Principles of Programming Languages
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Functional Javascript
www.it-ebooks.info www.it-ebooks.info Functional JavaScript Michael Fogus www.it-ebooks.info Functional JavaScript by Michael Fogus Copyright © 2013 Michael Fogus. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://my.safaribooksonline.com). For more information, contact our corporate/ institutional sales department: 800-998-9938 or [email protected]. Editor: Mary Treseler Indexer: Judith McConville Production Editor: Melanie Yarbrough Cover Designer: Karen Montgomery Copyeditor: Jasmine Kwityn Interior Designer: David Futato Proofreader: Jilly Gagnon Illustrator: Robert Romano May 2013: First Edition Revision History for the First Edition: 2013-05-24: First release See http://oreilly.com/catalog/errata.csp?isbn=9781449360726 for release details. Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. Functional JavaScript, the image of an eider duck, and related trade dress are trademarks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc., was aware of a trade‐ mark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and author assume no responsibility for errors or omissions, or for damages resulting from the use of the information contained herein. -

Functional SMT Solving: a New Interface for Programmers
Functional SMT solving: A new interface for programmers A thesis submitted in Partial Fulfillment of the Requirements for the Degree of Master of Technology by Siddharth Agarwal to the DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING INDIAN INSTITUTE OF TECHNOLOGY KANPUR June, 2012 v ABSTRACT Name of student: Siddharth Agarwal Roll no: Y7027429 Degree for which submitted: Master of Technology Department: Computer Science & Engineering Thesis title: Functional SMT solving: A new interface for programmers Name of Thesis Supervisor: Prof Amey Karkare Month and year of thesis submission: June, 2012 Satisfiability Modulo Theories (SMT) solvers are powerful tools that can quickly solve complex constraints involving booleans, integers, first-order logic predicates, lists, and other data types. They have a vast number of potential applications, from constraint solving to program analysis and verification. However, they are so complex to use that their power is inaccessible to all but experts in the field. We present an attempt to make using SMT solvers simpler by integrating the Z3 solver into a host language, Racket. Our system defines a programmer’s interface in Racket that makes it easy to harness the power of Z3 to discover solutions to logical constraints. The interface, although in Racket, retains the structure and brevity of the SMT-LIB format. We demonstrate this using a range of examples, from simple constraint solving to verifying recursive functions, all in a few lines of code. To my grandfather Acknowledgements This project would have never have even been started had it not been for my thesis advisor Dr Amey Karkare’s help and guidance. Right from the time we were looking for ideas to when we finally had a concrete proposal in hand, his support has been invaluable. -

Feature-Specific Profiling
Feature-Specific Profiling LEIF ANDERSEN, PLT @ Northeastern University, United States of America VINCENT ST-AMOUR, PLT @ Northwestern University, United States of America JAN VITEK, Northeastern University and Czech Technical University MATTHIAS FELLEISEN, PLT @ Northeastern University, United States of America While high-level languages come with significant readability and maintainability benefits, their performance remains difficult to predict. For example, programmers may unknowingly use language features inappropriately, which cause their programs to run slower than expected. To address this issue, we introduce feature-specific profiling, a technique that reports performance costs in terms of linguistic constructs. Festure-specific profilers help programmers find expensive uses of specific features of their language. We describe the architecture ofa profiler that implements our approach, explain prototypes of the profiler for two languages withdifferent characteristics and implementation strategies, and provide empirical evidence for the approach’s general usefulness as a performance debugging tool. ACM Reference Format: Leif Andersen, Vincent St-Amour, Jan Vitek, and Matthias Felleisen. 2018. Feature-Specific Profiling. 1,1 (September 2018), 35 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn 1 PROFILING WITH ACTIONABLE ADVICE When programs take too long to run, programmers tend to reach for profilers to diagnose the problem. Most profilers attribute the run-time costs during a program’s execution to cost centers such as function calls or statements in source code. Then they rank all of a program’s cost centers in order to identify and eliminate key bottlenecks (Amdahl 1967). If such a profile helps programmers optimize their code, we call it actionable because it points to inefficiencies that can be remedied with changes to the program. -

Revised5report on the Algorithmic Language Scheme
Revised5 Report on the Algorithmic Language Scheme RICHARD KELSEY, WILLIAM CLINGER, AND JONATHAN REES (Editors) H. ABELSON R. K. DYBVIG C. T. HAYNES G. J. ROZAS N. I. ADAMS IV D. P. FRIEDMAN E. KOHLBECKER G. L. STEELE JR. D. H. BARTLEY R. HALSTEAD D. OXLEY G. J. SUSSMAN G. BROOKS C. HANSON K. M. PITMAN M. WAND Dedicated to the Memory of Robert Hieb 20 February 1998 CONTENTS Introduction . 2 SUMMARY 1 Overview of Scheme . 3 1.1 Semantics . 3 The report gives a defining description of the program- 1.2 Syntax . 3 ming language Scheme. Scheme is a statically scoped and 1.3 Notation and terminology . 3 properly tail-recursive dialect of the Lisp programming 2 Lexical conventions . 5 language invented by Guy Lewis Steele Jr. and Gerald 2.1 Identifiers . 5 Jay Sussman. It was designed to have an exceptionally 2.2 Whitespace and comments . 5 clear and simple semantics and few different ways to form 2.3 Other notations . 5 expressions. A wide variety of programming paradigms, in- 3 Basic concepts . 6 3.1 Variables, syntactic keywords, and regions . 6 cluding imperative, functional, and message passing styles, 3.2 Disjointness of types . 6 find convenient expression in Scheme. 3.3 External representations . 6 The introduction offers a brief history of the language and 3.4 Storage model . 7 of the report. 3.5 Proper tail recursion . 7 4 Expressions . 8 The first three chapters present the fundamental ideas of 4.1 Primitive expression types . 8 the language and describe the notational conventions used 4.2 Derived expression types . -

Meta-Tracing Makes a Fast Racket
Meta-tracing makes a fast Racket Carl Friedrich Bolz Tobias Pape Jeremy Siek Software Development Team Hasso-Plattner-Institut Indiana University King’s College London Potsdam [email protected] [email protected] [email protected] potsdam.de Sam Tobin-Hochstadt Indiana University [email protected] ABSTRACT 1. INTRODUCTION Tracing just-in-time (JIT) compilers record and optimize the instruc- Just-in-time (JIT) compilation has been applied to a wide variety tion sequences they observe at runtime. With some modifications, languages, with early examples including Lisp, APL, Basic, Fortran, a tracing JIT can perform well even when the executed program is Smalltalk, and Self [Aycock, 2003]. These days, JIT compilation itself an interpreter, an approach called meta-tracing. The advantage is mainstream; it is responsible for running both server-side Java of meta-tracing is that it separates the concern of JIT compilation applications [Paleczny et al., 2001] and client-side JavaScript appli- from language implementation, enabling the same JIT compiler to cations in web browsers [Hölttä, 2013]. be used with many different languages. The RPython meta-tracing Mitchell [1970] observed that one could obtain an instruction JIT compiler has enabled the efficient interpretation of several dy- sequence from an interpreter by recording its actions. The interpreter namic languages including Python (PyPy), Prolog, and Smalltalk. can then jump to this instruction sequence, this trace, when it returns In this paper we present initial findings in applying the RPython to interpret the same part of the program. For if-then-else statements, JIT to Racket. Racket comes from the Scheme family of program- there is a trace for only one branch. -

Functional SMT Solving with Z3 and Racket
Functional SMT Solving with Z3 and Racket Siddharth Agarwal∗y Amey Karkarey [email protected] [email protected] ∗Facebook Inc, yDepartment of Computer Science & Engineering Menlo Park, CA, USA Indian Institute of Technology Kanpur, India Abstract—Satisfiability Modulo Theories (SMT) solvers are can attack range from simple puzzles like Sudoku and n- powerful tools that can quickly solve complex constraints queens, to planning and scheduling, program analysis [8], involving Booleans, integers, first-order logic predicates, lists, whitebox fuzz testing [9] and bounded model checking [10]. and other data types. They have a vast number of potential Yet SMT solvers are only used by a small number of experts. It applications, from constraint solving to program analysis and isn’t hard to see why: the standard way for programs to interact verification. However, they are so complex to use that their power with SMT solvers like Z3 [4], Yices [5] and CVC3 [11] is via is inaccessible to all but experts in the field. We present an attempt to make using SMT solvers simpler by integrating the powerful but relatively arcane C APIs that require the users Z3 solver into a host language, Racket. The system defines a to know the particular solver’s internals. For example, here programmer’s interface in Racket that makes it easy to harness is a C program that asks Z3 whether the simple proposition the power of Z3 to discover solutions to logical constraints. The p ^ :p is satisfiable. interface, although in Racket, retains the structure and brevity Z3_config cfg = Z3_mk_config(); of the SMT-LIB format. -

Comparative Studies of 10 Programming Languages Within 10 Diverse Criteria
Department of Computer Science and Software Engineering Comparative Studies of 10 Programming Languages within 10 Diverse Criteria Jiang Li Sleiman Rabah Concordia University Concordia University Montreal, Quebec, Concordia Montreal, Quebec, Concordia [email protected] [email protected] Mingzhi Liu Yuanwei Lai Concordia University Concordia University Montreal, Quebec, Concordia Montreal, Quebec, Concordia [email protected] [email protected] COMP 6411 - A Comparative studies of programming languages 1/139 Sleiman Rabah, Jiang Li, Mingzhi Liu, Yuanwei Lai This page was intentionally left blank COMP 6411 - A Comparative studies of programming languages 2/139 Sleiman Rabah, Jiang Li, Mingzhi Liu, Yuanwei Lai Abstract There are many programming languages in the world today.Each language has their advantage and disavantage. In this paper, we will discuss ten programming languages: C++, C#, Java, Groovy, JavaScript, PHP, Schalar, Scheme, Haskell and AspectJ. We summarize and compare these ten languages on ten different criterion. For example, Default more secure programming practices, Web applications development, OO-based abstraction and etc. At the end, we will give our conclusion that which languages are suitable and which are not for using in some cases. We will also provide evidence and our analysis on why some language are better than other or have advantages over the other on some criterion. 1 Introduction Since there are hundreds of programming languages existing nowadays, it is impossible and inefficient -

The Grace Programming Language Draft Specification Version 0.3.1261" (2013)
Portland State University PDXScholar Computer Science Faculty Publications and Presentations Computer Science 2013 The Grace Programming Language Draft Specification ersionV 0.3.1261 Andrew P. Black Portland State University, [email protected] Kim B. Bruce James Noble Follow this and additional works at: https://pdxscholar.library.pdx.edu/compsci_fac Part of the Programming Languages and Compilers Commons Let us know how access to this document benefits ou.y Citation Details Black, Andrew P.; Bruce, Kim B.; and Noble, James, "The Grace Programming Language Draft Specification Version 0.3.1261" (2013). Computer Science Faculty Publications and Presentations. 111. https://pdxscholar.library.pdx.edu/compsci_fac/111 This Post-Print is brought to you for free and open access. It has been accepted for inclusion in Computer Science Faculty Publications and Presentations by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. The Grace Programming Language Draft Specification Version 0.3.1261 Andrew P. Black Kim B. Bruce James Noble August 14, 2013 1 Introduction This is a specification of the Grace Programming Language. This specifica- tion is notably incomplete, and everything is subject to change. In particular, this version does not address: • the library, especially collection syntax and collection literals • nested static type system (although we’ve made a start) • module system James Ishould write up from DYLA paperJ • metadata (Java’s @annotations, C] attributes, final, abstract etc) James Ishould add this tooJ Kim INeed to add syntax, but not necessarily details of which attributes are in language (yet)J • immutable data and pure methods. -
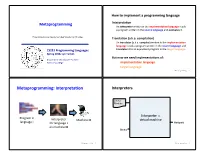
Metaprogramming: Interpretaaon Interpreters
How to implement a programming language Metaprogramming InterpretaAon An interpreter wriDen in the implementaAon language reads a program wriDen in the source language and evaluates it. These slides borrow heavily from Ben Wood’s Fall ‘15 slides. TranslaAon (a.k.a. compilaAon) An translator (a.k.a. compiler) wriDen in the implementaAon language reads a program wriDen in the source language and CS251 Programming Languages translates it to an equivalent program in the target language. Spring 2018, Lyn Turbak But now we need implementaAons of: Department of Computer Science Wellesley College implementaAon language target language Metaprogramming 2 Metaprogramming: InterpretaAon Interpreters Source Program Interpreter = Program in Interpreter Machine M virtual machine language L for language L Output on machine M Data Metaprogramming 3 Metaprogramming 4 Metaprogramming: TranslaAon Compiler C Source x86 Target Program C Compiler Program if (x == 0) { cmp (1000), $0 Program in Program in x = x + 1; bne L language A } add (1000), $1 A to B translator language B ... L: ... x86 Target Program x86 computer Output Interpreter Machine M Thanks to Ben Wood for these for language B Data and following pictures on machine M Metaprogramming 5 Metaprogramming 6 Interpreters vs Compilers Java Compiler Interpreters No work ahead of Lme Source Target Incremental Program Java Compiler Program maybe inefficient if (x == 0) { load 0 Compilers x = x + 1; ifne L } load 0 All work ahead of Lme ... inc See whole program (or more of program) store 0 Time and resources for analysis and opLmizaLon L: ... (compare compiled C to compiled Java) Metaprogramming 7 Metaprogramming 8 Compilers... whose output is interpreted Interpreters.. -

An Interpreter for a Novice-Oriented Programming Language With
An Interpreter for a Novice-Oriented Programming Language with Runtime Macros by Jeremy Daniel Kaplan Submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment of the requirements for the degree of Master of Engineering in Electrical Engineering and Computer Science at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY June 2017 ○c Jeremy Daniel Kaplan, MMXVII. All rights reserved. The author hereby grants to MIT permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part in any medium now known or hereafter created. Author................................................................ Department of Electrical Engineering and Computer Science May 12, 2017 Certified by. Adam Hartz Lecturer Thesis Supervisor Accepted by . Christopher Terman Chairman, Masters of Engineering Thesis Committee 2 An Interpreter for a Novice-Oriented Programming Language with Runtime Macros by Jeremy Daniel Kaplan Submitted to the Department of Electrical Engineering and Computer Science on May 12, 2017, in partial fulfillment of the requirements for the degree of Master of Engineering in Electrical Engineering and Computer Science Abstract In this thesis, we present the design and implementation of a new novice-oriented programming language with automatically hygienic runtime macros, as well as an interpreter framework for creating such languages. The language is intended to be used as a pedagogical tool for introducing basic programming concepts to introductory programming students. We designed it to have a simple notional machine and to be similar to other modern languages in order to ease a student’s transition into other programming languages. Thesis Supervisor: Adam Hartz Title: Lecturer 3 4 Acknowledgements I would like to thank every student and staff member of MIT’s 6.01 that I have worked with in the years I was involved in it. -

CSE341: Programming Languages Spring 2014 Unit 5 Summary Contents Switching from ML to Racket
CSE341: Programming Languages Spring 2014 Unit 5 Summary Standard Description: This summary covers roughly the same material as class and recitation section. It can help to read about the material in a narrative style and to have the material for an entire unit of the course in a single document, especially when reviewing the material later. Please report errors in these notes, even typos. This summary is not a sufficient substitute for attending class, reading the associated code, etc. Contents Switching from ML to Racket ...................................... 1 Racket vs. Scheme ............................................. 2 Getting Started: Definitions, Functions, Lists (and if) ...................... 2 Syntax and Parentheses .......................................... 5 Dynamic Typing (and cond) ....................................... 6 Local bindings: let, let*, letrec, local define ............................ 7 Top-Level Definitions ............................................ 9 Bindings are Generally Mutable: set! Exists ............................ 9 The Truth about cons ........................................... 11 Cons cells are immutable, but there is mcons ............................. 11 Introduction to Delayed Evaluation and Thunks .......................... 12 Lazy Evaluation with Delay and Force ................................. 13 Streams .................................................... 14 Memoization ................................................. 15 Macros: The Key Points ......................................... -

Haskell-Like S-Expression-Based Language Designed for an IDE
Department of Computing Imperial College London MEng Individual Project Haskell-Like S-Expression-Based Language Designed for an IDE Author: Supervisor: Michal Srb Prof. Susan Eisenbach June 2015 Abstract The state of the programmers’ toolbox is abysmal. Although substantial effort is put into the development of powerful integrated development environments (IDEs), their features often lack capabilities desired by programmers and target primarily classical object oriented languages. This report documents the results of designing a modern programming language with its IDE in mind. We introduce a new statically typed functional language with strong metaprogramming capabilities, targeting JavaScript, the most popular runtime of today; and its accompanying browser-based IDE. We demonstrate the advantages resulting from designing both the language and its IDE at the same time and evaluate the resulting environment by employing it to solve a variety of nontrivial programming tasks. Our results demonstrate that programmers can greatly benefit from the combined application of modern approaches to programming tools. I would like to express my sincere gratitude to Susan, Sophia and Tristan for their invaluable feedback on this project, my family, my parents Michal and Jana and my grandmothers Hana and Jaroslava for supporting me throughout my studies, and to all my friends, especially to Harry whom I met at the interview day and seem to not be able to get rid of ever since. ii Contents Abstract i Contents iii 1 Introduction 1 1.1 Objectives ........................................ 2 1.2 Challenges ........................................ 3 1.3 Contributions ...................................... 4 2 State of the Art 6 2.1 Languages ........................................ 6 2.1.1 Haskell ....................................