High-Performance Local Area Communication with Fast Sockets
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Libioth (Slides)
libioth The definitive API for the Internet of Threads Renzo Davoli – Michael Goldweber "niversit$ o% Bolo&na '(taly) – *avier "niver#it$ (Cin!innati, "SA) ,irt-alS.-are Micro/ernel DevRoo0 1 © 2021 Davoli-Goldweber libioth. CC-BY-SA 4.0 (nternet of Thread# (IoTh) service1.company.com → 2001:1:2::1 service2.company.com → 2001:1:2::2 host.company.com→11.12.13.14 processes service3.company.com → 2001:1:2::3 2 © 2021 Davoli-Goldweber libioth. CC-BY-SA 4.0 IoTh vs Iold What is an end-node o% the (nternet4 (t depends on what is identified b$ an (P addre##. ● (nternet o% 1hreads – (oTh – 7roce##e#8threads are a-tonomou# nodes of the (nternet ● (nternet o% 9e&ac$ Devi!es 'in brie% (-old in this presentation) – (nternet o% :ost# – Internet of ;etwork Controller#. – (nternet o% ;a0e#5a!e# 2 © 2021 Davoli-Goldweber libioth. CC-BY-SA 4.0 7,M – IoTh - </ernel 4 © 2021 Davoli-Goldweber libioth. CC-BY-SA 4.0 7,M – IoTh - </ernel ● icro/ernel, Internet o% Threads, Partial Virtual a!hines have the co00on goal to create independent code units i05lementing services ● 1hey are all against monolithic i05lementation# ● 1he challenge o% this talk is to !reate !ontacts, e>5loit paralleli#0#+ that allow to share res-lts, A7I, code. = © 2021 Davoli-Goldweber libioth. CC-BY-SA 4.0 Network Sta!/ ● API to application layer TCP-IP stack TCP UDP IPv4 IPv6 ICMP(v4,v6) ● API (NPI) to data-link – (e.g. libioth uses VDE: libvdeplug) ? © 2021 Davoli-Goldweber libioth. CC-BY-SA 4.0 IoTh & </ernel User process User process TCP-IP stack TCP UDP TCP/IP stack process IPv4 IPv6 ICMP(v4,v6) TCP-IP stack TCP UDP IPv4 IPv6 ICMP(v4,v6) Data-link network server Data-link network server @ © 2021 Davoli-Goldweber libioth. -

Improving Networking
IMPERIAL COLLEGE LONDON FINALYEARPROJECT JUNE 14, 2010 Improving Networking by moving the network stack to userspace Author: Matthew WHITWORTH Supervisor: Dr. Naranker DULAY 2 Abstract In our modern, networked world the software, protocols and algorithms involved in communication are among some of the most critical parts of an operating system. The core communication software in most modern systems is the network stack, but its basic monolithic design and functioning has remained unchanged for decades. Here we present an adaptable user-space network stack, as an addition to my operating system Whitix. The ideas and concepts presented in this report, however, are applicable to any mainstream operating system. We show how re-imagining the whole architecture of networking in a modern operating system offers numerous benefits for stack-application interactivity, protocol extensibility, and improvements in network throughput and latency. 3 4 Acknowledgements I would like to thank Naranker Dulay for supervising me during the course of this project. His time spent offering constructive feedback about the progress of the project is very much appreciated. I would also like to thank my family and friends for their support, and also anybody who has contributed to Whitix in the past or offered encouragement with the project. 5 6 Contents 1 Introduction 11 1.1 Motivation.................................... 11 1.1.1 Adaptability and interactivity.................... 11 1.1.2 Multiprocessor systems and locking................ 12 1.1.3 Cache performance.......................... 14 1.2 Whitix....................................... 14 1.3 Outline...................................... 15 2 Hardware and the LDL 17 2.1 Architectural overview............................. 17 2.2 Network drivers................................. 18 2.2.1 Driver and device setup....................... -

Post Sockets - a Modern Systems Network API Mihail Yanev (2065983) April 23, 2018
Post Sockets - A Modern Systems Network API Mihail Yanev (2065983) April 23, 2018 ABSTRACT In addition to providing native solutions for problems, es- The Berkeley Sockets API has been the de-facto standard tablishing optimal connection with a Remote point or struc- systems API for networking. However, designed more than tured data communication, we have identified that a com- three decades ago, it is not a good match for the networking mon issue with many of the previously provided networking applications today. We have identified three different sets of solutions has been leaving the products vulnerable to code problems in the Sockets API. In this paper, we present an injections and/or buffer overflow attacks. The root cause implementation of Post Sockets - a modern API, proposed by for such problems has mostly proved to be poor memory Trammell et al. that solves the identified limitations. This or resource management. For this reason, we have decided paper can be used for basis of evaluation of the maturity of to use the Rust programming language to implement the Post Sockets and if successful to promote its introduction as new API. Rust is a programming language, that provides a replacement API to Berkeley Sockets. data integrity and memory safety guarantees. It uses region based memory, freeing the programmer from the responsibil- ity of manually managing the heap resources. This in turn 1. INTRODUCTION eliminates the possibility of leaving the code vulnerable to Over the years, writing networked applications has be- resource management errors, as this is handled by the lan- come increasingly difficult. -

Introduction to RAW-Sockets Jens Heuschkel, Tobias Hofmann, Thorsten Hollstein, Joel Kuepper
Introduction to RAW-sockets Jens Heuschkel, Tobias Hofmann, Thorsten Hollstein, Joel Kuepper 16.05.2017 Technical Report No. TUD-CS-2017-0111 Technische Universität Darmstadt Telecooperation Report No. TR-19, The Technical Reports Series of the TK Research Division, TU Darmstadt ISSN 1864-0516 http://www.tk.informatik.tu-darmstadt.de/de/publications/ Introduction to RAW-sockets by Heuschkel, Jens Hofmann, Tobias Hollstein, Thorsten Kuepper, Joel May 17, 2017 Abstract This document is intended to give an introduction into the programming with RAW-sockets and the related PACKET-sockets. RAW-sockets are an additional type of Internet socket available in addition to the well known DATAGRAM- and STREAM-sockets. They do allow the user to see and manipulate the information used for transmitting the data instead of hiding these details, like it is the case with the usually used STREAM- or DATAGRAM sockets. To give the reader an introduction into the subject we will first give an overview about the different APIs provided by Windows, Linux and Unix (FreeBSD, Mac OS X) and additional libraries that can be used OS-independent. In the next section we show general problems that have to be addressed by the programmer when working with RAW-sockets. We will then provide an introduction into the steps necessary to use the APIs or libraries, which functionality the different concepts provide to the programmer and what they provide to simplify using RAW and PACKET-sockets. This section includes examples of how to use the different functions provided by the APIs. Finally in the additional material we will give some complete examples that show the concepts and can be used as a basis to write own programs. -

Freertos and TCP/IP Communication: the Lwip Library
Advanced School on Programmable System-on-Chip for Scientific Instrumentation FreeRTOS and TCP/IP communication: the lwIP library Fernando Rincón [email protected] Smr3160 – ICTP (Nov. & Dic. 2017) Con%en%& ● T'e l$IP TCP/IP s%ac) – The ne%work &%ac) – The socke% conce*% ● +**#ica%ion Arc'i%ec%,res ● #$IP and FreeRT!S ● '%%*&-(($$$.xi#in..com(video(&oc/net$orking-wi%'0#$i*01oc,&ed01ree0 r%o&.h%ml 2 FreeRT!S + lwIP Smr3160 – ICTP (Nov. & Dic. 2017) #$IP TCP/IP stac) ● #$IP stand& for 2i/'%$ei/'t IP: – Sma## foo%*rin% im*#emen%a%ion – S*ecia##3 $el# &,i%ed 1or embedded sy&%ems ● Su**orts a large n,mber of protoco#& – 5DP, TCP, ICMP6 ARP, ... ● API&- – Ber)e#e3 &oc)et&- ● re9,ire& an !.S. – Ra$ API ● Wi%' or $i%'o,t !S ● 7ore contro#6 b,t more comp#e. to u&e ● Inc#,ded in xilin. SD; – +#&o incl,des driver for <i#in. =%'erne% driver – <+PP1026 is %'e reference a**#ica%ion no%e 3 FreeRT!S + lwIP Smr3160 – ICTP (Nov. & Dic. 2017) T'e network stack ● T'e net$ork desi/n i& organi>ed a& a layer s%ac). ● =ac' layer provides a set o1 service& to t'e up*er layer and req,ires &ervice& from t'e lo$er layer. ● T'e la3er 'n' o1 a node main%ain& a virt,a# conver&a%ion wi%' t'e same #a3er t'e des%ina%ion node. T'a% conver&a%ion m,&% mee% a s*eci@c *ro%oco#. -

STREAMS Vs. Sockets Performance Comparison for UDP
STREAMS vs. Sockets Performance Comparison for UDP Experimental Test Results for Linux Brian F. G. Bidulock∗ OpenSS7 Corporation June 16, 2007 Abstract cations facilities of the kernel: With the objective of contrasting performance between Transport Layer Interface (TLI). TLI is an acronym for the STREAMS and legacy approaches to system facilities, a com- Transport Layer Interface [TLI92]. The TLI was the non- parison is made between the tested performance of the Linux Na- standard interface provided by SVR4, later standardized by tive Sockets UDP implementation and STREAMS TPI UDP and X/Open as the XTI described below. This interface is now XTIoS UDP implementations using the Linux Fast-STREAMS deprecated. package [LfS]. X/Open Transport Interface (XTI). XTI is an acronym for the X/Open Transport Interface [XTI99]. The X/Open Trans- 1 Background port Interface is a standardization of the UNIX System V UNIX networking has a rich history. The TCP/IP protocol suite Release 4, Transport Layer Interface. The interface con- was first implemented by BBN using Sockets under a DARPA re- sists of an Application Programming Interface implemented search project on 4.1aBSD and then incorporated by the CSRG as a shared object library. The shared object library com- into 4.2BSD [MBKQ97]. Lachmann and Associates (Legent) sub- municates with a transport provider Stream using a service sequently implemented one of the first TCP/IP protocol suite primitive interface called the Transport Provider Interface. based on the Transport Provider Interface (TPI) [TLI92] and While XTI was implemented directly over STREAMS de- STREAMS [GC94]. Two other predominant TCP/IP implemen- vices supporting the Transport Provider Interface (TPI) tations on STREAMS surfaced at about the same time: Wollon- [TPI99] under SVR4, several non-traditional approaches ex- gong and Mentat. -

Transport Layer Socket Programming
Part 4 TRANSPORT LAYER SOCKET PROGRAMMING Client Server Programming - Slide Figures/quotes from Andrew Tanenbaum Computer Networks book (Teacher Slides) 1 Transport Layer Data transmission service goals for the application layer Efficiency Reliability Accuracy Cost-effective The entity that does the work is called the transport entity The transport entity Is usually part of the operating system kernel sometimes a separate library package which is loaded by the OS or even user processes And sometimes even on the network interface card The transport entity (TCP) employs the services of the network layer (IP), and its associated software and hardware (cards and device drivers) Client Server Programming - Slide Figures/quotes from Andrew Tanenbaum Computer Networks book (Teacher Slides) 2 Transport Layer The transport entity code runs entirely on users machines, but the network layer mostly runs on routers, cards, and other bridging hardware Bridging hardware is inherently unreliable and uncontrollable Ethernet cards, routers, and similar hardware do not contain adequate software for detecting and correcting errors To solve this problem we must add another layer that improves the quality of the service: the transport entity detects network problems: packet losses, packet errors, delays, etc. and then fixes these problems by: retransmissions, error corrections, synchronization, and connection resets Transport layer interface must be simple and convenient to use since it is intended for a human user Client Server Programming -

Socket Programming
Socket Programming Nikhil Shetty GSI, EECS122 Spring 2007 Outline • APIs – Motivation • Sockets • C Socket APIs • Tips for programming What is an API? • API – stands for Application Programming Interface What is an API? • API – stands for Application Programming Interface. • Interface to what? – In our case, it is an interface to use the network. What is an API? • API – stands for Application Programming Interface. • Interface to what? – In our case, it is an interface to use the network. • A connection to the transport layer. What is an API? • API – stands for Application Programming Interface. • Interface to what? – In our case, it is an interface to use the network. • A connection to the transport layer. • WHY DO WE NEED IT? Need for API • One Word - Layering • Functions at transport layer and below very complex. • E.g. Imagine having to worry about errors on the wireless link and signals to be sent on the radio. • Helps in code reuse. APPLICATION API TRANSPORT NETWORK LINK PHYSICAL Layering Diagramatically Application API System Calls LAN Card Radio What is a socket then? • What is a socket? Introduction • What is a socket? • It is an abstraction that is provided to an application programmer to send or receive data to another process. Introduction • What is a socket? • It is an abstraction that is provided to an application programmer to send or receive data to another process. • Data can be sent to or received from another process running on the same machine or a different machine. • In short, it is an end point of a data connection. Socket – An Abstraction Adapted from http://www.troubleshooters.com/codecorn/sockets/ Sockets • It is like an endpoint of a connection • Exists on either side of connection • Identified by IP Address and Port number • E.g. -
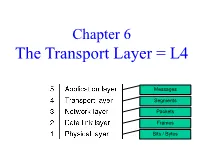
The Transport Layer = L4
Chapter 6 The Transport Layer = L4 Messages Segments Packets Frames Bits / Bytes L2-L3-L4 encapsulation Transport layer sends segments in packets (in frames) Segment Frame trailer Segment Interactions L3-L4-L5 Transport layer offers connectionless (UDP) and connection- oriented (TCP) service to applications L4 vs. L3 L3 is “hop-by-hop”, operating on the source host, destination host, and on all the routers in the network. L4 is “end-to-end”, operating only on the source host and destination host! • The users have no control over the network, esp. when there are multiple networks in between • L3 does not retransmit pkts. (it just sends error notifications via ICMP), i.e. it is unreliable • L4 provides end-to-end reliability, i.e. it provides reliable service to L5 • Yes, L4 also provides unreliable service (UDP), but that has very little functionality. Simplified Transport Service Primitives (offered by L4 to L5) Applications (L5) invoke these primitives to implement connection- oriented transport service. Scenario: one server and multiple clients: – Each client calls connect, send, receive, disconnect – Server calls listen, receive, send, disconnect Segment High-level state diagram of TCP connection life-cycle Dashed lines show server Solid lines show client state sequence state sequence Transitions in italics are due to segment arrivals. Real-life Transport Service Primitives Berkeley Sockets Very widely used primitives, started with TCP on UNIX • A “socket” is a transport endpoint, analogous to a hardware socket • Like simple set plus SOCKET, BIND, and ACCEPT Always executed in this order by a server Unlike the simplified model, here LISTEN is not blocking! Same as Returns file handle which can Symmetrical, i.e. -

Design and Research of Future Network (IPV9) API
International Journal of Advanced Network, Monitoring and Controls Volume 04, No.04, 2019 Design and Research of Future Network (IPV9) API Xu Yinqiu Xie Jianping Shanghai Decimal Network Information Shanghai Decimal Network Information Technology Co. Ltd. Technology Co. Ltd. E-mail: [email protected] E-mail: [email protected] Abstract—Socket is a way of process communication, that is protocol. Each socket has a socket number, including used it to invoke some API function to realize the distribution the IP address of the host and a 16-bit host port network libraries in different host of data exchange between number, such as (host IP address: port number). the relevant process. According to the TCP/IP protocol In short, Socket is equals to (IP address: port assigned to the network address of the local host, to number), which is represented by a decimal IP address communicate between the two processes, the host must know followed by a port number, separated by a colon or the other's location first, that is, the IP of the other host. At the comma. Each transport layer connection is uniquely same time, to get the port number, it is used to identify the identified by two terminals (that is, two sockets) at local communication process; a local process in communication each end of the communication. For example, if the will occupy a port number, different process port number is IPv4 address is 118.38.18.1 and the port number is 23, different, so it must be assigned a port number that is not used the resulting socket is (118.38.18.1:23), If the IPV9 before communication. -

The Berkeley Sockets API
The Berkeley Sockets API Networked Systems Architecture 3 Lecture 4 The Berkeley Sockets API • Widely used low-level C networking API • First introduced in 4.3BSD Unix • Now available on most platforms: Linux, MacOS X, Windows, FreeBSD, Solaris, etc. • Largely compatible cross-platform Concepts Application • Sockets provide a standard interface between network and application Two types of socket: Socket • • Stream – provides a virtual circuit service • Datagram – delivers individual packets • Independent of network type: • Commonly used with TCP/IP and UDP/IP, Network but not specific to the Internet protocols • Only discuss TCP/IP sockets today TCP/IP Connection Client Server fd fd connfd ? Network ? Socket Socket int fd = socket(...) int fd = socket(...) bind(fd, ..., ...) listen(fd, ...) connect(fd, ..., ...) connfd = accept(fd, ...) write(fd, data, datalen) read(connfd, buffer, buflen) read(fd, buffer, buflen) write(connfd, data, datalen) close(fd) close(connfd) TCP/IP Connection Server fd = socket(…); Client bind(fd, …); Specify well-known port fd = socket(…); listen(fd, …); Begin listening TCP/IP connection established connect(fd, …); connfd = accept(fd, …); Block until connection established Send request write(fd, …); read(connfd, …); Wait for response read(fd, …); write(connfd, …); TCP/IP connection shutdown close(fd, …); read(connfd, …); EOF read close(connfd, …); Creating a socket #include <sys/socket.h><sys/types.h> #include <sys/socket.h> AF_INET for IPv4 AF_INET6 for IPv6 int fd; ... fd = socket(family, type, protocol); SOCK_STREAM for TCP if (fd == -1) { SOCK_DGRAM for UDP // Error: unable to create socket ... 0 (not used for Internet sockets) } ... Create an unbound socket, not connected to network; can be used as either a client or a server Handling Errors Socket functions return -1 and set the global variable errno on failure fd = socket(family, type, protocol); The Unix man pages should if (fd == -1) { switch (errno) { list the possible errors that case EPROTONOTSUPPORT : can occur for each function // Protocol not supported .. -

Socket Programming& Porting Linux On
Socket Programming& Porting Linux on (Raspberry/ARM) Jay Shakti1, Taniya Das2, Rachit Gupta3, Arimardan Singh4 Department of Electronics &Communication Engineering, IIMT College of Engineering Greater Noida, (India) ABSTRACT The aim of the paper is to introduce sockets, its deployment pertaining to network programming. Sockets play a vital role in client server applications. The client and server can communicate with each other by writing to or reading from these sockets. They were invented in Berkeley as part of the BSD flavor of UNIX operating systems. And they spread like wildfire with the Internet. This paper introduces elements of network programming and concepts involved in creating network applications using sockets. One of the most basic network programming tasks likely to be faced as a java programmer is performing the socket functions/methods because java has been preferred mostly for establishing client server communications using sockets. I.INTRODUCTION In the 1980s, the US government‟s Advanced Research Projects Agency (ARPA) provided funds to the University of California at Berkeley to implement TCP/IP protocols under the UNIX operating system. During this project, a group of Berkeley researchers developed an application program interface (API) for TCP/IP network communications called the socket interface. The socket interface is an API TCP/IP networks i.e. it defines a variety of software functions or routines for the development of applications for TCP/IP networks. The socket interface designers originally built their interface into the UNIX operating system. However, the other operating systems, environments, such as Microsoft Windows, implement the socket interface as software libraries. 66 | P a g e These sockets are the programming interfaces provided by the TCP and UDP protocols for stream and datagram communication respectively of the transport layer which is a part of the TCP/IP stack.