energy, transportation, will grow strongly over the next five years, with the global public safety, retail and hospitality market reaching nearly $30 billion by 2023.1 are deploying smartwatches for While smartwatches for fitness and activity tracking are popular, consumer demand is only part of the equation. added business value. Enterprises are also seeing business value in wearable devices. In a report by Robert Half Technology, 81 percent of CIOs surveyed expect wearable devices like smartwatches to Samsung has been working to address these concerns and become common tools in the workplace.2 has developed the tools to make its Galaxy and Galaxy Active smartwatches customizable, easily manageable and highly secure for enterprise users. This white paper will look at how these tools address key wearable security and manageability challenges, as well as considerations for smartwatch 81% deployments. of CIOs surveyed expect wearable devices like smartwatches to become common tools in the workplace. Industries as varied as healthcare, finance, energy, transportation, public safety, retail and hospitality are deploying smartwatches for added business value, such as hands-free communication for maintenance workers, task management, as well as physical monitoring of field workers in dangerous or remote locations. -

Screencast TV Adapter for Intel Wireless Display
TV ADAPTER FOR INTEL® WIRELESS DISPLAY User Manual SCREENCAST F7D4501 8820-00810 Rev. A01 TABLE OF CONTENTS Getting Started . 1 Introduction . .1 What’s in the Box?............................................2 What’s not in the Box?.........................................2 What Else Should I Know? .....................................3 Adapter Setup . 4 Where to Place Your ScreenCast TV Adapter . .4 Plugging Everything Together . 4 Software—First-Time Setup . .5 Using Your ScreenCast . 10 How to Use It . .10 Playing Content on Your TV . .10 Options for Using the TV Screen ...............................11 What Else Do I Need to Know? . 12 Using the Reset Button . 13 Information . 14 FCC Statement..............................................14 Belkin International, Inc., Limited 1-Year Product Warranty .........15 Technical Support . .17 GEttiNG StARTED Introduction Thank you for purchasing the ScreenCast TV Adapter for Intel Wireless Display. We created this product to help you wirelessly transmit your favorite content from your laptop to the best screen in your house—your living-room TV. Before the ScreenCast TV Adapter, you may have needed a long cable or simply crowded around your laptop screen to share movies, pictures, and surf the Web. Now you can take content from any WiDi laptop with a second-generation Intel® Core™ processor and easily display it on your TV with the ScreenCast TV Adapter. From the latest Blu-ray Disc™ movies to your favorite Netflix® and YouTube® videos, to just showing off pictures of your recent family vacation, exactly what you see on your laptop can now be displayed on your TV from as far as 30 feet away. 1 GEttiNG StARTED What’s in the Box? What’s not in the Box? • ScreenCast TV Adapter for Intel Wireless Display • An Intel Wireless Display (WiDi) laptop • You need a WiDi laptop to use the ScreenCast TV Adapter. -

Meet the Eee PC
Chapter 1 Meet the Eee PC In This Chapter ▶ Not your average laptop ▶ Popular Eee PC misconceptions ▶ Reviewing Eee PC models ▶ Selecting an Eee PC ▶ Purchasing an Eee PC his chapter introduces you to the ASUS Eee PC. (Eee PC is pronounced Twith a single E, not multiple EEEs, as in “Eeek, a mouse!”) If you’re won- dering where all those Es came from, it’s from a marketing campaign that states the computer is “Easy to learn, easy to work, and easy to play.” In this chapter, I tell you what the Eee PC is — and just as important, what it isn’t. I then list available models, describe their specifications, and conclude by giving you tips on selecting and purchasing an Eee PC. Eee PC: Not Your Average Laptop The Eee PC (see Figure 1-1) has been called a mini-laptop, a subnotebook, a Mobile Internet Device (MID), and a netbook (a catchy marketing buzzword for small, Internet-centric laptops). Whatever you call it, the Eee PC is a shrunk- down, lightweightCOPYRIGHTED laptop that has these keyMATERIAL features: ✓ Small — At just a bit over two pounds and roughly the size of this book, the 7-inch and 8.9-inch screen models are designed to be go-anywhere, do-anything personal computers. To fit in such a small package, keys on the Eee PC are smaller than those found on a typical laptop keyboard — right around 83 percent of normal. After you get used to the small size it’s possible to touch type with some practice. -

How to Display Web Content on Your TV
presents How to Display Web Content on Your TV What’s the easiest way to display web content on your TV? In many cases, you can use a cable from a video output port on your laptop (or other connected device) to a video input port on your TV. Start by checking both your laptop and TV to see what type of ports they’ve got, then see the notes below for tips on using the cable that matches your ports. HDMI – If both your laptop and TV have HDMI ports, you’re home free. The HDMI will deliver both high quality video and audio. Plug it into both devices, then press the INPUT button on your TV’s remote control until you see the computer’s picture mirrored on your TV. HDMI Note for Mac or iPad users – You will need to purchase an apple HDMI adapter. The adapter plugs into your Apple device’s video out port. Then you can connect an HDMI cable to the adapter and your TV. DVI – If both your laptop and your TV have DVI ports, you can use a DVI cable to carry the web video to your TV. DVI will not carry audio, so you’ll need a separate audio cable. You can use a single-pin audio cable and plug it into the headphone jack on the laptop and to the audio-in jack on your TV. This will be a good quality video solution. After connecting the cable, press the INPUT button on your TV’s remote control until you see the DV computer’s picture mirrored on your TV. -

Student Laptop Recommendations
Information Technology Services http://www.lander.edu/its [email protected] 864.388.8234 Student Laptop Recommendations Information Technology Services provides the following information to assist students with decisions about computer purchases. In general, most new or recently purchased laptops that students bring with them to Lander will meet the basic requirements for network connectivity on Lander University’s wireless network, regardless of Operating System (Windows/PC Platform or Mac OS). The Technology Resource Assistance Center for Students (TRACS) supports student laptops, mobile devices and gaming systems on campus and should be a first stop for students needing help connecting to Lander’s network or with questions about the configuration and function of computers. TRACS is located on the lower level of Jackson Library. These are the minimum recommendations for computers connecting to Lander University’s network: Windows 2.0 GHz Intel Core i5 Processor 6 GB RAM 250+ GB Hard Drive Windows 10 CD-R/RW or DVD-R/RW 10/100/1000 Gigabit Ethernet (Standard on most models) 802.11b/g/n on laptops (Standard on most models) Extended warranty plan, including accidental damage coverage, for expected life of computer (strongly recommended) Bag to protect laptop, if applicable 250+ GB external Backup Storage ***Lander University’s wireless network does not allow connections by computers running Windows Vista or older.*** Macintosh 2.0 GHz Intel Core 2 Duo Processor 4 GB RAM 250 GB Hard Drive OS X (10.10 - Yosemite) or newer Gigabit Ethernet (Standard on all new models, except MacBook Air and MacBook Pro with Retina Display) 802.11b/g/n on laptops (802.11n standard on all new models) AppleCare Protection Plan (strongly recommended) Bag to protect laptop, if applicable 120 GB external Backup Storage Chromebooks are a slightly less-expensive alternative that provide much of the same functionality as a laptop, but due to limitations should be considered a supplemental device, rather than a primary device. -
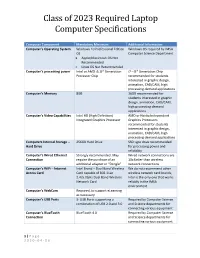
Class of 2023 Required Laptop Computer Specifications
Class of 2023 Required Laptop Computer Specifications Computer Component Mandatory Minimum Additional Information Computer’s Operating System Windows 10 Professional Edition Windows OS required by IMSA OS Computer Science Department Apple/Macintosh OS Not Recommended Linux OS Not Recommended Computer’s processing power Intel or AMD i5, 8th Generation i7 – 8th Generation Chip Processor Chip recommended for students interested in graphic design, animation, CAD/CAM, high processing demand applications Computer’s Memory 8GB 16GB recommended for students interested in graphic design, animation, CAD/CAM, high processing demand applications Computer’s Video Capabilities Intel HD (High Definition) AMD or Nvidia Independent Integrated Graphics Processor Graphics Processors recommended for students interested in graphic design, animation, CAD/CAM, high processing demand applications Computers Internal Storage – 256GB Hard Drive SSD type drive recommended Hard Drive for processing power and reliability Computer’s Wired Ethernet Strongly recommended. May Wired network connections are Connection require the purchase of an 10x faster than wireless additional adapter or “Dongle” network connections Computer’s WiFi – Internet Intel Brand – Dual Band Wireless We do not recommend other Access Card Card capable of 802.11ac wireless network card brands, 2.4/5.0GHz Dual Band Wireless Intel is the only one that works Network Card reliably in the IMSA environment Computer’s WebCam Required, to support eLearning as necessary Computer’s USB Ports 3- USB Ports -

Getting to Know Computers
Computer Basics Getting to Know Computers Page 1 What is a Computer? A computer is an electronic device that manipulates information, or "data." It has the ability to store, retrieve, and process data. You can use a computer to type documents, send email, and browse the internet. You can also use it to handle spreadsheets, accounting, database management, presentations, games, and more. Watch the video to learn about different types of computers. Watch the video (2:39). Need help? Computers Simplified For beginning computer users, the computer aisles at an electronics store can be quite a mystery, not to mention overwhelming. However, computers really aren't that mysterious. All types of computers consist of two basic parts: Hardware is any part of your computer that has a physical structure, such as the computer monitor or keyboard. Software is any set of instructions that tells the hardware what to do. It is what guides the hardware and tells it how to accomplish each task. Some examples of software are web browsers, games, and word processors such as Microsoft Word. A motherboard (hardware) Microsoft Word (software) Anything you buy for your computer can be classified as either hardware or software. Once you learn more about these items, computers are actually very straightforward. The first electronic computer, the Electronic Numerical Integrator and Computer (ENIAC), was developed in ©1998-2013 Goodwill Community Foundation, Inc. All rights reserved. 1946. It took up 1,800 square feet and weighed 30 tons. Page 2 What are the Different Types of Computers? When most people hear the word "computer," they think of a personal computer such as a desktop or laptop computer. -

Personal Computer/Laptop Technical Requirements
EPIC4SJH Personal Computer/Laptop Technical Recommendations and Access Requirements This document reviews the minimum technical recommendations and access requirements for using personal computers/laptops to support the best virtual and independent Epic training and practice experience. You are asked to review these before beginning your training. Have question? Call the ServiceDesk: 844-922-7548. Technical Recommendations Epic training and practice should be completed on a computer or laptop. You should NOT use an iPad, iPhone or Chrome Book for training, or you will have challenges viewing Epic screens and online training. For best learning experience, please note the following minimum system recommendations for personal computers and laptops. Personal Web Brower Operating system Internet Other Equipment Computer or Connection Laptop Minimum screen Latest version of At least Windows 10 High speed For virtual training, a display size of 15” Chrome (preferred) (Window 7 may work, internet private phone is but some issues may DSL/Cable recommended over Audio capability Latest version of be encountered) (not dialup) computer Internet Explorer 11, microphone for best Microsoft Chromium MAC computer - Reliable sound quality Edge Catalina OS connection Comfortable headphones/ earbuds Access Requirements To complete training and practice in the Epic system remotely, you must have Multifactor Authentication (MFA) set up and Citrix Workspace must be installed on your personal computer. Please follow these steps in advance of training. Installing -

Pdas and Smartphones in the Classroom Teaching and Technology Trends Symposium March 30, 2007 Jimmy D
PDAs and Smartphones in the Classroom Teaching and Technology Trends Symposium March 30, 2007 Jimmy D. Clark, Instructional Design Specialist Introduction Figure 1: Mobile Devices Today’s young learners use mobile devices such as cell phones, PDAs, MP3 players, and GPS devices every day. They enjoy learning as part of a group or team, or even in a “smartmob” or “learning swarm.” They play computer games, interact constantly with each other on websites such as Facebook and MySpace, and wish their college learning experience matched the learning they do in their everyday lives. Mobile learning technologies give them this opportunity. In this workshop we will focus on how PDAs and smartphones facilitate learning in today’s new teaching and learning environment. What You Will Learn in this Workshop In this workshop you will learn what mobile learning is: its history, some of the advantages of mobile learning, and about some of the tools used in mobile learning. You will also learn about the features of a PDA, its history, and the ways they are used in education. We will also talk about the challenges of using PDAs in education, with special emphasis on accessibility issues. In the last part of our discussion of PDAs we will talk about future trends in the use of PDAs in education. In the section on smartphones we will discuss what a smartphone is, its features, operating systems, the history of the smartphone, the reasons they are popular in education, and future trends in smartphones. This will not be a hands-on workshop. Goals and Objectives for this Workshop The goals and objectives for this workshop are: 1. -

NOMAD PD2100A Multimedia Podium New Users Brief
NOMAD PD2100A Multimedia Podium As installed in the Lake County Courthouse OVERVIEW The Nomad PD2100A Multimedia Podium System is a powerful and robust model from the Nomad Technologies Multimedia Podium line. This all-in-one system integrates a wide variety of presentation equipment to share the technology from courtroom-to-courtroom. Setup is easy . simply plug the power cord into the power outlet and the three shielded cables and the entire unit is connected and ready for use. Nomad enables you to convey your ideas easier to understand and increase jury interest and comprehension with multimedia presentations. Whether it's a PowerPoint presentation, DVD discs, VCR tapes, X-rays, digital or printed documents, photographs, books and three dimensional objects, . you have the tools you need to bring your presentations to life. Features of the Nomad PD2100A Podium include: A proprietary multimedia podium designed by Nomad Technologies Two wireless touch-screen controllers - One on the Judge’s bench, the other is stored in the podium and can move from table to table. A 58” digital wall display for the Jury (with 4:3 or 16:9 aspect ratio, pole mounted above the Witness Stand.) A 15” touch-screen preview monitor with annotation within the podium for the presenter. Another 15” touch-screen monitor with annotation mounted with an adjustable arm mount for the Witness Stand. A powerful digital document camera. A VCR/DVD player with DVD to VCR or VCR to DVD record capabilities. A high-quality sound system including a powerful amplifier, a ducker (voice- over media) system, a gooseneck microphone and integrated speakers.