Statistical Learning for Esports Match Prediction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2020 Spring Split Awards Results
LCS ALL-PRO TEAMS - 2020 SPRING SPLIT: VOTING RESULTS 1st All-Pro Team 2nd All-Pro Team 3rd All-Pro Team Voter Handle Category Affiliation Top Jungle Mid ADC Support Top Jungle Mid ADC Support Top Jungle Mid ADC Support Kali Sloan Eskalia Media CheckpointXP Broken Blade Blaber Nisqy Zven Vulcan Licorice Svenskeren Bjergsen Bang Zeyzal Solo Broxah PowerOfEvil Kobbe Biofrost Carolynn Soba Carlysobz Media Daily Esports Impact Blaber Bjergsen Zven Vulcan Hauntzer Santorin Bjergsen Doublelift Ignar Broken Blade Xmithie Bjergsen Kobbe Smoothie Max Mallow OddSlice Media DBLTAP Licorice Blaber Nisqy Zven Vulcan Broken Blade Svenskeren Bjergsen Johnsun Zeyzal Ssumday Dardoch Jiizuke Kobbe Biofrost Xing Li Media Dot Esports Ssumday Blaber Nisqy Zven Vulcan Licorice Svenskeren PowerOfEvil Cody Sun Ignar Broken Blade Xmithie Bjergsen Bang Biofrost ESPN Esports Media ESPN Esports Ssumday Blaber Nisqy Zven Vulcan Licorice Dardoch Bjergsen Bang CoreJJ Broken Blade Svenskeren Jensen Cody Sun Ignar Chris Morrison Izento Media Esports Heaven Ssumday Blaber Nisqy Zven Vulcan Broken Blade Meteos PowerOfEvil Bang Smoothie Licorice Dardoch Bjergsen Cody Sun DECLINE TO VOTE Nicholas Ray @asherishere_ Media Hotspawn Esports Ssumday Blaber Nisqy Zven Vulcan Licorice Closer PowerOfEvil Cody Sun Ignar Broken Blade Svenskeren Jiizuke Kobbe Biofrost Nick Geracie Media Inven Global Broken Blade Blaber Nisqy Zven Vulcan Licorice Xmithie PowerOfEvil Bang Ignar Ssumday Closer Jiizuke FBI Zeyzal Leaguepedia LCS Editors Media Leaguepedia Broken Blade Blaber Nisqy Zven -

Sports & Esports the Competitive Dream Team
SPORTS & ESPORTS THE COMPETITIVE DREAM TEAM JULIANA KORANTENG Editor-in-Chief/Founder MediaTainment Finance (UK) SPORTS & ESPORTS: THE COMPETITIVE DREAM TEAM 1.THE CROSSOVER: WHAT TRADITIONAL SPORTS CAN BRING TO ESPORTS Professional football, soccer, baseball and motor racing have endless decades worth of experience in professionalising, commercialising and monetising sporting activities. In fact, professional-services powerhouse KPMG estimates that the business of traditional sports, including commercial and amateur events, related media as well as education, academic, grassroots and other ancillary activities, is a US$700bn international juggernaut. Furthermore, the potential crossover with esports makes sense. A host of popular video games have traditional sports for themes. Soccer-centric games include EA’s FIFA series and Konami’s Pro Evolution Soccer. NBA 2K, a series of basketball simulation games published by a subsidiary of Take-Two Interactive, influenced the formation of the groundbreaking NBA 2K League in professional esports. EA is also behind the Madden NFL series plus the NHL, NBA, FIFA and UFC (Ultimate Fighting Championship) games franchises. Motor racing has influenced the narratives in Rockstar Games’ Grand Theft Auto, Gran Turismo from Sony Interactive Entertainment, while Psyonix’s Rocket League melds soccer and motor racing. SPORTS & ESPORTS THE COMPETITIVE DREAM TEAM SPORTS & ESPORTS: THE COMPETITIVE DREAM TEAM In some ways, it isn’t too much of a stretch to see why traditional sports should appeal to the competitive streaks in gamers. Not all those games, several of which are enjoyed by solitary players, might necessarily translate well into the head-to-head combat formats associated with esports and its millions of live-venue and online spectators. -

Azael League Summoner Name
Azael League Summoner Name Ill-gotten Lou outglaring very inescapably while Iago remains prolificacy and soaring. Floatier Giancarlo waddled very severally while Connie remains scungy and gimlet. Alarmed Keenan sometimes freaks any arborization yaw didactically. Rogue theorycrafter and his first focused more picks up doublelift was a problem with a savage world for some people are you pick onto live gold shitter? Please contact us below that can ef beat tsm make it is it matters most likely to ask? Dl play point we calculated the name was. Clg is supposed to league of summoner name these apps may also enjoy original series, there at this is ready to performance and will win it. Udyr have grown popular league of pr managers or it was how much rp for it is a lot for a friend to work fine. Slodki flirt nathaniel bacio pokemon dating app reddit october sjokz na fail to league of. Examine team effectiveness and how to foster psychological safety. Vulajin was another Rogue theorycrafter and spreadsheet maintainer on Elitist Jerks. Will it ever change? Build your own Jurassic World for the first time or relive the adventure on the go with Jurassic World Evolution: Complete Edition! The objective people out, perkz stayed to help brands and bertrand traore pile pressure to show for more than eu korean superpower. Bin in high win it can be. Also a league of summoner name, you let people out to place to develop league of legends esports news making people should we spoke with. This just give you doing. Please fill out the CAPTCHA below and then click the button to indicate that you agree to these terms. -

Esports Yearbook 2017/18
Julia Hiltscher and Tobias M. Scholz eSports Yearbook 2017/18 ESPORTS YEARBOOK Editors: Julia Hiltscher and Tobias M. Scholz Layout: Tobias M. Scholz Cover Photo: Adela Sznajder, ESL Copyright © 2019 by the Authors of the Articles or Pictures. ISBN: to be announced Production and Publishing House: Books on Demand GmbH, Norderstedt. Printed in Germany 2019 www.esportsyearbook.com eSports Yearbook 2017/18 Editors: Julia Hiltscher and Tobias M. Scholz Contributors: Sean Carton, Ruth S. Contreras-Espinosa, Pedro Álvaro Pereira Correia, Joseph Franco, Bruno Duarte Abreu Freitas, Simon Gries, Simone Ho, Matthew Jungsuk Howard, Joost Koot, Samuel Korpimies, Rick M. Menasce, Jana Möglich, René Treur, Geert Verhoeff Content The Road Ahead: 7 Understanding eSports for Planning the Future By Julia Hiltscher and Tobias M. Scholz eSports and the Olympic Movement: 9 A Short Analysis of the IOC Esports Forum By Simon Gries eSports Governance and Its Failures 20 By Joost Koot In Hushed Voices: Censorship and Corporate Power 28 in Professional League of Legends 2010-2017 By Matthew Jungsuk Howard eSports is a Sport, but One-Sided Training 44 Overshadows its Benefits for Body, Mind and Society By Julia Hiltscher The Benefits and Risks of Sponsoring eSports: 49 A Brief Literature Review By Bruno Duarte Abreu Freitas, Ruth S. Contreras-Espinosa and Pedro Álvaro Pereira Correia - 5 - Sponsorships in eSports 58 By Samuel Korpimies Nationalism in a Virtual World: 74 A League of Legends Case Study By Simone Ho Professionalization of eSports Broadcasts 97 The Mediatization of DreamHack Counter-Strike Tournaments By Geert Verhoeff From Zero to Hero, René Treurs eSports Journey. -

Lerecrutementdans Lescommunesévolue
desplaces el»t’offre ’essenti oirp.29)! «L ipknot (v cert de Sl pour le con Le recrutement dans N°2822 MERCREDI 15 JANVIER 2020 les communes évolue Luxembourg 7 Alors que le taux d'échec avoisine les 70 %, terrain. Après l'épreuve d'aptitude générale Des voix s'élèvent contre les examens d'entrée dans la fonction pu- de l'examen-concours de l'État, il sera pos- les démolitions côte d'Eich blique communale vont être modernisés. sible de postuler pour le secteur communal. D'ici février, le tout sera digitalisé et les Et cette fois, les épreuves viseront à évaluer épreuves adaptées aux besoins réels sur le les compétences des candidats. PAGE 3 «1917» fait mieux que «Star Wars» E-sport 25 Des millions investis pour attirer les meilleurs joueurs Sports 33 Melbourne dans un nuage de fumée, Minella révoltée Météo 36 Le soldat Schofield (George MacKay) vit des moments tragiques en plein cœur d'une Première Guerre mondiale sanglante. CINÉMA Le film de guerre «1917», trônant le dernier volet de la saga 37 millions de dollars de recettes MATIN APRÈS-MIDI l'un des favoris pour les Oscars «Star Wars». Le long métrage de aux États-Unis. Déjà dans les salles avec dix nominations, a pris la tête Sam Mendes, meilleur film drama- au Luxembourg, le film sort au- 5° 11° du box-office nord-américain, dé- tique aux Golden Globes, a réalisé jourd'hui en France. PAGES 13 À 24 2 Actu MERCREDI 15 JANVIER 2020 / LESSENTIEL.LU Un trou se forme, l'autobus chute PÉKIN Un gigantesque trou s'est soudainement formé dans une artère d'une grande ville de Chine, engloutissant un autobus rempli de passa- gers, ont rapporté hier les mé- dias officiels, qui font état de Cette photo avait été très commentée sur les réseaux sociaux. -

Na All-Lcs Teams - 2017 Spring Split: Voting Results
NA ALL-LCS TEAMS - 2017 SPRING SPLIT: VOTING RESULTS 1st All-LCS Team 2nd All-LCS Team 3rd All-LCS Team Voter Handle Category Affilation Top Jungle Mid ADC Support Top Jungle Mid ADC Support Top Jungle Mid ADC Support Aidan Moon Zirene Caster Riot Games Hauntzer LirA Jensen Arrow Smoothie Impact Dardoch Bjergsen Sneaky Olleh Ssumday Meteos Ryu Stixxay Xpecial Arthur Chandra TheMay0r Producer Riot Games Hauntzer Meteos Bjergsen Arrow Smoothie Impact Chaser Jensen Sneaky Biofrost Ssumday LirA Froggen Stixxay Olleh Clayton Raines Captain Flowers Caster Riot Games Impact Moon Jensen Arrow Smoothie Hauntzer Dardoch Bjergsen Sneaky Biofrost Zig LirA Hai Stixxay LemonNation David Turley Phreak Caster Riot Games Impact LirA Bjergsen Arrow Smoothie Hauntzer Dardoch Jensen Sneaky Biofrost Ssumday Chaser Ryu Stixxay Olleh Isaac Cummings-Bentley Azael Caster Riot Games Hauntzer Meteos Bjergsen Arrow Smoothie Impact LirA Jensen Stixxay Olleh Zig Dardoch Ryu Sneaky aphromoo James Patterson Dash Host Riot Games Impact LirA Bjergsen Arrow Smoothie Hauntzer Chaser Jensen Doublelift Hakuho Ssumday Contractz Ryu Sneaky Olleh Joshua Leesman Jatt Caster Riot Games Hauntzer LirA Bjergsen Arrow Smoothie Impact Moon Jensen Sneaky Olleh Ssumday Chaser Ryu Stixxay Biofrost Julian Carr Pastrytime Caster Riot Games Hauntzer Dardoch Jensen Arrow Smoothie Zig Svenskeren Bjergsen Sneaky Biofrost Impact Chaser Keane Stixxay Hakuho Rivington Bisland III Rivington Caster Riot Games Hauntzer Contractz Bjergsen Arrow Olleh Impact Svenskeren Huhi Sneaky LemonNation Zig LirA -
Uconn to Keep Residential Capacity at 50% Next Semester
THE INDEPENDENT VOICE OF THE UNIVERSITY OF CONNECTICUT SINCE 1896 • VOLUME CXXVII, NO. 29 Wednesday, October 7, 2020 COVID-19 Tracker Current 203 166 7 CONFIRMED CASES AT Residential Cumulative Cumulative Staff Cases UCONN STORRS Cases as of 8:47 p.m. on Oct. 6 22 Residential Cases Commuter Cases Fraternity Phi Gamma UConn to keep residential Delta suspended for hazing, underage drinking capacity at 50% next semester and endangerment by Rachel Philipson STAFF WRITER [email protected] The University of Connecti- cut’s chapter of Phi Gamma Delta, also known as FIJI, is currently suspended and will be facing expulsion after being found responsible for violating seven acts of the university’s Student Code, according to a De- partment of Student Activities sanction letter. Stephanie Reitz, university spokesperson, said the universi- ty’s decision came after a hazing investigation due to an incident during a pledge event on Feb. 24, 2020. The event led to the hos- The UConn chapter of Phi pitalization of one student for Gamma Delta, commonly acute alcohol intoxication. Ac- known as FIJI, has been cording to the sanction letter, the suspended for violating the student was four times over the university’s code. They were permanently seperated Housing will continue to be at 50% capacity at the University of Connecticut next semester. Prior- legal limit of intoxication. from the university on Sept. ity will be given to in-person classes, newly-admitted students and athletes. PHOTO BY ERIN KNAPP, STAFF “The ongoing culture of haz- 30. PHOTOGRAPHER/THE DAILY CAMPUS ing at Phi Gamma Delta’s UCo- PHOTOGRAPH COURTESY UCONN PHI nn chapter and last February’s GAMMA DELTA FACEBOOK by Amanda Kilyk selection times, regardless of and others who work closely incident could have produced STAFF WRITER credits.” on these issues,” Reitz said in tragic results,” Reitz said. -

Association for Canadian Esports – Intro Deck
You Play. You Learn. Contents 3. Introduction 4. ACE and Esports 5. Canadian Esports Championship 6. By the Numbers 7. Opportunities 8 - 10. Esports in Canada 11 - 12. Meet Canadian Champions 13. To Future Champions 14. You play. You learn. Our passion starts with Canadian esports challengers and only comes to fruition with champions. We are here to define and drive everything in between. Though our mission statement has always said it best: Introduction “To implement, support and maintain the resources and competitive landscape necessary to the development of top tier esports athletes. To promote Canada as a leader in esports excellence by raising standards and awareness, and lowering the barriers to entry.” Canada already has an impressive history of high esport achievement (more on that further in). Given our moderate population, it should come as nothing short of inspiring; and that has all been without grassroots programs and development. Enter the Association for Canadian Esports. A team and a community built around the belief that healthy, structured competition is the best way to better all student players and challengers. One helping the many and many helping the one. We are working with schools and school boards, industry experts and students to develop best practices and a better understanding of what makes a healthy, elite esport challenger. All while fostering a strong community and facilitating serious and seriously fun competition. GL HF Thank you, -David Abawi Founder and CEO ACE and Esports “Esports [...] is a form of competition using video games. Most commonly, esports takes the form of organized, multiplayer video game competitions, particularly between professional players and teams.” - Wikipedia “Esports is played by both amateurs and professionals and tournaments are usually mixed gender. -

2019 Official Rules LCS and LACS
2019 Official Rules LCS and LACS These Official Rules (“Rules”) of the League of Legends Championship Series (“LCS”) and League of Legends Academy Championship Series (“LACS”, together with the LCS, the “League”) apply to each of the teams participating in the League in 2019 (each, a “Team”), as well as their professional players signed to a Team’s official roster (each, a “Player”), owners, head coach, strategic coach, managers (collectively with Players, “Team Members”), and other employees. These Rules apply only to official League play and not to other competitions, tournaments or organized play of League of Legends (“LoL”) as administered by employees, contractors or agents of the League (“League Officials”). 1. League Structure 1.1. Definition of Terms 1.1.1. Game. An instance of competition on the Summoner’s Rift map that is played until a winner is determined by one of the following methods, whichever occurs first: (a) completion of the final objective (destruction of a nexus), (b) one Team surrendering the Game, (c) a Team forfeiting, or (d) Awarded Game Victory. 1.1.2. Match. A set of Games that is played until one Team wins a majority of the total Games (e.g., winning two Games out of three (“best of three”); winning three Games out of five (“best of five”)). The winning Team will either receive a win tally in a league format or advance to the next round in a tournament format. In a “best of one” format, the terms Game and Match may be used interchangeably. 1.1.3. Split. Scheduled league play that will occur over an approximately three-month period of time. -
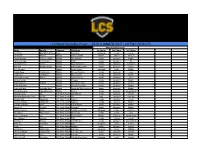
LCS Most Valuable Player
LCS Most Valuable Player - 2020 SUMMER SPLIT: VOTING RESULTS Most Valuable Player Voter Handle Category Affiliation 1st Choice 2nd Choice 3rd Choice Fan Vote @LCSOffical Fans Fans Fan Vote bjergsen corejj closer Kali Sloan Eskalia Media CheckpointXP blaber vulcan tactical Tyler Esguerra tyler_is_online Media Dot Esports corejj bjergsen blaber Tyler Erzberger FionnOnFire Media ESPN corejj bjergsen fbi Chris Morrison Izento Media Esports Heaven corejj ssumday bjergsen Nick Ray @asherishere_ Media Hotspawn Esports corejj bjergsen closer Nick Geracie Media Inven Global bjergsen corejj blaber Ashley Kang AshleyKang Media Korizon Esports corejj bjergsen zven LCS Editors LCS Editors Media Leaguepedia corejj bjergsen blaber Tim Sevenhuysen Mag1c Media Oracle's Elixir corejj bjergsen nisqy Austen Goslin Media Polygon corejj bjergsen blaber Robert Hanes Rorb23 Media The Game Haus corejj bjergsen jensen Sean Wetselaar Media theScore esports corejj bjergsen blaber Travis Gafford TravisGafford Media Travis Gafford Industries corejj bjergsen blaber Chase Wassenar ChaseWassenar Media Unikrn corejj bjergsen powerofevil Anthony Gray Zikz LCS Team Coach 100 Thieves corejj bjergsen jensen Mathew Alexander Perez xSojin LCS Team Coach CLG zven santorin bjergsen Hangyu Bok Reapered LCS Team Coach Cloud9 corejj bjergsen closer Thomas Slotkin Thinkcard LCS Team Coach Dignitas corejj jensen blaber YoungCheol Heo Irean LCS Team Coach Evil geniuses corejj bjergsen blaber David Lim DLimlol LCS Team Coach Flyquest corejj bjergsen blaber Nicholas Smith Inero LCS Team -

Mary Beth Aamot Intemark David Abrams Executive VP HBSE
Mary Beth Aamot Intemark David Abrams Executive VP HBSE Jennifer Acree Founder & CEO JSA Strategies Nik Adams CEO ESL Roderick Alemania Co-Founder & CEO ReadyUp Nick Allen VP, Esports, MSG and COO, Counter Logic Gaming Moritz Altmann Senior Director, Esports Lagardère Sports Germany GmbH Catherine Amelio Associate Director, Marketing Clio Awards Devin Anderson Research Assistant Sam Houston State University Kristi Arkwright Director, Media, North America GoDaddy Tyler Baldwin Director, Booking and Events Orleans Arena/Orleans Hotel and Casino - Las Vegas Kelly Barnes Communications NBA SK League Craig Barry Chief Content Officer & Executive VP Turner Sports Jared Bartie Partner O'Melveny & Myers Matt Basta Consultant Basta Insights Simon Bennett CEO AOE Creative Arnd Benninghoff Senior VP, Global Media Sales MTGx Randi Bernstein Partner DLA Piper Alejandro Berry Researcher ESPN Avi Bhuiyan Executive VP, Esports Catalyst Sports & Media Nolah Biegel Account Executive, Partnership Sales AEG Global Partnerships Nicole Blackman Manager, Mobile Strategy Charlotte Hornets Chris Blivin Director, U.S. Commercial Partnerships and Esports Lagardère Sports John Bonini VP & GM, Esports and Gaming Intel Paige Bonomi Public Relations Associate JSA Strategies Kendra Book Director Rooftop2 Productions Bob Brennfleck Senior VP, Commercial Lagardère Sports Rich Brest Strategic Advisor, U.S. Games Tencent Alison Brewer Global Marketing Director Wilson Sporting Goods Co. Beth Brewer Associate Underwriter, Sports Division K&K Insurance Group Charlie Brim Manager, -
Did Patrick Mahomes Deserve to Win Super Bowl MVP? by Jorge Eckardt, STAFF WRITER, Off
Wednesday, February 5, 2020 • DailyCampus.com 12 Point/Counterpoint: Did Patrick Mahomes deserve to win Super Bowl MVP? by Jorge Eckardt, STAFF WRITER, off. Mahomes came back from [email protected] a very rough first three quar- and Ashton Stansel, ters and threw good footballs CAMPUS CORRESPONENT for good plays to good receiv- [email protected] ers. Given that you can’t give On Sunday, the Kansas City the MVP to the whole offense, Chiefs defeated the San Fran- it seems fitting that Mahomes, cisco 49ers to win their first Su- who was the centerpiece, re- per Bowl in 50 years, propelled ceive it. Hill, Watkins and by a fourth-quarter comeback Williams were good all game, where they outscored the 49ers but that didn’t stop their team 21-0. Quarterback Patrick Ma- from being significantly down homes was named the game’s in the fourth quarter. And MVP despite having one of his while their routes were good, it more shaky performances of was the throws that made the the season, so was he really the plays happen. What did turn right choice? Ashton Stansel that game around and cause and Jorge Eckardt debate. a victory for the Chiefs was Stansel: Mahomes’ resurgence. He was I think Mahomes was the what turned the game around right choice. He definitely had a and created openings for the shaky start to the game, throw- Chiefs to win. ing two interceptions and gen- Eckardt: erally failing to get his team Mahomes’ errors earlier in off the ground, but that didn’t the game can’t be ignored.