Major Qualifying Project
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Netcat and Trojans/Backdoors
Netcat and Trojans/Backdoors ECE4883 – Internetwork Security 1 Agenda Overview • Netcat • Trojans/Backdoors ECE 4883 - Internetwork Security 2 Agenda Netcat • Netcat ! Overview ! Major Features ! Installation and Configuration ! Possible Uses • Netcat Defenses • Summary ECE 4883 - Internetwork Security 3 Netcat – TCP/IP Swiss Army Knife • Reads and Writes data across the network using TCP/UDP connections • Feature-rich network debugging and exploration tool • Part of the Red Hat Power Tools collection and comes standard on SuSE Linux, Debian Linux, NetBSD and OpenBSD distributions. • UNIX and Windows versions available at: http://www.atstake.com/research/tools/network_utilities/ ECE 4883 - Internetwork Security 4 Netcat • Designed to be a reliable “back-end” tool – to be used directly or easily driven by other programs/scripts • Very powerful in combination with scripting languages (eg. Perl) “If you were on a desert island, Netcat would be your tool of choice!” - Ed Skoudis ECE 4883 - Internetwork Security 5 Netcat – Major Features • Outbound or inbound connections • TCP or UDP, to or from any ports • Full DNS forward/reverse checking, with appropriate warnings • Ability to use any local source port • Ability to use any locally-configured network source address • Built-in port-scanning capabilities, with randomizer ECE 4883 - Internetwork Security 6 Netcat – Major Features (contd) • Built-in loose source-routing capability • Can read command line arguments from standard input • Slow-send mode, one line every N seconds • Hex dump of transmitted and received data • Optional ability to let another program service established connections • Optional telnet-options responder ECE 4883 - Internetwork Security 7 Netcat (called ‘nc’) • Can run in client/server mode • Default mode – client • Same executable for both modes • client mode nc [dest] [port_no_to_connect_to] • listen mode (-l option) nc –l –p [port_no_to_connect_to] ECE 4883 - Internetwork Security 8 Netcat – Client mode Computer with netcat in Client mode 1. -

Ncircle IP360
VULNERABILITY MANAGEMENT TECHNOLOGY REPORT nCircle IP360 OCTOBER 2006 www.westcoastlabs.org 2 VULNERABILITY MANAGEMENT TECHNOLOGY REPORT CONTENTS nCircle IP360 nCircle, 101 Second Street, Suite 400, San Francisco, CA 94105 Phone: +1 (415) 625 5900 • Fax: +1 (415) 625 5982 Test Environment and Network ................................................................3 Test Reports and Assessments ................................................................4 Checkmark Certification – Standard and Premium ....................................5 Vulnerabilities..........................................................................................6 West Coast Labs Vulnerabilities Classification ..........................................7 The Product ............................................................................................8 Developments in the IP360 Technology ....................................................9 Test Report ............................................................................................10 Test Results ............................................................................................17 West Coast Labs Conclusion....................................................................18 Security Features Buyers Guide ..............................................................19 West Coast Labs, William Knox House, Britannic Way, Llandarcy, Swansea, SA10 6EL, UK. Tel : +44 1792 324000, Fax : +44 1792 324001. www.westcoastlabs.org VULNERABILITY MANAGEMENT TECHNOLOGY REPORT 3 TEST ENVIRONMENT -

List of TCP and UDP Port Numbers from Wikipedia, the Free Encyclopedia
List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the transport layer of the Internet Protocol Suite for the establishment of host-to-host connectivity. Originally, port numbers were used by the Network Control Program (NCP) in the ARPANET for which two ports were required for half- duplex transmission. Later, the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) needed only one port for full- duplex, bidirectional traffic. The even-numbered ports were not used, and this resulted in some even numbers in the well-known port number /etc/services, a service name range being unassigned. The Stream Control Transmission Protocol database file on Unix-like operating (SCTP) and the Datagram Congestion Control Protocol (DCCP) also systems.[1][2][3][4] use port numbers. They usually use port numbers that match the services of the corresponding TCP or UDP implementation, if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[5] However, many unofficial uses of both well-known and registered port numbers occur in practice. Contents 1 Table legend 2 Well-known ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Official: Port is registered with IANA for the application.[5] Unofficial: Port is not registered with IANA for the application. Multiple use: Multiple applications are known to use this port. Well-known ports The port numbers in the range from 0 to 1023 are the well-known ports or system ports.[6] They are used by system processes that provide widely used types of network services. -

How to Cheat at Configuring Open Source Security Tools
436_XSS_FM.qxd 4/20/07 1:18 PM Page ii 441_HTC_OS_FM.qxd 4/12/07 1:32 PM Page i Visit us at www.syngress.com Syngress is committed to publishing high-quality books for IT Professionals and deliv- ering those books in media and formats that fit the demands of our customers. We are also committed to extending the utility of the book you purchase via additional mate- rials available from our Web site. SOLUTIONS WEB SITE To register your book, visit www.syngress.com/solutions. Once registered, you can access our [email protected] Web pages. There you may find an assortment of value- added features such as free e-books related to the topic of this book, URLs of related Web sites, FAQs from the book, corrections, and any updates from the author(s). ULTIMATE CDs Our Ultimate CD product line offers our readers budget-conscious compilations of some of our best-selling backlist titles in Adobe PDF form. These CDs are the perfect way to extend your reference library on key topics pertaining to your area of expertise, including Cisco Engineering, Microsoft Windows System Administration, CyberCrime Investigation, Open Source Security, and Firewall Configuration, to name a few. DOWNLOADABLE E-BOOKS For readers who can’t wait for hard copy, we offer most of our titles in downloadable Adobe PDF form. These e-books are often available weeks before hard copies, and are priced affordably. SYNGRESS OUTLET Our outlet store at syngress.com features overstocked, out-of-print, or slightly hurt books at significant savings. SITE LICENSING Syngress has a well-established program for site licensing our e-books onto servers in corporations, educational institutions, and large organizations. -
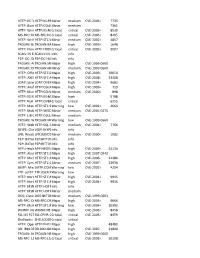
HTTP: IIS "Propfind" Rem HTTP:IIS:PROPFIND Minor Medium
HTTP: IIS "propfind"HTTP:IIS:PROPFIND RemoteMinor DoS medium CVE-2003-0226 7735 HTTP: IkonboardHTTP:CGI:IKONBOARD-BADCOOKIE IllegalMinor Cookie Languagemedium 7361 HTTP: WindowsHTTP:IIS:NSIISLOG-OF Media CriticalServices NSIISlog.DLLcritical BufferCVE-2003-0349 Overflow 8035 MS-RPC: DCOMMS-RPC:DCOM:EXPLOIT ExploitCritical critical CVE-2003-0352 8205 HTTP: WinHelp32.exeHTTP:STC:WINHELP32-OF2 RemoteMinor Buffermedium Overrun CVE-2002-0823(2) 4857 TROJAN: BackTROJAN:BACKORIFICE:BO2K-CONNECT Orifice 2000Major Client Connectionhigh CVE-1999-0660 1648 HTTP: FrontpageHTTP:FRONTPAGE:FP30REG.DLL-OF fp30reg.dllCritical Overflowcritical CVE-2003-0822 9007 SCAN: IIS EnumerationSCAN:II:IIS-ISAPI-ENUMInfo info P2P: DC: DirectP2P:DC:HUB-LOGIN ConnectInfo Plus Plus Clientinfo Hub Login TROJAN: AOLTROJAN:MISC:AOLADMIN-SRV-RESP Admin ServerMajor Responsehigh CVE-1999-0660 TROJAN: DigitalTROJAN:MISC:ROOTBEER-CLIENT RootbeerMinor Client Connectmedium CVE-1999-0660 HTTP: OfficeHTTP:STC:DL:OFFICEART-PROP Art PropertyMajor Table Bufferhigh OverflowCVE-2009-2528 36650 HTTP: AXIS CommunicationsHTTP:STC:ACTIVEX:AXIS-CAMERAMajor Camerahigh Control (AxisCamControl.ocx)CVE-2008-5260 33408 Unsafe ActiveX Control LDAP: IpswitchLDAP:OVERFLOW:IMAIL-ASN1 IMail LDAPMajor Daemonhigh Remote BufferCVE-2004-0297 Overflow 9682 HTTP: AnyformHTTP:CGI:ANYFORM-SEMICOLON SemicolonMajor high CVE-1999-0066 719 HTTP: Mini HTTP:CGI:W3-MSQL-FILE-DISCLSRSQL w3-msqlMinor File View mediumDisclosure CVE-2000-0012 898 HTTP: IIS MFCHTTP:IIS:MFC-EXT-OF ISAPI FrameworkMajor Overflowhigh (via -

Hacking for Dummies.Pdf
01 55784X FM.qxd 3/29/04 4:16 PM Page i Hacking FOR DUMmIES‰ by Kevin Beaver Foreword by Stuart McClure 01 55784X FM.qxd 3/29/04 4:16 PM Page v 01 55784X FM.qxd 3/29/04 4:16 PM Page i Hacking FOR DUMmIES‰ by Kevin Beaver Foreword by Stuart McClure 01 55784X FM.qxd 3/29/04 4:16 PM Page ii Hacking For Dummies® Published by Wiley Publishing, Inc. 111 River Street Hoboken, NJ 07030-5774 Copyright © 2004 by Wiley Publishing, Inc., Indianapolis, Indiana Published by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permis- sion of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permission should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, (317) 572-3447, fax (317) 572-4447, e-mail: permcoordinator@ wiley.com. Trademarks: Wiley, the Wiley Publishing logo, For Dummies, the Dummies Man logo, A Reference for the Rest of Us!, The Dummies Way, Dummies Daily, The Fun and Easy Way, Dummies.com, and related trade dress are trademarks or registered trademarks of John Wiley & Sons, Inc. -

A Toolkit for Detecting and Analyzing Malicious Software
A Toolkit for Detecting and Analyzing Malicious Software Michael Weber, Matthew Schmid & Michael Schatz David Geyer Cigital, Inc. [email protected] Dulles, VA 20166 g fmweber, mschmid, mschatz @cigital.com Abstract the virus or Trojan horse performs malicious actions unbe- knownst to the user. These programs often propagate while In this paper we present PEAT: The Portable Executable attached to games or other enticing executables. Analysis Toolkit. It is a software prototype designed to pro- Malicious programmers have demonstrated their cre- vide a selection of tools that an analyst may use in order ativity by developing a great number of techniques through to examine structural aspects of a Windows Portable Ex- which malware can be attached to a benign host. Several ecutable (PE) file, with the goal of determining whether insertion methods are common, including appending new malicious code has been inserted into an application af- sections to an executable, appending the malicious code ter compilation. These tools rely on structural features of to the last section of the host, or finding an unused region executables that are likely to indicate the presence of in- of bytes within the host and writing the malicious content serted malicious code. The underlying premise is that typi- there. A less elegant but effective insertion method is to cal application programs are compiled into one binary, ho- simply overwrite parts of the host application. mogeneous from beginning to end with respect to certain Given the myriad ways malicious software can attach to structural features; any disruption of this homogeneity is a benign host it is often a time-consuming process to even a strong indicator that the binary has been tampered with. -

Back Door and Remote Administration Programs
By:By:XÇzXÇzAA TÅÅtÜTÅÅtÜ ]A]A `t{ÅÉÉw`t{ÅÉÉw SupervisedSupervised By:DrBy:Dr.. LoLo’’aiai TawalbehTawalbeh New York Institute of Technology (NYIT)-Jordan’s Campus 1 Eng. Ammar Mahmood 11/2/2006 Introduction A backdoor in a computer system (or cryptosystem or algorithm) is a method of bypassing normal authentication or securing remote access to a computer, while attempting to remain hidden from casual inspection.(unauthorized persons/systems) Most backdoors are autonomic malicious programs that must be somehow installed to a computer. Some parasites do not require the installation, as their parts are already integrated into particular SW running on a remote host. 11/2/2006 Eng. Ammar Mahmood 2 Introduction The backdoor may take the form of an installed program (e.g., Back Orifice or the Sony/BMG rootkit backdoor installed when any of millions of Sony music CDs were played on a Windows computer), or could be a modification to a legitimate program. 11/2/2006 Eng. Ammar Mahmood 3 Ways of Infection Typical backdoors can be accidentally installed by unaware users. Some backdoors come attached to e- mail messages or are downloaded from the Internet using file sharing programs. Their authors give them unsuspicious names and trick users into opening or executing such files (Trojan horse ). Backdoors often are installed by other parasites like viruses, worms or even spyware (even antispyware e.g. AdWare SpyWare SE ). They get into the system without user knowledge and consent and affect everybody who uses a compromised computer. Some threats can be manually installed by malicious local users who have sufficient privileges for the software installation. -

Security Management Server Virtual V9.8
Security Management Server Virtual - AdminHelp v9.8 Table of Contents Welcome ......................................................................................................................... 1 About the Online Help System ............................................................................................ 1 Attributions, Copyrights, and Trademarks .............................................................................. 1 Get Started ..................................................................................................................... 15 Get Started with Dell Data Security ..................................................................................... 15 Log In ......................................................................................................................... 15 Log Out ....................................................................................................................... 15 Dashboard ................................................................................................................... 16 Change the Superadmin Password ....................................................................................... 18 Components .................................................................................................................... 19 Remote Management Console ............................................................................................ 19 Default Port Values ....................................................................................................... -

ISS Internet Scanner
VULNERABILITY ASSESSMENT TECHNOLOGY REPORT ISS Internet Scanner OCTOBER 2006 www.westcoastlabs.org 2 VULNERABILITY ASSESSMENT TECHNOLOGY REPORT CONTENTS ISS Internet Scanner Internet Security Systems, 6303 Barfield Road, Atlanta, GA 30328, USA Phone: +1-404-236-2700 Test Environment and Network ................................................................3 Test Reports and Assessments ................................................................4 Checkmark Certification – Standard and Premium ....................................5 Vulnerabilities..........................................................................................6 West Coast Labs Vulnerabilities Classification ..........................................7 The Product ............................................................................................8 Developments in the Internet Scanner Technology ....................................9 Test Report ............................................................................................10 Test Results ............................................................................................17 West Coast Labs Conclusion....................................................................18 Security Features Buyers Guide ..............................................................19 West Coast Labs, William Knox House, Britannic Way, Llandarcy, Swansea, SA10 6EL, UK. Tel : +44 1792 324000, Fax : +44 1792 324001. www.westcoastlabs.org VULNERABILITY ASSESSMENT TECHNOLOGY REPORT 3 TEST ENVIRONMENT AND -

Back Orifice Download Hacker
Back Orifice Download Hacker 1 / 4 Back Orifice Download Hacker 2 / 4 3 / 4 Surely you've heard the news already: Back Orifice 2000 (BO2K) is floating ... never download software from unknown vendors or software authors; don't let .... The program BO2K was written by DilDog of the hacking and phreaking group Cult of the Dead Cow and was based on the previous BO codes of SirDystic released in August '98 (also a cDc member). They provide this program absolutely free to download at their website www.bo2k.com.. Download: R.A.T, Crypter, Binder, Source Code, Botnet.... Back Orifice 2000 is a new version of the famous Back Orifice backdoor trojan (hacker's remote access tool). It was created by the Cult of Dead Cow hackers .... 1999-0660 "A hacker utility or Trojan Horse installed on a system… ... An intruder can download files from a Back Orifice system by sending a.. "Back Orifice" is a hacker's dream, and a Netizen's nightmare. ... It has reportedly been downloaded by well over 100,000 people since then.. Some hackers download files and steal passwords. ... Several RATs are frequently found in the wild, including Back Orifice, NetBus, Subseven, and DeepThroat.. Back Orifice - Windows Remote Administration Tool, by the cDc. ... The controversial Windows Remote Administration/Hacking Tool/Trojan has been ported ... tags | trojan: MD5 | 83e687476c2db91023c227524a676781: Download | Favorite .... I also downloaded the code of Back Orifice 2000. Even though these codes are called the Hacker Tool, it is very interesting to me about Internet code like socket, .... ... Thomas Cook's currency exchange site Microsoft: Back-door hack no threat to .. -

Chapter 10 Phase 4: Maintaining Access
Chapter 10 Phase 4: Maintaining Access Trojan Horses ♦ Software program containing a concealed malicious capability but appears to be benign, useful, or attractive to users Backdoor ♦ Software that allows an attacker to access a machine using an alternative entry method ♦ Installed by attackers after a machine has been compromised ♦ May Permit attacker to access a computer without needing to provide account names and passwords ♦ Used in movie “War Games” ♦ Can be sshd listening to a port other than 22 ♦ Can be setup using Netcat Netcat as a Backdoor ♦ A popular backdoor tool ♦ Netcat must be compiled with “GAPING_SECURITY_HOLE” option ♦ On victim machine, run Netcat in listener mode with –e flag to execute a specific program such as a command shell ♦ On attacker’s machine run Netcat in client mode to connect to backdoor on victim Running Netcat as a Backdoor on Unix Note: on attacker’s machine, run “nc victim 12345” Running Netcat as a Backdoor on WinNT/2000 Trojan Horse Backdoors ♦ Programs that combine features of backdoors and Trojan horses – Not all backdoors are Trojan horses – Not all Trojan horses are backdoors ♦ Programs that seem useful but allows an attacker to access a system and bypass security controls Categories of Trojan Horse Backdoors ♦ Application-level Trojan Horse Backdoor – A separate application runs on the system that provides backdoor access to attacker ♦ Traditional RootKits – Critical operating system executables are replaced by attacker to create backdoors and facilitate hiding ♦ Kernel-level RootKits – Operating