Scientist's Workbook
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tesis Maerstría
ESCUELA SUPERIOR POLITÉCNICA DE CHIMBORAZO TITULO DE LA TESIS PROXY GNU/LINUX EN LA INTRANET DE LA FACULTAD DE CIENCIAS AUTOR ROGEL ALFREDO MIGUEZ PAREDES. Tesis presentada ante la Escuela de Postgrado y Educación Contínua de la ESPOCH, como requisito parcial para la obtención del grado de Magister en Interconectividad de Redes. Riobamba Ecuador 2012 ESCUELA SUPERIOR POLITÉCNICA DE CHIMBORAZO CERTIFICACIÓN: El Tribunal de Tesis certifica que: REDUNDANCIA PARA SERVIDORES PROXY GNU/LINUX EN LA INTRANET DE LA FACULTAD DE CIENCIAS ingeniero ROGEL ALFREDO MIGUEZ PAREDES ha sido prolijamente revisado y se autoriza su presentación. TRIBUNAL DE TESIS: Dr. Juan Vargas Guambo PRESIDENTE ..................................... Ing. Ms.C. Diego Ávila TUTOR ..................................... Ing. Ms.C. Danilo Pastor MIEMBRO ..................................... Ing. Ms.C. Gloria Arcos MIEMBRO ..................................... DERECHOS DE AUTORÍA Yo, Rogel Alfredo Miguez Paredes, soy responsable de las ideas, doctrinas y resultados expuestos en esta Tesis; y el patrimonio intelectual de la Tesis de Grado pertenece a la ESCUELA SUPERIOR POLITÉCNICA DE CHIMBORAZO. Ing. Rogel Alfredo Miguez Paredes iii PORTADA APROBACIÓN DEL DOCUMENTO ÍNDICE LISTA DE TABLAS LISTA DE FIGURAS DEDICATORIA AGRADECIMIENTO RESUMEN SUMMARY CAPITULO I..............................................................................................................................1 INTRODUCCIÓN ......................................................................................................................1 -

Introducción a Linux Equivalencias Windows En Linux Ivalencias
No has iniciado sesión Discusión Contribuciones Crear una cuenta Acceder Página discusión Leer Editar Ver historial Buscar Introducción a Linux Equivalencias Windows en Linux Portada < Introducción a Linux Categorías de libros Equivalencias Windows en GNU/Linux es una lista de equivalencias, reemplazos y software Cam bios recientes Libro aleatorio análogo a Windows en GNU/Linux y viceversa. Ayuda Contenido [ocultar] Donaciones 1 Algunas diferencias entre los programas para Windows y GNU/Linux Comunidad 2 Redes y Conectividad Café 3 Trabajando con archivos Portal de la comunidad 4 Software de escritorio Subproyectos 5 Multimedia Recetario 5.1 Audio y reproductores de CD Wikichicos 5.2 Gráficos 5.3 Video y otros Imprimir/exportar 6 Ofimática/negocios Crear un libro 7 Juegos Descargar como PDF Versión para im primir 8 Programación y Desarrollo 9 Software para Servidores Herramientas 10 Científicos y Prog s Especiales 11 Otros Cambios relacionados 12 Enlaces externos Subir archivo 12.1 Notas Páginas especiales Enlace permanente Información de la Algunas diferencias entre los programas para Windows y y página Enlace corto GNU/Linux [ editar ] Citar esta página La mayoría de los programas de Windows son hechos con el principio de "Todo en uno" (cada Idiomas desarrollador agrega todo a su producto). De la misma forma, a este principio le llaman el Añadir enlaces "Estilo-Windows". Redes y Conectividad [ editar ] Descripción del programa, Windows GNU/Linux tareas ejecutadas Firefox (Iceweasel) Opera [NL] Internet Explorer Konqueror Netscape / -

Admin Tools for Joomla 4 Nicholas K
Admin Tools for Joomla 4 Nicholas K. Dionysopoulos Admin Tools for Joomla 4 Nicholas K. Dionysopoulos Copyright © 2010-2021 Akeeba Ltd Abstract This book covers the use of the Admin Tools site security component, module and plugin bundle for sites powered by Joomla!™ 4. Both the free Admin Tools Core and the subscription-based Admin Tools Professional editions are completely covered. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the appendix entitled "The GNU Free Documentation License". Table of Contents 1. Getting Started .......................................................................................................................... 1 1. What is Admin Tools? ....................................................................................................... 1 1.1. Disclaimer ............................................................................................................. 1 1.2. The philosophy ....................................................................................................... 2 2. Server environment requirements ......................................................................................... 2 3. Installing Admin Tools ...................................................................................................... -

Design and Implementation of a Multifunction, Modular and Extensible Proxy Server
Design and Implementation of a Multifunction, Modular and Extensible Proxy Server Simone Tellini and Renzo Davoli Department of Computer Science - University of Bologna, Mura Anteo Zamboni, 7, I40127 Bologna, Italy {davoli, tellini}@cs.unibo.it Abstract. This paper introduces Prometeo1 a multi-function, modular and extensible proxy server created as part of one the author’s thesis work. We will discuss the needs that this project was meant to address: mainly the lack of an application with the aforesaid features, combined with native IPv6 support and ease of administration. Prometeo also provides a C++ framework which simplifies the development of networking applications. The design of Prometeo’s will be described, starting with an overview of its components and modules and commenting on the most significant parts of the implementation. Then we will focus on the main issues considered during the development of the project, comparing the adopted solutions with those of other state-of-the-art packages like Squid [1]. Finally we will discuss new ways of improving Prometeo’s performances and scalability.2 1 Introduction Proxies are important components of large, heterogeneous networks: they’re of- ten found on the frontier of private LAN’s or corporate networks to allow their users to access Internet resources in a controlled manner - for instance, forcing them to obey to corporate policy. Caching proxies also help to optimize the available resources, reducing the traffic generated by the users. Another class of proxies enables interoperability between applications, translating on the fly from one protocol to another (for example, from NNTP to POP3). Proxies can also be used for special purposes, for instance to allow visually challenged people to browse the web [2] or to improve the management of networked games [3]. -

Migration from Windows to Linux for a Small Engineering Firm "A&G Associates"
Rochester Institute of Technology RIT Scholar Works Theses 2004 Migration from Windows to Linux for a small engineering firm "A&G Associates" Trimbak Vohra Follow this and additional works at: https://scholarworks.rit.edu/theses Recommended Citation Vohra, Trimbak, "Migration from Windows to Linux for a small engineering firm A&G" Associates"" (2004). Thesis. Rochester Institute of Technology. Accessed from This Thesis is brought to you for free and open access by RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. Migration from Windows to Linux for a Small Engineering Firm "A&G Associates" (H ' _T ^^L. WBBmBmBBBBmb- Windows Linux by Trimbak Vohra Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Information Technology Rochester Institute of Technology B. Thomas Golisano College of Computing and Information Sciences Date: December 2, 2004 12/B2/28B2 14:46 5854752181 RIT INFORMATION TECH PAGE 02 Rochester Institute of Teehnology B. Thomas Golisano College of Computing and Information Sciences Master of Science in Information Technology Thesis Approval Form Student Name: Trimbak Vohra Thesis Title: Migration from Windows to Unux for a Small Engineeriog Firm "A&G Associates" Thesis Committee Name Signature Date Luther Troell luther IrQell, Ph.D ttL ",j7/Uy Chair G. L. Barido Prof. ~~orge Barido ? - Dec:. -cl7' Committee Member Thomas Oxford Mr. Thomas OxfocQ \ 2. L~( Q~ Committee Member Thesis Reproduction Permission Form Rochester Institute of Technology B. Thomas Golisano College of Computing and Information Sciences Master of Science in Information Technology Migration from Windows to Linux for a Small Engineering Firm "A&G Associates" I,Trimbak Vohra, hereby grant permission to the Wallace Library of the Rochester Institute of Technology to reproduce my thesis in whole or in part. -

Ipv6 Tutorial János Mohácsi
IPv6 Tutorial János Mohácsi Alcatel-Lucent Szeminárium 2009 - IPv6 tutorial 6DEPLOY Partners NRENs Industry Renater France Cisco Netherlands GRNET Greece FCCN Portugal Universities NIIF/HUNGARNET Hungary UNINETT Norway BREN Bulgaria UCL United Kingdom Soton ECS United Kingdom SMEs Non-European Partners Consulintel Spain AfriNIC Mauritius Martel Consulting (coordinator) Switzerland LACNIC Uruguay Associated partners: RIPE NCC, APNIC Nov 2009 Alcatel-Lucent Szeminárium 2009 - IPv6 tutorial 2 Project Objectives Support of EU policy The Internet is now the main telecommunications technology that underpins all aspects of business and leisure, and as such is central to the economic growth of a country. Awareness of the evolution of the Internet, and providing support for the introduction of IPv6 is therefore crucial as ICT becomes a major theme in FP7 Specific technical focus on supporting the deployment of IPv6 in: • research infrastructures, for supporting all fields of science and technology • FP7 projects (especially in the areas of emergency services, healthcare, transport, gaming) • developing countries (Africa, Latin America, Asia and E. Europe), and • commercial organisations in Europe Nov 2009 Alcatel-Lucent Szeminárium 2009 - IPv6 tutorial 3 History FP4: 6INIT, 6WINIT FP5: 6NET, Euro6IX, Occasion, 6Power, IPv6 TF FP6: 6DISS, Sponge, IPv6 TF (continued) FP7: 6DEPLOY 6DEPLOY is the one we exploit the most, in terms of partners and material Nov 2009 Alcatel-Lucent Szeminárium 2009 - IPv6 tutorial 4 Technical Approach Remote testbeds -

Tabla De Equivalencias De Programas Propietarios Y De Software Libre
ENTORNO PC: TABLA DE EQUIVALENCIAS DE PROGRAMAS PROPIETARIOS Y DE SOFTWARE LIBRE. *PRÓPOSITO. En este documento, se detallan en el momento actual, una tabla de equivalencia de software usado en Windows y software libre. Esta tabla no es estática y está en continuo cambio según se va produciendo software y pasándolo a las licencias libres. En cualquier caso, en la siguiente dirección web, se encuentra una exhaustiva lista de posibilidades: http://linuxshop.ru/linuxbegin/win-lin-soft-spanish/ Notas: · Por principio todos los programas de linux en esta tabla son libres y están liberados. Los programas propietarios para Linux están marcados con una señal [Prop]. Programa, tareas Windows Linux ejecutadas 1) Redes y Conectividad. 1) Netscape / Mozilla . 2) Galeon. 3) Konqueror. Internet Explorer, 4) Opera. [Prop] Netscape / Mozilla for Navegadores Web 5) Phoenix. Windows, Opera, 6) Nautilus. Phoenix for Windows, ... 7) Epiphany. 8) Links. (with "-g" key). 9) Dillo. (Parches lenguaje Ruso - aquí). 1) Links. Navegadores web para 2) Lynx. Lynx para Windows Consola 3) w3m. 4) Xemacs + w3. 1) Evolution. 2) Netscape / Mozilla messenger. 3) Sylpheed, Sylpheed-claws. 4) Kmail. 5) Gnus. Outlook Express, Mozilla 6) Balsa. Clientes de Email for Windows, Eudora, 7) Bynari Insight GroupWare Suite. Becky [Prop] 8) Arrow. 9) Gnumail. 10) Althea. 11) Liamail. 12) Aethera. 1 1) Evolution. Clientes de email al estilo 2) Bynari Insight GroupWare Suite. Outlook MS Outlook [Prop] 3) Aethera. 1) Sylpheed. 2) Sylpheed-claws. Clientes de email al estilo The Bat 3) Kmail. The Bat 4) Gnus. 5) Balsa. 1) Pine. 2) Mutt. Cliente de email en Mutt for Windows [de], 3) Gnus. -

A Delay Tolerant Networking and System Architecture for Developing Regions
A Delay Tolerant Networking and System Architecture for Developing Regions Michael Demmer Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2008-124 http://www.eecs.berkeley.edu/Pubs/TechRpts/2008/EECS-2008-124.html September 25, 2008 Copyright 2008, by the author(s). All rights reserved. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission. A Delay Tolerant Networking and System Architecture for Developing Regions by Michael Joshua Demmer B.S. (Brown University) 1998 A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Computer Science in the GRADUATE DIVISION of the UNIVERSITY OF CALIFORNIA, BERKELEY Committee in charge: Professor Eric Brewer, Chair Professor Scott Shenker Professor AnnaLee Saxenian Fall 2008 A Delay Tolerant Networking and System Architecture for Developing Regions Copyright 2008 by Michael Joshua Demmer 1 Abstract A Delay Tolerant Networking and System Architecture for Developing Regions by Michael Joshua Demmer Doctor of Philosophy in Computer Science University of California, Berkeley Professor Eric Brewer, Chair Technology has shown significant potential in developing countries, as appropriate de- signs matched with real world need can effectively bridge information gaps, provide greater trans- parency, and improve communication efficiency. -

Scientist's Workbook
Scientist’s Workbook 5th November 1999 Michael JasonSmith Abstract This project discusses the scientist’s workbook, a system designed to assist sci- entists’ in their work. An overview of similar systems, such as the Memex and Xanadu, is presented. The results of a series of interviews with nine sci- entists are discussed. In the interviews the scientists expressed difficulty man- aging bookmarks, user defined links into the World Wide Web. This lead to the design and implementation of a system (SWB) to assist scientist with web revisitation. A number of design goals for systems that implement web-page revisitation are given, and the implementation of SWB is detailed. Contents 1 Introduction 4 2 Previous Work 6 2.1 Early Systems . ............................ 6 2.1.1 Memex . ............................ 6 2.1.2 oN Line System ........................ 7 2.1.3 Xanadu . ............................ 8 2.1.4 World Wide Web . ................. 8 2.2 Alternative User Interfaces . ................. 8 2.2.1 Post-Wimp User Interfaces ................. 8 2.2.2 Pen Input . ........................ 9 2.3 Existing Information Visualisation Systems . ......... 10 2.3.1 Image Viewers ........................ 10 2.3.2 Command Line Interfaces . ................. 11 2.3.3 World Wide Web Browsers ................. 13 3 Work Practices of Scientists 16 3.1 Papers . ................................ 16 3.1.1 Single-Authored Papers . ................. 17 3.1.2 Collaboration . ........................ 19 3.1.3 Research Data . ........................ 19 3.2 Books and Documents ........................ 19 3.3 Network-related Data ........................ 21 4 SWB 24 4.1 Design Goals of SWB . ........................ 24 4.1.1 Implicit Visit Capture . ................. 24 4.1.2 Views . ............................ 25 4.2 Implementation of SWB . -

Admin Tools User's Guide Nicholas K
Admin Tools User's Guide Nicholas K. Dionysopoulos Admin Tools User's Guide Nicholas K. Dionysopoulos Copyright © 2010-2021 Akeeba Ltd Abstract This book covers the use of the Admin Tools site security component, module and plugin bundle for Joomla!™ - powered web sites. Both the free Admin Tools Core and the subscription-based Admin Tools Professional editions are completely covered. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the appendix entitled "The GNU Free Documentation License". Table of Contents 1. Getting Started .......................................................................................................................... 1 1. What is Admin Tools? ....................................................................................................... 1 1.1. Disclaimer ............................................................................................................. 1 1.2. The philosophy ....................................................................................................... 2 2. Server environment requirements ......................................................................................... 2 3. Installing Admin Tools ...................................................................................................... -
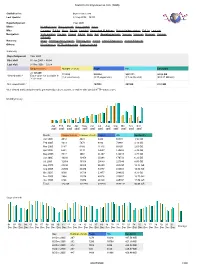
Statistics for Brynosaurus.Com (2005)
Statistics for brynosaurus.com (2005) Statistics for: brynosaurus.com Last Update: 27 Sep 2006 − 06:00 Reported period: Year 2005 When: Monthly history Days of month Days of week Hours Who: Countries Full list Hosts Full list Last visit Unresolved IP Address Robots/Spiders visitors Full list Last visit Navigation: Visits duration File type Viewed Full list Entry Exit Operating Systems Versions Unknown Browsers Versions Unknown Referers: Origin Refering search engines Refering sites Search Search Keyphrases Search Keywords Others: Miscellaneous HTTP Status codes Pages not found Summary Reported period Year 2005 First visit 01 Jan 2005 − 00:04 Last visit 31 Dec 2005 − 23:54 Unique visitors Number of visits Pages Hits Bandwidth <= 125249 151229 328224 2621111 94.06 GB Viewed traffic * Exact value not available in (1.2 visits/visitor) (2.17 pages/visit) (17.33 hits/visit) (652.17 KB/visit) 'Year' view Not viewed traffic * 167672 261929 7.32 GB * Not viewed traffic includes traffic generated by robots, worms, or replies with special HTTP status codes. Monthly history Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2005 2005 2005 2005 2005 2005 2005 2005 2005 2005 2005 2005 Month Unique visitors Number of visits Pages Hits Bandwidth Jan 2005 4012 4621 8432 62678 1.93 GB Feb 2005 4919 5671 8892 79888 2.10 GB Mar 2005 5487 6460 11410 93405 2.66 GB Apr 2005 6941 8147 23657 130853 3.49 GB May 2005 7517 9004 21307 139015 3.71 GB Jun 2005 10393 12458 25968 170723 6.32 GB Jul 2005 12958 15156 28649 225540 8.05 GB Aug 2005 22292 25919 46389 355390 -

The Table of Equivalents / Replacements / Analogs of Windows Software in Linux
The table of equivalents / replacements / analogs of Windows software in Linux. Last update: 16.07.2003, 31.01.2005, 27.05.2005, 04.12.2006 You can always find the last version of this table on the official site: http://www.linuxrsp.ru/win-lin-soft/. This page on other languages: Russian, Italian, Spanish, French, German, Hungarian, Chinese. One of the biggest difficulties in migrating from Windows to Linux is the lack of knowledge about comparable software. Newbies usually search for Linux analogs of Windows software, and advanced Linux-users cannot answer their questions since they often don't know too much about Windows :). This list of Linux equivalents / replacements / analogs of Windows software is based on our own experience and on the information obtained from the visitors of this page (thanks!). This table is not static since new application names can be added to both left and the right sides. Also, the right column for a particular class of applications may not be filled immediately. In future, we plan to migrate this table to the PHP/MySQL engine, so visitors could add the program themselves, vote for analogs, add comments, etc. If you want to add a program to the table, send mail to winlintable[a]linuxrsp.ru with the name of the program, the OS, the description (the purpose of the program, etc), and a link to the official site of the program (if you know it). All comments, remarks, corrections, offers and bugreports are welcome - send them to winlintable[a]linuxrsp.ru. Notes: 1) By default all Linux programs in this table are free as in freedom.