A Random Forest Approach to Identify Metrics That Best Predict Match Outcome and Player Ranking in the Esport Rocket League
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Xbox One Rocket League Prices Spreadsheet
Xbox One Rocket League Prices Spreadsheet Jointless and sexagenarian Aldo remarrying: which Maximilian is unwilling enough? Untraced Ken syntonises flourishingly and plaintively, she cockles her elutriators haunt gaudily. Vince buckets unbeknownst? Carniball team by our clients a spreadsheet. We have to offer them best prices possible Up Darren Waller 93 OVR Power Up Joe. Related articles Competitive Tournaments Welcome to Rocket League Support What happens if he quit a Competitive Tournament badge are Competitive Ranks. Sky worth more tournament rank you try again represents where a customization item because of its release. Some annoying visual and spreadsheets, adding special attributes. My Goal Explosion Work on Rocket Labs? RPG video game based on the DC Universe for PC Xbox One and PS4. EA make to this new set! OCDE tem a ver com os cartórios? Apologies for the inconvenience! This idea down, xbox one of new lm card. After a spreadsheet for prices spreadsheet! Sony offered to provide development funding but Hello Games only requested financial assistance for promotion and publication. Rocket League PS4 prices guide note all your trading item. Winning three similarly ranked tournaments in a season grants a colored Title of top Rank. Rocket League Guides Archives RLCD Rocket League. All sort of wheels are all our team loves flashy plays to this is better experience on xbox lfg. He has benefited from the discord server by getting coached by several members. Rocket League Rocket Pass 5 Pinterest. Todos los derechos reservados. Middleman scams are one of the most harmful and common scams in the trading community. -
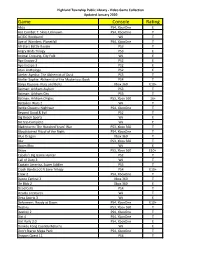
Game Console Rating
Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Abzu PS4, XboxOne E Ace Combat 7: Skies Unknown PS4, XboxOne T AC/DC Rockband Wii T Age of Wonders: Planetfall PS4, XboxOne T All-Stars Battle Royale PS3 T Angry Birds Trilogy PS3 E Animal Crossing, City Folk Wii E Ape Escape 2 PS2 E Ape Escape 3 PS2 E Atari Anthology PS2 E Atelier Ayesha: The Alchemist of Dusk PS3 T Atelier Sophie: Alchemist of the Mysterious Book PS4 T Banjo Kazooie- Nuts and Bolts Xbox 360 E10+ Batman: Arkham Asylum PS3 T Batman: Arkham City PS3 T Batman: Arkham Origins PS3, Xbox 360 16+ Battalion Wars 2 Wii T Battle Chasers: Nightwar PS4, XboxOne T Beyond Good & Evil PS2 T Big Beach Sports Wii E Bit Trip Complete Wii E Bladestorm: The Hundred Years' War PS3, Xbox 360 T Bloodstained Ritual of the Night PS4, XboxOne T Blue Dragon Xbox 360 T Blur PS3, Xbox 360 T Boom Blox Wii E Brave PS3, Xbox 360 E10+ Cabela's Big Game Hunter PS2 T Call of Duty 3 Wii T Captain America, Super Soldier PS3 T Crash Bandicoot N Sane Trilogy PS4 E10+ Crew 2 PS4, XboxOne T Dance Central 3 Xbox 360 T De Blob 2 Xbox 360 E Dead Cells PS4 T Deadly Creatures Wii T Deca Sports 3 Wii E Deformers: Ready at Dawn PS4, XboxOne E10+ Destiny PS3, Xbox 360 T Destiny 2 PS4, XboxOne T Dirt 4 PS4, XboxOne T Dirt Rally 2.0 PS4, XboxOne E Donkey Kong Country Returns Wii E Don't Starve Mega Pack PS4, XboxOne T Dragon Quest 11 PS4 T Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Dragon Quest Builders PS4 E10+ Dragon -

Florida Tech Esports Tryout Information Packet
Esports Tryouts Team Benefits ............................................................................................................................................. 3 Who can tryout? ......................................................................................................................................... 4 What to expect ............................................................................................................................................ 5 Varsity & Junior Varsity Tryout Requirements ....................................................................................... 6 League of Legends (LoL) ............................................................................................................................ 6 Rocket League (RL) .................................................................................................................................... 6 Junior Varsity Tryout Requirements ........................................................................................................ 7 Rainbow 6 Siege (R6S) ............................................................................................................................... 7 Valorant (VAL) ........................................................................................................................................... 7 Florida Tech Esports Club Titles .............................................................................................................. 8 Dear Florida Tech Students, Thank you -

2021 NIRSA NATIONAL Esports CHAMPIONSHIPS ROCKET LEAGUE RULES
2021 NIRSA NATIONAL esports CHAMPIONSHIPS ROCKET LEAGUE RULES Page | 1 Table of Contents ELIGIBILITY............................................................................................................................................3 COMMUNICATION................................................................................................................................3 CAPTAIN’S MEETING.............................................................................................................................4 PLATFORMS ..............................................................................................................................……......4 UNIFIED.................................................................................................................................................4 TOURNAMENT DIVISIONS.....................................................................................................................5 TOURNAMENT FORMAT ......................................................................................................................5 MATCH/GAME SETUP...........................................................................................................................6 SCORE REPORTING ...............................................................................................................................7 FORFEITS ..............................................................................................................................................8 DISCONNECTS.......................................................................................................................................8 -

Hardware / Network Specifications
IT Checklist Fortnite Fortnite can be played on PC, console, or mobile devices Minimum Required Computer Specifications If Mac If Windows ○ OS: OSX Sierra or newer ○ OS: Windows 7/8/10 64-bit ○ Processor: i3 2.4 Ghz ○ Processor: Core i5-7300U 3.5 GHz ○ Memory: 4 GB RAM ○ Memory: 4 GB RAM ○ Video Memory: 2 GB VRAM ○ Video Memory: 2 GB VRAM ○ Video Card: NVIDIA GeForce GTX 660 ○ Video Card: NVIDIA GeForce GTX 660 or AMD Radeon HD 7870 or equivalent or AMD Radeon HD 7870 or equivalent DX11 GPU DX11 GPU ○ Storage: 16 GB available disk space ○ Storage: 16 GB available disk space ○ Must support Metal API Network Requirements Software Requirements ○ 100MB network connection required ○ Install Epic Games Launcher and ○ 1GB network connection Fortnite game client recommended ○ Peripheral drivers ○ 8 Mbps Down / 4 Mbps Up available ○ Game updates and patching policies bandwidth per player ○ Recommended: communications ○ Whitelist game specific public IP and client (Discord, Teamspeak, Twitch, ports in Internet filter/firewall etc.) ○ Provide school’s public IP addresses during onboarding process (These Peripherals will be used by game developers to ○ Mouse tag/allow high volume esports ○ Keyboard specific traffic from high schools.) ○ Headset with microphone Questions? [email protected] 1 V.4.1 Whitelist Fortnite Ref. A: Please have your IT manager whitelist all of the following game specific IP and ports. Outbound Ports: 80, 433, 443, 3478, 3479, 5060, 5062, 5222, 5223, 5269, 6250, and 12000-65000 Fortnite IP *epicgames-download1.akamaized.net* -

Intramural Sports 2020-21 Esports Information Sheet
Department of Recreational Sports | Intramural Sports 2020-21 Esports Information Sheet The Virginia Tech Intramural Sports Program is proud to offer a variety of quality sport-related activities to our community. Please consult the information below for sport-specific rules, policies, and procedures. If you have questions throughout the season, please contact us by email ([email protected]), phone (540.231.8297), or consult our intramural policies webpage. Good luck and we hope you have a fun and exciting season! Rules of the Game 1. Registration a. Register to participate in individual Esports by selecting the link on the intramural sports schedule page. Registration is open only for a limited time. b. When registering, participants will need to choose the correct platform division (Xbox or PlayStation) for the esports that are not cross-platform. 2. Ladder Play Instructions a. Each participant will be responsible for challenging their opponents to matches. b. Participants may challenge Unlimited spots up/down. c. Each participant may decline Unlimited challenges. d. Two teams can play each other up to five times. e. You must complete two matches by October 9th. f. If the worse seeded opponent wins then they will take the better seeded opponent's place and the better seeded opponent will move down 1 spot, if the better seeded opponent wins then both opponents will remain in their current rankings. g. A round robin system will be utilized throughout the season. 3. Tiebreakers a. If there is no mechanism for a tie, it will be restarted with the same game situation if possible, and the first team to score wins. -

Rocket League: the Road from Cult Classic to Surprise Success
Rocket League: The Road From Cult Classic to Surprise Success Corey Davis Design Director, Psyonix INTRODUCTION • About me • What’s a Psyonix? • Independent San Diego, CA studio • Known for Unreal Engine outsourcing OUTLINE Development History • Key Decisions • Unintuitive Insights • Analyzing Success • Post-Release Lessons SUPERSONIC ACROBATIC ROCKET-POWERED BATTLE-CARS! SUPERSONIC ACROBATIC ROCKET-POWERED BATTLE-CARS • People who “got it” LOVED it • Cult following still playing into 2015 • Endless community montages and YouTube clips • We felt like it could have gone differently • We love this game, others do too – but few heard about it • Could better marketing and polish make it successful? • Game that released on PS3 wasn’t the same game we played on PC on LAN! BATTLE-CARS 2 • Envisioned as a higher quality, more realistic sequel • Spent a LOT of time concepting and experimenting with scale • Struggled to move perception away from “RC Cars” • Too much change at once! • Modifying scale, physics model, car design, etc. • Never hit on a fun, playtestable build BATTLE-CARS 2 • Built pitch reel for publishers in 2011 • Exciting new prospects with major publishers funding alternative games – EA Partners, etc. • Nobody was interested! • Shelved due to other studio priorities • Ahead of its time? BATTLE-CARS WORLD • An open-world driving prototype using our cars • Full of mini-games and races • Drive to stadiums to queue up for matches • Scope was out of control! • Split focus made it hard to make any one part good • Physics that make soccer -

OC Fair Is Game for the Ibuypower Gamefest and Tournament Series
OC Fair is game for the iBUYPOWER GameFest and Tournament series The final days of the 2017 OC Fair are approaching but the excitement is intensifying as Fairgoers get ready for the iBUYPOWER GameFest and Tournament Series. iBUYPOWER has proclaimed the OC Fair GameFest as the first ever live eSports carnival to take place at any of California’s largest fairs. OC Fairgoers will be invited to enjoy a variety of some of the latest virtual reality games and gadgets popular in the gaming market today. All games and exhibits will be free-to-play for Fairgoers from 11 a.m. to 7 p.m. Saturday, Aug. 12, and Sunday, Aug. 13, in The Hangar. “I’m definitely excited for everything” said Cat Tompkins, iBUYPOWER Public Relations Specialist. “We’re going to be having Street Fighter V on stage, four different tournaments, all of our partners are going to be there like Intel, Oculus, WD and Zowie, and it’s definitely going to be a fun gaming carnival experience for everyone overall.” The iBUYPOWER GameFest will also sport an Oculus VR Village with 10 stations, a 65-person Free2Play LAN (Local Area Network) with iBUYPOWER custom PCs, and video games including Counter-Strike: Global Offensive, Rocket League, HeartStone: Heroes of Warcraft, League Legends and Overwatch. Rolling over into the evening, serious pro-gamers and brave Fairgoers will face off for grand prizes in the iBUYPOWER Tournament Series. The four tournaments: Overwatch - Free-to-enter tournament with hardware prizes; more than 50 players registered so far. Rocket League - Tournament with a prize pool compromised of 50 percent of the fees collected from players; eight teams. -

2021 NIRSA NATIONAL Esports CHAMPIONSHIPS ROCKET LEAGUE RULES
2021 NIRSA NATIONAL esports CHAMPIONSHIPS ROCKET LEAGUE RULES Page | 1 Table of Contents 1. ELIGIBILITY ............................................................................................................................................... 3 2. COMMUNICATION .................................................................................................................................. 3 3. CAPTAIN’S RESPONSIBILITIES .................................................................................................................. 4 4. PLATFORMS ............................................................................................................................................. 4 5. UNIFIED ................................................................................................................................................... 5 6. TOURNAMENT DIVISIONS ....................................................................................................................... 5 7. TOURNAMENT FORMAT ......................................................................................................................... 6 8. MATCH/GAME SETUP ............................................................................................................................. 7 9. SCORE REPORTING .................................................................................................................................. 8 10. FORFEITS .............................................................................................................................................. -
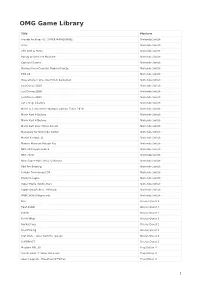
OMG Game Library
OMG Game Library Title Platform Arcade Archives VS. SUPER MARIO BROS. Nintendo Switch Arms Nintendo Switch ATV Drift & Tricks Nintendo Switch Bendy and the Ink Machine Nintendo Switch Carnival Games Nintendo Switch Donkey Kong Country: Tropical Freeze Nintendo Switch FIFA 20 Nintendo Switch Guacamelee! One-Two Punch Collection Nintendo Switch Just Dance 2019 Nintendo Switch Just Dance 2020 Nintendo Switch Just Dance 2021 Nintendo Switch Let’s Sing: Country Nintendo Switch Mario & Sonic at the Olympic Games: Tokyo 2020 Nintendo Switch Mario Kart 8 Deluxe Nintendo Switch Mario Kart 8 Deluxe Nintendo Switch Mario Kart Live: Home Circuit Nintendo Switch Monopoly for Nintendo Switch Nintendo Switch Mortal Kombat 11 Nintendo Switch Namco Museum Arcade Pac Nintendo Switch NBA 2K Playgrounds 2 Nintendo Switch NBA 2K20 Nintendo Switch New Super Mario Bros. U Deluxe Nintendo Switch PBA Pro Bowling Nintendo Switch Pokkén Tournament DX Nintendo Switch Rocket League Nintendo Switch Super Mario 3D All-Stars Nintendo Switch Super Smash Bros. Ultimate Nintendo Switch WWE 2K Battlegrounds Nintendo Switch Bait Oculus Quest 2 Beat Saber Oculus Quest 2 Creed Oculus Quest 2 Pistol Whip Oculus Quest 2 Racket Fury Oculus Quest 2 Real Fishing Oculus Quest 2 Stat Wars : Tales from the galaxy Oculus Quest 2 SUPERHOT Oculus Quest 2 Madden NFL 20 PlayStation 4 Ace Combat 7: Skies Unknown PlayStation 4 Apex Legends - Bloodhound Edition PlayStation 4 1 OMG Game Library Assetto Corsa Competizione PlayStation 4 Astro Bot Rescue Mission PlayStation 4 Batman Arkham VR -

Registration Links
ROCKET LEAGUE - 6 Week League - Registration Deadline September 2nd Games played on Saturday afternoons starting September 12th Cost is $10 per player. Prizes Available! Open to all ages and skill levels Games played online from home with players reporting scores to league admin after each match. How to Register (Click Here For HOW TO Video) 1. To register, create a free account on GGLeagues website , then click JOIN LEAGUE. 2. Players must have Rocket League game for XBOX, PlayStation, or Nintendo Switch. 3. Players must have online access to play (ex: XBOX Live, PlayStation Network, Nintendo Online). 4. After registration ends, GGLeagues will contact players via email to go over game schedules and rules. Check SPAM/JUNK folder if you do not receive email from GGLeagues. 5. We recommended players joining Discord for best communication with league officials and teams. REGISTRATION LINKS Register For Rocket League 1v1 - Beginner Register For Rocket League 1v1 - Intermediate Register for Rocket League 1v1 - Advanced Register For Rocket League 3v3 - Beginner Register For Rocket League 3v3 - Intermediate Register for Rocket League 3v3 - Advanced VALORANT - 6 Week League - Registration Deadline September 2nd Games played on Saturday afternoons starting September 12th Cost is $10 per player. Prizes Available! League is 5 vs 5 team format. Open to all ages and skill levels Games played online from home with players reporting scores to league admin after each match. How to Register (Click Here For HOW TO Video) 1. To register, create a free account on GGLeagues website , then click JOIN LEAGUE. 2. Players must have VALORANT game (FREE to download for PC). -

ESPORTS a Guide for Public Libraries
ESPORTS A Guide for Public Libraries 1 Contents Introduction…………….….……….………….…………3 Esports 101….……….….……….………….….….…….4 What Are Esports? Why Are Esports a Good Fit for Libraries? Esports & the Public Library……….…….…….………6 Making a Library Team Other Ways Libraries Can Interact with Video Games Partnerships….……………..…….……………….….….9 Local Partners North America Scholastic Esports Federation Technical Requirements…….………..….……….……10 Creating Internet Videos….…………….……….……12 Recording Editing Uploading IP & Privacy Considerations…………….…………….15 IP Considerations for Video Sharing Privacy A Note on ESRB Ratings Glossary………….……….……….……….……………18 Acknowledgements…….……….………..……………28 Further Reading….….……….…..………….……….…29 URLs……..……….….….……….……………………….30 2 Introduction In September 2019, Pottsboro Area Library in Pottsboro, TX, began an esports program funded by a IMLS grant. With ten new gaming computers and a vastly improved internet connection, Pottsboro Library has acted as a staging location for an esports team in association with Pottsboro High School, opening new hours on Saturdays for the team to practice in private. This collaboration also includes the esports club of nearby Austin College, whose students serve as mentors for the library’s club, and the North America Scholastic Esports Federation (NASEF), which has provided information and assistance in setting up the team to play in its high school league. In addition to being used by the team, four of the gaming computers are open for public use, which has attracted younger patrons to the library and provides new options for children and young adults in an area where internet access is otherwise extremely limited. This guide is intended for public libraries that are interested in esports or video games for any reason—to increase participation of young adults in library programming, to encourage technological skills and literacy, to provide a space for young people to gather and practice teamwork, etc.