A Sketch-Based Interface for Parametric Character
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CRU DANCE Friday March 12Th - Sunday March 14Th, 2021 MASON, OH
CRU DANCE Friday March 12th - Sunday March 14th, 2021 MASON, OH th Friday March 12 , 2021 Start Time: 5:00pm Studio Check in- Studio B, F, Q 4:30 PM Jadden Hahn, Shaylee Knott, Heidi Schleidt, 1 Q Coffee Anyone? Teen Tap Small Group Intermediate 5:00 PM Eliana Tipton Anna Armold, Olivia Ashmore, Lana Baker, Gabrielle Barbosa, Lilliana Barbosa, Quinnlyn Musical Blaisdell, Annabel Blake, Ava Constable, 2 F Little Girls Junior Large Group Novice 5:03 PM Theater Morgan Flick, Bella Hughes, Madelyn Hughes, Abigail Larson, Teagan Manley, Andromeda Search, Jackie Wright, Pammy Wright 3 Q I Can Be Anything Petite Jazz Solo Novice Arianna Liggett 5:07 PM 4 Q Miss Invisible Petite Lyrical Solo Novice Makenzie Berling 5:09 PM Piper Hays, Brooklyn Homan, Franky Jellison, 5 B Booty Swing Junior Jazz Small Group Intermediate Janessa Smuts, Sophie Steinbrunner, 5:12 PM Madison Wendeln 6 F Meant Senior Contemporary Solo Intermediate Pammy Wright 5:15 PM 7 B Womanizer Senior Jazz Solo Intermediate Shelby Ranly 5:18 PM 8 Q Just Mime'en My Business Junior Acrobat Solo Novice Alexis Burke 5:21 PM I Just Died in Your Arms 9 F Junior Open Solo Elite Jackie Wright 5:24 PM Tonight Anna Armold, Quinnlyn Blaisdell, Morgan 10 F Shadows of the Night Junior Jazz Small Group Intermediate 5:26 PM Flick, Madelyn Hughes Jadden Hahn, Gabrielle Helton, Shaylee 11 Q Amazing Grace Teen Contemporary Small Group Intermediate Knott, Reese Lynch, Heidi Schleidt, Eliana 5:29 PM Tipton 12 F Speechless Mini Jazz Solo Novice Teagan Manley 5:32 PM 13 B Dynamite Junior Jazz Solo Intermediate -

Skins Uk Download Season 1 Episode 1: Frankie
skins uk download season 1 Episode 1: Frankie. Howard Jones - New Song Scene: Frankie in her room animating Strange Boys - You Can't Only Love When You Want Scene: Frankie turns up at college with a new look Aeroplane - We Cant Fly Scene: Frankie decides to go to the party anyway. Fergie - Glamorous Scene: Music playing from inside the club. Blondie - Heart of Glass Scene: Frankie tries to appeal to Grace and Liv but Mini chucks her out, then she gets kidnapped by Alo & Rich. British Sea Power - Waving Flags Scene: At the swimming pool. Skins Series 1 Complete Skins Series 2 Complete Skins Series 3 Complete Skins Series 4 Complete Skins Series 5 Complete Skins Series 6 Complete Skins - Effy's Favourite Moments Skins: The Novel. Watch Skins. Skins in an award-winning British teen drama that originally aired in January of 2007 and continues to run new seasons today. This show follows the lives of teenage friends that are living in Bristol, South West England. There are many controversial story lines that set this television show apart from others of it's kind. The cast is replaced every two seasons to bring viewers brand new story lines with entertaining and unique characters. The first generation of Skins follows teens Tony, Sid, Michelle, Chris, Cassie, Jal, Maxxie and Anwar. Tony is one of the most popular boys in sixth form and can be quite manipulative and sarcastic. Michelle is Tony's girlfriend, who works hard at her studies, is very mature, but always puts up with Tony's behavior. -

Comic-Con Issue 15 Rewe St., Brooklyn, NY 11211 3210 Vanowen St., Burbank, CA 91505 [email protected] [email protected]
PERSPECTIVE THE JOURNAL OF THE ART DIRECTORS GUILD JULY – AUGUST 2015 US $8.00 Comic-Con Issue 15 Rewe St., Brooklyn, NY 11211 3210 Vanowen St., Burbank, CA 91505 [email protected] [email protected] BRIDGEPROPS.COM ® contents The Anatomy of an Anti-Hero 12 Constantine’s darkness doesn’t feel so bad by David Blass, Production Designer Tomorrowland 20 Logos and pins by Clint Schultz, Graphic Designer Comic Con, Pot Fields 28 Designing the world of Ted 2 & a Giant Cake by Stephen Lineweaver, Production Designer Welcome to Nowhere 36 Manhattan in New Mexico by Ruth Ammon, Production Designer Comic Book Art 46 Created by Art Directors Guild members Collected by Patrick Rodriguez, Illustrator 5 EDITORIAL 6 CONTRIBUTORS 8 NEWS ON THE COVER: 58 PRODUCTION DESIGN Director Brad Bird called on Graphic Designer Clint Schultz three different times to develop 60 MEMBERSHIP key logos for Tomorrowland (Scott Chambliss, Production Designer). His last assignment 61 CALENDAR resulted in this fully rendered 3D model of 62 MILESTONES the T pin that is an important prop and story element in the film. It went on to become 64 RESHOOTS central to the studio’s marketing efforts. PERSPECTIVE | JULY/AUGUST 2015 1 PERSPECTIVE THE JOURNAL OF THE ART DIRECTORS GUILD July/August 2015 PERSPECTIVE ISSN: 1935-4371, No. 60, © 2015. Published bimonthly by the Art Directors Guild, Local 800, IATSE, 11969 Ventura Blvd., Second Floor, Studio City, CA 91604-2619. Telephone 818 762 9995. Fax 818 762 9997. Periodicals postage paid at North Hollywood, CA, and at other cities. -

Animating Race the Production and Ascription of Asian-Ness in the Animation of Avatar: the Last Airbender and the Legend of Korra
Animating Race The Production and Ascription of Asian-ness in the Animation of Avatar: The Last Airbender and The Legend of Korra Francis M. Agnoli Submitted for the degree of Doctor of Philosophy (PhD) University of East Anglia School of Art, Media and American Studies April 2020 This copy of the thesis has been supplied on condition that anyone who consults it is understood to recognise that its copyright rests with the author and that use of any information derived there from must be in accordance with current UK Copyright Law. In addition, any quotation or extract must include full attribution. 2 Abstract How and by what means is race ascribed to an animated body? My thesis addresses this question by reconstructing the production narratives around the Nickelodeon television series Avatar: The Last Airbender (2005-08) and its sequel The Legend of Korra (2012-14). Through original and preexisting interviews, I determine how the ascription of race occurs at every stage of production. To do so, I triangulate theories related to race as a social construct, using a definition composed by sociologists Matthew Desmond and Mustafa Emirbayer; re-presentations of the body in animation, drawing upon art historian Nicholas Mirzoeff’s concept of the bodyscape; and the cinematic voice as described by film scholars Rick Altman, Mary Ann Doane, Michel Chion, and Gianluca Sergi. Even production processes not directly related to character design, animation, or performance contribute to the ascription of race. Therefore, this thesis also references writings on culture, such as those on cultural appropriation, cultural flow/traffic, and transculturation; fantasy, an impulse to break away from mimesis; and realist animation conventions, which relates to Paul Wells’ concept of hyper-realism. -

2011-2012 Annual Report to the Case Western Reserve Community: Ours Is a Campus Full of People Driven to Make a Difference
THINK AHEAD 2011-2012 Annual Report To the Case Western Reserve Community: Ours is a campus full of people driven to make a difference. Whether pursuing a cure for Alzheimer’s or prosecuting pirates on the high seas, our faculty, staff, and students strive for impact. They translate discoveries about nature into state-of- the-art technology. They turn insights about oral health into answers to orthopedic issues. They even use irritation about a common car problem as fuel for a promising product. Are we dreamers? Absolutely. But at Case Western Reserve, aspirations are only the start. Then come questions: How can we make this concept work? What tweaks will take it farther? What improvements can we add? As Gmail inventor Paul Buchheit (’98) told our 2012 graduates, the correct path may not be the one everyone else identifies. Sometimes the answer involves forging through unfamiliar trails. In such instances, the key is not only to listen to instincts, but follow them. In 2011-2012, that spirit spurred Celia Weatherhead to announce that she and her late husband, Albert, had committed $50 million to our university to advance management education and community health. It led an anonymous donor to commit $20 million for our programs in the natural sciences. And it prompted trustee Larry Sears and his wife, Sally Zlotnik Sears, to contribute $5 million to think[box], a campus initiative to encourage entrepreneurial innovation. Such support inspires us all. It also helps attract still more like-minded achievers. The undergraduate class we admitted this spring represents the largest, most diverse and most academically accomplished in our university’s history. -

Full Competitor List
Competitor List Argentina Entries: 2 Height Handler Dog Breed 300 Fernando Estevez Costas Arya Mini Poodle 600 Jorge Esteban Ramos Trice Border Collie Salinas Australia Entries: 6 Height Handler Dog Breed 400 Reserve Dog Casper Dutch Smoushond 500 Maria Thiry Tebbie Border Collie 500 Maria Thiry Beat Pumi 600 Emily Abrahams Loki Border Collie 600 Reserve Dog Ferno Border Collie 600 Gillian Self Showtime Border Collie Austria Entries: 12 Height Handler Dog Breed 300 Helgar Blum Tim Parson Russell Ter 300 Markus Fuska Cerry Lee Shetland Sheepdog 300 Markus Fuska Nala Crossbreed 300 Petra Reichetzer Pixxel Shetland Sheepdog 400 Gabriele Breitenseher Aileen Shetland Sheepdog 400 Gregor Lindtner Asrael Shetland Sheepdog 400 Daniela Lubei Ebby Shetland Sheepdog 500 Petra Reichetzer Paisley Border Collie 500 Hermann Schauhuber Haily Border Collie 600 Michaela Melcher Treat Border Collie 600 Sonja Mladek Flynn Border Collie 600 Sonja Mladek Trigger Border Collie Belgium Entries: 17 Height Handler Dog Breed 300 Dorothy Capeta Mauricio Ben Jack Russell Terrier 300 Ann Herreman Lance Shetland Sheepdog 300 Brechje Pots Dille Jack Russell Terrier 300 Kristel Van Den Eynde Mini Jack Russell Terrier 400 Ann Herreman Qiell Shetland Sheepdog 400 Anneleen Holluyn Hjatho Mini Australian Shep 400 Anneleen Holluyn Ippy Mini Australian Shep 26-Apr-19 19:05 World Agility Open 2019 Page 1 of 14 500 Franky De Witte Laser Border Collie 500 Franky De Witte Idol Border Collie 500 Erik Denecker Tara Border Collie 500 Philippe Dubois Jessy Border Collie 600 Kevin Baert -

Delaware Recommended Curriculum Unit Template
Delaware Recommended Curriculum Unit Template Preface: This unit has been created as a model for teachers in their designing or redesigning of course curricula. It is by no means intended to be inclusive; rather it is meant to be a springboard for a teacher’s thoughts and creativity. The information we have included represents one possibility for developing a unit based on the Delaware content standards and the Understanding by Design framework and philosophy. Subject/Topic Area: Visual Art Grade Level(s): 4 Searchable Key Words: cartoon, animation, cel, storyboard Designed By: Dave Kelleher District: Red Clay Time Frame: Eight 45 minute classes Date: November 18, 2008 Revised: May 2009 Brief Summary of Unit Creating, performing, responding and making connections are learning concepts that are at the core of the Visual and Performing Arts curriculum. This unit will stress the responding concept and the product for responding will be animation. Students will view animated cartoons (non-computer generated) and analyze how multiple uses of “one image”, or cel (short for celluloid- thin sheets of clear plastic that characters are drawn on and then painted), create a story in motion and convey the point/opinion of the animator. Ultimately, focus will center on one individual cel and how it relates to the given point/opinion and, due to its cartoon nature, may/may not effectively convey the opinion (i.e. some people might find it difficult to relate to a serious topic when the character presented is an adorable pink bunny with a bowtie). Because the art world had previously considered animation beneath it, artistic skill and creativity in the creation of characters, emotions, storyline, and backgrounds were often ignored. -
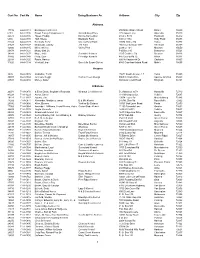
Cert No Name Doing Business As Address City Zip 1 Cust No
Cust No Cert No Name Doing Business As Address City Zip Alabama 17732 64-A-0118 Barking Acres Kennel 250 Naftel Ramer Road Ramer 36069 6181 64-A-0136 Brown Family Enterprises Llc Grandbabies Place 125 Aspen Lane Odenville 35120 22373 64-A-0146 Hayes, Freddy Kanine Konnection 6160 C R 19 Piedmont 36272 6394 64-A-0138 Huff, Shelia Blackjack Farm 630 Cr 1754 Holly Pond 35083 22343 64-A-0128 Kennedy, Terry Creeks Bend Farm 29874 Mckee Rd Toney 35773 21527 64-A-0127 Mcdonald, Johnny J M Farm 166 County Road 1073 Vinemont 35179 42800 64-A-0145 Miller, Shirley Valley Pets 2338 Cr 164 Moulton 35650 20878 64-A-0121 Mossy Oak Llc P O Box 310 Bessemer 35021 34248 64-A-0137 Moye, Anita Sunshine Kennels 1515 Crabtree Rd Brewton 36426 37802 64-A-0140 Portz, Stan Pineridge Kennels 445 County Rd 72 Ariton 36311 22398 64-A-0125 Rawls, Harvey 600 Hollingsworth Dr Gadsden 35905 31826 64-A-0134 Verstuyft, Inge Sweet As Sugar Gliders 4580 Copeland Island Road Mobile 36695 Arizona 3826 86-A-0076 Al-Saihati, Terrill 15672 South Avenue 1 E Yuma 85365 36807 86-A-0082 Johnson, Peggi Cactus Creek Design 5065 N. Main Drive Apache Junction 85220 23591 86-A-0080 Morley, Arden 860 Quail Crest Road Kingman 86401 Arkansas 20074 71-A-0870 & Ellen Davis, Stephanie Reynolds Wharton Creek Kennel 512 Madison 3373 Huntsville 72740 43224 71-A-1229 Aaron, Cheryl 118 Windspeak Ln. Yellville 72687 19128 71-A-1187 Adams, Jim 13034 Laure Rd Mountainburg 72946 14282 71-A-0871 Alexander, Marilyn & James B & M's Kennel 245 Mt. -

Scheme and Syllabus of B. Tech. 3D Animation and Graphics Engineering
IKG PUNJAB TECHNICAL UNIVERSITY Batch 2012 Scheme and Syllabus Of B. Tech. 3D Animation and Graphics Engineering PUNJAB TECHNICAL UNIVERSITY, JALANDHAR Punjab Technical University B.Tech 3D Aninmations & Graphics Third Semester Contact Hours: 32 Hrs. Load Marks Distribution Course Code Course Name Allocation Total Marks Credits L T P Internal External BTCS301 Computer Architecture 3 1 - 40 60 100 4 BTAM302 Engg. Mathematics-III 3 1 - 40 60 100 4 BTCS304 Data Structures 3 1 - 40 60 100 4 BTCS305 Object Oriented 3 1 - 40 60 100 4 Programming using C++ BTAG301 Basics of Animation 3 1 - 40 60 100 4 BTCS306 Data Structures Lab - - 4 30 20 50 2 BTCS307 Institutional Practical - - - 60 40 100 1 Training BTCS309 Object Oriented - - 4 30 20 50 2 Programming using C++ Lab BTAG302 Basics of Animation - - 4 30 20 50 2 Lab B.Tech 3D Aninmations & Graphics Fourth Semester Contact Hours: 32 Hrs. Load Marks Distribution Course Code Course Name Allocation Total Credits L T P Internal External Marks BTAG 401 Fundamentals of 3 1 - 40 60 100 4 Preproduction BTAG 402 Multimedia Technologies 3 1 - 40 60 100 4 BTAG 403 Multimedia Networks 3 1 - 40 60 100 4 BTCS 504 Computer Graphics 3 1 - 40 60 100 4 BTAG 404 Multimedia Devices 3 1 - 40 60 100 4 BTAG 405 Preproduction Workshop - - 4 30 20 50 2 BTCS 509 Computer Graphics Lab - - 2 30 20 50 1 BTAG 406 Animation lab-II - - 4 30 20 50 2 BTAG 407 Network Lab - - 2 30 20 50 1 General Fitness - - - 100 - 100 - Total 15 5 12 420 380 800 26 PUNJAB TECHNICAL UNIVERSITY, JALANDHAR B.Tech 3D Aninmations & Graphics Fifth Semester Contact Hours: 30 Hrs. -

Syllabus for the Bachelor in Animation
UNIVERSITYU OF MUMBAI’S GARWARE INSTITUTE OF CAREER EDUCATION & DEVELOPMENT Syllabus for the Bachelor in Animation Credit Based Semester and Grading System with effect from the Academic Year (2017-2018) AC 11-05-2017 Item No. UNIVERSITYU OF MUMBAI’S SyllabusU for Approval Sr. No. Heading Particulars 1 Title of the Course Bachelor in Animation 10+2 pass – with minimum 45% 2 Eligibility for Admission marks Admissions on the basis of Written Test & Interview. 3 Passing Marks 50% passing marks Ordinances / 4 Regulations ( if any) 5 No. of Years / Semesters Three years full time/ 6 semester 6 Level Bachelor 7 Pattern Yearly / semester New 8 Status To be implemented from 9 From academic year 2017-18 Academic Year Date: 11/05/2017 Signature : Dr. Anil Karnik, I/C. Director, Garware Institute of Career Education & Development INTRODUCTIONU A sequence of images creates an illusion of a moving object is termed as Animation. India is one of the most preferred outsourcing countries. We not only do outsourcing services, we are also a creator of original animation. Some of the popular original contents are Chota bheem, Little Krishna, Delhi Safari, Arjun, Road side Romeo etc. Animation is a combination of entertainment and technology. It is composed of design, drawing, layout and production of graphically rich multimedia clips. Time and space are important in animation. Those who excel in drawing and creativity can choose animation as their career. An animator’s job is to analyze the script thoroughly and get into the skin of the character. Creating idea, storyboard, Character design, backgrounds, etc and using technical methodology to create stunning visuals short movies is the ideal steps in making a successful animation feature. -

SKIN GRAFTS and SKIN SUBSTITUTES James F Thornton MD
SKIN GRAFTS AND SKIN SUBSTITUTES James F Thornton MD HISTORY OF SKIN GRAFTS ANATOMY Ratner1 and Hauben and colleagues2 give excel- The character of the skin varies greatly among lent overviews of the history of skin grafting. The individuals, and within each person it varies with following highlights are excerpted from these two age, sun exposure, and area of the body. For the sources. first decade of life the skin is quite thin, but from Grafting of skin originated among the tilemaker age 10 to 35 it thickens progressively. At some caste in India approximately 3000 years ago.1 A point during the fourth decade the thickening stops common practice then was to punish a thief or and the skin once again begins to decrease in sub- adulterer by amputating the nose, and surgeons of stance. From that time until the person dies there is their day took free grafts from the gluteal area to gradual thinning of dermis, decreased skin elastic- repair the deformity. From this modest beginning, ity, and progressive loss of sebaceous gland con- skin grafting evolved into one of the basic clinical tent. tools in plastic surgery. The skin also varies greatly with body area. Skin In 1804 an Italian surgeon named Boronio suc- from the eyelid, postauricular and supraclavicular cessfully autografted a full-thickness skin graft on a areas, medial thigh, and upper extremity is thin, sheep. Sir Astley Cooper grafted a full-thickness whereas skin from the back, buttocks, palms of the piece of skin from a man’s amputated thumb onto hands and soles of the feet is much thicker. -

Adventuring with Books: a Booklist for Pre-K-Grade 6. the NCTE Booklist
DOCUMENT RESUME ED 311 453 CS 212 097 AUTHOR Jett-Simpson, Mary, Ed. TITLE Adventuring with Books: A Booklist for Pre-K-Grade 6. Ninth Edition. The NCTE Booklist Series. INSTITUTION National Council of Teachers of English, Urbana, Ill. REPORT NO ISBN-0-8141-0078-3 PUB DATE 89 NOTE 570p.; Prepared by the Committee on the Elementary School Booklist of the National Council of Teachers of English. For earlier edition, see ED 264 588. AVAILABLE FROMNational Council of Teachers of English, 1111 Kenyon Rd., Urbana, IL 61801 (Stock No. 00783-3020; $12.95 member, $16.50 nonmember). PUB TYPE Books (010) -- Reference Materials - Bibliographies (131) EDRS PRICE MF02/PC23 Plus Postage. DESCRIPTORS Annotated Bibliographies; Art; Athletics; Biographies; *Books; *Childress Literature; Elementary Education; Fantasy; Fiction; Nonfiction; Poetry; Preschool Education; *Reading Materials; Recreational Reading; Sciences; Social Studies IDENTIFIERS Historical Fiction; *Trade Books ABSTRACT Intended to provide teachers with a list of recently published books recommended for children, this annotated booklist cites titles of children's trade books selected for their literary and artistic quality. The annotations in the booklist include a critical statement about each book as well as a brief description of the content, and--where appropriate--information about quality and composition of illustrations. Some 1,800 titles are included in this publication; they were selected from approximately 8,000 children's books published in the United States between 1985 and 1989 and are divided into the following categories: (1) books for babies and toddlers, (2) basic concept books, (3) wordless picture books, (4) language and reading, (5) poetry. (6) classics, (7) traditional literature, (8) fantasy,(9) science fiction, (10) contemporary realistic fiction, (11) historical fiction, (12) biography, (13) social studies, (14) science and mathematics, (15) fine arts, (16) crafts and hobbies, (17) sports and games, and (18) holidays.