Mining Software Repositories for Traceability Links
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Red Hat Enterprise Linux 6 Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Dave Brolley William Cohen Roland Grunberg Aldy Hernandez Karsten Hopp Jakub Jelinek Developer Guide Jeff Johnston Benjamin Kosnik Aleksander Kurtakov Chris Moller Phil Muldoon Andrew Overholt Charley Wang Kent Sebastian Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Edition 0 Author Dave Brolley [email protected] Author William Cohen [email protected] Author Roland Grunberg [email protected] Author Aldy Hernandez [email protected] Author Karsten Hopp [email protected] Author Jakub Jelinek [email protected] Author Jeff Johnston [email protected] Author Benjamin Kosnik [email protected] Author Aleksander Kurtakov [email protected] Author Chris Moller [email protected] Author Phil Muldoon [email protected] Author Andrew Overholt [email protected] Author Charley Wang [email protected] Author Kent Sebastian [email protected] Editor Don Domingo [email protected] Editor Jacquelynn East [email protected] Copyright © 2010 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. -

Ubuntu Kung Fu
Prepared exclusively for Alison Tyler Download at Boykma.Com What readers are saying about Ubuntu Kung Fu Ubuntu Kung Fu is excellent. The tips are fun and the hope of discov- ering hidden gems makes it a worthwhile task. John Southern Former editor of Linux Magazine I enjoyed Ubuntu Kung Fu and learned some new things. I would rec- ommend this book—nice tips and a lot of fun to be had. Carthik Sharma Creator of the Ubuntu Blog (http://ubuntu.wordpress.com) Wow! There are some great tips here! I have used Ubuntu since April 2005, starting with version 5.04. I found much in this book to inspire me and to teach me, and it answered lingering questions I didn’t know I had. The book is a good resource that I will gladly recommend to both newcomers and veteran users. Matthew Helmke Administrator, Ubuntu Forums Ubuntu Kung Fu is a fantastic compendium of useful, uncommon Ubuntu knowledge. Eric Hewitt Consultant, LiveLogic, LLC Prepared exclusively for Alison Tyler Download at Boykma.Com Ubuntu Kung Fu Tips, Tricks, Hints, and Hacks Keir Thomas The Pragmatic Bookshelf Raleigh, North Carolina Dallas, Texas Prepared exclusively for Alison Tyler Download at Boykma.Com Many of the designations used by manufacturers and sellers to distinguish their prod- ucts are claimed as trademarks. Where those designations appear in this book, and The Pragmatic Programmers, LLC was aware of a trademark claim, the designations have been printed in initial capital letters or in all capitals. The Pragmatic Starter Kit, The Pragmatic Programmer, Pragmatic Programming, Pragmatic Bookshelf and the linking g device are trademarks of The Pragmatic Programmers, LLC. -

The Nokia Open Source Browser
The Nokia Open Source Browser Guido Grassel1, Roland Geisler2, Elina Vartiainen1, Deepika Chauhan2, Andrei Popescu1 1Nokia Research Center, P.O. Box 407, 00045 Nokia Group, Finland 2Nokia Technology Platforms, 5 Wayside Road, Burlington, MA 01803, U.S.A, [guido.grassel, roland.geisler, elina.vartiainen, deepika.chauhan, andrei.popescu]@nokia.com ABSTRACT learned and benefits, and chapter 7 summarizes and makes final With the advent of faster wireless networks and more conclusions. capable mobile devices we expect to see growth in the mobile use of the Internet. In this paper we describe a new Web browser for 2. RELATED WORK mobile devices that we have built based on Open Source Software Both Web browsers licensed by Nokia as well as S60’s own components. Our goal was to design a full Web browser that is browser used Narrow Layout. Narrow Layout is a method easy to use, an architecture that is portable to other mobile whereby the Web page is reformatted into one column that fits the software platforms, and an Open Source development approach to width of a typically small handheld device display. This way, the give others the opportunity to further develop it or use it for need for horizontal scrolling is eliminated and the user will see all research purposes. We describe our technical implementation, the the content just by scrolling down. From our own experience usability features that we invented, and discuss the benefits and using these browsers, and based on usability studies [17] we Nokia's plans to work with the Open Source community to further concluded that this method was insufficient. -

Rapid GUI Development with Qtruby
Rapid GUI Development with QtRuby Caleb Tennis The Pragmatic Bookshelf Raleigh, North Carolina Dallas, Texas BOOKLEET © Many of the designations used by manufacturers and sellers to distin- guish their products are claimed as trademarks. Where those designations appear in this book, and The Pragmatic Programmers, LLC was aware of a trademark claim, the designations have been printed in initial capital letters or in all capitals. The Pragmatic Starter Kit, The Pragmatic Pro- grammer, Pragmatic Programming, Pragmatic Bookshelf and the linking g device are trademarks of The Pragmatic Programmers, LLC. Qt® is a registered trademark of Trolltech in Norway, the United States and other countries. Useful Friday Links • Source code from this book and Every precaution was taken in the preparation of this book. However, the other resources. publisher assumes no responsibility for errors or omissions, or for dam- • Free updates to this PDF • Errata and suggestions. To report ages that may result from the use of information (including program list- an erratum on a page, click the ings) contained herein. link in the footer. To see what we’re up to, please visit us at http://www.pragmaticprogrammer.com Copyright © 2006 The Pragmatic Programmers LLC. All rights reserved. This PDF publication is intended for the personal use of the individual whose name appears at the bottom of each page. This publication may not be disseminated to others by any means without the prior consent of the publisher. In particular, the publication must not be made available on the Internet (via a web server, file sharing network, or any other means). -

Master Thesis Innovation Dynamics in Open Source Software
Master thesis Innovation dynamics in open source software Author: Name: Remco Bloemen Student number: 0109150 Email: [email protected] Telephone: +316 11 88 66 71 Supervisors and advisors: Name: prof. dr. Stefan Kuhlmann Email: [email protected] Telephone: +31 53 489 3353 Office: Ravelijn RA 4410 (STEPS) Name: dr. Chintan Amrit Email: [email protected] Telephone: +31 53 489 4064 Office: Ravelijn RA 3410 (IEBIS) Name: dr. Gonzalo Ord´o~nez{Matamoros Email: [email protected] Telephone: +31 53 489 3348 Office: Ravelijn RA 4333 (STEPS) 1 Abstract Open source software development is a major driver of software innovation, yet it has thus far received little attention from innovation research. One of the reasons is that conventional methods such as survey based studies or patent co-citation analysis do not work in the open source communities. In this thesis it will be shown that open source development is very accessible to study, due to its open nature, but it requires special tools. In particular, this thesis introduces the method of dependency graph analysis to study open source software devel- opment on the grandest scale. A proof of concept application of this method is done and has delivered many significant and interesting results. Contents 1 Open source software 6 1.1 The open source licenses . 8 1.2 Commercial involvement in open source . 9 1.3 Opens source development . 10 1.4 The intellectual property debates . 12 1.4.1 The software patent debate . 13 1.4.2 The open source blind spot . 15 1.5 Litterature search on network analysis in software development . -

Webkit and Blink: Open Development Powering the HTML5 Revolution
WebKit and Blink: Open Development Powering the HTML5 Revolution Juan J. Sánchez LinuxCon 2013, New Orleans Myself, Igalia and WebKit Co-founder, member of the WebKit/Blink/Browsers team Igalia is an open source consultancy founded in 2001 Igalia is Top 5 contributor to upstream WebKit/Blink Working with many industry actors: tablets, phones, smart tv, set-top boxes, IVI and home automation. WebKit and Blink Juan J. Sánchez Outline The WebKit technology: goals, features, architecture, code structure, ports, webkit2, ongoing work The WebKit community: contributors, committers, reviewers, tools, events How to contribute to WebKit: bugfixing, features, new ports Blink: history, motivations for the fork, differences, status and impact in the WebKit community WebKit and Blink Juan J. Sánchez WebKit: The technology WebKit and Blink Juan J. Sánchez The WebKit project Web rendering engine (HTML, JavaScript, CSS...) The engine is the product Started as a fork of KHTML and KJS in 2001 Open Source since 2005 Among other things, it’s useful for: Web browsers Using web technologies for UI development WebKit and Blink Juan J. Sánchez Goals of the project Web Content Engine: HTML, CSS, JavaScript, DOM Open Source: BSD-style and LGPL licenses Compatibility: regression testing Standards Compliance Stability Performance Security Portability: desktop, mobile, embedded... Usability Hackability WebKit and Blink Juan J. Sánchez Goals of the project NON-goals: “It’s an engine, not a browser” “It’s an engineering project not a science project” “It’s not a bundle of maximally general and reusable code” “It’s not the solution to every problem” http://www.webkit.org/projects/goals.html WebKit and Blink Juan J. -

Open Source Software Seminar — Konstantin Käfer Webkit
WebKit Bug #17229 Konstantin Käfer 1 Open Source SoftwareOpen Seminar Source — Software Konstantin Seminar Käfer Outline ‣ Project Structure and Goals ‣ History ‣ Communication and Process ‣ People ‣ The Bug 2 Open Source Software Seminar — Konstantin Käfer WebKit GTK Android Google Symbian Chrome Safari Qt Toolkit 3 Open Source Software Seminar — Konstantin Käfer 1. Project Structure and Goals WebCore JavaScriptCore Rendering Engine JavaScript Engine WebKit { Wrapper 4 Open Source Software Seminar — Konstantin Käfer 1. Project Structure and Goals Goals ‣ Web Content Engine: mainly web, but also general- purpose display/interaction engine ‣ Portability: Make it usable on many platforms ‣ Hackability: Keep code easy and maintainable ‣ Usability: Use platform-native UI conventions 5 Open Source Software Seminar — Konstantin Käfer 2. History 2. History 1999: Started as KHTML (KDE project) 2002: Apple forked quietly 2005: Apple opens up development process Now: “Unforking” 6 Open Source Software Seminar — Konstantin Käfer 2. History Apple vs. KHTML ‣ Apple did only the minimum required by LGPL ‣ No access to internal CVS ‣ Changes are released as single large patches ‣ Lots of platform-specific code ‣ Only WebCore/JSCore, but not WebKit was released 7 Open Source Software Seminar — Konstantin Käfer 3. Communication and Process Mailing lists Bug tracker IRC Ticket Patch Review Commit 8 Open Source Software Seminar — Konstantin Käfer 3. Communication and Process Mailing lists ‣ webkit-dev: General discussion ‣ webkit-reviews: Receives all review requests ‣ webkit-changes: Receives all commit messages ‣ webkit-unassigned: All unassigned tickets ‣ webkitsdk-dev: Development on Mac OS X 9 Open Source Software Seminar — Konstantin Käfer 3. Communication and Process Bug tracker ‣ Bugzilla 10 Open Source Software Seminar — Konstantin Käfer 3. -
The State of KHTML in the Beginning
The State of KHTML In The Beginning... Why KHTML Is Important ● KHTML is critical to the success of KDE ● Provides a fast, light web browser and component that tightly integrates with KDE ● Gives us higher visibility as a project: “the web” is much larger than the Linux desktop community ● It's a great testcase for our existing infrastructure What We Have ● CSS 1 / 2 parts of 3 ● Java applets (modular) ● SSL ● ECMAScript 1.2 ● Wallet ● XHTML ● KDE integration ● HTML up to 4.x ● Basic LiveConnect ● “AJAX” support ● KJSEmbed derived ● NS plugin support from KJS What We Don't Have ● Internal SVG support ● DOM bindings to non- C++/non-JS ● Latest NSPlugin API support ● Opacity (Qt4 should help) ● XBL ● Lightweight widgets ● Content Editable KHTML – From Industry ● Great alternative to Gecko and Opera – small, fast, easy to understand, standards compliant ● In use in many embedded platforms as well as desktop browsers – Safari, Nokia, Omni, etc ● Forking is a problem ● Gaining respect from other browser vendors ● Could become a major player with enough 'unity' - >= 10% market share Can We Complete The “Merge”? ● “Merging” is not really feasible at this point ● Unity – a port of WebKit to Qt4: – KPart, KIO development is underway – Ca n co-exist with KHTML from KDE – Works 'now' – Abstraction layer in WebKit makes it relatively easy to port – Open questions: How do we avoid re-forking? How do we merge our own work? If We Go Unity, What Do We Gain? ● Support for many of the functions we lack as described earlier – XBL, content editable, etc ● -

The Konqueror Handbook
The Konqueror Handbook Pamela Roberts Developers: The KDE Team The Konqueror Handbook 2 Contents 1 Overview 6 2 Konqueror Basics7 2.1 Starting Konqueror . .7 2.2 The Parts of Konqueror . .8 2.3 Tooltips and What’s This? . .9 2.4 Left and Middle Mouse Button Actions . .9 2.5 Right Mouse Button Menus . 10 2.6 Viewing Help, Man and Info Pages . 11 3 Konqueror the File Manager 12 3.1 Folders and Paths . 12 3.2 View Modes . 12 3.2.1 File Tip Info . 13 3.2.2 File Previews . 13 3.2.3 Information in the View . 14 3.3 Folder View Properties . 14 3.3.1 The View Properties Dialog . 15 3.4 Navigation . 15 3.4.1 Finding Files and Folders . 16 3.4.2 Removable Devices . 16 3.5 Deleting Files and Folders . 17 3.6 Moving and Copying . 17 3.6.1 Using Drag ’n Drop . 18 3.6.2 Duplicate File or Folder Names . 18 3.7 Selecting Items in the View . 19 3.7.1 Selecting Items Using the Mouse . 19 3.7.2 Selecting Items Using the Keyboard . 19 3.7.3 Selecting Items Using the Menu . 20 3.8 Create New . 20 3.9 Changing Names and Permissions . 21 3.9.1 Copy and Rename . 21 3.10 Configuring File Associations . 22 3.11 At the Command Line . 22 The Konqueror Handbook 4 Konqueror the Web Browser 23 4.1 Connecting to the Internet . 23 4.2 Surfing and Searching . 24 4.3 Tabbed Browsing . 25 4.4 Web Shortcuts . -

Glossary.Pdf
2 Contents 1 Glossary 4 3 1 Glossary Technologies Akonadi The data storage access mechanism for all PIM (Personal Information Manager) data in KDE SC 4. One single storage and retrieval system allows efficiency and extensibility not possible under KDE 3, where each PIM component had its own system. Note that use of Akonadi does not change data storage formats (vcard, iCalendar, mbox, maildir etc.) - it just provides a new way of accessing and updating the data.</p><p> The main reasons for design and development of Akonadi are of technical nature, e.g. having a unique way to ac- cess PIM-data (contacts, calendars, emails..) from different applications (e.g. KMail, KWord etc.), thus eliminating the need to write similar code here and there.</p><p> Another goal is to de-couple GUI applications like KMail from the direct access to external resources like mail-servers - which was a major reason for bug-reports/wishes with regard to perfor- mance/responsiveness in the past.</p><p> More info:</p><p> <a href=https://community.kde.org/KDE_PIM/Akonadi target=_top>Akonadi for KDE’s PIM</a></p><p> <a href=https://en.wikipedia.org/wiki/Akonadi target=_top>Wikipedia: Akonadi</a></p><p> <a href=https://techbase.kde.org/KDE_PIM/Akonadi target=_top>Techbase - Akonadi</a> See Also "GUI". See Also "KDE". Applications Applications are based on the core libraries projects by the KDE community, currently KDE Frameworks and previously KDE Platform.</p><p> More info:</p><p> <a href=https://community.kde.org/Promo/Guidance/Branding/Quick_Guide/ target=_top>KDE Branding</a> See Also "Plasma". -

Webkit in Qt and Qtopia (2008)
WebKit in Qt and Qtopia February 2008 Abstract This whitepaper discusses the challenges faced when developing applications that re- quire dynamic user interfaces based on Web technologies. We describe why Trolltech has chosen WebKit as the preferred option for integration of Web technology in Qt applications, and describe benefits and possible use cases enabled by this integration. Contents 1. Executive Summary 2 2. Rationale 3 2.1. Web Technologies Provide Rich Experiences ................... 3 2.2. Simplifying the User Interface ........................... 3 3. The Trolltech Solution 4 4. Features Overview 5 4.1. Web Standards Support ............................... 5 4.2. Native Application Integration ........................... 6 5. In Depth: Technology Details 7 5.1. Examples ....................................... 7 5.2. Underlying Technologies .............................. 9 5.3. Future Improvements ................................ 10 6. Benefits 11 7. Use Cases 12 WebKit in Qt and Qtopia © 2008 Trolltech ASA 1. Executive Summary Forthcoming versions of Trolltech’s Qt and Qtopia products feature integration of the We- bKit open source rendering and scripting components. The Qt WebKit Integration abstracts the components with highly intuitive Qt APIs, and exploits Qt’s underlying infrastructure to retain its renowned cross-platform portability. The Qt WebKit Integration allows Web and native content to be easily merged on de- vices and in desktop applications, allowing new opportunities for service innovation. Use cases may include mixing Facebook content with local address book details, or populating a scripted idle screen weather widget with live updates. WebKit allows script based – as opposed to code based – development of a UI. This allows for faster design, code and test iterations than compiled code because there is less overhead for deployment. -
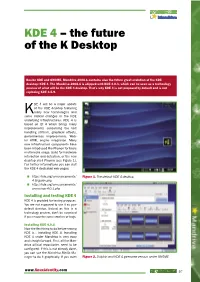
KDE 4 – the Future of the K Desktop
KDE 4 – the future of the K Desktop Beside KDE and GNOME, Mandriva 2008.1 contains also the future great evolution of the KDE desktop: KDE 4. The Mandriva 2008.1 is shipped with KDE 4.0.3, which can be seen as a technology preview of what will be the KDE 4 desktop. That’s why KDE 4 is not proposed by default and is not replacing KDE 3.5.9. DE 4 will be a major update of the KDE desktop featuring Kmany new technologies and some radical changes in the KDE underlying infrastructures. KDE 4 is based on Qt 4 which brings many improvements concerning the text handling (Arthur), graphical effects, performances improvements, Web- kit HTML engine integration. Many new infrastructure components have been introduced like Phonon for basic multimedia usage, Solid for hardware interaction and detection, or the new desktop shell Plasma (see Figure 1). For further informations you can visit the KDE 4 dedicated web pages: http://kde.org/announcements/ Figure 1. The default KDE 4 desktop 4.0/guide.php http://kde.org/announcements/ announce-4.0.3.php Installing and testing KDE 4 KDE 4 is provided for testing purposes. You are not supposed to use it as your default desktop. Indeed as this is a technology preview, don’t be surprised if you encounter some crashes or bugs. Installing KDE 4.0.3 Now the first thing to do before testing KDE is... installing KDE 4. Installing KDE 4 under Mandriva is very easy and straightforward. First, all the Man- driva official repositories need to be configured.