Volatility Modeling with a Generalized T-Distribution
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

5.1 Convergence in Distribution
556: MATHEMATICAL STATISTICS I CHAPTER 5: STOCHASTIC CONVERGENCE The following definitions are stated in terms of scalar random variables, but extend naturally to vector random variables defined on the same probability space with measure P . Forp example, some results 2 are stated in terms of the Euclidean distance in one dimension jXn − Xj = (Xn − X) , or for se- > quences of k-dimensional random variables Xn = (Xn1;:::;Xnk) , 0 1 1=2 Xk @ 2A kXn − Xk = (Xnj − Xj) : j=1 5.1 Convergence in Distribution Consider a sequence of random variables X1;X2;::: and a corresponding sequence of cdfs, FX1 ;FX2 ;::: ≤ so that for n = 1; 2; :: FXn (x) =P[Xn x] : Suppose that there exists a cdf, FX , such that for all x at which FX is continuous, lim FX (x) = FX (x): n−!1 n Then X1;:::;Xn converges in distribution to random variable X with cdf FX , denoted d Xn −! X and FX is the limiting distribution. Convergence of a sequence of mgfs or cfs also indicates conver- gence in distribution, that is, if for all t at which MX (t) is defined, if as n −! 1, we have −! () −!d MXi (t) MX (t) Xn X: Definition : DEGENERATE DISTRIBUTIONS The sequence of random variables X1;:::;Xn converges in distribution to constant c if the limiting d distribution of X1;:::;Xn is degenerate at c, that is, Xn −! X and P [X = c] = 1, so that { 0 x < c F (x) = X 1 x ≥ c Interpretation: A special case of convergence in distribution occurs when the limiting distribution is discrete, with the probability mass function only being non-zero at a single value, that is, if the limiting random variable is X, then P [X = c] = 1 and zero otherwise. -

Parameter Specification of the Beta Distribution and Its Dirichlet
%HWD'LVWULEXWLRQVDQG,WV$SSOLFDWLRQV 3DUDPHWHU6SHFLILFDWLRQRIWKH%HWD 'LVWULEXWLRQDQGLWV'LULFKOHW([WHQVLRQV 8WLOL]LQJ4XDQWLOHV -5HQpYDQ'RUSDQG7KRPDV$0D]]XFKL (Submitted January 2003, Revised March 2003) I. INTRODUCTION.................................................................................................... 1 II. SPECIFICATION OF PRIOR BETA PARAMETERS..............................................5 A. Basic Properties of the Beta Distribution...............................................................6 B. Solving for the Beta Prior Parameters...................................................................8 C. Design of a Numerical Procedure........................................................................12 III. SPECIFICATION OF PRIOR DIRICHLET PARAMETERS................................. 17 A. Basic Properties of the Dirichlet Distribution...................................................... 18 B. Solving for the Dirichlet prior parameters...........................................................20 IV. SPECIFICATION OF ORDERED DIRICHLET PARAMETERS...........................22 A. Properties of the Ordered Dirichlet Distribution................................................. 23 B. Solving for the Ordered Dirichlet Prior Parameters............................................ 25 C. Transforming the Ordered Dirichlet Distribution and Numerical Stability ......... 27 V. CONCLUSIONS........................................................................................................ 31 APPENDIX................................................................................................................... -

Package 'Distributional'
Package ‘distributional’ February 2, 2021 Title Vectorised Probability Distributions Version 0.2.2 Description Vectorised distribution objects with tools for manipulating, visualising, and using probability distributions. Designed to allow model prediction outputs to return distributions rather than their parameters, allowing users to directly interact with predictive distributions in a data-oriented workflow. In addition to providing generic replacements for p/d/q/r functions, other useful statistics can be computed including means, variances, intervals, and highest density regions. License GPL-3 Imports vctrs (>= 0.3.0), rlang (>= 0.4.5), generics, ellipsis, stats, numDeriv, ggplot2, scales, farver, digest, utils, lifecycle Suggests testthat (>= 2.1.0), covr, mvtnorm, actuar, ggdist RdMacros lifecycle URL https://pkg.mitchelloharawild.com/distributional/, https: //github.com/mitchelloharawild/distributional BugReports https://github.com/mitchelloharawild/distributional/issues Encoding UTF-8 Language en-GB LazyData true Roxygen list(markdown = TRUE, roclets=c('rd', 'collate', 'namespace')) RoxygenNote 7.1.1 1 2 R topics documented: R topics documented: autoplot.distribution . .3 cdf..............................................4 density.distribution . .4 dist_bernoulli . .5 dist_beta . .6 dist_binomial . .7 dist_burr . .8 dist_cauchy . .9 dist_chisq . 10 dist_degenerate . 11 dist_exponential . 12 dist_f . 13 dist_gamma . 14 dist_geometric . 16 dist_gumbel . 17 dist_hypergeometric . 18 dist_inflated . 20 dist_inverse_exponential . 20 dist_inverse_gamma -

Iam 530 Elements of Probability and Statistics
IAM 530 ELEMENTS OF PROBABILITY AND STATISTICS LECTURE 4-SOME DISCERETE AND CONTINUOUS DISTRIBUTION FUNCTIONS SOME DISCRETE PROBABILITY DISTRIBUTIONS Degenerate, Uniform, Bernoulli, Binomial, Poisson, Negative Binomial, Geometric, Hypergeometric DEGENERATE DISTRIBUTION • An rv X is degenerate at point k if 1, Xk P X x 0, ow. The cdf: 0, Xk F x P X x 1, Xk UNIFORM DISTRIBUTION • A finite number of equally spaced values are equally likely to be observed. 1 P(X x) ; x 1,2,..., N; N 1,2,... N • Example: throw a fair die. P(X=1)=…=P(X=6)=1/6 N 1 (N 1)(N 1) E(X) ; Var(X) 2 12 BERNOULLI DISTRIBUTION • An experiment consists of one trial. It can result in one of 2 outcomes: Success or Failure (or a characteristic being Present or Absent). • Probability of Success is p (0<p<1) 1 with probability p Xp;0 1 0 with probability 1 p P(X x) px (1 p)1 x for x 0,1; and 0 p 1 1 E(X ) xp(y) 0(1 p) 1p p y 0 E X 2 02 (1 p) 12 p p V (X ) E X 2 E(X ) 2 p p2 p(1 p) p(1 p) Binomial Experiment • Experiment consists of a series of n identical trials • Each trial can end in one of 2 outcomes: Success or Failure • Trials are independent (outcome of one has no bearing on outcomes of others) • Probability of Success, p, is constant for all trials • Random Variable X, is the number of Successes in the n trials is said to follow Binomial Distribution with parameters n and p • X can take on the values x=0,1,…,n • Notation: X~Bin(n,p) Consider outcomes of an experiment with 3 Trials : SSS y 3 P(SSS) P(Y 3) p(3) p3 SSF, SFS, FSS y 2 P(SSF SFS FSS) P(Y 2) p(2) 3p2 (1 p) SFF, FSF, FFS y 1 P(SFF FSF FFS ) P(Y 1) p(1) 3p(1 p)2 FFF y 0 P(FFF ) P(Y 0) p(0) (1 p)3 In General: n n! 1) # of ways of arranging x S s (and (n x) F s ) in a sequence of n positions x x!(n x)! 2) Probability of each arrangement of x S s (and (n x) F s ) p x (1 p)n x n 3)P(X x) p(x) p x (1 p)n x x 0,1,..., n x • Example: • There are black and white balls in a box. -

The Length-Biased Versus Random Sampling for the Binomial and Poisson Events Makarand V
Journal of Modern Applied Statistical Methods Volume 12 | Issue 1 Article 10 5-1-2013 The Length-Biased Versus Random Sampling for the Binomial and Poisson Events Makarand V. Ratnaparkhi Wright State University, [email protected] Uttara V. Naik-Nimbalkar Pune University, Pune, India Follow this and additional works at: http://digitalcommons.wayne.edu/jmasm Part of the Applied Statistics Commons, Social and Behavioral Sciences Commons, and the Statistical Theory Commons Recommended Citation Ratnaparkhi, Makarand V. and Naik-Nimbalkar, Uttara V. (2013) "The Length-Biased Versus Random Sampling for the Binomial and Poisson Events," Journal of Modern Applied Statistical Methods: Vol. 12 : Iss. 1 , Article 10. DOI: 10.22237/jmasm/1367381340 Available at: http://digitalcommons.wayne.edu/jmasm/vol12/iss1/10 This Regular Article is brought to you for free and open access by the Open Access Journals at DigitalCommons@WayneState. It has been accepted for inclusion in Journal of Modern Applied Statistical Methods by an authorized editor of DigitalCommons@WayneState. Journal of Modern Applied Statistical Methods Copyright © 2013 JMASM, Inc. May 2013, Vol. 12, No. 1, 54-57 1538 – 9472/13/$95.00 The Length-Biased Versus Random Sampling for the Binomial and Poisson Events Makarand V. Ratnaparkhi Uttara V. Naik-Nimbalkar Wright State University, Pune University, Dayton, OH Pune, India The equivalence between the length-biased and the random sampling on a non-negative, discrete random variable is established. The length-biased versions of the binomial and Poisson distributions are discussed. Key words: Length-biased data, weighted distributions, binomial, Poisson, convolutions. Introduction binomial distribution (probabilities), which was The occurrence of so-called length-biased data appropriate at that time. -

The Multivariate Normal Distribution=1See Last Slide For
Moment-generating Functions Definition Properties χ2 and t distributions The Multivariate Normal Distribution1 STA 302 Fall 2017 1See last slide for copyright information. 1 / 40 Moment-generating Functions Definition Properties χ2 and t distributions Overview 1 Moment-generating Functions 2 Definition 3 Properties 4 χ2 and t distributions 2 / 40 Moment-generating Functions Definition Properties χ2 and t distributions Joint moment-generating function Of a p-dimensional random vector x t0x Mx(t) = E e x t +x t +x t For example, M (t1; t2; t3) = E e 1 1 2 2 3 3 (x1;x2;x3) Just write M(t) if there is no ambiguity. Section 4.3 of Linear models in statistics has some material on moment-generating functions (optional). 3 / 40 Moment-generating Functions Definition Properties χ2 and t distributions Uniqueness Proof omitted Joint moment-generating functions correspond uniquely to joint probability distributions. M(t) is a function of F (x). Step One: f(x) = @ ··· @ F (x). @x1 @xp @ @ R x2 R x1 For example, f(y1; y2) dy1dy2 @x1 @x2 −∞ −∞ 0 Step Two: M(t) = R ··· R et xf(x) dx Could write M(t) = g (F (x)). Uniqueness says the function g is one-to-one, so that F (x) = g−1 (M(t)). 4 / 40 Moment-generating Functions Definition Properties χ2 and t distributions g−1 (M(t)) = F (x) A two-variable example g−1 (M(t)) = F (x) −1 R 1 R 1 x1t1+x2t2 R x2 R x1 g −∞ −∞ e f(x1; x2) dx1dx2 = −∞ −∞ f(y1; y2) dy1dy2 5 / 40 Moment-generating Functions Definition Properties χ2 and t distributions Theorem Two random vectors x1 and x2 are independent if and only if the moment-generating function of their joint distribution is the product of their moment-generating functions. -

Field Guide to Continuous Probability Distributions
Field Guide to Continuous Probability Distributions Gavin E. Crooks v 1.0.0 2019 G. E. Crooks – Field Guide to Probability Distributions v 1.0.0 Copyright © 2010-2019 Gavin E. Crooks ISBN: 978-1-7339381-0-5 http://threeplusone.com/fieldguide Berkeley Institute for Theoretical Sciences (BITS) typeset on 2019-04-10 with XeTeX version 0.99999 fonts: Trump Mediaeval (text), Euler (math) 271828182845904 2 G. E. Crooks – Field Guide to Probability Distributions Preface: The search for GUD A common problem is that of describing the probability distribution of a single, continuous variable. A few distributions, such as the normal and exponential, were discovered in the 1800’s or earlier. But about a century ago the great statistician, Karl Pearson, realized that the known probabil- ity distributions were not sufficient to handle all of the phenomena then under investigation, and set out to create new distributions with useful properties. During the 20th century this process continued with abandon and a vast menagerie of distinct mathematical forms were discovered and invented, investigated, analyzed, rediscovered and renamed, all for the purpose of de- scribing the probability of some interesting variable. There are hundreds of named distributions and synonyms in current usage. The apparent diver- sity is unending and disorienting. Fortunately, the situation is less confused than it might at first appear. Most common, continuous, univariate, unimodal distributions can be orga- nized into a small number of distinct families, which are all special cases of a single Grand Unified Distribution. This compendium details these hun- dred or so simple distributions, their properties and their interrelations. -

University of Tartu DISTRIBUTIONS in FINANCIAL MATHEMATICS (MTMS.02.023)
University of Tartu Faculty of Mathematics and Computer Science Institute of Mathematical Statistics DISTRIBUTIONS IN FINANCIAL MATHEMATICS (MTMS.02.023) Lecture notes Ants Kaasik, Meelis K¨a¨arik MTMS.02.023. Distributions in Financial Mathematics Contents 1 Introduction1 1.1 The data. Prediction problem..................1 1.2 The models............................2 1.3 Summary of the introduction..................2 2 Exploration and visualization of the data2 2.1 Motivating example.......................2 3 Heavy-tailed probability distributions7 4 Detecting the heaviness of the tail 10 4.1 Visual tests............................ 10 4.2 Maximum-sum ratio test..................... 13 4.3 Records test............................ 14 4.4 Alternative definition of heavy tails............... 15 5 Creating new probability distributions. Mixture distribu- tions 17 5.1 Combining distributions. Discrete mixtures.......... 17 5.2 Continuous mixtures....................... 19 5.3 Completely new parts...................... 20 5.4 Parameters of a distribution................... 21 6 Empirical distribution. Kernel density estimation 22 7 Subexponential distributions 27 7.1 Preliminaries. Definition..................... 27 7.2 Properties of subexponential class............... 28 8 Well-known distributions in financial and insurance mathe- matics 30 8.1 Exponential distribution..................... 30 8.2 Pareto distribution........................ 31 8.3 Weibull Distribution....................... 33 i MTMS.02.023. Distributions in Financial Mathematics -

Claims Frequency Distribution Models
Claims Frequency Distribution Models Chapter 6 Stat 477 - Loss Models Chapter 6 (Stat 477) Claims Frequency Models Brian Hartman - BYU 1 / 19 Introduction Introduction Here we introduce a large class of counting distributions, which are discrete distributions with support consisting of non-negative integers. Generally used for modeling number of events, but in an insurance context, the number of claims within a certain period, e.g. one year. We call these claims frequency models. Let N denote the number of events (or claims). Its probability mass function (pmf), pk = Pr(N = k), for k = 0; 1; 2;:::, gives the probability that exactly k events (or claims) occur. Chapter 6 (Stat 477) Claims Frequency Models Brian Hartman - BYU 2 / 19 Introduction probability generating function The probability generating function N P1 k Recall the pgf of N: PN (z) = E(z ) = k=0 pkz . Just like the mgf, pgf also generates moments: 0 00 PN (1) = E(N) and PN (1) = E[N(N − 1)]: More importantly, it generates probabilities: dm P (m)(z) = E zN = E[N(N − 1) ··· (N − m + 1)zN−m] N dzm 1 X k−m = k(k − 1) ··· (k − m + 1)z pk k=m Thus, we see that 1 P (m)(0) = m! p or p = P (m)(0): N m m m! Chapter 6 (Stat 477) Claims Frequency Models Brian Hartman - BYU 3 / 19 Some discrete distributions Some familiar discrete distributions Some of the most commonly used distributions for number of claims: Binomial (with Bernoulli as special case) Poisson Geometric Negative Binomial The (a; b; 0) class The (a; b; 1) class Chapter 6 (Stat 477) Claims Frequency Models Brian Hartman - BYU 4 / 19 Bernoulli random variables Bernoulli random variables N is Bernoulli if it takes only one of two possible outcomes: 1; if a claim occurs N = : 0; otherwise q is the standard symbol for the probability of a claim, i.e. -

Chapter 2 Random Variables and Distributions
Chapter 2 Random Variables and Distributions CHAPTER OUTLINE Section 1 Random Variables Section 2 Distributions of Random Variables Section 3 Discrete Distributions Section 4 Continuous Distributions Section 5 Cumulative Distribution Functions Section 6 One-Dimensional Change of Variable Section 7 Joint Distributions Section 8 Conditioning and Independence Section 9 Multidimensional Change of Variable Section 10 Simulating Probability Distributions Section 11 Further Proofs (Advanced) In Chapter 1, we discussed the probability model as the central object of study in the theory of probability. This required defining a probability measure P on a class of subsets of the sample space S. It turns out that there are simpler ways of presenting a particular probability assignment than this — ways that are much more convenient to work with than P. This chapter is concerned with the definitions of random variables, distribution functions, probability functions, density functions, and the development of the concepts necessary for carrying out calculations for a probability model using these entities. This chapter also discusses the concept of the conditional distribution of one random variable, given the values of others. Conditional distributions of random variables provide the framework for discussing what it means to say that variables are related, which is important in many applications of probability and statistics. 33 34 Section 2.1: Random Variables 2.1 Random Variables The previous chapter explained how to construct probability models, including a sam- ple space S and a probability measure P. Once we have a probability model, we may define random variables for that probability model. Intuitively, a random variable assigns a numerical value to each possible outcome in the sample space. -

Distributions You Can Count on . . . but What's the Point? †
econometrics Article Distributions You Can Count On . But What’s the Point? † Brendan P. M. McCabe 1 and Christopher L. Skeels 2,* 1 School of Management, University of Liverpoo, Liverpool L69 7ZH, UK; [email protected] 2 Department of Economics, The University of Melbourne, Carlton VIC 3053, Australia * Correspondence: [email protected] † An early version of this paper was originally prepared for the Fest in Celebration of the 65th Birthday of Professor Maxwell King, hosted by Monash University. It was started while Skeels was visiting the Department of Economics at the University of Bristol. He would like to thank them for their hospitality and, in particular, Ken Binmore for a very helpful discussion. We would also like to thank David Dickson and David Harris for useful comments along the way. Received: 2 September 2019; Accepted: 25 February 2020; Published: 4 March 2020 Abstract: The Poisson regression model remains an important tool in the econometric analysis of count data. In a pioneering contribution to the econometric analysis of such models, Lung-Fei Lee presented a specification test for a Poisson model against a broad class of discrete distributions sometimes called the Katz family. Two members of this alternative class are the binomial and negative binomial distributions, which are commonly used with count data to allow for under- and over-dispersion, respectively. In this paper we explore the structure of other distributions within the class and their suitability as alternatives to the Poisson model. Potential difficulties with the Katz likelihood leads us to investigate a class of point optimal tests of the Poisson assumption against the alternative of over-dispersion in both the regression and intercept only cases. -
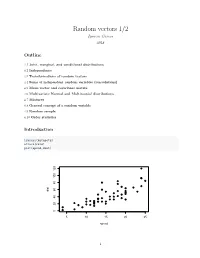
Random Vectors 1/2 Ignacio Cascos 2018
Random vectors 1/2 Ignacio Cascos 2018 Outline 4.1 Joint, marginal, and conditional distributions 4.2 Independence 4.3 Transformations of random vectors 4.4 Sums of independent random variables (convolutions) 4.5 Mean vector and covariance matrix 4.6 Multivariate Normal and Multinomial distributions 4.7 Mixtures 4.8 General concept of a random variable 4.9 Random sample 4.10 Order statistics Introduction library(datasets) attach(cars) plot(speed,dist) 120 100 80 60 dist 40 20 0 5 10 15 20 25 speed 1 4.1 Joint, marginal, and conditional distributions In many situations we are interested in more than one feature (variable) associated with the same random experiment. A random vector is a measurable mapping from a sample space S into Rd. A bivariate random vector maps S into R2, 2 (X, Y ): S −→ R . The joint distribution of a random vector describes the simultaneous behavior of all variables that build the random vector. Discrete random vectors Given X and Y two discrete random variables (on the same probability space), we define • joint probability mass function: pX,Y (x, y) = P (X = x, Y = y) satisfying – pX,Y (x, y) ≥ 0; P P – x y pX,Y (x, y) = 1. joint cumulative distribution function F x , y P X ≤ x ,Y ≤ y P P p x, y • : X,Y ( 0 0) = ( 0 0) = x≤x0 y≤y0 X,Y ( ). For any (borelian) A ⊂ R2, we use the joint probability mass function to compute the probability that (X, Y ) lies in A, X P ((X, Y ) ∈ A) = pX,Y (xi, yj) .