1 Power-Law Distributions, the H-Index, And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Portfolio Optimization Performance During Malaysia's
Modern Applied Science; Vol. 14, No. 4; 2020 ISSN 1913-1844 E-ISSN 1913-1852 Published by Canadian Center of Science and Education The Portfolio Optimization Performance during Malaysia’s 2018 General Election by Using Noncooperative and Cooperative Game Theory Approach Muhammad Akram Ramadhan bin Ibrahim1, Pah Chin Hee1, Mohd Aminul Islam1 & Hafizah Bahaludin1 1Department of Computational and Theoretical Sciences Kulliyyah of Science International Islamic University Malaysia, 25200 Kuantan, Pahang, Malaysia Correspondence: Pah Chin Hee, Department of Computational and Theoretical Sciences, Kulliyyah of Science, International Islamic University Malaysia, 25200 Kuantan, Pahang, Malaysia. Received: February 10, 2020 Accepted: February 28, 2020 Online Published: March 4, 2020 doi:10.5539/mas.v14n4p1 URL: https://doi.org/10.5539/mas.v14n4p1 Abstract Game theory approach is used in this study that involves two types of games which are noncooperative and cooperative. Noncooperative game is used to get the equilibrium solutions from each payoff matrix. From the solutions, the values then be used as characteristic functions of Shapley value solution concept in cooperative game. In this paper, the sectors are divided into three groups where each sector will have three different stocks for the game. This study used the companies that listed in Bursa Malaysia and the prices of each stock listed in this research obtained from Datastream. The rate of return of stocks are considered as an input to get the payoff from each stock and its coalition sectors. The value of game for each sector is obtained using Shapley value solution concepts formula to find the optimal increase of the returns. The Shapley optimal portfolio, naive diversification portfolio and market portfolio performances have been calculated by using Sharpe ratio. -

Opttek Systems, Inc. President Dr. Fred Glover Elected to Membership in National Academy of Engineering
OptTek Systems, Inc. President Dr. Fred Glover Elected to Membership In National Academy of Engineering Boulder, CO, February 18, 2002 – Dr. Fred Glover, President of OptTek Systems, Inc., and MediaOne Professor of Systems Science, Leeds School of Business, University of Colorado, Boulder was elected to membership in the National Academy of Engineering. This honor was bestowed to Dr. Glover for contributions to optimization modeling and algorithmic development, and for solving problems in distribution, planning, and design. Election to the National Academy of Engineering is one of the highest professional distinctions that can be accorded an engineer. Academy membership honors those who have made "important contributions to engineering theory and practice" and those who have demonstrated "unusual accomplishment in the pioneering of new and developing fields of technology." OptTek’s software, OptQuest®, which is well known in both the simulation and optimization communities, is based on the contributions of Professor Fred Glover, a founder of OptTek Systems, Inc. and a winner of the von Neumann Theory Prize (the highest and most distinguished award of the INFORMS Society, the John von Neumann Theory Prize is awarded annually to an individual who has made fundamental, sustained contributions to theory in operations research and the management sciences. Past recipients of this prize include Nobel Prize winners Kenneth Arrow, Herbert Simon and Harry Markowitz, and National Medal of Science winners George Dantzig and Richard Karp. Dr. Fred Glover won the award in 1998). “This award is yet another confirmation of the value that Dr. Glover’s methods have brought to the theory and practice of optimization and operations research. -

Robert Merton and Myron Scholes, Nobel Laureates in Economic Sciences, Receive 2011 CME Group Fred Arditti Innovation Award
Robert Merton and Myron Scholes, Nobel Laureates in Economic Sciences, Receive 2011 CME Group Fred Arditti Innovation Award CHICAGO, Sept. 8, 2011 /PRNewswire/ -- The CME Group Center for Innovation (CFI) today announced Robert C. Merton, School of Management Distinguished Professor of Finance at the MIT Sloan School of Management and Myron S. Scholes, chairman of the Board of Economic Advisors of Stamos Partners, are the 2011 CME Group Fred Arditti Innovation Award recipients. Both recipients are recognized for their significant contributions to the financial markets, including the discovery and development of the Black-Scholes options pricing model, used to determine the value of options derivatives. The award will be presented at the fourth annual Global Financial Leadership Conference in Naples, Fla., Monday, October 24. "The Fred Arditti Award honors individuals whose innovative ideas created significant change to the markets," said Leo Melamed, CME Group Chairman Emeritus and Competitive Markets Advisory Council (CMAC) Vice Chairman. "The nexus between the Black-Scholes model and this Award needs no explanation. Their options model forever changed the nature of markets and provided the necessary foundation for the measurement of risk. The CME Group options markets were built on that infrastructure." "The Black-Scholes pricing model is still widely used to minimize risk in the financial markets," said Scholes, who first articulated the model's formula along with economist Fischer Black. "It is thrilling to witness the impact it has had in this industry, and we are honored to receive this recognition for it." "Amid uncertainty in the financial markets, we are pleased the Black-Scholes pricing model still plays an important role in determining pricing and managing risk," said Merton, who worked with Scholes and Black to further mathematically prove the model. -

A Two Parameter Discrete Lindley Distribution
Revista Colombiana de Estadística January 2016, Volume 39, Issue 1, pp. 45 to 61 DOI: http://dx.doi.org/10.15446/rce.v39n1.55138 A Two Parameter Discrete Lindley Distribution Distribución Lindley de dos parámetros Tassaddaq Hussain1;a, Muhammad Aslam2;b, Munir Ahmad3;c 1Department of Statistics, Government Postgraduate College, Rawalakot, Pakistan 2Department of Statistics, Faculty of Sciences, King Abdulaziz University, Jeddah, Saudi Arabia 3National College of Business Administration and Economics, Lahore, Pakistan Abstract In this article we have proposed and discussed a two parameter discrete Lindley distribution. The derivation of this new model is based on a two step methodology i.e. mixing then discretizing, and can be viewed as a new generalization of geometric distribution. The proposed model has proved itself as the least loss of information model when applied to a number of data sets (in an over and under dispersed structure). The competing mod- els such as Poisson, Negative binomial, Generalized Poisson and discrete gamma distributions are the well known standard discrete distributions. Its Lifetime classification, kurtosis, skewness, ascending and descending factorial moments as well as its recurrence relations, negative moments, parameters estimation via maximum likelihood method, characterization and discretized bi-variate case are presented. Key words: Characterization, Discretized version, Estimation, Geometric distribution, Mean residual life, Mixture, Negative moments. Resumen En este artículo propusimos y discutimos la distribución Lindley de dos parámetros. La obtención de este Nuevo modelo está basada en una metodo- logía en dos etapas: mezclar y luego discretizar, y puede ser vista como una generalización de una distribución geométrica. El modelo propuesto de- mostró tener la menor pérdida de información al ser aplicado a un cierto número de bases de datos (con estructuras de supra y sobredispersión). -

Journal of Economics and Management
Journal of Economics and Management ISSN 1732-1948 Vol. 39 (1) 2020 Sylwia Bąk https://orcid.org/0000-0003-4398-0865 Institute of Economics, Finance and Management Faculty of Management and Social Communication Jagiellonian University, Cracow, Poland [email protected] The problem of uncertainty and risk as a subject of research of the Nobel Prize Laureates in Economic Sciences Accepted by Editor Ewa Ziemba | Received: June 27, 2019 | Revised: October 29, 2019 | Accepted: November 8, 2019. Abstract Aim/purpose – The main aim of the present paper is to identify the problem of uncer- tainty and risk in research carried out by the Nobel Prize Laureates in Economic Sciences and its analysis by disciplines/sub-disciplines represented by the awarded researchers. Design/methodology/approach – The paper rests on the literature analysis, mostly analysis of research achievements of the Nobel Prize Laureates in Economic Sciences. Findings – Studies have determined that research on uncertainty and risk is carried out in many disciplines and sub-disciplines of economic sciences. In addition, it has been established that a number of researchers among the Nobel Prize laureates in the field of economic sciences, take into account the issues of uncertainty and risk. The analysis showed that researchers selected from the Nobel Prize laureates have made a significant contribution to raising awareness of the importance of uncertainty and risk in many areas of the functioning of individuals, enterprises and national economies. Research implications/limitations – Research analysis was based on a selected group of scientific research – Laureates of the Nobel Prize in Economic Sciences. However, thus confirmed ground-breaking and momentous nature of the research findings of this group of authors justifies the selective choice of the analysed research material. -

ΒΙΒΛΙΟΓ ΡΑΦΙΑ Bibliography
Τεύχος 53, Οκτώβριος-Δεκέμβριος 2019 | Issue 53, October-December 2019 ΒΙΒΛΙΟΓ ΡΑΦΙΑ Bibliography Βραβείο Νόμπελ στην Οικονομική Επιστήμη Nobel Prize in Economics Τα τεύχη δημοσιεύονται στον ιστοχώρο της All issues are published online at the Bank’s website Τράπεζας: address: https://www.bankofgreece.gr/trapeza/kepoe https://www.bankofgreece.gr/en/the- t/h-vivliothhkh-ths-tte/e-ekdoseis-kai- bank/culture/library/e-publications-and- anakoinwseis announcements Τράπεζα της Ελλάδος. Κέντρο Πολιτισμού, Bank of Greece. Centre for Culture, Research and Έρευνας και Τεκμηρίωσης, Τμήμα Documentation, Library Section Βιβλιοθήκης Ελ. Βενιζέλου 21, 102 50 Αθήνα, 21 El. Venizelos Ave., 102 50 Athens, [email protected] Τηλ. 210-3202446, [email protected], Tel. +30-210-3202446, 3202396, 3203129 3202396, 3203129 Βιβλιογραφία, τεύχος 53, Οκτ.-Δεκ. 2019, Bibliography, issue 53, Oct.-Dec. 2019, Nobel Prize Βραβείο Νόμπελ στην Οικονομική Επιστήμη in Economics Συντελεστές: Α. Ναδάλη, Ε. Σεμερτζάκη, Γ. Contributors: A. Nadali, E. Semertzaki, G. Tsouri Τσούρη Βιβλιογραφία, αρ.53 (Οκτ.-Δεκ. 2019), Βραβείο Nobel στην Οικονομική Επιστήμη 1 Bibliography, no. 53, (Oct.-Dec. 2019), Nobel Prize in Economics Πίνακας περιεχομένων Εισαγωγή / Introduction 6 2019: Abhijit Banerjee, Esther Duflo and Michael Kremer 7 Μονογραφίες / Monographs ................................................................................................... 7 Δοκίμια Εργασίας / Working papers ...................................................................................... -

Words from the Wise an AQR Interview with Richard Thaler
July 2018 Words from the Wise An AQR Interview with Richard Thaler Richard Thaler, a founding father of behavioral finance and 2017 recipient of the Nobel Prize in Economics, discusses his pioneering research, including how our behaviors influence decision making and investing and what to do about it. This is the eighth in a series of Words from the Wise interviews to be published on AQR.com. Richard H. Thaler is the Charles R. Walgreen Distinguished Service Professor of Behavioral Science and Economics at the University of Chicago Booth School of Business. He was awarded the 2017 Nobel Memorial Prize in Economic Sciences for his contributions to the field of behavioral economics. He is an author or editor of six books, including the recent Misbehaving: The Making of Behavioral Economics (2015), the global best seller (with Cass R. Sunstein) Nudge: Improving Decisions About Health, Wealth, and Happiness (2008), The Winner’s Curse: Paradoxes and Anomalies of Economic Life (1994), and Quasi-Rational Economics (1991). He is a member of the National Academy of Science and American Academy of Arts and Sciences, a fellow of the American Finance Association and the Econometrics Society, and served as the president of the American Economic Association in 2015. 02 Words from the Wise — Richard Thaler Additional articles in the AQR Words from the Wise interview series www.aqr.com/Insights/Research/Interviews Jack Bogle Founder, Vanguard Group Charley Ellis Founder, Greenwich Associates Robert Engle Michael Armellino Professor of Finance, New York -

Reference As Behavior Towards Risk.” Review of Economic Studies 25 (2) (1958): 65-86
CHAPTER 1 Risk Uncorrelated with Returns 1. Eric N. Berg, “Market Place; A Study Shakes Confidence in the Volatile-Stock Theory,” New York Times, February 18, 1992. 2. Eugene Fama and Kenneth French, “The Cross-Section of Expected Stock Re turns, Journal of Finance 47 (2) (1992): 427—465. 3. Robert L. Heilbroner, The Worldly Philosophers: The Lives, Times, and Ideas of the Great Economic Thinkers (New York: Simon & Schuster, 1999). 4. Barry Nalebuff and Ian Ayres, Why Not?: How to Use Everyday Ingenuity to Solve Problems Big and Small (Boston: Harvard Business School Press, 2003); Steven Levitt and Stephen J. Dubner, Freakonomics: A Rogue Economist Ex plores the Hidden Side of Everything (New York: HarperCollins, 2006). 5. Peter L. Bernstein, Capital Ideas Evolving, 2nd ed. (Hoboken, NJ: John Wiley & Sons, 2007). 6. Marvin Minsky, The Emotion Machine: Commonsense Thinking, Artificial In telligence, and the Future of the Human Mind (New York: Simon & Schuster, 2007). CHAPTER 2 The Creation of the Standard Risk-Return Model 1. Peter L. Bernstein, Capital Ideas Evolving, 2nd ed. (Hoboken, NJ: John Wiley & Sons, 2007). 2. Peter L. Bernstein, Against the Gods: The Remarkable Story of Risk (New York: John Wiley & Sons, 1998), 1. 3. David Silverman, “The Case of Stock Splits: When One Plus One Equals More Than Two,” Smart Money, August 2, 2005. 4. The Miller-Modigliani Theorem states that the value of a firm is independent of the way it is financed, that is, the debt-equity proportion does not affect the sum value of the debt plus equity. 5. Frank H. -

Descriptive Statistics
IMGD 2905 Descriptive Statistics Chapter 3 Summarizing Data Q: how to summarize numbers? • With lots of playtesting, there is a lot of data (good!) • But raw data is often just a pile of numbers • Rarely of interest, or even sensible Summarizing Data Measures of central tendency Groupwork 4 3 7 8 3 4 22 3 5 3 2 3 • Indicate central tendency with one number? • What are pros and cons of each? Measure of Central Tendency: Mean • Aka: “arithmetic mean” or “average” =AVERAGE(range) =AVERAGEIF() – averages if numbers meet certain condition Measure of Central Tendency: Median • Sort values low to high and take middle value =MEDIAN(range) Measure of Central Tendency: Mode • Number which occurs most frequently • Not too useful in many cases Best use for categorical data • e.g., most popular Hero group in http://pad3.whstatic.com/images/thumb/c/cd/Find-the-Mode-of-a-Set-of-Numbers- Heroes of theStep-7.jpg/aid130521-v4-728px-Find-the-Mode-of-a-Set-of-Numbers-Step-7.jpg Storm =MODE() Mean, Median, Mode? frequency Mean, Median, Mode? frequency Mean, Median, Mode? frequency Mean, Median, Mode? frequency Mean, Median, Mode? frequency Mean, Median, Mode? mean median modes mode mean median frequency no mode mean (a) median (b) frequency mode mode median median (c) mean mean frequency frequency frequency (d) (e) Which to Use: Mean, Median, Mode? Which to Use: Mean, Median, Mode? • Mean many statistical tests that use sample ‒ Estimator of population mean ‒ Uses all data Which to Use: Mean, Median, Mode? • Median is useful for skewed data ‒ e.g., income data (US Census) or housing prices (Zillo) ‒ e.g., Overwatch team (6 players): 5 people level 5, 1 person level 275 ₊ Mean is 50 - not so useful since no one at this level ₊ Median is 5 – perhaps more representative ‒ Does not use all data. -

The Need to Measure Variance in Experiential Learning and a New Statistic to Do So
Developments in Business Simulation & Experiential Learning, Volume 26, 1999 THE NEED TO MEASURE VARIANCE IN EXPERIENTIAL LEARNING AND A NEW STATISTIC TO DO SO John R. Dickinson, University of Windsor James W. Gentry, University of Nebraska-Lincoln ABSTRACT concern should be given to the learning process rather than performance outcomes. The measurement of variation of qualitative or categorical variables serves a variety of essential We contend that insight into process can be gained purposes in simulation gaming: de- via examination of within-student and across-student scribing/summarizing participants’ decisions for variance in decision-making. For example, if the evaluation and feedback, describing/summarizing role of an experiential exercise is to foster trial-and- simulation results toward the same ends, and error learning, the variance in a student’s decisions explaining variation for basic research purposes. will be greatest when the trial-and-error stage is at Extant measures of dispersion are not well known. its peak. To the extent that the exercise works as Too, simulation gaming situations are peculiar in intended, greater variances would be expected early that the total number of observations available-- in the game play as opposed to later, barring the usually the number of decision periods or the game world encountering a discontinuity. number of participants--is often small. Each extant measure of dispersion has its own limitations. On the other hand, it is possible that decisions may Common limitations are that, under ordinary be more consistent early and then more variable later circumstances and especially with small numbers if the student is trying to recover from early of observations, a measure may not be defined and missteps. -
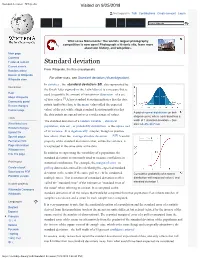
Standard Deviation - Wikipedia Visited on 9/25/2018
Standard deviation - Wikipedia Visited on 9/25/2018 Not logged in Talk Contributions Create account Log in Article Talk Read Edit View history Wiki Loves Monuments: The world's largest photography competition is now open! Photograph a historic site, learn more about our history, and win prizes. Main page Contents Featured content Standard deviation Current events Random article From Wikipedia, the free encyclopedia Donate to Wikipedia For other uses, see Standard deviation (disambiguation). Wikipedia store In statistics , the standard deviation (SD, also represented by Interaction the Greek letter sigma σ or the Latin letter s) is a measure that is Help used to quantify the amount of variation or dispersion of a set About Wikipedia of data values.[1] A low standard deviation indicates that the data Community portal Recent changes points tend to be close to the mean (also called the expected Contact page value) of the set, while a high standard deviation indicates that A plot of normal distribution (or bell- the data points are spread out over a wider range of values. shaped curve) where each band has a Tools The standard deviation of a random variable , statistical width of 1 standard deviation – See What links here also: 68–95–99.7 rule population, data set , or probability distribution is the square root Related changes Upload file of its variance . It is algebraically simpler, though in practice [2][3] Special pages less robust , than the average absolute deviation . A useful Permanent link property of the standard deviation is that, unlike the variance, it Page information is expressed in the same units as the data. -

Ideological Profiles of the Economics Laureates · Econ Journal Watch
Discuss this article at Journaltalk: http://journaltalk.net/articles/5811 ECON JOURNAL WATCH 10(3) September 2013: 255-682 Ideological Profiles of the Economics Laureates LINK TO ABSTRACT This document contains ideological profiles of the 71 Nobel laureates in economics, 1969–2012. It is the chief part of the project called “Ideological Migration of the Economics Laureates,” presented in the September 2013 issue of Econ Journal Watch. A formal table of contents for this document begins on the next page. The document can also be navigated by clicking on a laureate’s name in the table below to jump to his or her profile (and at the bottom of every page there is a link back to this navigation table). Navigation Table Akerlof Allais Arrow Aumann Becker Buchanan Coase Debreu Diamond Engle Fogel Friedman Frisch Granger Haavelmo Harsanyi Hayek Heckman Hicks Hurwicz Kahneman Kantorovich Klein Koopmans Krugman Kuznets Kydland Leontief Lewis Lucas Markowitz Maskin McFadden Meade Merton Miller Mirrlees Modigliani Mortensen Mundell Myerson Myrdal Nash North Ohlin Ostrom Phelps Pissarides Prescott Roth Samuelson Sargent Schelling Scholes Schultz Selten Sen Shapley Sharpe Simon Sims Smith Solow Spence Stigler Stiglitz Stone Tinbergen Tobin Vickrey Williamson jump to navigation table 255 VOLUME 10, NUMBER 3, SEPTEMBER 2013 ECON JOURNAL WATCH George A. Akerlof by Daniel B. Klein, Ryan Daza, and Hannah Mead 258-264 Maurice Allais by Daniel B. Klein, Ryan Daza, and Hannah Mead 264-267 Kenneth J. Arrow by Daniel B. Klein 268-281 Robert J. Aumann by Daniel B. Klein, Ryan Daza, and Hannah Mead 281-284 Gary S. Becker by Daniel B.