An Implementation of Python for Drracket 1 Introduction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Functional SMT Solving: a New Interface for Programmers
Functional SMT solving: A new interface for programmers A thesis submitted in Partial Fulfillment of the Requirements for the Degree of Master of Technology by Siddharth Agarwal to the DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING INDIAN INSTITUTE OF TECHNOLOGY KANPUR June, 2012 v ABSTRACT Name of student: Siddharth Agarwal Roll no: Y7027429 Degree for which submitted: Master of Technology Department: Computer Science & Engineering Thesis title: Functional SMT solving: A new interface for programmers Name of Thesis Supervisor: Prof Amey Karkare Month and year of thesis submission: June, 2012 Satisfiability Modulo Theories (SMT) solvers are powerful tools that can quickly solve complex constraints involving booleans, integers, first-order logic predicates, lists, and other data types. They have a vast number of potential applications, from constraint solving to program analysis and verification. However, they are so complex to use that their power is inaccessible to all but experts in the field. We present an attempt to make using SMT solvers simpler by integrating the Z3 solver into a host language, Racket. Our system defines a programmer’s interface in Racket that makes it easy to harness the power of Z3 to discover solutions to logical constraints. The interface, although in Racket, retains the structure and brevity of the SMT-LIB format. We demonstrate this using a range of examples, from simple constraint solving to verifying recursive functions, all in a few lines of code. To my grandfather Acknowledgements This project would have never have even been started had it not been for my thesis advisor Dr Amey Karkare’s help and guidance. Right from the time we were looking for ideas to when we finally had a concrete proposal in hand, his support has been invaluable. -

Feature-Specific Profiling
Feature-Specific Profiling LEIF ANDERSEN, PLT @ Northeastern University, United States of America VINCENT ST-AMOUR, PLT @ Northwestern University, United States of America JAN VITEK, Northeastern University and Czech Technical University MATTHIAS FELLEISEN, PLT @ Northeastern University, United States of America While high-level languages come with significant readability and maintainability benefits, their performance remains difficult to predict. For example, programmers may unknowingly use language features inappropriately, which cause their programs to run slower than expected. To address this issue, we introduce feature-specific profiling, a technique that reports performance costs in terms of linguistic constructs. Festure-specific profilers help programmers find expensive uses of specific features of their language. We describe the architecture ofa profiler that implements our approach, explain prototypes of the profiler for two languages withdifferent characteristics and implementation strategies, and provide empirical evidence for the approach’s general usefulness as a performance debugging tool. ACM Reference Format: Leif Andersen, Vincent St-Amour, Jan Vitek, and Matthias Felleisen. 2018. Feature-Specific Profiling. 1,1 (September 2018), 35 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn 1 PROFILING WITH ACTIONABLE ADVICE When programs take too long to run, programmers tend to reach for profilers to diagnose the problem. Most profilers attribute the run-time costs during a program’s execution to cost centers such as function calls or statements in source code. Then they rank all of a program’s cost centers in order to identify and eliminate key bottlenecks (Amdahl 1967). If such a profile helps programmers optimize their code, we call it actionable because it points to inefficiencies that can be remedied with changes to the program. -

Meta-Tracing Makes a Fast Racket
Meta-tracing makes a fast Racket Carl Friedrich Bolz Tobias Pape Jeremy Siek Software Development Team Hasso-Plattner-Institut Indiana University King’s College London Potsdam [email protected] [email protected] [email protected] potsdam.de Sam Tobin-Hochstadt Indiana University [email protected] ABSTRACT 1. INTRODUCTION Tracing just-in-time (JIT) compilers record and optimize the instruc- Just-in-time (JIT) compilation has been applied to a wide variety tion sequences they observe at runtime. With some modifications, languages, with early examples including Lisp, APL, Basic, Fortran, a tracing JIT can perform well even when the executed program is Smalltalk, and Self [Aycock, 2003]. These days, JIT compilation itself an interpreter, an approach called meta-tracing. The advantage is mainstream; it is responsible for running both server-side Java of meta-tracing is that it separates the concern of JIT compilation applications [Paleczny et al., 2001] and client-side JavaScript appli- from language implementation, enabling the same JIT compiler to cations in web browsers [Hölttä, 2013]. be used with many different languages. The RPython meta-tracing Mitchell [1970] observed that one could obtain an instruction JIT compiler has enabled the efficient interpretation of several dy- sequence from an interpreter by recording its actions. The interpreter namic languages including Python (PyPy), Prolog, and Smalltalk. can then jump to this instruction sequence, this trace, when it returns In this paper we present initial findings in applying the RPython to interpret the same part of the program. For if-then-else statements, JIT to Racket. Racket comes from the Scheme family of program- there is a trace for only one branch. -

Functional SMT Solving with Z3 and Racket
Functional SMT Solving with Z3 and Racket Siddharth Agarwal∗y Amey Karkarey [email protected] [email protected] ∗Facebook Inc, yDepartment of Computer Science & Engineering Menlo Park, CA, USA Indian Institute of Technology Kanpur, India Abstract—Satisfiability Modulo Theories (SMT) solvers are can attack range from simple puzzles like Sudoku and n- powerful tools that can quickly solve complex constraints queens, to planning and scheduling, program analysis [8], involving Booleans, integers, first-order logic predicates, lists, whitebox fuzz testing [9] and bounded model checking [10]. and other data types. They have a vast number of potential Yet SMT solvers are only used by a small number of experts. It applications, from constraint solving to program analysis and isn’t hard to see why: the standard way for programs to interact verification. However, they are so complex to use that their power with SMT solvers like Z3 [4], Yices [5] and CVC3 [11] is via is inaccessible to all but experts in the field. We present an attempt to make using SMT solvers simpler by integrating the powerful but relatively arcane C APIs that require the users Z3 solver into a host language, Racket. The system defines a to know the particular solver’s internals. For example, here programmer’s interface in Racket that makes it easy to harness is a C program that asks Z3 whether the simple proposition the power of Z3 to discover solutions to logical constraints. The p ^ :p is satisfiable. interface, although in Racket, retains the structure and brevity Z3_config cfg = Z3_mk_config(); of the SMT-LIB format. -

Comparative Studies of 10 Programming Languages Within 10 Diverse Criteria
Department of Computer Science and Software Engineering Comparative Studies of 10 Programming Languages within 10 Diverse Criteria Jiang Li Sleiman Rabah Concordia University Concordia University Montreal, Quebec, Concordia Montreal, Quebec, Concordia [email protected] [email protected] Mingzhi Liu Yuanwei Lai Concordia University Concordia University Montreal, Quebec, Concordia Montreal, Quebec, Concordia [email protected] [email protected] COMP 6411 - A Comparative studies of programming languages 1/139 Sleiman Rabah, Jiang Li, Mingzhi Liu, Yuanwei Lai This page was intentionally left blank COMP 6411 - A Comparative studies of programming languages 2/139 Sleiman Rabah, Jiang Li, Mingzhi Liu, Yuanwei Lai Abstract There are many programming languages in the world today.Each language has their advantage and disavantage. In this paper, we will discuss ten programming languages: C++, C#, Java, Groovy, JavaScript, PHP, Schalar, Scheme, Haskell and AspectJ. We summarize and compare these ten languages on ten different criterion. For example, Default more secure programming practices, Web applications development, OO-based abstraction and etc. At the end, we will give our conclusion that which languages are suitable and which are not for using in some cases. We will also provide evidence and our analysis on why some language are better than other or have advantages over the other on some criterion. 1 Introduction Since there are hundreds of programming languages existing nowadays, it is impossible and inefficient -
Metaprogramming: Interpretaaon Interpreters
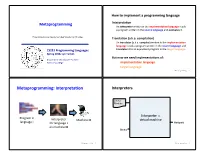
How to implement a programming language Metaprogramming InterpretaAon An interpreter wriDen in the implementaAon language reads a program wriDen in the source language and evaluates it. These slides borrow heavily from Ben Wood’s Fall ‘15 slides. TranslaAon (a.k.a. compilaAon) An translator (a.k.a. compiler) wriDen in the implementaAon language reads a program wriDen in the source language and CS251 Programming Languages translates it to an equivalent program in the target language. Spring 2018, Lyn Turbak But now we need implementaAons of: Department of Computer Science Wellesley College implementaAon language target language Metaprogramming 2 Metaprogramming: InterpretaAon Interpreters Source Program Interpreter = Program in Interpreter Machine M virtual machine language L for language L Output on machine M Data Metaprogramming 3 Metaprogramming 4 Metaprogramming: TranslaAon Compiler C Source x86 Target Program C Compiler Program if (x == 0) { cmp (1000), $0 Program in Program in x = x + 1; bne L language A } add (1000), $1 A to B translator language B ... L: ... x86 Target Program x86 computer Output Interpreter Machine M Thanks to Ben Wood for these for language B Data and following pictures on machine M Metaprogramming 5 Metaprogramming 6 Interpreters vs Compilers Java Compiler Interpreters No work ahead of Lme Source Target Incremental Program Java Compiler Program maybe inefficient if (x == 0) { load 0 Compilers x = x + 1; ifne L } load 0 All work ahead of Lme ... inc See whole program (or more of program) store 0 Time and resources for analysis and opLmizaLon L: ... (compare compiled C to compiled Java) Metaprogramming 7 Metaprogramming 8 Compilers... whose output is interpreted Interpreters.. -

Comparative Studies of 10 Programming Languages Within 10 Diverse Criteria Revision 1.0
Comparative Studies of 10 Programming Languages within 10 Diverse Criteria Revision 1.0 Rana Naim∗ Mohammad Fahim Nizam† Concordia University Montreal, Concordia University Montreal, Quebec, Canada Quebec, Canada [email protected] [email protected] Sheetal Hanamasagar‡ Jalal Noureddine§ Concordia University Montreal, Concordia University Montreal, Quebec, Canada Quebec, Canada [email protected] [email protected] Marinela Miladinova¶ Concordia University Montreal, Quebec, Canada [email protected] Abstract This is a survey on the programming languages: C++, JavaScript, AspectJ, C#, Haskell, Java, PHP, Scala, Scheme, and BPEL. Our survey work involves a comparative study of these ten programming languages with respect to the following criteria: secure programming practices, web application development, web service composition, OOP-based abstractions, reflection, aspect orientation, functional programming, declarative programming, batch scripting, and UI prototyping. We study these languages in the context of the above mentioned criteria and the level of support they provide for each one of them. Keywords: programming languages, programming paradigms, language features, language design and implementation 1 Introduction Choosing the best language that would satisfy all requirements for the given problem domain can be a difficult task. Some languages are better suited for specific applications than others. In order to select the proper one for the specific problem domain, one has to know what features it provides to support the requirements. Different languages support different paradigms, provide different abstractions, and have different levels of expressive power. Some are better suited to express algorithms and others are targeting the non-technical users. The question is then what is the best tool for a particular problem. -

Typing the Numeric Tower
Typing the Numeric Tower Vincent St-Amour1, Sam Tobin-Hochstadt1, Matthew Flatt2, and Matthias Felleisen1 1 Northeastern University {stamourv,samth,matthias}@ccs.neu.edu 2 University of Utah [email protected] Abstract. In the past, the creators of numerical programs had to choose between simple expression of mathematical formulas and static type checking. While the Lisp family and its dynamically typed relatives support the straightforward ex- pression via a rich numeric tower, existing statically typed languages force pro- grammers to pollute textbook formulas with explicit coercions or unwieldy nota- tion. In this paper, we demonstrate how the type system of Typed Racket accom- modates both a textbook programming style and expressive static checking. The type system provides a hierarchy of numeric types that can be freely mixed as well as precise specifications of sign, representation, and range information—all while supporting generic operations. In addition, the type system provides infor- mation to the compiler so that it can perform standard numeric optimizations. 1 Designing the Numeric Tower From the classic two-line factorial program to financial applications to scientific com- putation to graphics software, programs rely on numbers and numeric computations. Because of this spectrum of numeric applications, programmers wish to use a wide vari- ety of numbers: the inductively defined natural numbers, fixed-width integers, floating- point numbers, complex numbers, etc. Supporting this variety demands careful attention to the design of programming languages that manipulate numbers. Most languages have taken one of two approaches to numbers. Many untyped lan- guages, drawing on the tradition of Lisp and Smalltalk, provide a hierarchy of numbers whose various levels can be freely used together, known as the numeric tower. -

Advanced Logical Type Systems for Untyped Languages
ADVANCED LOGICAL TYPE SYSTEMS FOR UNTYPED LANGUAGES Andrew M. Kent Submitted to the faculty of the University Graduate School in partial fulfillment of the requirements for the degree Doctor of Philosophy in the Department of Computer Science, Indiana University October 2019 Accepted by the Graduate Faculty, Indiana University, in partial fulfillment of the requirements for the degree of Doctor of Philosophy. Doctoral Committee Sam Tobin-Hochstadt, Ph.D. Jeremy Siek, Ph.D. Ryan Newton, Ph.D. Larry Moss, Ph.D. Date of Defense: 9/6/2019 ii Copyright © 2019 Andrew M. Kent iii To Caroline, for both putting up with all of this and helping me stay sane throughout. Words could never fully capture how grateful I am to have her in my life. iv ACKNOWLEDGEMENTS None of this would have been possible without the community of academics and friends I was lucky enough to have been surrounded by during these past years. From patiently helping me understand concepts to listening to me stumble through descriptions of half- baked ideas, I cannot thank enough my advisor and the professors and peers that donated a portion of their time to help me along this journey. v Andrew M. Kent ADVANCED LOGICAL TYPE SYSTEMS FOR UNTYPED LANGUAGES Type systems with occurrence typing—the ability to refine the type of terms in a control flow sensitive way—now exist for nearly every untyped programming language that has gained popularity. While these systems have been successful in type checking many prevalent idioms, most have focused on relatively simple verification goals and coarse interface specifications. -

Course Notes
David Liu Principles of Programming Languages Lecture Notes for CSC324 Department of Computer Science University of Toronto Contents Prelude: The Lambda Calculus It was in the 1930s, years before the invention of the first electronic computing devices, that a young mathematician named Alan Turing Alan Turing, 1912-1954 created modern computer science as we know it. Incredibly, this came about almost by accident; he had been trying to solve a problem from The Entscheidungsproblem (“decision mathematical logic! To answer this question, Turing developed an ab- problem”) asked whether an algorithm could decide if a logical statement is stract model of mechanical, procedural computation: a machine that provable from a given set of axioms. could read in a string of 0’s and 1’s, a finite state control that could Turing showed no such algorithm exists. make decisions and write 0’s and 1’s to its internal memory, and Finite state controls are analogous to an output space where the computation’s result would be displayed. the deterministic finite automata that you Though its original incarnation was an abstract mathematical object, learned about in CSC236. the fundamental mechanism of the Turing machine – reading data, executing a sequence of instructions to modify internal memory, and producing output – would soon become the von Neumann architec- ture lying at the heart of modern computers. It is no exaggeration that the fundamentals of computer science owe their genesis to this man. The story of Alan Turing and his machine is one of great genius, great triumph, and great sadness. Their legacy is felt by every computer scientist, software engineer, and computer engineer alive today. -

Designing a Comparative Usability Study of Error Messages
Designing a Comparative Usability Study of Error Messages Henry Fellows, Thomas Hagen, Sean Stockholm, and Elena Machkasova Computer Science Discipline University of Minnesota Morris Morris, MN 56267 [email protected], [email protected], [email protected], [email protected] Abstract Error messages are the only form of response that programmers get from malfunctioning programs. More experienced programmers often develop intuition about what error mes- sages actually mean, but novices only have the content of the error message. Our research focuses on two functional programming languages in the Lisp family, their current or po- tential use in introductory CS classes, and specifically on the quality of their error messages for beginner CS students. The languages we will be comparing are a subset of Racket called beginning student lan- guage, and Clojure. Beginning student language is a language designed for introductory students using the How to Design Programs 2 curriculum, with error messages that are designed for novices. Clojure is a Lisp built on top of the Java programming language which better supports concurrent and parallel programming and has been rapidly gaining popularity in industry. However, Clojure was not developed with beginner programmers in mind: its native error messages are often just Java error messages that dont make sense to programmers without Java background. Our previous work with Clojure has built an alter- native error messages system that we think may be more useful to beginner CS students. Our work is a part of the ClojurEd project which aims to use Clojure to teach an introduc- tory CS course. -
Principles of Programming Languages
David Liu Principles of Programming Languages Lecture Notes for CSC324 (Version 1.2) Department of Computer Science University of Toronto principles of programming languages 3 Many thanks to Alexander Biggs, Peter Chen, Rohan Das, Ozan Erdem, Itai David Hass, Hengwei Guo, Kasra Kyanzadeh, Jasmin Lantos, Jason Mai, Ian Stewart-Binks, Anthony Vandikas, and many anonymous students for their helpful comments and error-spotting in earlier versions of these notes. Contents Prelude: The Lambda Calculus 7 Alonzo Church 8 The Lambda Calculus 8 A Paradigm Shift in You 10 Course Overview 11 Racket: Functional Programming 13 Quick Introduction 13 Function Application 14 Special Forms: and, or, if, cond 20 Lists 23 Higher-Order Functions 28 Lexical Closures 33 Summary 40 6 david liu Macros, Objects, and Backtracking 43 Basic Objects 44 Macros 48 Macros with ellipses 52 Objects revisited 55 Non-deterministic choice 60 Continuations 64 Back to -< 68 Multiple choices 69 Predicates and Backtracking 73 Haskell and Types 79 Quick Introduction 79 Folding and Laziness 85 Lazy to Infinity and Beyond! 87 Types in programming 88 Types in Haskell 91 Type Inference 92 Multi-Parameter Functions and Currying 94 Type Variables and Polymorphism 96 User-Defined Types 100 principles of programming languages 7 Type classes 103 State in a Pure World 111 Haskell Input/Output 117 Purity through types 120 One more abstraction 121 In Which We Say Goodbye 125 Appendix A: Prolog and Logic Programming 127 Getting Started 127 Facts and Simple Queries 128 Rules 132 Recursion 133 Prolog Implementation 137 Tracing Recursion 144 Cuts 147 Prelude: The Lambda Calculus It seems to me that there have been two really clean, consistent models of programming so far: the C model and the Lisp model.