Vertical PDF Slides
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Apple, Inc. Collegiate Purchase Program Premier Price List January 11, 2011
Apple, Inc. Collegiate Purchase Program Premier Price List January 11, 2011 Revisions to the December 7, 2010 Collegiate Purchase Program Premier Price List Effective January 11, 2011 PRODUCTS ADDED TO THE PRICE LIST PRODUCTS REPRICED ON THE PRICE LIST PRODUCTS REMOVED FROM THE PRICE LIST This Price List supersedes all previous Price Lists. Products subject to discontinuation without notice. Prices subject to change without notice. Education Solutions Apple iPod Learning Lab The Apple iPod Learning Lab provides schools with the ideal solution for managing multiple iPod devices in the classroom. The solution includes (20) iPod touch 8GB devices housed in a durable and easy-to-use Apple-exclusive mobile cart capable of storing and charging up to 40 iPod devices. The cart's ability to sync up to 20 iPod devices at a time from one computer makes it quick and easy to set up the devices for student use. The mobile cart's secure, roll-top door can be locked for safe iPod storage. The cart also includes room for storage of up to four notebook computers and a variety of iPod accessories. And, because the cart is mobile, it can be easily shared among multiple classrooms. Choose one of the pre-configured solutions below, or build your own custom iPod lab by visiting http://edu1.apple.com/custom_ipod_lab/. Recommended add-ons: The MacBook is an ideal companion for the Apple iPod Learning Lab. Create compelling education content with iLife and organize and share that content via iTunes. Apple Professional Development prepares teachers to effectively integrate iPod devices and podcasting into their curriculum. -

A Survey of Smartwatch Platforms from a Developer's Perspective
Grand Valley State University ScholarWorks@GVSU Technical Library School of Computing and Information Systems 2015 A Survey of Smartwatch Platforms from a Developer’s Perspective Ehsan Valizadeh Grand Valley State University Follow this and additional works at: https://scholarworks.gvsu.edu/cistechlib ScholarWorks Citation Valizadeh, Ehsan, "A Survey of Smartwatch Platforms from a Developer’s Perspective" (2015). Technical Library. 207. https://scholarworks.gvsu.edu/cistechlib/207 This Project is brought to you for free and open access by the School of Computing and Information Systems at ScholarWorks@GVSU. It has been accepted for inclusion in Technical Library by an authorized administrator of ScholarWorks@GVSU. For more information, please contact [email protected]. A Survey of Smartwatch Platforms from a Developer’s Perspective By Ehsan Valizadeh April, 2015 A Survey of Smartwatch Platforms from a Developer’s Perspective By Ehsan Valizadeh A project submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Information Systems At Grand Valley State University April, 2015 ________________________________________________________________ Dr. Jonathan Engelsma April 23, 2015 ABSTRACT ................................................................................................................................................ 5 INTRODUCTION ...................................................................................................................................... 6 WHAT IS A SMARTWATCH -
![Arxiv:1809.10387V1 [Cs.CR] 27 Sep 2018 IEEE TRANSACTIONS on SUSTAINABLE COMPUTING, VOL](https://docslib.b-cdn.net/cover/6402/arxiv-1809-10387v1-cs-cr-27-sep-2018-ieee-transactions-on-sustainable-computing-vol-586402.webp)
Arxiv:1809.10387V1 [Cs.CR] 27 Sep 2018 IEEE TRANSACTIONS on SUSTAINABLE COMPUTING, VOL
IEEE TRANSACTIONS ON SUSTAINABLE COMPUTING, VOL. X, NO. X, MONTH YEAR 0 This work has been accepted in IEEE Transactions on Sustainable Computing. DOI: 10.1109/TSUSC.2018.2808455 URL: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8299447&isnumber=7742329 IEEE Copyright Notice: c 2018 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. arXiv:1809.10387v1 [cs.CR] 27 Sep 2018 IEEE TRANSACTIONS ON SUSTAINABLE COMPUTING, VOL. X, NO. X, MONTH YEAR 1 Identification of Wearable Devices with Bluetooth Hidayet Aksu, A. Selcuk Uluagac, Senior Member, IEEE, and Elizabeth S. Bentley Abstract With wearable devices such as smartwatches on the rise in the consumer electronics market, securing these wearables is vital. However, the current security mechanisms only focus on validating the user not the device itself. Indeed, wearables can be (1) unauthorized wearable devices with correct credentials accessing valuable systems and networks, (2) passive insiders or outsider wearable devices, or (3) information-leaking wearables devices. Fingerprinting via machine learning can provide necessary cyber threat intelligence to address all these cyber attacks. In this work, we introduce a wearable fingerprinting technique focusing on Bluetooth classic protocol, which is a common protocol used by the wearables and other IoT devices. Specifically, we propose a non-intrusive wearable device identification framework which utilizes 20 different Machine Learning (ML) algorithms in the training phase of the classification process and selects the best performing algorithm for the testing phase. -

Smartwatch Security Research TREND MICRO | 2015 Smartwatch Security Research
Smartwatch Security Research TREND MICRO | 2015 Smartwatch Security Research Overview This report commissioned by Trend Micro in partnership with First Base Technologies reveals the security flaws of six popular smartwatches. The research involved stress testing these devices for physical protection, data connections and information stored to provide definitive results on which ones pose the biggest risk with regards to data loss and data theft. Summary of Findings • Physical device protection is poor, with only the Apple Watch having a lockout facility based on a timeout. The Apple Watch is also the only device which allowed a wipe of the device after a set number of failed login attempts. • All the smartwatches had local copies of data which could be accessed through the watch interface when taken out of range of the paired smartphone. If a watch were stolen, any data already synced to the watch would be accessible. The Apple Watch allowed access to more personal data than the Android or Pebble devices. • All of the smartwatches we tested were using Bluetooth encryption and TLS over WiFi (for WiFi enabled devices), so consideration has obviously been given to the security of data in transit. • Android phones can use ‘trusted’ Bluetooth devices (such as smartwatches) for authentication. This means that the smartphone will not lock if it is connected to a trusted smartwatch. Were the phone and watch stolen together, the thief would have full access to both devices. • Currently smartwatches do not allow the same level of interaction as a smartphone; however it is only a matter of time before they do. -

Mobius Smatwatches.Key
Разработка для Smart Watches: Apple WatchKit, Android Wear и TizenOS Agenda History Tizen for Wearable Apple Watch Android Wear QA History First Smart Watches Samsung SPH-WP10 1999 IBM Linux Watch 2000 Microsoft SPOT 2003 IBM Linux Watches Today Tizen for Wearable • Display: 360x380; 320x320 • Hardware: 512MB, 4GB, 1Ghz dual-core • Sensors • Accelerometer • Gyroscope • Compass (optional) • Heart Rate monitor (optional) • Ambient Light (optional) • UV (optional) • Barometer (optional) • Camera (optional) • Input • Touch • Microphone • Connectivity: BLE • Devices: Samsung Gear 2, Gear S, Gear, Gear Neo • Compatibility: Samsung smartphones Tizen: Samsung Gear S Tizen for Wearable: Development Tizen for Wearable: Development Tizen IDE Tizen Emulator Apple Watch • Display: 390x312; 340x272 • Hardware: 256M, 1 (2)Gb; Apple S 1 • Sensors: • Accelerometer • Gyroscope • Heart Rate monitor • Barometer • Input • digital crown • force touch • touch • microphone • Compatibility: iOS 8.2 • Devices: 24 types Apple Watch Apple Watch Kit Apple Watch kit: Watch Sim Android Wear • Display: Round; Rect • 320x290; 320x320, 280x280 • Hardware: 512MB, 4GB, 1Ghz (TIOMAP, Qualcomm) • Sensors • Accelerometer • Gyroscope (optional) • Compass (optional) • Heart Rate monitor (optional) • Ambient Light (optional) • UV (optional) • Barometer (optional) • GPS (optional) • Input • Touch • Microphone • Connectivity: BLE • Devices: Moto 360, LG G Watch, Gear Live, ZenWatch, Sony Smartwatch 3, LG G Watch R • Compatibility: Android 4.3 Android Wear Android Wear IDE Android -
The Ipad Comparison Chart Compare All Models of the Ipad
ABOUT.COM FOOD HEALTH HOME MONEY STYLE TECH TRAVEL MORE Search... About.com About Tech iPad iPad Hardware and Competition The iPad Comparison Chart Compare All Models of the iPad By Daniel Nations SHARE iPad Expert Ads iPAD Pro New Apple iPAD iPAD 2 iPAD Air iPAD Cases iPAD MINI2 Cheap Tablet PC Air 2 Case Used Computers iPAD Display The iPad has evolved since it was originally announced in January 2010. Sign Up for our The iPad 2 added dual-facing cameras Free Newsletters along with a faster processor and improved graphics, but the biggest jump About Apple was with the iPad 3, which increased the Tech Today resolution of the display to 2,048 x 1,536 iPad and added Siri for voice recognition. The iPad 4 was a super-charged iPad 3, with Enter your email around twice the processing power, and the iPad Mini, released alongside the iPad SIGN UP 4, was Apple's first 7.9-inch iPad. Two years ago, the iPad Air became the TODAY'S TOP 5 PICKS IN TECH first iPad to use a 64-bit chip, ushering IPAD CATEGORIES the iPad into a new era. We Go Hands-On 5 With the OnePlus X New to iPad: How to Get The latest in Apple's lineup include the By Faryaab Sheikh Started With Your iPad iPad Pro, which super-sizes the screen to Smartphones Expert The entire iPad family: Pro, Air and Mini. Image © 12.9 inches and is compatible with a new The Best of the iPad: Apps, Apple, Inc. -

Miniatured Inertial Motion and Position Tracking and Visualization Systems Using Android Wear Platform
MINIATURED INERTIAL MOTION AND POSITION TRACKING AND VISUALIZATION SYSTEMS USING ANDROID WEAR PLATFORM A thesis submitted in partial fulfillment of the requirement for the degree of Master of Science By DHRUVKUMAR NAVINCHANDRA PATEL B.E., Gujarat Technological University, 2014 2016 Wright State University WRIGHT STATE UNIVERSITY GRADUATE SCHOOL January 6th, 2017 I HEREBY RECOMMEND THAT THE THESIS PREPARED UNDER MY SUPERVISION BY Dhruvkumar Navinchandra Patel ENTITLED Miniatured Inertial Motion and Position Tracking and Visualization Systems Using Android Wear Platform BE ACCEPTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF Master of Science. _____________________________________ Yong Pei, Ph.D. Thesis Director _____________________________________ Mateen M. Rizki, Ph.D. Chair, Department of Computer Science and Engineering Committee on Final Examination _____________________________________ Yong Pei, Ph.D. _____________________________________ Mateen M. Rizki, Ph.D. _____________________________________ Paul Bender, Ph.D. _____________________________________ Robert E.W. Fyffe, Ph.D. Vice President for Research and Dean of the Graduate School ABSTRACT Patel, Dhruvkumar Navinchandra. M.S. Department of Computer Science and Engineering, Wright State University, 2016. Miniatured Inertial Motion and Position Tracking and Visualization Systems Using Android Wear Platform. In this thesis, we have designed and developed a motion tracking and visualization system using the latest motion tracking sensory technologies. It is one -

NVIDIA Tegra 4 Family CPU Architecture 4-PLUS-1 Quad Core
Whitepaper NVIDIA Tegra 4 Family CPU Architecture 4-PLUS-1 Quad core 1 Table of Contents ...................................................................................................................................................................... 1 Introduction .............................................................................................................................................. 3 NVIDIA Tegra 4 Family of Mobile Processors ............................................................................................ 3 Benchmarking CPU Performance .............................................................................................................. 4 Tegra 4 Family CPUs Architected for High Performance and Power Efficiency ......................................... 6 Wider Issue Execution Units for Higher Throughput ............................................................................ 6 Better Memory Level Parallelism from a Larger Instruction Window for Out-of-Order Execution ...... 7 Fast Load-To-Use Logic allows larger L1 Data Cache ............................................................................. 8 Enhanced branch prediction for higher efficiency .............................................................................. 10 Advanced Prefetcher for higher MLP and lower latency .................................................................... 10 Large Unified L2 Cache ....................................................................................................................... -
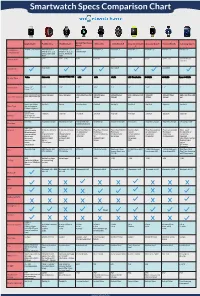
Smartwatch Specs Comparison Chart
Smartwatch Specs Comparison Chart Apple Watch Pebble Time Pebble Steel Alcatel One Touch Moto 360 LG G Watch R Sony Smartwatch Asus ZenWatch Huawei Watch Samsung Gear S Watch 3 Smartphone iPhone 5 and Newer Android OS 4.1+ Android OS 4.1+ iOS 7+ Android 4.3+ Android 4.3+ Android 4.3+ Android 4.3+ Android 4.3+ Android 4.3+ iPhone 4, 4s, 5, 5s, iPhone 4, 4s, 5, 5s, Android 4.3+ Compatibility and 5c, iOS 6 and and 5c, iOS 6 and iOS7 iOS7 Price in USD $349+ $299 $149 - $180 $149 $249.99 $299 $200 $199 $349 - 399 $299 $149 (w/ contract) May 2015 June 2015 June 2015 Availability Display Type Screen Size 38mm: 1.5” 1.25” 1.25” 1.22” 1.56” 1.3” 1.6” 1.64” 1.4” 2” 42mm: 1.65” 38mm: 340x272 (290 ppi) 144 x 168 pixel 144 x 168 pixel 204 x 204 Pixel 258 320x290 pixel 320x320 pixel 320 x 320 pixel 269 320x320 400x400 Pixel 480 x 360 Pixel 300 Screen Resolution 42mm: 390x312 (302 ppi) ppi 205 ppi 245 ppi ppi 278ppi 286 ppi ppi Sport: Ion-X Glass Gorilla 3 Gorilla Corning Glass Gorilla 3 Gorilla 3 Gorilla 3 Gorilla 3 Sapphire Gorilla 3 Glass Type Watch: Sapphire Edition: Sapphire 205mah Approx 18 hrs 150 mah 130 mah 210 mah 320 mah 410 mah 420 mah 370 mah 300 mah 300 mah Battery Up to 72 hrs on Battery Reserve Mode Wireless Magnetic Charger Magnetic Charger Intergrated USB Wireless Qi Magnetic Charger Micro USB Magnetic Charger Magnetic Charger Charging Cradle Charging inside watch band Hear Rate Sensors Pulse Oximeter 3-Axis Accelerome- 3-Axis Accelerome- Hear Rate Monitor Hear Rate Monitor Heart Rate Monitor Ambient light Heart Rate monitor Heart -

Investigation Numérique & Terminaux Apple
Investigation numérique & terminaux Apple iOS Acquisition de données Mathieu RENARD ANSSI/LAM mathieu.renard[à]ssi.gouv.fr 1 Constat # Démocratisation de l’usage terminaux mobile en entreprise – Stockage d’informations professionnelles – Sécurité, management des terminaux mal ou non maitrisé # Men aces – Accès illégitimes au données professionnelles / réseau de l’entité – Usurpation d’identité – Atteinte à la disponibilité du terminal # Risques accentués par le caractère mobile des terminaux (perte, vol) # Les terminaux mobiles sont des cibles de choix pour les attaquants 2 Investigation numérique iOS Outils # Framework iPhoneDataProtection – Acquisition physique (iPhone 4 et inférieur) # iPhone Backup analyzer2 – Analyse des sauvegardes iOS # Celebrite UFED – Solution commerciale – Acquisition physique (iPhone 4 et inférieur) – Acquisition Logique (backup & AFC) 3 Investigation numérique & terminaux Apple iOS # La liste d’outils d’investigation numérique pour iOS est limitée # Aucun outil ne permet d’infirmer ou confirmer une compromission # Nécessité de développer des méthodes et outils 4 iPhone Architecture et sécurité http://iphoneroot.com/ipad-mini-gets-x-rayed-photo/#more-18711 5 Architecture matérielle Let’s open the box BCM43342 Wi-Fi SoC SK Hynix H2JTDG8UD3MBR 16 GB NAND Apple A7 APL0698 SoC Qualcomm MDM9615M LTE Modem (BaseBand) NXP LPC1800 Qualcomm WTR1605L M7 Motion coprocessor LTE/HSPA+/CDMA2K/TDSCDMA/EDGE/GPS (Cortex M3) (Tranceiver) http://www.chipworks.com/en/technical-competitive-analysis/resources/blog/inside-the-iphone-5s/ -

Hardware-Assisted Rootkits: Abusing Performance Counters on the ARM and X86 Architectures
Hardware-Assisted Rootkits: Abusing Performance Counters on the ARM and x86 Architectures Matt Spisak Endgame, Inc. [email protected] Abstract the OS. With KPP in place, attackers are often forced to move malicious code to less privileged user-mode, to ele- In this paper, a novel hardware-assisted rootkit is intro- vate privileges enabling a hypervisor or TrustZone based duced, which leverages the performance monitoring unit rootkit, or to become more creative in their approach to (PMU) of a CPU. By configuring hardware performance achieving a kernel mode rootkit. counters to count specific architectural events, this re- Early advances in rootkit design focused on low-level search effort proves it is possible to transparently trap hooks to system calls and interrupts within the kernel. system calls and other interrupts driven entirely by the With the introduction of hardware virtualization exten- PMU. This offers an attacker the opportunity to redirect sions, hypervisor based rootkits became a popular area control flow to malicious code without requiring modifi- of study allowing malicious code to run underneath a cations to a kernel image. guest operating system [4, 5]. Another class of OS ag- The approach is demonstrated as a kernel-mode nostic rootkits also emerged that run in System Manage- rootkit on both the ARM and Intel x86-64 architectures ment Mode (SMM) on x86 [6] or within ARM Trust- that is capable of intercepting system calls while evad- Zone [7]. The latter two categories, which leverage vir- ing current kernel patch protection implementations such tualization extensions, SMM on x86, and security exten- as PatchGuard. -

Apple, Inc. Collegiate Purchase Program Premier Price List March 11, 2011
Apple, Inc. Collegiate Purchase Program Premier Price List March 11, 2011 Revisions to the February 15, 2011 Collegiate Purchase Program Premier Price List Effective March 11, 2011 PRODUCTS ADDED TO THE PRICE LIST D5889LL/A APS APD Expert On Call (up to 4 hours) 680.00 MC939LL/A iPad Smart Cover - Polyurethane - Gray 39.00 MC940ZM/A iPad 2 Dock 29.00 MC941LL/A iPad Smart Cover - Polyurethane - Pink 39.00 MC942LL/A iPad Smart Cover - Polyurethane - Blue 39.00 MC944LL/A iPad Smart Cover - Polyurethane - Green 39.00 MC945LL/A iPad Smart Cover - Polyurethane - Orange 39.00 MC947LL/A iPad Smart Cover - Leather - Black 69.00 MC948LL/A iPad Smart Cover Leather - Tan 69.00 MC949LL/A iPad Smart Cover Leather - Navy 69.00 MC952LL/A iPad Smart Cover Leather - Cream 69.00 MC953ZM/A Digital AV Adapter (HDMI) 39.00 MC769LL/A iPad Wi-Fi 16GB Black 499.00 MC770LL/A iPad Wi-Fi 32GB Black 599.00 MC916LL/A iPad Wi-Fi 64GB Black 699.00 MC979LL/A iPad Wi-Fi 16GB White 499.00 MC980LL/A iPad Wi-Fi 32GB White 599.00 MC981LL/A iPad Wi-Fi 64GB White 699.00 MC773LL/A iPad Wi-Fi + 3G 16GB Black 629.00 MC774LL/A iPad Wi-Fi + 3G 32GB Black 729.00 MC775LL/A iPad Wi-Fi + 3G 64GB Black 829.00 MC982LL/A iPad Wi-Fi + 3G 16GB White 629.00 MC983LL/A iPad Wi-Fi + 3G 32GB White 729.00 MC984LL/A iPad Wi-Fi + 3G 64GB White 829.00 PRODUCTS REPRICED ON THE PRICE LIST PRODUCTS REMOVED FROM THE PRICE LIST MA407LL/A Mac mini 110W power adapter MB595LL/A AppleCare Premium Service and Support Plan - Enrollment Kit for Xserve This Price List supersedes all previous Price Lists.