Formal Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 2 Introduction to Classical Propositional
CHAPTER 2 INTRODUCTION TO CLASSICAL PROPOSITIONAL LOGIC 1 Motivation and History The origins of the classical propositional logic, classical propositional calculus, as it was, and still often is called, go back to antiquity and are due to Stoic school of philosophy (3rd century B.C.), whose most eminent representative was Chryssipus. But the real development of this calculus began only in the mid-19th century and was initiated by the research done by the English math- ematician G. Boole, who is sometimes regarded as the founder of mathematical logic. The classical propositional calculus was ¯rst formulated as a formal ax- iomatic system by the eminent German logician G. Frege in 1879. The assumption underlying the formalization of classical propositional calculus are the following. Logical sentences We deal only with sentences that can always be evaluated as true or false. Such sentences are called logical sentences or proposi- tions. Hence the name propositional logic. A statement: 2 + 2 = 4 is a proposition as we assume that it is a well known and agreed upon truth. A statement: 2 + 2 = 5 is also a proposition (false. A statement:] I am pretty is modeled, if needed as a logical sentence (proposi- tion). We assume that it is false, or true. A statement: 2 + n = 5 is not a proposition; it might be true for some n, for example n=3, false for other n, for example n= 2, and moreover, we don't know what n is. Sentences of this kind are called propositional functions. We model propositional functions within propositional logic by treating propositional functions as propositions. -

Theory of Computer Science
Theory of Computer Science MODULE-1 Alphabet A finite set of symbols is denoted by ∑. Language A language is defined as a set of strings of symbols over an alphabet. Language of a Machine Set of all accepted strings of a machine is called language of a machine. Grammar Grammar is the set of rules that generates language. CHOMSKY HIERARCHY OF LANGUAGES Type 0-Language:-Unrestricted Language, Accepter:-Turing Machine, Generetor:-Unrestricted Grammar Type 1- Language:-Context Sensitive Language, Accepter:- Linear Bounded Automata, Generetor:-Context Sensitive Grammar Type 2- Language:-Context Free Language, Accepter:-Push Down Automata, Generetor:- Context Free Grammar Type 3- Language:-Regular Language, Accepter:- Finite Automata, Generetor:-Regular Grammar Finite Automata Finite Automata is generally of two types :(i)Deterministic Finite Automata (DFA)(ii)Non Deterministic Finite Automata(NFA) DFA DFA is represented formally by a 5-tuple (Q,Σ,δ,q0,F), where: Q is a finite set of states. Σ is a finite set of symbols, called the alphabet of the automaton. δ is the transition function, that is, δ: Q × Σ → Q. q0 is the start state, that is, the state of the automaton before any input has been processed, where q0 Q. F is a set of states of Q (i.e. F Q) called accept states or Final States 1. Construct a DFA that accepts set of all strings over ∑={0,1}, ending with 00 ? 1 0 A B S State/Input 0 1 1 A B A 0 B C A 1 * C C A C 0 2. Construct a DFA that accepts set of all strings over ∑={0,1}, not containing 101 as a substring ? 0 1 1 A B State/Input 0 1 S *A A B 0 *B C B 0 0,1 *C A R C R R R R 1 NFA NFA is represented formally by a 5-tuple (Q,Σ,δ,q0,F), where: Q is a finite set of states. -

COMPSCI 501: Formal Language Theory Insights on Computability Turing Machines Are a Model of Computation Two (No Longer) Surpris
Insights on Computability Turing machines are a model of computation COMPSCI 501: Formal Language Theory Lecture 11: Turing Machines Two (no longer) surprising facts: Marius Minea Although simple, can describe everything [email protected] a (real) computer can do. University of Massachusetts Amherst Although computers are powerful, not everything is computable! Plus: “play” / program with Turing machines! 13 February 2019 Why should we formally define computation? Must indeed an algorithm exist? Back to 1900: David Hilbert’s 23 open problems Increasingly a realization that sometimes this may not be the case. Tenth problem: “Occasionally it happens that we seek the solution under insufficient Given a Diophantine equation with any number of un- hypotheses or in an incorrect sense, and for this reason do not succeed. known quantities and with rational integral numerical The problem then arises: to show the impossibility of the solution under coefficients: To devise a process according to which the given hypotheses or in the sense contemplated.” it can be determined in a finite number of operations Hilbert, 1900 whether the equation is solvable in rational integers. This asks, in effect, for an algorithm. Hilbert’s Entscheidungsproblem (1928): Is there an algorithm that And “to devise” suggests there should be one. decides whether a statement in first-order logic is valid? Church and Turing A Turing machine, informally Church and Turing both showed in 1936 that a solution to the Entscheidungsproblem is impossible for the theory of arithmetic. control To make and prove such a statement, one needs to define computability. In a recent paper Alonzo Church has introduced an idea of “effective calculability”, read/write head which is equivalent to my “computability”, but is very differently defined. -

Use Formal and Informal Language in Persuasive Text
Author’S Craft Use Formal and Informal Language in Persuasive Text 1. Focus Objectives Explain Using Formal and Informal Language In this mini-lesson, students will: Say: When I write a persuasive letter, I want people to see things my way. I use • Learn to use both formal and different kinds of language to gain support. To connect with my readers, I use informal language in persuasive informal language. Informal language is conversational; it sounds a lot like the text. way we speak to one another. Then, to make sure that people believe me, I also use formal language. When I use formal language, I don’t use slang words, and • Practice using formal and informal I am more objective—I focus on facts over opinions. Today I’m going to show language in persuasive text. you ways to use both types of language in persuasive letters. • Discuss how they can apply this strategy to their independent writing. Model How Writers Use Formal and Informal Language Preparation Display the modeling text on chart paper or using the interactive whiteboard resources. Materials Needed • Chart paper and markers 1. As the parent of a seventh grader, let me assure you this town needs a new • Interactive whiteboard resources middle school more than it needs Old Oak. If selling the land gets us a new school, I’m all for it. Advanced Preparation 2. Last month, my daughter opened her locker and found a mouse. She was traumatized by this experience. She has not used her locker since. If you will not be using the interactive whiteboard resources, copy the Modeling Text modeling text and practice text onto chart paper prior to the mini-lesson. -

Cs 61A/Cs 98-52
CS 61A/CS 98-52 Mehrdad Niknami University of California, Berkeley Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 1 / 23 Something like this? (Is this good?) def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ j] is_match= False break if is_match: return i What if you were looking for a pattern? Like an email address? Motivation How would you find a substring inside a string? Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 2 / 23 def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ j] is_match= False break if is_match: return i What if you were looking for a pattern? Like an email address? Motivation How would you find a substring inside a string? Something like this? (Is this good?) Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 2 / 23 What if you were looking for a pattern? Like an email address? Motivation How would you find a substring inside a string? Something like this? (Is this good?) def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ j] is_match= False break if is_match: return i Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 2 / 23 Motivation How would you find a substring inside a string? Something like this? (Is this good?) def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ -

Thinking Recursively Part Four
Thinking Recursively Part Four Announcements ● Assignment 2 due right now. ● Assignment 3 out, due next Monday, April 30th at 10:00AM. ● Solve cool problems recursively! ● Sharpen your recursive skillset! A Little Word Puzzle “What nine-letter word can be reduced to a single-letter word one letter at a time by removing letters, leaving it a legal word at each step?” Shrinkable Words ● Let's call a word with this property a shrinkable word. ● Anything that isn't a word isn't a shrinkable word. ● Any single-letter word is shrinkable ● A, I, O ● Any multi-letter word is shrinkable if you can remove a letter to form a word, and that word itself is shrinkable. ● So how many shrinkable words are there? Recursive Backtracking ● The function we wrote last time is an example of recursive backtracking. ● At each step, we try one of many possible options. ● If any option succeeds, that's great! We're done. ● If none of the options succeed, then this particular problem can't be solved. Recursive Backtracking if (problem is sufficiently simple) { return whether or not the problem is solvable } else { for (each choice) { try out that choice. if it succeeds, return success. } return failure } Failure in Backtracking S T A R T L I N G Failure in Backtracking S T A R T L I N G S T A R T L I G Failure in Backtracking S T A R T L I N G S T A R T L I G Failure in Backtracking S T A R T L I N G Failure in Backtracking S T A R T L I N G S T A R T I N G Failure in Backtracking S T A R T L I N G S T A R T I N G S T R T I N G Failure in Backtracking S T A R T L I N G S T A R T I N G S T R T I N G Failure in Backtracking S T A R T L I N G S T A R T I N G Failure in Backtracking S T A R T L I N G S T A R T I N G S T A R I N G Failure in Backtracking ● Returning false in recursive backtracking does not mean that the entire problem is unsolvable! ● Instead, it just means that the current subproblem is unsolvable. -

Midterm Study Sheet for CS3719 Regular Languages and Finite
Midterm study sheet for CS3719 Regular languages and finite automata: • An alphabet is a finite set of symbols. Set of all finite strings over an alphabet Σ is denoted Σ∗.A language is a subset of Σ∗. Empty string is called (epsilon). • Regular expressions are built recursively starting from ∅, and symbols from Σ and closing under ∗ Union (R1 ∪ R2), Concatenation (R1 ◦ R2) and Kleene Star (R denoting 0 or more repetitions of R) operations. These three operations are called regular operations. • A Deterministic Finite Automaton (DFA) D is a 5-tuple (Q, Σ, δ, q0,F ), where Q is a finite set of states, Σ is the alphabet, δ : Q × Σ → Q is the transition function, q0 is the start state, and F is the set of accept states. A DFA accepts a string if there exists a sequence of states starting with r0 = q0 and ending with rn ∈ F such that ∀i, 0 ≤ i < n, δ(ri, wi) = ri+1. The language of a DFA, denoted L(D) is the set of all and only strings that D accepts. • Deterministic finite automata are used in string matching algorithms such as Knuth-Morris-Pratt algorithm. • A language is called regular if it is recognized by some DFA. • ‘Theorem: The class of regular languages is closed under union, concatenation and Kleene star operations. • A non-deterministic finite automaton (NFA) is a 5-tuple (Q, Σ, δ, q0,F ), where Q, Σ, q0 and F are as in the case of DFA, but the transition function δ is δ : Q × (Σ ∪ {}) → P(Q). -

Regular Languages and Finite Automata for Part IA of the Computer Science Tripos
N Lecture Notes on Regular Languages and Finite Automata for Part IA of the Computer Science Tripos Prof. Andrew M. Pitts Cambridge University Computer Laboratory c 2012 A. M. Pitts Contents Learning Guide ii 1 Regular Expressions 1 1.1 Alphabets,strings,andlanguages . .......... 1 1.2 Patternmatching................................. .... 4 1.3 Somequestionsaboutlanguages . ....... 6 1.4 Exercises....................................... .. 8 2 Finite State Machines 11 2.1 Finiteautomata .................................. ... 11 2.2 Determinism, non-determinism, and ε-transitions. .. .. .. .. .. .. .. .. .. 14 2.3 Asubsetconstruction . .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..... 17 2.4 Summary ........................................ 20 2.5 Exercises....................................... .. 20 3 Regular Languages, I 23 3.1 Finiteautomatafromregularexpressions . ............ 23 3.2 Decidabilityofmatching . ...... 28 3.3 Exercises....................................... .. 30 4 Regular Languages, II 31 4.1 Regularexpressionsfromfiniteautomata . ........... 31 4.2 Anexample ....................................... 32 4.3 Complementand intersectionof regularlanguages . .............. 34 4.4 Exercises....................................... .. 36 5 The Pumping Lemma 39 5.1 ProvingthePumpingLemma . .... 40 5.2 UsingthePumpingLemma . ... 41 5.3 Decidabilityoflanguageequivalence . ........... 44 5.4 Exercises....................................... .. 45 6 Grammars 47 6.1 Context-freegrammars . ..... 47 6.2 Backus-NaurForm ................................ -

Chapter 6 Formal Language Theory
Chapter 6 Formal Language Theory In this chapter, we introduce formal language theory, the computational theories of languages and grammars. The models are actually inspired by formal logic, enriched with insights from the theory of computation. We begin with the definition of a language and then proceed to a rough characterization of the basic Chomsky hierarchy. We then turn to a more de- tailed consideration of the types of languages in the hierarchy and automata theory. 6.1 Languages What is a language? Formally, a language L is defined as as set (possibly infinite) of strings over some finite alphabet. Definition 7 (Language) A language L is a possibly infinite set of strings over a finite alphabet Σ. We define Σ∗ as the set of all possible strings over some alphabet Σ. Thus L ⊆ Σ∗. The set of all possible languages over some alphabet Σ is the set of ∗ all possible subsets of Σ∗, i.e. 2Σ or ℘(Σ∗). This may seem rather simple, but is actually perfectly adequate for our purposes. 6.2 Grammars A grammar is a way to characterize a language L, a way to list out which strings of Σ∗ are in L and which are not. If L is finite, we could simply list 94 CHAPTER 6. FORMAL LANGUAGE THEORY 95 the strings, but languages by definition need not be finite. In fact, all of the languages we are interested in are infinite. This is, as we showed in chapter 2, also true of human language. Relating the material of this chapter to that of the preceding two, we can view a grammar as a logical system by which we can prove things. -
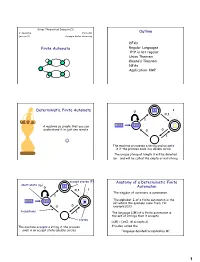
Deterministic Finite Automata 0 0,1 1
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -

Axiomatic Set Teory P.D.Welch
Axiomatic Set Teory P.D.Welch. August 16, 2020 Contents Page 1 Axioms and Formal Systems 1 1.1 Introduction 1 1.2 Preliminaries: axioms and formal systems. 3 1.2.1 The formal language of ZF set theory; terms 4 1.2.2 The Zermelo-Fraenkel Axioms 7 1.3 Transfinite Recursion 9 1.4 Relativisation of terms and formulae 11 2 Initial segments of the Universe 17 2.1 Singular ordinals: cofinality 17 2.1.1 Cofinality 17 2.1.2 Normal Functions and closed and unbounded classes 19 2.1.3 Stationary Sets 22 2.2 Some further cardinal arithmetic 24 2.3 Transitive Models 25 2.4 The H sets 27 2.4.1 H - the hereditarily finite sets 28 2.4.2 H - the hereditarily countable sets 29 2.5 The Montague-Levy Reflection theorem 30 2.5.1 Absoluteness 30 2.5.2 Reflection Theorems 32 2.6 Inaccessible Cardinals 34 2.6.1 Inaccessible cardinals 35 2.6.2 A menagerie of other large cardinals 36 3 Formalising semantics within ZF 39 3.1 Definite terms and formulae 39 3.1.1 The non-finite axiomatisability of ZF 44 3.2 Formalising syntax 45 3.3 Formalising the satisfaction relation 46 3.4 Formalising definability: the function Def. 47 3.5 More on correctness and consistency 48 ii iii 3.5.1 Incompleteness and Consistency Arguments 50 4 The Constructible Hierarchy 53 4.1 The L -hierarchy 53 4.2 The Axiom of Choice in L 56 4.3 The Axiom of Constructibility 57 4.4 The Generalised Continuum Hypothesis in L. -
6.045 Final Exam Name
6.045J/18.400J: Automata, Computability and Complexity Prof. Nancy Lynch 6.045 Final Exam May 20, 2005 Name: • Please write your name on each page. • This exam is open book, open notes. • There are two sheets of scratch paper at the end of this exam. • Questions vary substantially in difficulty. Use your time accordingly. • If you cannot produce a full proof, clearly state partial results for partial credit. • Good luck! Part Problem Points Grade Part I 1–10 50 1 20 2 15 3 25 Part II 4 15 5 15 6 10 Total 150 final-1 Name: Part I Multiple Choice Questions. (50 points, 5 points for each question) For each question, any number of the listed answersClearly may place be correct. an “X” in the box next to each of the answers that you are selecting. Problem 1: Which of the following are true statements about regular and nonregular languages? (All lan guages are over the alphabet{0, 1}) IfL1 ⊆ L2 andL2 is regular, thenL1 must be regular. IfL1 andL2 are nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is nonregular, then the complementL 1 must of also be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is regular, thenL1 ∪ L2 must be nonregular. Problem 2: Which of the following are guaranteed to be regular languages ? ∗ L2 = {ww : w ∈{0, 1}}. L2 = {ww : w ∈ L1}, whereL1 is a regular language. L2 = {w : ww ∈ L1}, whereL1 is a regular language. L2 = {w : for somex,| w| = |x| andwx ∈ L1}, whereL1 is a regular language.