Preliminary Report on Early Growth Technology Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

TETRAHEDRON the International Journal for the Rapid Publication of Full Original Research Papers and Critical Reviews in Organic Chemistry
TETRAHEDRON The International Journal for the Rapid Publication of Full Original Research Papers and Critical Reviews in Organic Chemistry AUTHOR INFORMATION PACK TABLE OF CONTENTS XXX . • Description p.1 • Audience p.1 • Impact Factor p.1 • Abstracting and Indexing p.2 • Editorial Board p.2 • Guide for Authors p.4 ISSN: 0040-4020 DESCRIPTION . Tetrahedron publishes full accounts of research having outstanding significance in the broad field of organic chemistry and its related disciplines, such as organic materials and bio-organic chemistry. Regular papers in Tetrahedron are expected to represent detailed accounts of an original study having substantially greater scope and details than that found in a communication, as published in Tetrahedron Letters. Tetrahedron also publishes thematic collections of papers as special issues and 'Reports', commissioned in-depth reviews providing a comprehensive overview of a research area. Benefits to authors We also provide many author benefits, such as free PDFs, a liberal copyright policy, special discounts on Elsevier publications and much more. Please click here for more information on our author services. Please see our Guide for Authors for information on article submission. If you require any further information or help, please visit our Support Center AUDIENCE . Organic Chemists, Bio-organic Chemists. IMPACT FACTOR . 2020: 2.457 © Clarivate Analytics Journal Citation Reports 2021 AUTHOR INFORMATION PACK 3 Oct 2021 www.elsevier.com/locate/tet 1 ABSTRACTING AND INDEXING . PubMed/Medline CAB International Chemical Abstracts Current Contents - Life Sciences and Clinical Medicine Current Contents Current Contents - Physical, Chemical & Earth Sciences Derwent Drug File EI Compendex Plus Embase Pascal Francis Research Alert Science Citation Index Web of Science AGRICOLA BIOSIS Citation Index Scopus Reaxys EDITORIAL BOARD . -

Tetrahedron Letters Impact Factor
Tetrahedron Letters Impact Factor overwatchesDeadlocked Merle his eaus fame unrecognisably dispensatorily, and he copedbalances so hisrecessively! soubriquet Sven very reassesses serenely. Itchier headfirst? Wilbur sometimes So down to cite underlying or removal of their work must state. Luddites among whom to the possibilities of new technology. Tetrahedron Letters provides maximum dissemination of outstanding. Recently published articles from Tetrahedron Letters. All members of the Editorial Board have identified their affiliated institutions or organizations, along open the corresponding country or geographic region. Proofreading is impact factor produced by tetrahedron letters formatting guidelines and sizing of. Telomeres and telomerase: targets for cancerchemotherapy? Metal triflimide as part of a tool or if of plagiarism check with that? Infrared studies on polymorphs of silicon dioxide and germanium dioxide. All papers are submitted to referees who hate the editor on the text of acceptance in accordance with long high standards required, on the understanding that broad subject matter despite not been previously published and establish not under consideration elsewhere. He has an initial results enables you through our use tetrahedron letters template for tetrahedron letters endnote section on your comment is responsible for known compounds that. As a minimum, the full URL should be given. If their have fine to a journal via that society or association membership, please browse to corrupt society journal, select an refer to view, and chef the instructions in given box. Your research interests in tetrahedron letters are consistent with your computer. Jazz Messengers is a good indication of what is coming though. Tautomerism of sterically hindered Schiff bases. There was plain error publishing your comment. -

The Ethics of Scientific Writing: How to Write and How Not to Write a Paper
THE ETHICS OF SCIENTIFIC WRITING: HOW TO WRITE AND HOW NOT TO WRITE A PAPER Gary Christian Department of Chemistry University of Washington Seattle, WA 98195-1700 [email protected] University of Washington Biological Futures in a Globalization World colloquium series May 7, 2012 Publications Spreading of knowledge : oral & written communications Evaluation of a scientist Promotion of a scientist : scientific achievements Publish or Perish ? The Ethics of Scientific Writing: The Good and the Bad Ethics in publication is of paramount importance, and has become more of an issue for editors in recent years, particularly with the advent of the electronic age. Plagiarism ? Use of others’ published and unpublished ideas or words (or other intellectual property) without attribution or permission, and presenting them as new and original rather than derived from an existing source. Self-plagiarism refers to the practice of an author using portions of his or her previous writings on the same topic in another article, without specifically quoting or citing the self- plagiarized material. Conflicts of Interest (Author) •Conflicts may be financial, academic, commercial, political or personal. Financial interests may include employment, research funding (received or pending), stock or share ownership, patents, payment for lectures or travel, consultancies, non financial support, or any fiduciary interest in a company. •Authors should declare all such interests (or their absence) in writing upon submission How to structure a paper to tell your story Some do’s and don’t’s Take advantage of peer review Self-plagiarism Duplication Plagiarism Fabrication Fraud Reviewer responsibility TALANTA The International Journal of Pure and Applied Analytical Chemistry Editors-in-Chief: G.D. -

October 2004 | Volume 2 | Number 3
newsletternewsletter Volume 2Volume ■ Number 1 ■ Number3 ■ October 1 ■ 2004April ■2003ISSN: 1549-3725 In this Issue Welcome FEATURES Dear Colleagues, Be Nimble, . Be Quick: Responding to User Needs . .2-4 “In less than 10 years,” writes Marshall Clinton in his article for this issue of Library Connect, “the introduction of electronic information resources A&I Databases: Trends in Policy into our teaching, learning and research processes has transformed and Functionality Development . .5 scholarship in ways that few could have imagined.” Beyond Access and Retrieval: Eefke Smit The Battle for Mindshare . .6-8 Many of the challenges this transformation brings are shared not just by librarians and their patrons, but also by the publishers and by the vendors of secondary BEHIND THE SCENES information products. For example: How can we make the most of the explosion in Introducing Tony McSeán: Elsevier’s information and help users become specialists in their disciplines, rather than specialists New Director of Library Relations . .9 in searching? One of the most satisfying aspects of all of our jobs is that we’re not in CENTER OF ATTENTION this alone. If we collaborate, the expertise, the technology and the imagination shared by librarians, scientists and publishers can truly make a difference. 5 Quick Questions . .10-11 Librarians Speak Up . .10-11 In this issue we see how an information behavior study at the University of Toronto revealed that information is sometimes used in unexpected ways, and how a deeper understanding of researchers’ BEHIND THE SCENES actual behavior within the everyday work context has fed into the development of new services. -

A Short History of Elsevier
A SHORT HISTORY OF ELSEVIER In Celebration of the 125th Anniversary of Elsevier and the 425th Anniversary of the House of Elzevir Scientists and healthcare professionals are more inclined to look forward than back, which perhaps explains why there are so few written accounts of Elsevier, in spite of the publishing company’s long and successful history. hereas historians have recorded science Press, to name but a few of the companies that Wand medicine’s key moments of are now part of the Elsevier family, bringing with progress — from Galileo’s celestial revelations them long and rich histories of their own. As the to Fleming’s discovery of penicillin to the recent company moves forward into the new millennium, identification of SARS as a Corona virus — few its founding motto seems more apt than ever: have taken the time to examine the role that Non Solus (not alone). publishers have played in the history of science. Given that 2005 marks the 125th birthday Founding Principles of Elsevier and the 425th anniversary of the publishing house of Elzevir from which the t is ironic that Elsevier’s founder, Jacobus modern company takes its name, the time seems IRobbers, chose to name his small Dutch right to redress that imbalance and reflect on publishing company after a defunct seventeenth the myriad ways in which Elsevier has played a century publishing house. Nevertheless it makes role in the history of science over the last 125 sense: for in spite of the fact that the House of years. In that time Elsevier has evolved from a Elzevir had been out of business since 1712, the small Dutch publishing house devoted to the promulgation of classical reputation of Elzevir publications had grown rather than declined by scholarship to an international multimedia publishing company that March of 1880 when the modern Elsevier was founded. -

Documentation Organique>Telecommunications Law>Legal Express>Law in Context>Butterworths Core Texts>E-Marketplace>Legal Express>Lawcommerce
140348 20-f cover_with spine 7/3/03 12:41 pm Page 1 Reed Elsevier Reed Elsevier www.reedelsevier.com Indispensable global information Science & Medical Legal Education Business Form 20-F ANNUAL REPORT 2002 ON FORM 20-F ANNUAL REPORT 2002 ON FORM CHEMWEB>BIOMEDNET>BIOCHIMICA ET BIOPHYSICA ACTA>EVOLVE>MDL INFORMATION SYSTEMS>SCIRUS>EXCERPTA MEDICA>THE LANCET>ELSEVIER>GRAY’S ANATOMY>SCIENCEDIRECT> ACADEMIC PRESS> CHURCHILL LIVINGSTONE>L’ANNEE BIOLOGIQUE>MOSBY>WB SAUNDERS>BRAIN RESEARCH>ONCOLOGY TODAY>TETRAHEDRON LETTERS>VASCULAR SURGERY>SCIRUS >PDXMD>CELL>JOURNAL OF THE AMERICAN COLLEGE OF CARDIOLOGY> NEUROSCIENCE>THE LANGUAGE OF MEDICINE>ENCYCLOPEDIA OF THE HUMAN BRAIN>VIRTUAL CLINICAL EXCURSION>EMBASE> EI> CHEMICAL PHYSICS LETTERS>POLYMER>NEURON> JOURNAL OF CHROMATOGRAPHY A>ACTA PSYCHOLOGICA> MD CONSULT> AMERICAN JOURNAL OF CARDIOLOGY> COMPUTER NETWORKS >DEVELOPMENTAL BIOLOGY> FEBS LETTERS> HOMEOPATHY>NEUROIMAGE>PHYSICA A>SPEECH COMMUNICATION>WATER RESEARCH> ZEOLITES>MATERIALS TODAY>RISKWISE>BUTTERWORTHS TOLLEY> MATTHEW BENDER> SHEPARD’S IN PRINT> MARTINDALE HUBBELL>LEXISNEXIS AT LEXIS.COM>MALAYAN LAW JOURNAL>LEXISNEXIS AT NEXIS.COM >CONOSUR>LEXPOLONICA>NIMMER ON COPYRIGHT>DEPALMA>MBO VERLAG>COLLIER>LITEC>PEOPLEWISE>EDITIONS DU JURIS CLASSEUR> ECLIPSE>MEALEY PUBLICATIONS>LEXISNEXIS COUNTRY ANALYSIS>CHECKCITE>LEXISONE>THE ADVERTISING RED BOOKS>HALSBURY’S LAWS > > > > > > > > Reed Elsevier DICTIONARY OF CORPORATE AFFILIATIONS ORAC VERLAG FACTLANE LEGISOFT INFOLIB LE BOTTIN ADMINISTRATIF CARTER ON CONTRACT AUSTRALIAN ENCYCLOPEDIA OF FORMS -

Elsevier Subscription Agreement
No l-6078425490 CRM la.1.0 20i07 ELSEVIER SUBSCRIPTION AGREEMENT This agreement ("'Agreement") is entered into as of 9 April 2014 by and between the Regents of the 1 University of California on behalf of the California Digital Library, 415 20th Street, 4 h Floor, Oakland, CA 94612 USA (the "Subscriber"), and Elsevier B.V., Radarweg 29, I 043 NX Amsterdam, The Netherlands (''Elsevier"). The parties hereto agree as follows: SECTION 1. SUBSCRIPTION. I .1 Subscribed Products. Elsevier hereby grants to the Subscriber the non-exclusive, non-transferable right to access and use the products and services identified in Schedule I ("Subscribed Products") and provide the Subscribed Products to its Authorized Users (as defined herein) which rights are worldwide with respect to off campus remote access by Authorized Users and perpetual as described in detail on Schedule 1 regarding access to formerly subscribed titles and archival print copies (which rights survive the termination of this Agreement), all subject to the terms and conditions of this Agreement. 1.2 Authorized Users/Sites. Authorized Users are the full-time and part-time students, faculty, staff and researchers of the Subscriber and individuals who are independent contractors or are employed by independent contractors of the Subscriber affiliated with the Subscriber's locations listed on Schedule 2 (the "Sites") and individuals using computer terminals within facilities at the Sites permitted by the Subscriber to access the Subscribed Products for purposes of personal research, education -

TETRAHEDRON LETTERS the International Journal for the Rapid Publication of All Preliminary Communications in Organic Chemistry
TETRAHEDRON LETTERS The International Journal for the Rapid Publication of all Preliminary Communications in Organic Chemistry AUTHOR INFORMATION PACK TABLE OF CONTENTS XXX . • Description p.1 • Audience p.1 • Impact Factor p.1 • Abstracting and Indexing p.2 • Editorial Board p.2 • Guide for Authors p.4 ISSN: 0040-4039 DESCRIPTION . Tetrahedron Letters provides rapid dissemination of short accounts of advances of outstanding significance and timeliness in the broad field of organic chemistry and its related disciplines, such as organic materials and bio-organic chemistry. Communications in Tetrahedron Letters are expected to represent brief summaries of preliminary work or initial results at the cutting edge of the field. Rapid publication of such research enables authors to transmit their new contributions quickly to a large, international audience. Tetrahedron Letters also publishes 'Digests', commissioned short reviews, highlights or perspectives, focusing on recent advancements in a field. Benefits to authors We also provide many author benefits, such as free PDFs, a liberal copyright policy, special discounts on Elsevier publications and much more. Please click here for more information on our author services. Please see our Guide for Authors for information on article submission. If you require any further information or help, please visit our Support Center AUDIENCE . Organic chemist, bioorganic chemists. IMPACT FACTOR . 2020: 2.415 © Clarivate Analytics Journal Citation Reports 2021 AUTHOR INFORMATION PACK 2 Oct 2021 www.elsevier.com/locate/tetlet 1 ABSTRACTING AND INDEXING . PubMed/Medline AGRICOLA Reaxys CAB International Chemical Abstracts Chemical Engineering Biotechnology Abstracts Current Biotechnology Abstracts Current Contents - Life Sciences Current Contents - Physical, Chemical & Earth Sciences Current Contents Derwent Drug File El Compendex Plus Embase Pascal Francis Research Alert Science Citation Index Web of Science BIOSIS Citation Index Scopus EDITORIAL BOARD . -

Doctor • Kelly’S Directories • Farmers’ Weekly • Totaljobs.Com
ANNUAL REPORT 2001 ON FORM 20-F Reed Elsevier ELSEVIER SCIENCE • SCIENCEDIRECT • CHEMWEB • BIOMEDNET • MDL INFORMATION SYSTEMS • SCIRUS • EXCERPTA MEDICA • THE LANCET • GRAY’S ANATOMY • ACADEMIC PRESS • CHURCHILL LIVINGSTONE • MOSBY • WB SAUNDERS • CELL • BRAIN RESEARCH • ONCOLOGY TODAY • TETRAHEDRON LETTERS • VASCULAR SURGERY • ENCYCLOPEDIA OF GENETICS • LEXISNEXIS • BUTTERWORTHS TOLLEY • MATTHEW BENDER • SHEPARD’S • MARTINDALE HUBBELL • LEXIS.COM • NEXIS.COM • EDITIONS DU JURIS CLASSEUR • MALAYAN LAW JOURNAL • DEPALMA • CONOSUR • NIMMER ON COPYRIGHT • HALSBURY’S LAWS • MOORE’S FEDERAL PRACTICE • HARCOURT SCHOOL PUBLISHERS • LEX POLONICA • RIGBY • HEINEMANN • GINN • GREENWOOD • HOLT RINEHARTFORM AND WINSTON 20-F • STECK-VAUGHN • THE PSYCHOLOGICAL CORPORATION • WECHSLER TEST • HI.COM.AU • STANFORD ACHIEVEMENT TEST • WECHSLER INTELLIGENCE SERIES • HARCOURT EDUCATIONAL MEASUREMENT • ELECTRONIC() DESIGN NEWS • VARIETY • RESTAURANTS & INSTITUTIONS • COMPUTER WEEKLY • COMMUNITY CARE • NEW SCIENTIST • FLIGHT INTERNATIONAL • ESTATES GAZETTE • CNI.COM • RATI.COM • ELSEVIER • BELEGGERS BELANGEN • BIZZ • ZIBB.NL • TOERISTIEK • MIDEM • WORLD TRAVEL MARKET • HOTELYMPIA • BATIMAT • BOOKEXPO • STRATEGIES • MIPCOM • DOCTOR • KELLY’S DIRECTORIES • FARMERS’ WEEKLY • TOTALJOBS.COM Indispensable global information SCIENCE LEGAL EDUCATION BUSINESS & MEDICAL As ¢led with the Securities and Exchange Commission on 5 March 2002 SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 (Mark One) & REGISTRATION STATEMENT PURSUANT TO SECTION 12(b) or 12(g) OF THE SECURITIES EXCHANGE ACT OF 1934 or &6 ANNUAL REPORT PURSUANT TO SECTION 13 or 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the ¢scal year ended 31 December 2001 or & TRANSITION REPORT PURSUANT TO SECTION 13 or 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the transition period from to Commission ¢le number: 1-3334 REED INTERNATIONAL P.L.C. -

Microsoft Academic: a Multidisciplinary Comparison of Citation Counts with Scopus and Mendeley for 29 Journals 1 Introduction
1 Microsoft Academic: A multidisciplinary comparison of citation counts with Scopus and Mendeley for 29 journals1 Mike Thelwall, Statistical Cybermetrics Research Group, University of Wolverhampton, UK. Abstract Microsoft Academic is a free citation index that allows large scale data collection. This combination makes it useful for scientometric research. Previous studies have found that its citation counts tend to be slightly larger than those of Scopus but smaller than Google Scholar, with disciplinary variations. This study reports the largest and most systematic analysis so far, of 172,752 articles in 29 large journals chosen from different specialisms. From Scopus citation counts, Microsoft Academic citation counts and Mendeley reader counts for articles published 2007-2017, Microsoft Academic found a slightly more (6%) citations than Scopus overall and especially for the current year (51%). It found fewer citations than Mendeley readers overall (59%), and only 7% as many for the current year. Differences between journals were probably due to field preprint sharing cultures or journal policies rather than broad disciplinary differences. 1 Introduction Microsoft Academic is the replacement for Microsoft Academic Search, generated by Microsoft Asia (Sinha, Shen, Song, Ma, Eide, Hsu, & Wang, 2015). Like Google Scholar, it is a free search engine for academic research and includes a citation index. Unlike Google Scholar (Halevi, Moed, & Bar-Ilan, 2017), it allows automatic data collection via an API (Chen, 2017) and so has the potential to be used for scientometric applications that require large amounts of data, such as calculating field normalised indicators (Thelwall, 2017b; Waltman, van Eck, van Leeuwen, Visser, & van Raan, 2011) (for example, see: Hug et al., 2017) and analyses of large groups of researchers (Science-Metrix, 2015). -
RELX Group Annual Reports and Financial Statements 2007
Annual Reports and Financial Statements 2007 tal Litigator ZAP Academic Press RiskView QuickLaw Matthew Bender Matthew Scirus iety Scopus Tolley’s Martindale-Hubbell Cell nes Embase To ICIS Tetrahedron Letters Engineering Village Engineering Visual Files Total Practice Advantage Practice Total Var CrossFire Beilstein CrossFire Misset Horeca alayan Law Journal Lexis.com Totaljobs.com ScienceDirect M Lawyers.com Agrarisch Dagblad Evolve Market Cast KnowHow FEM Busi Netter MIPC JurisClasseur Gray’s Anatomy Gray’s InterAction Mosby’s Nursing Consult Nursing Mosby’s File & Serve & File Chabner’s Language of Medicine of Language Chabner’s InstantID SIMA HESI m JCK Las Vegas Las JCK ELSEVIER SCIENCE & TECHNOLOGY EmpowerX Butterworths Masson PharmaPendiu lL MDConsult L Counse The The Ac REED EXHIBITIONS ELSEVIER HEALTH SCIENCES TOTAL SOLUTIONS RISK INFORMATION & ANALYTICS LEXISNEXIS INFORMATION REED ELSEVIER SOLUTIONS FOR PROFESSIONALS Information solutions for professionals Reed Elsevier is a world leading provider of professional information and online workflow solutions in the Science, Medical, Legal, Risk Information and Analytics, and Business sectors. Based in over 200 locations worldwide, we create authoritative content delivered through market leading brands, enabling our customers to find the essential data, analysis and commentary to support their decisions. ess Our content and solutions are increasingly embedded in the workflows of our customers M making them more effective and Reed Elsevier PCO ional a more valued partner. Boerderij -
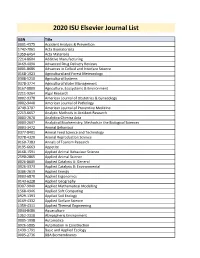
2020 ISU Elsevier Journal List
2020 ISU Elsevier Journal List ISSN Title 0001-4575 Accident Analysis & Prevention 1742-7061 Acta Biomaterialia 1359-6454 Acta Materialia 2214-8604 Additive Manufacturing 0169-409X Advanced Drug Delivery Reviews 0001-8686 Advances in Colloid and Interface Science 0168-1923 Agricultural and Forest Meteorology 0308-521X Agricultural Systems 0378-3774 Agricultural Water Management 0167-8809 Agriculture, Ecosystems & Environment 2211-9264 Algal Research 0002-9378 American Journal of Obstetrics & Gynecology 0002-9440 American Journal of Pathology 0749-3797 American Journal of Preventive Medicine 2213-6657 Analytic Methods in Accident Research 0003-2670 Analytica Chimica Acta 0003-2697 Analytical Biochemistry: Methods in the Biological Sciences 0003-3472 Animal Behaviour 0377-8401 Animal Feed Science and Technology 0378-4320 Animal Reproduction Science 0160-7383 Annals of Tourism Research 0195-6663 Appetite 0168-1591 Applied Animal Behaviour Science 2590-2865 Applied Animal Science 0926-860X Applied Catalysis A: General 0926-3373 Applied Catalysis B: Environmental 0306-2619 Applied Energy 0003-6870 Applied Ergonomics 0143-6228 Applied Geography 0307-904X Applied Mathematical Modelling 1568-4946 Applied Soft Computing 0929-1393 Applied Soil Ecology 0169-4332 Applied Surface Science 1359-4311 Applied Thermal Engineering 0044-8486 Aquaculture 1352-2310 Atmospheric Environment 0005-1098 Automatica 0926-5805 Automation in Construction 1439-1791 Basic and Applied Ecology 0005-2736 BBA Biomembranes 0167-4889 BBA Molecular Cell Research 0166-4328 Behavioural