Time-Aware Ranking in Sport Social Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

BISPING: Barnett Needs to Push the Pace Vs. Nelson
FS1 UFC TONIGHT Show Quotes – 9/23/15 BISPING: Barnett Needs To Push The Pace Vs. Nelson Florian: “Uriah Hall Is Too Dangerous To Just Stand and Trade With” LOS ANGELES – UFC TONIGHT host Kenny Florian and guest host Michael Bisping break down the upcoming FS1 UFC FIGHT NIGHT: BARNETT VS. NELSON. Karyn Bryant and Ariel Helwani add reports. UFC TONIGHT guest host Michael Bisping on how Josh Barnett can beat Roy Nelson: “Josh needs to not get hit by the right hand of Roy. He needs to push the pace of the fight, move forward, and push Roy up against fence and brutalize him with knees and elbows like he did with Frank Mir. Most of his finishes came from the clinch position. He finishes fights against the fence. He did that against Frank Mir.” UFC TONIGHT host Kenny Florian on Barnett avoiding Nelson’s knock out power: “Josh doesn’t want to be on the outside where Roy’s right hand can get him. He wants to be on the inside. He’s been busy on the submission circuit. He’s dangerous on the mat and that’s where he wants to get Roy.” Bisping on how Nelson should fight Barnett: “What Roy can’t get is predictable. If he just tries to throw the big right hand, Barnett is going to see it coming. Roy has to mix up his striking. I’m not sure he’s going to go for takedowns. But he has to mix his striking. His right hand and left hooks, to keep Josh at bay.” Florian on Nelson mixing up his strikes: “The knock on Nelson is his lack of evolution. -
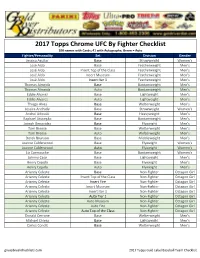
2017 Topps UFC Checklist
2017 Topps Chrome UFC By Fighter Checklist 100 names with Cards; 41 with Autographs; Green = Auto Fighter/Personality Set Division Gender Jessica Aguilar Base Strawweight Women's José Aldo Base Featherweight Men's José Aldo Insert Top of the Class Featherweight Men's José Aldo Insert Museum Featherweight Men's José Aldo Insert Iter 1 Featherweight Men's Thomas Almeida Base Bantamweight Men's Thomas Almeida Auto Bantamweight Men's Eddie Alvarez Base Lightweight Men's Eddie Alvarez Auto Lightweight Men's Thiago Alves Base Welterweight Men's Jessica Andrade Base Strawweight Women's Andrei Arlovski Base Heavyweight Men's Raphael Assunção Base Bantamweight Men's Joseph Benavidez Base Flyweight Men's Tom Breese Base Welterweight Men's Tom Breese Auto Welterweight Men's Derek Brunson Base Middleweight Men's Joanne Calderwood Base Flyweight Women's Joanne Calderwood Auto Flyweight Women's Liz Carmouche Base Bantamweight Women's Johnny Case Base Lightweight Men's Henry Cejudo Base Flyweight Men's Henry Cejudo Auto Flyweight Men's Arianny Celeste Base Non-Fighter Octagon Girl Arianny Celeste Insert Top of the Class Non-Fighter Octagon Girl Arianny Celeste Insert Fire Non-Fighter Octagon Girl Arianny Celeste Insert Museum Non-Fighter Octagon Girl Arianny Celeste Insert Iter 1 Non-Fighter Octagon Girl Arianny Celeste Auto Tier 1 Non-Fighter Octagon Girl Arianny Celeste Auto Museum Non-Fighter Octagon Girl Arianny Celeste Auto Fire Non-Fighter Octagon Girl Arianny Celeste Auto Top of the Class Non-Fighter Octagon Girl Donald Cerrone Base Welterweight -

Are Ufc Fighters Employees Or Independent Contractors?
Conklin Book Proof (Do Not Delete) 4/27/20 8:42 PM TWO CLASSIFICATIONS ENTER, ONE CLASSIFICATION LEAVES: ARE UFC FIGHTERS EMPLOYEES OR INDEPENDENT CONTRACTORS? MICHAEL CONKLIN* I. INTRODUCTION The fighters who compete in the Ultimate Fighting Championship (“UFC”) are currently classified as independent contractors. However, this classification appears to contradict the level of control that the UFC exerts over its fighters. This independent contractor classification severely limits the fighters’ benefits, workplace protections, and ability to unionize. Furthermore, the friendship between UFC’s brash president Dana White and President Donald Trump—who is responsible for making appointments to the National Labor Relations Board (“NLRB”)—has added a new twist to this issue.1 An attorney representing a former UFC fighter claimed this friendship resulted in a biased NLRB determination in their case.2 This article provides a detailed examination of the relationship between the UFC and its fighters, the relevance of worker classifications, and the case law involving workers in related fields. Finally, it performs an analysis of the proper classification of UFC fighters using the Internal Revenue Service (“IRS”) Twenty-Factor Test. II. UFC BACKGROUND The UFC is the world’s leading mixed martial arts (“MMA”) promotion. MMA is a one-on-one combat sport that combines elements of different martial arts such as boxing, judo, wrestling, jiu-jitsu, and karate. UFC bouts always take place in the trademarked Octagon, which is an eight-sided cage.3 The first UFC event was held in 1993 and had limited rules and limited fighter protections as compared to the modern-day events.4 UFC 15 was promoted as “deadly” and an event “where anything can happen and probably will.”6 The brutality of the early UFC events led to Senator John * Powell Endowed Professor of Business Law, Angelo State University. -

Dos Santos Has a Chance to Grow, Develop from Loss
dos Santos has a chance to grow, develop from loss Author : Robert D. Cobb Former UFC heavyweight champion Junior dos Santos learned a lot in his title fight with Cain Velasquez at UFC 155. I hope dos Santos paid attention because Velasquez put the blueprint to regaining his title right in front of him. Velasquez dominated from start to finish -- he won every round convincingly. Dos Santos learned he needs to become a better all-around fighter -- Velasquez is a better grappler, wrestler and, Saturday, was a better striker. Velasquez was able to mix up his strikes to take dos Santos down at will. The latter was the most-surprising; until this fight, dos Santos was widely-regarded as the best striker in the division. He has 10 victories by TKO or KO. Simply put, Velasquez proved himself the better fighter by showing more diversity in his game. Against most heavyweight fighters dos Santos doesn't need to be great at more than one aspect of the cage but against top-level fighters, heavy hands aren't always enough. He became champion without becoming a great wrestler -- partly because the depth of skill set at heavyweight is not as good as other divisions and partly because his striking is so dynamic. He showed that in the first fight with Velasquez, when he knocked him out early in the first round. 1 / 2 In a bout with talented submission artist Frank Mir and a separate fight with Roy Nelson, dos Santos stalked them around the ring with his fists. This time, Velasquez did the stalking. -

Musclepharm Sponsoring UFC Champion Anderson Silva and Other Fighters at Saturday's UFC 117 Pay-Per-View
August 6, 2010 MusclePharm Sponsoring UFC Champion Anderson Silva and Other Fighters at Saturday's UFC 117 Pay-Per-View Eight to Ten Million People Expected to Watch the Fight Worldwide DENVER-- MusclePharm(R) Corporation (OTCBB:MSLP), one of the fast-growing nutritional supplement companies in the United States, with a proprietary formulation used in eight performance products, will be sponsoring several Ultimate Fighting Championship (UFC) superstars during Saturday's UFC pay-per-view, UFC 117: Silva vs. Sonnen. Eight to ten million people are expected to watch the fight worldwide and the MusclePharm logo and publicly traded stock symbol, MSLP, will be displayed on each of the athletes' shorts and hats as well as a ring-side banner. Among the fighters sporting MusclePharm on Saturday include middleweight champion Anderson Silva, lightweight Clay Guida and heavyweight Junior Dos Santos. Each of the fighters will be appearing on the main television card. Silva will be fighting in the main event of the heavily-anticipated pay-per-view card, where he will square off against Chael Sonnen. The explosive middleweight champion is considered the top pound-for-pound fighter in mixed martial arts and the Brazilian native is undefeated in all 11 of his UFC fights, dating back to 2006. He last defended his belt at UFC 112 in Abu Dhabi, earning a victory in the main event. Thanks to his dynamic fighting style and incredible athletic ability, Silva has become an international superstar while also promoting the MusclePharm brand. That immense popularity and exciting fighting style has help expand the MusclePharm brand to gain visibility on a worldwide level. -

Mixed Martial Arts
COMPILED BY : - GAUTAM SINGH STUDY MATERIAL – SPORTS 0 7830294949 Mixed Martial Arts - Overview Mixed Martial Arts is an action-packed sport filled with striking and grappling techniques from a variety of combat sports and martial arts. During the early 1900s, many different mixed-style competitions were held throughout Europe, Japan and the Pacific Rim. CV Productions Inc. showed the first regulated MMA league in the US in 1980 called the Tough Guy Contest, which was later renamed as Battle of the Superfighters. In 1983, the Pennsylvania State Senate passed a bill which prohibited the sport. However, in 1993, it was brought back into the US TVs by the Gracie family who found the Ultimate Fighting Championships (UFC) which most of us have probably heard about on our TVs. These shows were promoted as a competition which intended in finding the most effective martial arts in an unarmed combat situation. The competitors fought each other with only a few rules controlling the fight. Later on, additional rules were established ensuring a little more safety for the competitors, although it still is quite life-threatening. A Brief History of Mixed Martial Arts THANKS FOR READING – VISIT OUR WEBSITE www.educatererindia.com COMPILED BY : - GAUTAM SINGH STUDY MATERIAL – SPORTS 0 7830294949 The history of MMA dates back to the Greek era. There was an ancient Olympic combat sport called as Pankration which had features of combination of grappling and striking skills. Later, this sport was passed on to the Romans. An early example of MMA is Greco-Roman Wrestling (GRW) in the late 1880s, where players fought without few to almost zero safety rules. -

Football Release Gomountaineers.Com Oct. 8, 2014
Garrett Finke Sports Information Director [email protected] Office: (970) 943-2831 Cell: (719) 334-2310 Football Release GoMountaineers.com Oct. 8, 2014 Game Notes GAME 6: WESTERN STATE VS BLACK HILLS STATE Start of Something Good... The Mountaineers began the season 2-2 Records: Western State (2-3 / 1-2 RMAC), for the first time since 2008. Black Hills State (2-3 / 1-2 RMAC) Western’s two wins this season tie the Location: Mountaineer Bowl (Capacity 4,000) season total from 2013. Radio: KEJJ 98.3 FM Gunnison. The last time Western had three wins in a season was 2009. Webcast: America One Sports (http://www.ameri- caonesports.com/partner_members.asp?id=55) If Western defeats BHSU it will be the first time the Mountaineers begin a season 3-3 Polls: Black Hills State / Western State - AFCA: since 2009. NR / NR; D2Football.com: NR / NR Coaches: Western State’s Jas Bains (5th season Hall of Fame Game... at Western State, 4th season as head coach); Saturday’s game will be the 20th Black Hills State’s John Reiners (6th season at Mountaineer Sports Hall of Fame game in Black Hills State and 3rd as head coach) Western’s history. Series History: Saturday’s game will mark the In the past six MSHOF games, Western is 3rd meeting between the two schools. Black Hills 3-3. State has won the previous two meetings. The Mountaineers won last year’s MSHOF Last Meeting: Last season, the game against game 33-27 over New Mexico Highlands Black Hills State was delayed until the final week University. -

Why Is This Called a Sport? Blood Gore Ultimate Fighting Choke Punch Kick Pummel Fighting Choke Punch Kick Pummel
WHY IS THIS CALLED A SPORT? BLOOD GORE ULTIMATE FIGHTING CHOKE PUNCH KICK PUMMEL FIGHTING CHOKE PUNCH KICK PUMMEL UFC capitalizes on the primal urge to watch men beat each other senseless, and is now worth $1.5-billion after being bought for $2-million eight years ago. James Christie explores the world inside and outside the octagon. From Saturday's Globe and Mail Last updated on Monday, Jul. 20, 2009 04:09AM EDT The Ultimate Fighting Championship is the sports world's version of a traffic accident. It's a bloody, brutal, violent spectacle, and people can't help but look. Learned social behaviour tells us it's uncivilized to watch as men pound each other into pâté inside an octagonal cage, let alone cheer madly as a losing combatant turns into a hematoma. Yet for the broadcast of UFC 100 from Las Vegas last weekend, young men lined up five deep in upscale downtown watering holes - not low-end beer joints - to scream and howl as combatants were pummelled and choked into unconsciousness. During one match, fighter Dan Henderson knocked opponent Michael Bisping unconscious and then - "Just to shut him up a little," Henderson said later - raised himself on his toes before dropping down to lay another blow on Bisping's still body. "It's a phenomenon that allows people to take part vicariously in the type of behaviour that, on the street, would get you a jail sentence," says Geoff Smith, a cultural historian and retired Queen's University professor. Whatever the draw, "like crack, it's growing exponentially," says Joel Gerson, five- time Canadian jujitsu champion and owner of Revolution MMA, a mixed martial arts club in Toronto. -

MMA RANKING Last Updated Friday, 27 November 2009 14:55
MMA RANKING Last Updated Friday, 27 November 2009 14:55 MMA RANKINGS Heavyweight Last update: November 19, 2009 Read more here: bloodyelbow.com Rank Fighter % Promotion Last Rank 1 Fedor Emelianenko 100 M-1 Global/Strikeforce 1 2 Brock Lesnar 96 UFC 2 3 Antonio Rodrigo Nogueira88 UFC 3 4 Frank Mir 86 UFC 4 5 Junior dos Santos 74 UFC 7 6 Josh Barnett 74 WVR 5 7 Cain Velasquez 67 UFC 11 8 Brett Rogers 65 Strikeforce 8 9 Shane Carwin 62 UFC 6 10 Fabricio Werdum 50 Strikeforce 13 11 Alistair Overeem 50 DREAM/Strikeforce 11 12 Randy Couture 49 UFC 9 13 Andrei Arlovski 44 ??? 10 14 Jeff Monson 27 Free Agent 14 15 Tim Sylvia 26 Adrenaline 18 16 Gabriel Gonzaga 24 UFC 15 17 Cheick Kongo 23 UFC 16 18 Antonio Silva 22 WVR/Strikeforce 22 19 Pedro Rizzo 21 Free Agent 19 19 Marcio Cruz 21 Art of Fighting 23 21 Ben Rothwell 21 UFC 17 22 Gilbert Yvel 20 Fight Force International24 22 Ray Mercer 20 Adrenaline 26 22 Semmy Schilt 20 K-1 24 25 Aleksander Emelianenko19 ProFC 20 25 Roy Nelson 19 UFC 21 Rankings compiled by Richard Wade. 1 / 3 MMA RANKING Last Updated Friday, 27 November 2009 14:55 November was supposed to be the most epic month in heavyweight MMA since August. Both #1 Fedor Emelianenko and #2 Brock Lesnar were set to fight. But just as in August, fate intervened and only one of the two titans of the division actually competed. In August it was the failure of #6 Josh Barnett to meet the licensing requirements of the CSAC and the resulting collapse of Affliction as a fight promotion that prevented Fedor from fighting. -

Legalization of Cage Fighting in New York Dear State Assembly Member
January 10, 2012 Re: Legalization of cage fighting in New York Dear State Assembly Member: We are writing you to raise concerns about renewed efforts by Zuffa LLC, the parent company of the Ultimate Fighting Championship (UFC), to legalize cage fighting in the State of New York. You are no doubt aware that the State of New York banned cage fighting in 1997. We urge you to continue to uphold the ban on cage fighting, given that the UFC, the largest promoter of cage fighting events in the U.S., has failed to demonstrate that it is willing to ensure its fighters behave in a socially responsible way, even as the company expressly markets its fights and fighters to children. We believe that the UFC contributes to a culture of violence against women, and lesbian, gay, bisexual and transgender (LGBT) people. Children, in particular, should not be exposed to the homophobic, misogynistic and violent language that has been permitted by the UFC. Please see the following website, UFC = Unfit For Children (www.UnfitForChildren.org), for more information. Some examples of anti-gay and anti-women statements by people associated with the UFC include the following: In videos, UFC light heavyweight Quinton “Rampage” Jackson repeatedly urged Japanese fans to repeat an anti-gay slur.1 The fans, who do not appear to understand English, repeated the anti-gay slur at Jackson’s urging. In one video, Jackson instructed a Japanese man to say, “Goodbye, I want you to piss on my face.”2 Recently, a UFC fighter taunted his opponent by threatening to act like former Penn State assistant football coach Jerry Sandusky, who has been charged with 52 counts of molesting boys. -

Ufc® Debuts in Wichita with a March 9Th Showdown Between Top-Ranked Heavyweight Knockout Artists, Exclusively on Espn+
UFC® DEBUTS IN WICHITA WITH A MARCH 9TH SHOWDOWN BETWEEN TOP-RANKED HEAVYWEIGHT KNOCKOUT ARTISTS, EXCLUSIVELY ON ESPN+ Las Vegas – UFC® heads to Wichita, Kan. for the first time in the promotion’s history and brings with it a showcase matchup in the heavyweight division. Recent title challenger and No.2- ranked Derrick Lewis looks to re-insert himself into the championship conversation by landing another signature KO against a former UFC heavyweight champion and fellow knockout artist No.7-ranked Junior Dos Santos. UFC FIGHT NIGHT ON ESPN+®: LEWIS vs. DOS SANTOS will stream live from INTRUST Bank Arena exclusively on ESPN+ at 7 p.m. CT/8 p.m. ET on Saturday, March 9, with the ESPN+ prelims kicking off the evening at 4 p.m. CT/5 p.m. ET. Doors open at 3 p.m. CT/4 p.m. ET. All UFC live events on ESPN+ will be available in English and Spanish. Coming off the first title shot of his UFC career against current No.1-ranked pound-for-pound fighter in the world Daniel Cormier, Lewis (21-6, fighting out of Houston, Texas) aims to get back to his winning ways with another spectacular knockout. Tied for having the most KOs in UFC heavyweight history, Lewis won nine of his last 10 bouts leading up to his title shot, including victories over Alexander Volkov, Francis Ngannou and Travis Browne. Lewis now intends to add the first ex-UFC champion to his KO list and earn the fifth post-fight award bonus in his last seven fights. -

Dos Santos-Carwin Fight on Indigo
Media contact only: Elodie Girardin-Lajoie Specialist, Media and Analysts Corporate Communications Telephone: 514 380-7772 Mobile: 514 516-7772 PRESS RELEASE For immediate release Live from Vancouver’s Rogers Arena on June 11 Dos Santos-Carwin fight on Indigo Montréal, June 9, 2011 – At 9 p.m. on Saturday, June 11, live from the Rogers Arena in Vancouver, Indigo will bring mixed martial fans another treat: UFC 131, featuring Junior Dos Santos of Brazil versus Shane Carwin of the U.S. Junior Dos Santos (12-1-0) was originally scheduled to face Brock Lesnar in the headline bout but Lesnar was sidelined by diverticulitis and replaced by Shane Carwin (12-1-0). The winner will take on current UFC heavyweight champion Cain Velasquez of the U.S. There are four other match-ups on the main card, including Peruvian-born Kenny Florian of the U.S. (14-5-1) against Diego Nunez of Brazil (16-1-0). The last time the two slugged it out was in an episode of the MMA Live television series, with Nunez emerging as the winner. In the other main events, Norway’s Jon Olav Einemo (6-1-0) faces Dave Herman of the U.S. (20-2-0), Demian Maia of Brazil (14-2-0) battles Mark Munos of the U.S. (10-2-0) and Donald Cerrone of the U.S. (14-3-0) spars with Vagner Rocha of Brazil (96-1-0). Fans will be pleased to know that well-known Québec mixed martial artist Patrick Coté will do the honours as colour commentator for the night while Jean-Paul Chartrand Jr.