Logic Meets Algebra: the Case of Regular Languages ∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Automata, Semigroups and Duality
Automata, semigroups and duality Mai Gehrke1 Serge Grigorieff2 Jean-Eric´ Pin2 1Radboud Universiteit 2LIAFA, CNRS and University Paris Diderot TANCL’07, August 2007, Oxford LIAFA, CNRS and University Paris Diderot Outline (1) Four ways of defining languages (2) The profinite world (3) Duality (4) Back to the future LIAFA, CNRS and University Paris Diderot Part I Four ways of defining languages LIAFA, CNRS and University Paris Diderot Words and languages Words over the alphabet A = {a, b, c}: a, babb, cac, the empty word 1, etc. The set of all words A∗ is the free monoid on A. A language is a set of words. Recognizable (or regular) languages can be defined in various ways: ⊲ by (extended) regular expressions ⊲ by finite automata ⊲ in terms of logic ⊲ by finite monoids LIAFA, CNRS and University Paris Diderot Basic operations on languages • Boolean operations: union, intersection, complement. • Product: L1L2 = {u1u2 | u1 ∈ L1,u2 ∈ L2} Example: {ab, a}{a, ba} = {aa, aba, abba}. • Star: L∗ is the submonoid generated by L ∗ L = {u1u2 · · · un | n > 0 and u1,...,un ∈ L} {a, ba}∗ = {1, a, aa, ba, aaa, aba, . .}. LIAFA, CNRS and University Paris Diderot Various types of expressions • Regular expressions: union, product, star: (ab)∗ ∪ (ab)∗a • Extended regular expressions (union, intersection, complement, product and star): A∗ \ (bA∗ ∪ A∗aaA∗ ∪ A∗bbA∗) • Star-free expressions (union, intersection, complement, product but no star): ∅c \ (b∅c ∪∅caa∅c ∪∅cbb∅c) LIAFA, CNRS and University Paris Diderot Finite automata a 1 2 The set of states is {1, 2, 3}. b The initial state is 1. b a 3 The final states are 1 and 2. -

Midterm Study Sheet for CS3719 Regular Languages and Finite
Midterm study sheet for CS3719 Regular languages and finite automata: • An alphabet is a finite set of symbols. Set of all finite strings over an alphabet Σ is denoted Σ∗.A language is a subset of Σ∗. Empty string is called (epsilon). • Regular expressions are built recursively starting from ∅, and symbols from Σ and closing under ∗ Union (R1 ∪ R2), Concatenation (R1 ◦ R2) and Kleene Star (R denoting 0 or more repetitions of R) operations. These three operations are called regular operations. • A Deterministic Finite Automaton (DFA) D is a 5-tuple (Q, Σ, δ, q0,F ), where Q is a finite set of states, Σ is the alphabet, δ : Q × Σ → Q is the transition function, q0 is the start state, and F is the set of accept states. A DFA accepts a string if there exists a sequence of states starting with r0 = q0 and ending with rn ∈ F such that ∀i, 0 ≤ i < n, δ(ri, wi) = ri+1. The language of a DFA, denoted L(D) is the set of all and only strings that D accepts. • Deterministic finite automata are used in string matching algorithms such as Knuth-Morris-Pratt algorithm. • A language is called regular if it is recognized by some DFA. • ‘Theorem: The class of regular languages is closed under union, concatenation and Kleene star operations. • A non-deterministic finite automaton (NFA) is a 5-tuple (Q, Σ, δ, q0,F ), where Q, Σ, q0 and F are as in the case of DFA, but the transition function δ is δ : Q × (Σ ∪ {}) → P(Q). -

Chapter 6 Formal Language Theory
Chapter 6 Formal Language Theory In this chapter, we introduce formal language theory, the computational theories of languages and grammars. The models are actually inspired by formal logic, enriched with insights from the theory of computation. We begin with the definition of a language and then proceed to a rough characterization of the basic Chomsky hierarchy. We then turn to a more de- tailed consideration of the types of languages in the hierarchy and automata theory. 6.1 Languages What is a language? Formally, a language L is defined as as set (possibly infinite) of strings over some finite alphabet. Definition 7 (Language) A language L is a possibly infinite set of strings over a finite alphabet Σ. We define Σ∗ as the set of all possible strings over some alphabet Σ. Thus L ⊆ Σ∗. The set of all possible languages over some alphabet Σ is the set of ∗ all possible subsets of Σ∗, i.e. 2Σ or ℘(Σ∗). This may seem rather simple, but is actually perfectly adequate for our purposes. 6.2 Grammars A grammar is a way to characterize a language L, a way to list out which strings of Σ∗ are in L and which are not. If L is finite, we could simply list 94 CHAPTER 6. FORMAL LANGUAGE THEORY 95 the strings, but languages by definition need not be finite. In fact, all of the languages we are interested in are infinite. This is, as we showed in chapter 2, also true of human language. Relating the material of this chapter to that of the preceding two, we can view a grammar as a logical system by which we can prove things. -

Language and Automata Theory and Applications
LANGUAGE AND AUTOMATA THEORY AND APPLICATIONS Carlos Martín-Vide Characterization • It deals with the description of properties of sequences of symbols • Such an abstract characterization explains the interdisciplinary flavour of the field • The theory grew with the need of formalizing and describing the processes linked with the use of computers and communication devices, but its origins are within mathematical logic and linguistics A bit of history • Early roots in the work of logicians at the beginning of the XXth century: Emil Post, Alonzo Church, Alan Turing Developments motivated by the search for the foundations of the notion of proof in mathematics (Hilbert) • After the II World War: Claude Shannon, Stephen Kleene, John von Neumann Development of computers and telecommunications Interest in exploring the functions of the human brain • Late 50s XXth century: Noam Chomsky Formal methods to describe natural languages • Last decades Molecular biology considers the sequences of molecules formed by genomes as sequences of symbols on the alphabet of basic elements Interest in describing properties like repetitions of occurrences or similarity between sequences Chomsky hierarchy of languages • Finite-state or regular • Context-free • Context-sensitive • Recursively enumerable REG ⊂ CF ⊂ CS ⊂ RE Finite automata: origins • Warren McCulloch & Walter Pitts. A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics, 5:115-133, 1943 • Stephen C. Kleene. Representation of events in nerve nets and -
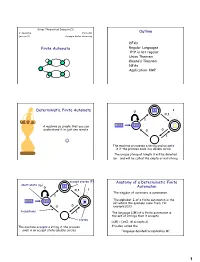
Deterministic Finite Automata 0 0,1 1
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -

2020 SIGACT REPORT SIGACT EC – Eric Allender, Shuchi Chawla, Nicole Immorlica, Samir Khuller (Chair), Bobby Kleinberg September 14Th, 2020
2020 SIGACT REPORT SIGACT EC – Eric Allender, Shuchi Chawla, Nicole Immorlica, Samir Khuller (chair), Bobby Kleinberg September 14th, 2020 SIGACT Mission Statement: The primary mission of ACM SIGACT (Association for Computing Machinery Special Interest Group on Algorithms and Computation Theory) is to foster and promote the discovery and dissemination of high quality research in the domain of theoretical computer science. The field of theoretical computer science is the rigorous study of all computational phenomena - natural, artificial or man-made. This includes the diverse areas of algorithms, data structures, complexity theory, distributed computation, parallel computation, VLSI, machine learning, computational biology, computational geometry, information theory, cryptography, quantum computation, computational number theory and algebra, program semantics and verification, automata theory, and the study of randomness. Work in this field is often distinguished by its emphasis on mathematical technique and rigor. 1. Awards ▪ 2020 Gödel Prize: This was awarded to Robin A. Moser and Gábor Tardos for their paper “A constructive proof of the general Lovász Local Lemma”, Journal of the ACM, Vol 57 (2), 2010. The Lovász Local Lemma (LLL) is a fundamental tool of the probabilistic method. It enables one to show the existence of certain objects even though they occur with exponentially small probability. The original proof was not algorithmic, and subsequent algorithmic versions had significant losses in parameters. This paper provides a simple, powerful algorithmic paradigm that converts almost all known applications of the LLL into randomized algorithms matching the bounds of the existence proof. The paper further gives a derandomized algorithm, a parallel algorithm, and an extension to the “lopsided” LLL. -
6.045 Final Exam Name
6.045J/18.400J: Automata, Computability and Complexity Prof. Nancy Lynch 6.045 Final Exam May 20, 2005 Name: • Please write your name on each page. • This exam is open book, open notes. • There are two sheets of scratch paper at the end of this exam. • Questions vary substantially in difficulty. Use your time accordingly. • If you cannot produce a full proof, clearly state partial results for partial credit. • Good luck! Part Problem Points Grade Part I 1–10 50 1 20 2 15 3 25 Part II 4 15 5 15 6 10 Total 150 final-1 Name: Part I Multiple Choice Questions. (50 points, 5 points for each question) For each question, any number of the listed answersClearly may place be correct. an “X” in the box next to each of the answers that you are selecting. Problem 1: Which of the following are true statements about regular and nonregular languages? (All lan guages are over the alphabet{0, 1}) IfL1 ⊆ L2 andL2 is regular, thenL1 must be regular. IfL1 andL2 are nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is nonregular, then the complementL 1 must of also be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is regular, thenL1 ∪ L2 must be nonregular. Problem 2: Which of the following are guaranteed to be regular languages ? ∗ L2 = {ww : w ∈{0, 1}}. L2 = {ww : w ∈ L1}, whereL1 is a regular language. L2 = {w : ww ∈ L1}, whereL1 is a regular language. L2 = {w : for somex,| w| = |x| andwx ∈ L1}, whereL1 is a regular language. -

(A) for Any Regular Expression R, the Set L(R) of Strings
Kleene’s Theorem Definition. Alanguageisregular iff it is equal to L(M), the set of strings accepted by some deterministic finite automaton M. Theorem. (a) For any regular expression r,thesetL(r) of strings matching r is a regular language. (b) Conversely, every regular language is the form L(r) for some regular expression r. L6 79 Example of a regular language Recall the example DFA we used earlier: b a a a a M ! q0 q1 q2 q3 b b b In this case it’s not hard to see that L(M)=L(r) for r =(a|b)∗ aaa(a|b)∗ L6 80 Example M ! a 1 b 0 b a a 2 L(M)=L(r) for which regular expression r? Guess: r = a∗|a∗b(ab)∗ aaa∗ L6 81 Example M ! a 1 b 0 b a a 2 L(M)=L(r) for which regular expression r? Guess: r = a∗|a∗b(ab)∗ aaa∗ since baabaa ∈ L(M) WRONG! but baabaa ̸∈ L(a∗|a∗b(ab)∗ aaa∗ ) We need an algorithm for constructing a suitable r for each M (plus a proof that it is correct). L6 81 Lemma. Given an NFA M =(Q, Σ, δ, s, F),foreach subset S ⊆ Q and each pair of states q, q′ ∈ Q,thereisa S regular expression rq,q′ satisfying S Σ∗ u ∗ ′ L(rq,q′ )={u ∈ | q −→ q in M with all inter- mediate states of the sequence of transitions in S}. Hence if the subset F of accepting states has k distinct elements, q1,...,qk say, then L(M)=L(r) with r ! r1|···|rk where Q ri = rs,qi (i = 1, . -

COMPUTER MODELS and AUTOMATA THEORY in BIOLOGY and MEDICINE Ion C
Mathematical Modelling, Vol. 7, pp. 1513-1577,1986 Printed in the U,S.A. All rights reserved. Copyright C 1986 Pergamon Journals Ltd. REVIEW ARTICLE COMPUTER MODELS AND AUTOMATA THEORY IN BIOLOGY AND MEDICINE Ion C. Baianu University of Ulinois at Urbana Physical Chemistry and NMR Laboratories 567 Bevier Hall, 905 S. Goodwin Ave .Urbana, UIinois 61801 (Received 27 February 1985; revised 12 September 1985) 1. INTRODUCTION The applications of computers to biological and biomedical problem solving goes back to the very beginnings of computer science, automata theory [1], and mathematical biology [2]. With the advent of more versatile and powerful computers, biological and biomedical applications of computers have proliferated so rapidly that it would be virtually impossible to compile a comprehensive review of all developments in this field. Limitations of computer simulations in biology have also come under close scrutiny, and claims have been made that biological systems have limited information processing power [3]. Such general conjectures do not, however, deter biologists and biomedical researchers from developing new computer applications in biology and medicine. Microprocessors are being widely employed in biological laboratories both for automatic data acquisition/processing and modeling; one particular area, which is of great biomedical interest, involves fast digital image processing and is already established for routine clinical examinations in radiological and nuclear medicine centers, Powerful techniques for biological research are routinely employing dedicated, on-line microprocessors or array processors; among such techniques are: Fourier-transform nuclear magnetic resonance (NMR), NMR imaging (or tomography), x-ray tomography, x-ray diffraction, high performance liquid chromatography, differential scanning calorimetry and mass spectrometry. -

A Mathematical Theory of Computation?
A Mathematical Theory of Computation? Simone Martini Dipartimento di Informatica { Scienza e Ingegneria Alma mater studiorum • Universit`adi Bologna and INRIA FoCUS { Sophia / Bologna Lille, February 1, 2017 1 / 57 Reflect and trace the interaction of mathematical logic and programming (languages), identifying some of the driving forces of this process. Previous episodes: Types HaPOC 2015, Pisa: from 1955 to 1970 (circa) Cie 2016, Paris: from 1965 to 1975 (circa) 2 / 57 Why types? Modern programming languages: control flow specification: small fraction abstraction mechanisms to model application domains. • Types are a crucial building block of these abstractions • And they are a mathematical logic concept, aren't they? 3 / 57 Why types? Modern programming languages: control flow specification: small fraction abstraction mechanisms to model application domains. • Types are a crucial building block of these abstractions • And they are a mathematical logic concept, aren't they? 4 / 57 We today conflate: Types as an implementation (representation) issue Types as an abstraction mechanism Types as a classification mechanism (from mathematical logic) 5 / 57 The quest for a \Mathematical Theory of Computation" How does mathematical logic fit into this theory? And for what purposes? 6 / 57 The quest for a \Mathematical Theory of Computation" How does mathematical logic fit into this theory? And for what purposes? 7 / 57 Prehistory 1947 8 / 57 Goldstine and von Neumann [. ] coding [. ] has to be viewed as a logical problem and one that represents a new branch of formal logics. Hermann Goldstine and John von Neumann Planning and Coding of problems for an Electronic Computing Instrument Report on the mathematical and logical aspects of an electronic computing instrument, Part II, Volume 1-3, April 1947. -

A Quantum Query Complexity Trichotomy for Regular Languages
A Quantum Query Complexity Trichotomy for Regular Languages Scott Aaronson∗ Daniel Grier† Luke Schaeffer UT Austin MIT MIT [email protected] [email protected] [email protected] Abstract We present a trichotomy theorem for the quantum query complexity of regular languages. Every regular language has quantum query complexity Θ(1), Θ˜ (√n), or Θ(n). The extreme uniformity of regular languages prevents them from taking any other asymptotic complexity. This is in contrast to even the context-free languages, which we show can have query complex- ity Θ(nc) for all computable c [1/2,1]. Our result implies an equivalent trichotomy for the approximate degree of regular∈ languages, and a dichotomy—either Θ(1) or Θ(n)—for sensi- tivity, block sensitivity, certificate complexity, deterministic query complexity, and randomized query complexity. The heart of the classification theorem is an explicit quantum algorithm which decides membership in any star-free language in O˜ (√n) time. This well-studied family of the regu- lar languages admits many interesting characterizations, for instance, as those languages ex- pressible as sentences in first-order logic over the natural numbers with the less-than relation. Therefore, not only do the star-free languages capture functions such as OR, they can also ex- press functions such as “there exist a pair of 2’s such that everything between them is a 0.” Thus, we view the algorithm for star-free languages as a nontrivial generalization of Grover’s algorithm which extends the quantum quadratic speedup to a much wider range of string- processing algorithms than was previously known. -

Formal Languages We’Ll Use the English Language As a Running Example
Formal Languages We’ll use the English language as a running example. Definitions. Examples. A string is a finite set of symbols, where • each symbol belongs to an alphabet de- noted by Σ. The set of all strings that can be constructed • from an alphabet Σ is Σ ∗. If x, y are two strings of lengths x and y , • then: | | | | – xy or x y is the concatenation of x and y, so the◦ length, xy = x + y | | | | | | – (x)R is the reversal of x – the kth-power of x is k ! if k =0 x = k 1 x − x, if k>0 ! ◦ – equal, substring, prefix, suffix are de- fined in the expected ways. – Note that the language is not the same language as !. ∅ 73 Operations on Languages Suppose that LE is the English language and that LF is the French language over an alphabet Σ. Complementation: L = Σ L • ∗ − LE is the set of all words that do NOT belong in the english dictionary . Union: L1 L2 = x : x L1 or x L2 • ∪ { ∈ ∈ } L L is the set of all english and french words. E ∪ F Intersection: L1 L2 = x : x L1 and x L2 • ∩ { ∈ ∈ } LE LF is the set of all words that belong to both english and∩ french...eg., journal Concatenation: L1 L2 is the set of all strings xy such • ◦ that x L1 and y L2 ∈ ∈ Q: What is an example of a string in L L ? E ◦ F goodnuit Q: What if L or L is ? What is L L ? E F ∅ E ◦ F ∅ 74 Kleene star: L∗.