Fast Computation of Divided Differences and Parallel Hermite Interpolation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fast and Efficient Algorithms for Evaluating Uniform and Nonuniform
World Academy of Science, Engineering and Technology International Journal of Computer and Information Engineering Vol:13, No:8, 2019 Fast and Efficient Algorithms for Evaluating Uniform and Nonuniform Lagrange and Newton Curves Taweechai Nuntawisuttiwong, Natasha Dejdumrong Abstract—Newton-Lagrange Interpolations are widely used in quadratic computation time, which is slower than the others. numerical analysis. However, it requires a quadratic computational However, there are some curves in CAGD, Wang-Ball, DP time for their constructions. In computer aided geometric design and Dejdumrong curves with linear complexity. In order to (CAGD), there are some polynomial curves: Wang-Ball, DP and Dejdumrong curves, which have linear time complexity algorithms. reduce their computational time, Bezier´ curve is converted Thus, the computational time for Newton-Lagrange Interpolations into any of Wang-Ball, DP and Dejdumrong curves. Hence, can be reduced by applying the algorithms of Wang-Ball, DP and the computational time for Newton-Lagrange interpolations Dejdumrong curves. In order to use Wang-Ball, DP and Dejdumrong can be reduced by converting them into Wang-Ball, DP and algorithms, first, it is necessary to convert Newton-Lagrange Dejdumrong algorithms. Thus, it is necessary to investigate polynomials into Wang-Ball, DP or Dejdumrong polynomials. In this work, the algorithms for converting from both uniform and the conversion from Newton-Lagrange interpolation into non-uniform Newton-Lagrange polynomials into Wang-Ball, DP and the curves with linear complexity, Wang-Ball, DP and Dejdumrong polynomials are investigated. Thus, the computational Dejdumrong curves. An application of this work is to modify time for representing Newton-Lagrange polynomials can be reduced sketched image in CAD application with the computational into linear complexity. -

Mials P
Euclid's Algorithm 171 Euclid's Algorithm Horner’s method is a special case of Euclid's Algorithm which constructs, for given polyno- mials p and h =6 0, (unique) polynomials q and r with deg r<deg h so that p = hq + r: For variety, here is a nonstandard discussion of this algorithm, in terms of elimination. Assume that d h(t)=a0 + a1t + ···+ adt ;ad =06 ; and n p(t)=b0 + b1t + ···+ bnt : Then we seek a polynomial n−d q(t)=c0 + c1t + ···+ cn−dt for which r := p − hq has degree <d. This amounts to the square upper triangular linear system adc0 + ad−1c1 + ···+ a0cd = bd adc1 + ad−1c2 + ···+ a0cd+1 = bd+1 . adcn−d−1 + ad−1cn−d = bn−1 adcn−d = bn for the unknown coefficients c0;:::;cn−d which can be uniquely solved by back substitution since its diagonal entries all equal ad =0.6 19aug02 c 2002 Carl de Boor 172 18. Index Rough index for these notes 1-1:-5,2,8,40 cartesian product: 2 1-norm: 79 Cauchy(-Bunyakovski-Schwarz) 2-norm: 79 Inequality: 69 A-invariance: 125 Cauchy-Binet formula: -9, 166 A-invariant: 113 Cayley-Hamilton Theorem: 133 absolute value: 167 CBS Inequality: 69 absolutely homogeneous: 70, 79 Chaikin algorithm: 139 additive: 20 chain rule: 153 adjugate: 164 change of basis: -6 affine: 151 characteristic function: 7 affine combination: 148, 150 characteristic polynomial: -8, 130, 132, 134 affine hull: 150 circulant: 140 affine map: 149 codimension: 50, 53 affine polynomial: 152 coefficient vector: 21 affine space: 149 cofactor: 163 affinely independent: 151 column map: -6, 23 agrees with y at Λt:59 column space: 29 algebraic dual: 95 column -

CS321-001 Introduction to Numerical Methods
CS321-001 Introduction to Numerical Methods Lecture 3 Interpolation and Numerical Differentiation Professor Jun Zhang Department of Computer Science University of Kentucky Lexington, KY 40506-0633 Polynomial Interpolation Given a set of discrete values, how can we estimate other values between these data The method that we will use is called polynomial interpolation. We assume the data we had are from the evaluation of a smooth function. We may be able to use a polynomial p(x) to approximate this function, at least locally. A condition: the polynomial p(x) takes the given values at the given points (nodes), i.e., p(xi) = yi with 0 ≤ i ≤ n. The polynomial is said to interpolate the table, since we do not know the function. 2 Polynomial Interpolation Note that all the points are passed through by the curve 3 Polynomial Interpolation We do not know the original function, the interpolation may not be accurate 4 Order of Interpolating Polynomial A polynomial of degree 0, a constant function, interpolates one set of data If we have two sets of data, we can have an interpolating polynomial of degree 1, a linear function x x1 x x0 p(x) y0 y1 x0 x1 x1 x0 y1 y0 y0 (x x0 ) x1 x0 Review carefully if the interpolation condition is satisfied Interpolating polynomials can be written in several forms, the most well known ones are the Lagrange form and Newton form. Each has some advantages 5 Lagrange Form For a set of fixed nodes x0, x1, …, xn, the cardinal functions, l0, l1,…, ln, are defined as 0 if i j li (x j ) ij -

Lagrange & Newton Interpolation
Lagrange & Newton interpolation In this section, we shall study the polynomial interpolation in the form of Lagrange and Newton. Given a se- quence of (n +1) data points and a function f, the aim is to determine an n-th degree polynomial which interpol- ates f at these points. We shall resort to the notion of divided differences. Interpolation Given (n+1) points {(x0, y0), (x1, y1), …, (xn, yn)}, the points defined by (xi)0≤i≤n are called points of interpolation. The points defined by (yi)0≤i≤n are the values of interpolation. To interpolate a function f, the values of interpolation are defined as follows: yi = f(xi), i = 0, …, n. Lagrange interpolation polynomial The purpose here is to determine the unique polynomial of degree n, Pn which verifies Pn(xi) = f(xi), i = 0, …, n. The polynomial which meets this equality is Lagrange interpolation polynomial n Pnx=∑ l j x f x j j=0 where the lj ’s are polynomials of degree n forming a basis of Pn n x−xi x−x0 x−x j−1 x−x j 1 x−xn l j x= ∏ = ⋯ ⋯ i=0,i≠ j x j −xi x j−x0 x j−x j−1 x j−x j1 x j−xn Properties of Lagrange interpolation polynomial and Lagrange basis They are the lj polynomials which verify the following property: l x = = 1 i= j , ∀ i=0,...,n. j i ji {0 i≠ j They form a basis of the vector space Pn of polynomials of degree at most equal to n n ∑ j l j x=0 j=0 By setting: x = xi, we obtain: n n ∑ j l j xi =∑ j ji=0 ⇒ i =0 j=0 j=0 The set (lj)0≤j≤n is linearly independent and consists of n + 1 vectors. -

Mathematical Topics
A Mathematical Topics This chapter discusses most of the mathematical background needed for a thor ough understanding of the material presented in the book. It has been mentioned in the Preface, however, that math concepts which are only used once (such as the mediation operator and points vs. vectors) are discussed right where they are introduced. Do not worry too much about your difficulties in mathematics, I can assure you that mine a.re still greater. - Albert Einstein. A.I Fourier Transforms Our curves are functions of an arbitrary parameter t. For functions used in science and engineering, time is often the parameter (or the independent variable). We, therefore, say that a function g( t) is represented in the time domain. Since a typical function oscillates, we can think of it as being similar to a wave and we may try to represent it as a wave (or as a combination of waves). When this is done, we have the function G(f), where f stands for the frequency of the wave, and we say that the function is represented in the frequency domain. This turns out to be a useful concept, since many operations on functions are easy to carry out in the frequency domain. Transforming a function between the time and frequency domains is easy when the function is periodic, but it can also be done for certain non periodic functions. The present discussion is restricted to periodic functions. 1IIIt Definition: A function g( t) is periodic if (and only if) there exists a constant P such that g(t+P) = g(t) for all values of t (Figure A.la). -

Coalgebraic Foundations of the Method of Divided Differences
ADVANCES IN MATHEMATICS 91, 75~135 (1992) Coalgebraic Foundations of the Method of Divided Differences PHILIP S. HIRSCHHORN AND LOUISE ARAKELIAN RAPHAEL* Department qf Muthenmtics, Howard Unhrersity, Washington. D.C. 20059 1. INTRODUCTION 1.1. Zntroductiorz The analogy between properties of the function e’ and the properties of the function l/( 1 -x) has led, in the past two centuries, to much new mathematics. At the most elementary level, it was noticed long ago that the function l/( 1 - x) is (roughly) the Laplace transform of the function e-‘;, and the theory of Laplace transforms, in its heyday, was concerned with drafting a correspondence table between properties of functions and properties of their Laplace transforms. In the development of functional analysis in the forties and fifties, properties of semigroups of linear operators on Banach spaces were thrown back onto properties of their resolvents; the functional equation satisfied by the resolvent of an operator was clearly perceived at that time as an analog-though still a mysterious one-of the Cauchy functional equation satisfied by the exponential function. A far more ancient, though, it must be admitted, still little known instance of this analogy is the Newton expansion of the calculus of divided difference (see, e.g., [lo] ). Although Taylor’s formula can be formally seen as a special case of a Newton expansion (obtained by taking equal arguments), nonetheless, the algebraic properties of the two expansions were radically different. Suitably reinterpreted, Taylor’s formula led in this * Partially supported by National Science Foundation Grant ECS8918050. 75 OOOl-8708/92 $7.50 Copyright ( 1992 by Academic Press. -

Interpolation
Interpolation 1 What is interpolation? For a certain function f (x) we know only the values y1 = f (x1),. ,yn = f (xn). For a pointx ˜ different from x1;:::;xn we would then like to approximate f (x˜) using the given data x1;:::;xn and y1;:::;yn. This means we are constructing a function p(x) which passes through the given points and hopefully is close to the function f (x). It turns out that it is a good idea to use polynomials as interpolating functions (later we will also consider piecewise polynomial functions). 2 Why are we interested in this? • Efficient evaluation of functions: For functions like f (x) = sin(x) it is possible to find values using a series expansion (e.g. Taylor series), but this takes a lot of operations. If we need to compute f (x) for many values x in an interval [a;b] we can do the following: – pick points x1;:::;xn in the interval – find the interpolating polynomial p(x) – Then: for any given x 2 [a;b] just evaluate the polynomial p(x) (which is cheap) to obtain an approximation for f (x) Before the age of computers and calculators, values of functions like sin(x) were listed in tables for values x j with a certain spacing. Then function values everywhere in between could be obtained by interpolation. A computer or calculator uses the same method to find values of e.g. sin(x): First an interpolating polynomial p(x) for the interval [0;p=2] was constructed and the coefficients are stored in the computer. -

A Low‐Cost Solution to Motion Tracking Using an Array of Sonar Sensors and An
A Low‐cost Solution to Motion Tracking Using an Array of Sonar Sensors and an Inertial Measurement Unit A thesis presented to the faculty of the Russ College of Engineering and Technology of Ohio University In partial fulfillment of the requirements for the degree Master of Science Jason S. Maxwell August 2009 © 2009 Jason S. Maxwell. All Rights Reserved. 2 This thesis titled A Low‐cost Solution to Motion Tracking Using an Array of Sonar Sensors and an Inertial Measurement Unit by JASON S. MAXWELL has been approved for the School of Electrical Engineering Computer Science and the Russ College of Engineering and Technology by Maarten Uijt de Haag Associate Professor School of Electrical Engineering and Computer Science Dennis Irwin Dean, Russ College of Engineering and Technology 3 ABSTRACT MAXWELL, JASON S., M.S., August 2009, Electrical Engineering A Low‐cost Solution to Motion Tracking Using an Array of Sonar Sensors and an Inertial Measurement Unit (91 pp.) Director of Thesis: Maarten Uijt de Haag As the desire and need for unmanned aerial vehicles (UAV) increases, so to do the navigation and system demands for the vehicles. While there are a multitude of systems currently offering solutions, each also possess inherent problems. The Global Positioning System (GPS), for instance, is potentially unable to meet the demands of vehicles that operate indoors, in heavy foliage, or in urban canyons, due to the lack of signal strength. Laser‐based systems have proven to be rather costly, and can potentially fail in areas in which the surface absorbs light, and in urban environments with glass or mirrored surfaces. -

The AMATYC Review, Fall 1992-Spring 1993. INSTITUTION American Mathematical Association of Two-Year Colleges
DOCUMENT RESUME ED 354 956 JC 930 126 AUTHOR Cohen, Don, Ed.; Browne, Joseph, Ed. TITLE The AMATYC Review, Fall 1992-Spring 1993. INSTITUTION American Mathematical Association of Two-Year Colleges. REPORT NO ISSN-0740-8404 PUB DATE 93 NOTE 203p. AVAILABLE FROMAMATYC Treasurer, State Technical Institute at Memphis, 5983 Macon Cove, Memphis, TN 38134 (for libraries 2 issues free with $25 annual membership). PUB TYPE Collected Works Serials (022) JOURNAL CIT AMATYC Review; v14 n1-2 Fall 1992-Spr 1993 EDRS PRICE MF01/PC09 Plus Postage. DESCRIPTORS *College Mathematics; Community Colleges; Computer Simulation; Functions (Mathematics); Linear Programing; *Mathematical Applications; *Mathematical Concepts; Mathematical Formulas; *Mathematics Instruction; Mathematics Teachers; Technical Mathematics; Two Year Colleges ABSTRACT Designed as an avenue of communication for mathematics educators concerned with the views, ideas, and experiences of two-year collage students and teachers, this journal contains articles on mathematics expoition and education,as well as regular features presenting book and software reviews and math problems. The first of two issues of volume 14 contains the following major articles: "Technology in the Mathematics Classroom," by Mike Davidson; "Reflections on Arithmetic-Progression Factorials," by William E. Rosentl,e1; "The Investigation of Tangent Polynomials with a Computer Algebra System," by John H. Mathews and Russell W. Howell; "On Finding the General Term of a Sequence Using Lagrange Interpolation," by Sheldon Gordon and Robert Decker; "The Floating Leaf Problem," by Richard L. Francis; "Approximations to the Hypergeometric Distribution," by Chltra Gunawardena and K. L. D. Gunawardena; aid "Generating 'JE(3)' with Some Elementary Applications," by John J. Edgeli, Jr. The second issue contains: "Strategies for Making Mathematics Work for Minorities," by Beverly J. -
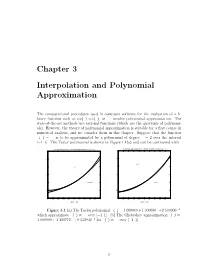
Chapter 3 Interpolation and Polynomial Approximation
Chapter 3 Interpolation and Polynomial Approximation The computational procedures used in computer software for the evaluation of a li- brary function such as sin(x); cos(x), or ex, involve polynomial approximation. The state-of-the-art methods use rational functions (which are the quotients of polynomi- als). However, the theory of polynomial approximation is suitable for a first course in numerical analysis, and we consider them in this chapter. Suppose that the function f(x) = ex is to be approximated by a polynomial of degree n = 2 over the interval [¡1; 1]. The Taylor polynomial is shown in Figure 1.1(a) and can be contrasted with 2 x The Taylor polynomial p(x)=1+x+0.5x2 which approximates f(x)=ex over [−1,1] The Chebyshev approximation q(x)=1+1.129772x+0.532042x for f(x)=e over [−1,1] 3 3 2.5 2.5 y=ex 2 2 y=ex 1.5 1.5 2 1 y=1+x+0.5x 1 y=q(x) 0.5 0.5 0 0 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 Figure 1.1(a) Figure 1.1(b) Figure 3.1 (a) The Taylor polynomial p(x) = 1:000000+ 1:000000x +0:500000x2 which approximate f(x) = ex over [¡1; 1]. (b) The Chebyshev approximation q(x) = 1:000000 + 1:129772x + 0:532042x2 for f(x) = ex over [¡1; 1]. -

Anl-7826 Chinese Remainder Ind Interpolation
ANL-7826 CHINESE REMAINDER IND INTERPOLATION ALGORITHMS John D. Lipson UolC-AUA-USAEC- ARGONNE NATIONAL LABORATORY, ARGONNE, ILLINOIS Prepared for the U.S. ATOMIC ENERGY COMMISSION under contract W-31-109-Eng-38 The facilities of Argonne National Laboratory are owned by the United States Govern ment. Under the terms of a contract (W-31 -109-Eng-38) between the U. S. Atomic Energy 1 Commission. Argonne Universities Association and The University of Chicago, the University employs the staff and operates the Laboratory in accordance with policies and programs formu lated, approved and reviewed by the Association. MEMBERS OF ARGONNE UNIVERSITIES ASSOCIATION The University of Arizona Kansas State University The Ohio State University Carnegie-Mellon University The University of Kansas Ohio University Case Western Reserve University Loyola University The Pennsylvania State University The University of Chicago Marquette University Purdue University University of Cincinnati Michigan State University Saint Louis University Illinois Institute of Technology The University of Michigan Southern Illinois University University of Illinois University of Minnesota The University of Texas at Austin Indiana University University of Missouri Washington University Iowa State University Northwestern University Wayne State University The University of Iowa University of Notre Dame The University of Wisconsin NOTICE This report was prepared as an account of work sponsored by the United States Government. Neither the United States nor the United States Atomic Energy Commission, nor any of their employees, nor any of their contractors, subcontrac tors, or their employees, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness or usefulness of any information, apparatus, product or process disclosed, or represents that its use would not infringe privately-owned rights. -

Confluent Vandermonde Matrices, Divided Differences, and Lagrange
CONFLUENT VANDERMONDE MATRICES, DIVIDED DIFFERENCES, AND LAGRANGE-HERMITE INTERPOLATION OVER QUATERNIONS VLADIMIR BOLOTNIKOV Abstract. We introduce the notion of a confluent Vandermonde matrix with quater- nion entries and discuss its connection with Lagrange-Hermite interpolation over quaternions. Further results include the formula for the rank of a confluent Van- dermonde matrix, the representation formula for divided differences of quaternion polynomials and their extensions to the formal power series setting. 1. Introduction The notion of the Vandermonde matrix arises naturally in the context of the La- grange interpolation problem when one seeks a complex polynomial taking prescribed values at given points. Confluent Vandermonde matrices come up once interpolation conditions on the derivatives of an unknown interpolant are also imposed; we refer to the survey [10] for confluent Vandermonde matrices and their applications. The study of Vandermonde matrices over division rings (with further specialization to the ring of quaternions) was initiated in [11]. In the follow-up paper [12], the Vandermonde ma- trices were studied in the setting of a division ring K endowed with an endomorphism s and an s-derivation D, along with their interactions with skew polynomials from the Ore domain K[z,s,D]. The objective of this paper is to extend the results from [11] in a different direction: to introduce a meaningful notion of a confluent Vandermonde matrix (over quaternions only, for the sake of simplicity) and to discuss its connections with Lagrange-Hermite interpolation problem for quaternion polynomials. Let H denote the skew field of quaternions α = x0+ix1+jx2+kx3 where x0,x1,x2,x3 ∈ arXiv:1505.03574v1 [math.RA] 13 May 2015 R and where i, j, k are the imaginary units commuting with R and satisfying i2 = j2 = k2 = ijk = −1.