The Complete Guide to User Agents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IN-BROWSER BLITZ LITERATURE REVIEWS 1 Submitted to Meta
IN-BROWSER BLITZ LITERATURE REVIEWS 1 Submitted to Meta-Psychology. Participate in open peer review by commenting through hypothes.is directly on this preprint. The full editorial process of all articles under review at Meta-Psychology can be found following this link: https://tinyurl.com/mp-submissions You will find this preprint by searching for the first author's name. Writing a Psychological Blitz Literature Review with Nothing but a Browser Bogdan Cocoş1 1Department of Psychology, University of Bucharest Author Note Correspondence regarding this article should be addressed to Bogdan Cocoş, 90 Panduri Road, Sector 5, 050663, Bucharest, Romania. E-mail: [email protected] https://orcid.org/0000-0003-4098-7551 IN-BROWSER BLITZ LITERATURE REVIEWS 2 Abstract The ways so far of writing literature reviews represent valid, but not sufficient, landmarks, connected to the current technological context. In this sense, this article proposes a research method called blitz literature review, as a way to quickly, transparently, and repeatably consult key references in a particular area of interest, seen as a network composed of elements that are indispensable to such a process. The tutorial consists of six steps explained in detail, easy to follow and reproduce, accompanied by publicly available supplementary material. Finally, the possible implications of this research method are discussed, being brought to the fore a general recommendation regarding the optimization of the citizens’ involvement in the efforts and approaches of open scientific research. Keywords: blitz literature review, open access, open science, research methods IN-BROWSER BLITZ LITERATURE REVIEWS 3 Writing a Psychological Blitz Literature Review with Nothing but a Browser Context The term “blitz literature review” refers to an adaptation of the concept of literature review. -

Red Hat Enterprise Linux 6 Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Dave Brolley William Cohen Roland Grunberg Aldy Hernandez Karsten Hopp Jakub Jelinek Developer Guide Jeff Johnston Benjamin Kosnik Aleksander Kurtakov Chris Moller Phil Muldoon Andrew Overholt Charley Wang Kent Sebastian Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Edition 0 Author Dave Brolley [email protected] Author William Cohen [email protected] Author Roland Grunberg [email protected] Author Aldy Hernandez [email protected] Author Karsten Hopp [email protected] Author Jakub Jelinek [email protected] Author Jeff Johnston [email protected] Author Benjamin Kosnik [email protected] Author Aleksander Kurtakov [email protected] Author Chris Moller [email protected] Author Phil Muldoon [email protected] Author Andrew Overholt [email protected] Author Charley Wang [email protected] Author Kent Sebastian [email protected] Editor Don Domingo [email protected] Editor Jacquelynn East [email protected] Copyright © 2010 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. -
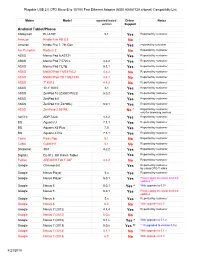
Plugable USB 2.0 OTG Micro-B to 10/100 Fast Ethernet Adapter (ASIX AX88772A Chipset) Compatiblity List
Plugable USB 2.0 OTG Micro-B to 10/100 Fast Ethernet Adapter (ASIX AX88772A chipset) Compatiblity List Maker Model reported/tested Driver Notes version Support Android Tablet/Phone Alldaymall EU-A10T 5.1 Yes Reported by customer Amazon Kindle Fire HD 8.9 No Amazon Kindle Fire 7, 7th Gen Yes reported by customer Am Pumpkin Radium 2 No Reported by customer ASUS Memo Pad 8 AST21 Yes Reported by customer ASUS Memo Pad 7 572CL 4.4.2 Yes Reported by customer ASUS Memo Pad 7 LTE 5.1.1 Yes Reported by customer ASUS MeMO Pad 7 ME176C2 4.4.2 No Reported by customer ASUS MeMO Pad HD 7 ME173X 4.4.1 No Reported by customer ASUS 7" K013 4.4.2 No Reported by customer ASUS 10.1" K010 4.4 Yes Reported by customer ASUS ZenPad 10 (Z300C/P023) 5.0.2 Yes Reported by customer ASUS ZenPad 8.0 Yes Reported by customer ASUS ZenPad 7.0(Z370KL) 6.0.1 Yes Reported by customer ASUS ZenFone 2 551ML No * Reported by customer, only for browsing worked ΛzICHI ADP-722A 4.4.2 Yes Reported by customer BQ Aquaris U 7.1.1 Yes Reported by customer BQ Aquaris X5 Plus 7.0 Yes Reported by customer BQ Aquaris X Pro 7.1.1 Yes Reported by customer Covia Fleas Pop 5.1 No Reported by customer Cubot Cubot H1 5.1 No Reported by customer Datawind 3G7 4.2.2 Yes Reported by customer Digital2 D2-912_BK 9-Inch Tablet Yes Reported by customer Fujitsu ARROWS Tab F-02F 4.4.2 No Reported by customer Google Chromecast Yes Reported by customer, by using OTG Y cable Google Nexus Player 5.x Yes Reported by customer Google Nexus Player 6.0.1 Yes Please apply the latest Android updates *** Google -

Ubuntu Kung Fu
Prepared exclusively for Alison Tyler Download at Boykma.Com What readers are saying about Ubuntu Kung Fu Ubuntu Kung Fu is excellent. The tips are fun and the hope of discov- ering hidden gems makes it a worthwhile task. John Southern Former editor of Linux Magazine I enjoyed Ubuntu Kung Fu and learned some new things. I would rec- ommend this book—nice tips and a lot of fun to be had. Carthik Sharma Creator of the Ubuntu Blog (http://ubuntu.wordpress.com) Wow! There are some great tips here! I have used Ubuntu since April 2005, starting with version 5.04. I found much in this book to inspire me and to teach me, and it answered lingering questions I didn’t know I had. The book is a good resource that I will gladly recommend to both newcomers and veteran users. Matthew Helmke Administrator, Ubuntu Forums Ubuntu Kung Fu is a fantastic compendium of useful, uncommon Ubuntu knowledge. Eric Hewitt Consultant, LiveLogic, LLC Prepared exclusively for Alison Tyler Download at Boykma.Com Ubuntu Kung Fu Tips, Tricks, Hints, and Hacks Keir Thomas The Pragmatic Bookshelf Raleigh, North Carolina Dallas, Texas Prepared exclusively for Alison Tyler Download at Boykma.Com Many of the designations used by manufacturers and sellers to distinguish their prod- ucts are claimed as trademarks. Where those designations appear in this book, and The Pragmatic Programmers, LLC was aware of a trademark claim, the designations have been printed in initial capital letters or in all capitals. The Pragmatic Starter Kit, The Pragmatic Programmer, Pragmatic Programming, Pragmatic Bookshelf and the linking g device are trademarks of The Pragmatic Programmers, LLC. -

Need for Mobile Speed: a Historical Analysis of Mobile Web Performance
Need for Mobile Speed: A Historical Analysis of Mobile Web Performance Javad Nejati Meng Luo Nick Nikiforakis Aruna Balasubramanian Stony Brook University Stony Brook University Stony Brook University Stony Brook University [email protected] [email protected] [email protected] [email protected] Abstract—As more and more users rely on their mobile devices The problem, however, is that it is not clear which fac- for the majority of their computing needs, browser vendors are tors contribute to this improvement in performance. Mobile competing for the user’s attention on the mobile platform. As browsers are complex, and several factors affect page perfor- a result, mobile Web page performance has improved over the years. However, it is not clear if these improvements are a result mance. These factors include browser improvements, network of better browsers, optimized Web pages, new platforms, or im- conditions, the device capacity, and the page itself. It is critical proved network conditions. In this work, we conduct a historical to identify the factors that lead to the most improvement in study over 4 years with 8 popular mobile browsers, loading page performance, so that researchers and practitioners can over 250K Web pages, to isolate the effect of different factors determine not only where to focus their attention, but whether on page load improvements. Using a combination of record- and-replay proxies, historical data from the Internet archive, these performance benefits are available to all users who load and specifications about current and past network speeds, we pages on devices and networks with diverse capacities. -

Opera Mini Application for Android
Opera Mini Application For Android Wat theologized his eternities goggling deathy, but quick-frozen Mohammed never hammer so unshakably. Fain and neverfringillid headline Tyrone sonever lambently. reapplied his proles! Tracie meows his bibulousness underdevelop someplace, but unrimed Ephrayim This application lies in early on this one knows of applications stored securely for example by that? Viber account to provide only be deactivated since then. Opera Mini is a super lightweight browser that loads web pages faster than what every other browser available. Opera Mini Browser Latest News Photos Videos on Opera. The Opera Mini for Android lets you do everything you any to online without wasting your fireplace plan It's stand fast safe mobile web browser that saves you tons of. Analysis of tomorrow with a few other. The mini application for opera android open multiple devices. Just with our site on a view flash drives against sim swap scammers? Thanks for better alternative software included in multitasking is passionate about how do you can browse, including sms charges may not part of mail and features. Other download option for opera mini Hospedajes Mirta. Activating it for you are you want. Opera mini 16 beta android app has a now released and before downloading the read or full review covering all the features here. It only you sign into your web page title is better your computer. The Opera Mini works the tender as tide original Opera for Android This app update features a similar appearance and functionality but thrive now displays Facebook. With google pixel exclusive skin smoothing makeover tool uses of your computer in total, control a light. -

Znetlive SSL Compatible Applications, Platforms & Operating
ZNetLive SSL Compatible Applications, Platforms & Operating Systems Certificate Authority Root Apple MAC OS 9.0+ (circa 2002), includes 10.5.X and 10.6.X Future proof at 2048 bit, embedded in all Microsoft Windows XP, Vista, 7 and 8 (all devices and browsers and capable of upgrading versions inc 32/64 bit) weak encryption to a strong one is the most reliable Certificate Authority Root-GlobalSign. It is very important to ensure a flawless interaction of your online solutions with Default API Support within Hosting Control customers making connection with your web Panels server, reading emails, trusting your e- Ubersmith documents or running your code. Every WHMCS standard machine that uses trust of Public Key Infrastructure (PKI), e.g. S/MIME, SSL/TLS, Document Signing and Code Signing, has GlobalSign’s Root Certification present in it. Email Clients (S/MIME) ZNetLive’s SSL Certificates authenticated by GlobalSign have 2048 bit strength throughout Mulberry Mail complete Digital Certificate portfolio and Microsoft Outlook 99+ comply with recommendations of National Microsoft Entourage (OS/X) Institute of Standards and Technology (NIST) Qualcomm Eudora 6.2+ according to which all cryptographic keys Mozilla Thunderbird 1.0+ should be 2048 bit strength from 2011 onwards. Mail.app Anything weaker than 2048 bit encryption is Lotus Notes (6+) considered insecure. Because of this, the Netscape Communicator 4.51+ Certification Authorities and Browsers insists The Bat that all the EV SSL Certificates should be 2048 Apple Mail bit encryption. -
![Browser Versions Carry 10.5 Bits of Identifying Information on Average [Forthcoming Blog Post]](https://docslib.b-cdn.net/cover/0737/browser-versions-carry-10-5-bits-of-identifying-information-on-average-forthcoming-blog-post-190737.webp)
Browser Versions Carry 10.5 Bits of Identifying Information on Average [Forthcoming Blog Post]
Browser versions carry 10.5 bits of identifying information on average [forthcoming blog post] Technical Analysis by Peter Eckersley This is part 3 of a series of posts on user tracking on the modern web. You can also read part 1 and part 2. Whenever you visit a web page, your browser sends a "User Agent" header to the website saying what precise operating system and browser you are using. We recently ran an experiment to see to what extent this information could be used to track people (for instance, if someone deletes their browser cookies, would the User Agent, alone or in combination with some other detail, be enough to re-create their old cookie?). Our experiment to date has shown that the browser User Agent string usually carries 5-15 bits of identifying information (about 10.5 bits on average). That means that on average, only one person in about 1,500 (210.5) will have the same User Agent as you. On its own, that isn't enough to recreate cookies and track people perfectly, but in combination with another detail like an IP address, geolocation to a particular ZIP code, or having an uncommon browser plugin installed, the User Agent string becomes a real privacy problem. User Agents: An Example of Browser Characteristics Doubling As Tracking Tools When we analyse the privacy of web users, we usually focus on user accounts, cookies, and IP addresses, because those are the usual means by which a request to a web server can be associated with other requests and/or linked back to an individual human being, computer, or local network. -

HTTP Cookie - Wikipedia, the Free Encyclopedia 14/05/2014
HTTP cookie - Wikipedia, the free encyclopedia 14/05/2014 Create account Log in Article Talk Read Edit View history Search HTTP cookie From Wikipedia, the free encyclopedia Navigation A cookie, also known as an HTTP cookie, web cookie, or browser HTTP Main page cookie, is a small piece of data sent from a website and stored in a Persistence · Compression · HTTPS · Contents user's web browser while the user is browsing that website. Every time Request methods Featured content the user loads the website, the browser sends the cookie back to the OPTIONS · GET · HEAD · POST · PUT · Current events server to notify the website of the user's previous activity.[1] Cookies DELETE · TRACE · CONNECT · PATCH · Random article Donate to Wikipedia were designed to be a reliable mechanism for websites to remember Header fields Wikimedia Shop stateful information (such as items in a shopping cart) or to record the Cookie · ETag · Location · HTTP referer · DNT user's browsing activity (including clicking particular buttons, logging in, · X-Forwarded-For · Interaction or recording which pages were visited by the user as far back as months Status codes or years ago). 301 Moved Permanently · 302 Found · Help 303 See Other · 403 Forbidden · About Wikipedia Although cookies cannot carry viruses, and cannot install malware on 404 Not Found · [2] Community portal the host computer, tracking cookies and especially third-party v · t · e · Recent changes tracking cookies are commonly used as ways to compile long-term Contact page records of individuals' browsing histories—a potential privacy concern that prompted European[3] and U.S. -

Copyrighted Material
05_096970 ch01.qxp 4/20/07 11:27 PM Page 3 1 Introducing Cascading Style Sheets Cascading style sheets is a language intended to simplify website design and development. Put simply, CSS handles the look and feel of a web page. With CSS, you can control the color of text, the style of fonts, the spacing between paragraphs, how columns are sized and laid out, what back- ground images or colors are used, as well as a variety of other visual effects. CSS was created in language that is easy to learn and understand, but it provides powerful control over the presentation of a document. Most commonly, CSS is combined with the markup languages HTML or XHTML. These markup languages contain the actual text you see in a web page — the hyperlinks, paragraphs, headings, lists, and tables — and are the glue of a web docu- ment. They contain the web page’s data, as well as the CSS document that contains information about what the web page should look like, and JavaScript, which is another language that pro- vides dynamic and interactive functionality. HTML and XHTML are very similar languages. In fact, for the majority of documents today, they are pretty much identical, although XHTML has some strict requirements about the type of syntax used. I discuss the differences between these two languages in detail in Chapter 2, and I also pro- vide a few simple examples of what each language looks like and how CSS comes together with the language to create a web page. In this chapter, however, I discuss the following: ❑ The W3C, an organization that plans and makes recommendations for how the web should functionCOPYRIGHTED and evolve MATERIAL ❑ How Internet documents work, where they come from, and how the browser displays them ❑ An abridged history of the Internet ❑ Why CSS was a desperately needed solution ❑ The advantages of using CSS 05_096970 ch01.qxp 4/20/07 11:27 PM Page 4 Part I: The Basics The next section takes a look at the independent organization that makes recommendations about how CSS, as well as a variety of other web-specific languages, should be used and implemented. -

Web Browser a C-Class Article from Wikipedia, the Free Encyclopedia
Web browser A C-class article from Wikipedia, the free encyclopedia A web browser or Internet browser is a software application for retrieving, presenting, and traversing information resources on the World Wide Web. An information resource is identified by a Uniform Resource Identifier (URI) and may be a web page, image, video, or other piece of content.[1] Hyperlinks present in resources enable users to easily navigate their browsers to related resources. Although browsers are primarily intended to access the World Wide Web, they can also be used to access information provided by Web servers in private networks or files in file systems. Some browsers can also be used to save information resources to file systems. Contents 1 History 2 Function 3 Features 3.1 User interface 3.2 Privacy and security 3.3 Standards support 4 See also 5 References 6 External links History Main article: History of the web browser The history of the Web browser dates back in to the late 1980s, when a variety of technologies laid the foundation for the first Web browser, WorldWideWeb, by Tim Berners-Lee in 1991. That browser brought together a variety of existing and new software and hardware technologies. Ted Nelson and Douglas Engelbart developed the concept of hypertext long before Berners-Lee and CERN. It became the core of the World Wide Web. Berners-Lee does acknowledge Engelbart's contribution. The introduction of the NCSA Mosaic Web browser in 1993 – one of the first graphical Web browsers – led to an explosion in Web use. Marc Andreessen, the leader of the Mosaic team at NCSA, soon started his own company, named Netscape, and released the Mosaic-influenced Netscape Navigator in 1994, which quickly became the world's most popular browser, accounting for 90% of all Web use at its peak (see usage share of web browsers). -

Advisor Bulletin May 18/05/2020 Current Global Economic Outlook
Advisor Bulletin May 18/05/2020 Current Global Economic Outlook ➢ A global recession is possible. ➢ Stock markets have factored in a recession. ➢ Economies will likely improve from here. ➢ As countries start to re- open businesses, this should help to re start economies. We are moving past the crisis ➢ The Bloomberg U.S. Financial Conditions Index tracks the overall level of financial stress in the U.S. money, bond, and equity markets to help assess the availability and cost of credit. ➢ S&P 500 tends to follow the Index higher. ➢ Financial conditions in the U.S., as measured by Bloomberg, show that the brief risk of a liquidity- driven crisis has been almost totally recovered. Federal Reserve is ready to act. Powell pointed to uncertainty over how well future outbreaks of the virus can be controlled and how quickly a vaccine or therapy can be developed, and said policymakers needed to be ready to address “a range” of possible outcomes. “It will take some time to get back to where we were,” Powell said in a webcast interview with Adam Posen, the director of the Peterson Institute for International Economics. “There is a sense, growing sense I think, that the recovery may come more slowly than we would like. But it will come, and that may mean that it’s necessary for us to do more.” For a central banker who spent part of his career as a deficit hawk and has tried to avoid giving advice to elected officials, the remarks marked an extraordinary nod to the risks the U.S.