Multliligual Self-Voicing Browser Model for Ethiopc Scripts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
World Wide Web: Introduzione E Componenti
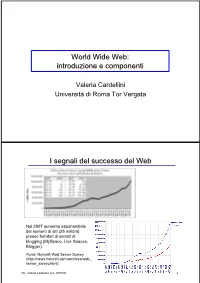
World Wide Web: introduzione e componenti Valeria Cardellini Università di Roma Tor Vergata I segnali del successo del Web Nel 2007 aumento esponenziale del numero di siti (25 milioni) presso fornitori di servizi di blogging (MySpace, Live Spaces, Blogger) Fonte: Netcraft Web Server Survey (http://news.netcraft.com/archives/web_ server_survey.html) IW - Valeria Cardellini, A.A. 2007/08 2 I segnali del successo del Web (2) • Fino all’introduzione dei sistemi P2P, il Web è stata l’applicazione killer di Internet (75% del traffico di Internet nel 1998) Event Period Peak day Peak minute NCSA server (Oct. 1995) - 2 Million - Olympic Summer Games 192 Million 8 Million - (Aug. 1996) (17 days) Nasa Pathfinder 942 Million 40 Million - (July 1997) (14 days) Olympic Winter Games 634.7 Million 55 Million 110,000 (Feb. 1998) (16 days) Wimbledon (July 1998) - - 145,000 FIFA World Cup 1,350 Million 73 Million 209,000 (July 1998) (84 days) Wimbledon (July 1999) - 125 Million 430,000 Wimbledon (July 2000) - 282 Million 964,000 Olympic Summer Games - 875 Million 1,200,000 (Sept. 2000) [Carico misurato in contatti] • Inoltre: google.com, msn.com, yahoo.com (> 200 milioni di contatti al giorno) IW - Valeria Cardellini, A.A. 2007/08 3 I motivi alla base del successo del Web • Digitalizzazione dell’informazione – Qualsiasi informazione rappresentabile in binario come sequenza di 0 e 1 • Diffusione di Internet (dagli anni 1970) – Trasporto dell’informazione ovunque, in tempi rapidissimi e a costi bassissimi • Diffusione dei PC (dagli anni 1980) – Accesso, memorizzazione ed elaborazione dell’informazione da parte di chiunque a costi bassissimi • Semplicità di utilizzo e trasparenza dell’allocazione delle risorse – Semplicità di utilizzo mediante l’uso di interfacce grafiche IW - Valeria Cardellini, A.A. -

MHCC Accessibility Conformance Report
Mt. Hood Community College Website Accessibility Conformance Report WCAG Edition VPAT® Version 2.3 (Revised) – April 2019 Name of Product/Version: www.mhcc.edu Product Description: MHCC Main Website Report Date: August 2, 2019 Contact Information: Tristan Price – [email protected] Notes: Evaluation Methods Used: IAAP WAS Testing Methodology, SiteImprove, Manual Testing __________________________________ “Voluntary Product Accessibility Template” and “VPAT” are registered service marks of the Information Technology Industry Council (ITI) Page 1 of 5 Applicable Standards/Guidelines This report covers the degree of conformance for the following accessibility standard/guidelines: Standard/Guideline Included In Report Web Content Accessibility Guidelines 2.0 Level A (Yes / No ) Level AA (Yes / No ) Level AAA (Yes / No ) Web Content Accessibility Guidelines 2.1 Level A (Yes / No ) Level AA (Yes / No ) Level AAA (Yes / No ) Terms The terms used in the Conformance Level information are defined as follows: • Supports: The functionality of the product has at least one method that meets the criterion without known defects or meets with equivalent facilitation. • Partially Supports: Some functionality of the product does not meet the criterion. • Does Not Support: The majority of product functionality does not meet the criterion. • Not Applicable: The criterion is not relevant to the product. • Not Evaluated: The product has not been evaluated against the criterion. This can be used only in WCAG 2.0 Level AAA. WCAG 2.x Report Note: When reporting on conformance with the WCAG 2.x Success Criteria, they are scoped for full pages, complete processes, and accessibility-supported ways of using technology as documented in the WCAG 2.0 Conformance Requirements. -

HTTP Cookie - Wikipedia, the Free Encyclopedia 14/05/2014
HTTP cookie - Wikipedia, the free encyclopedia 14/05/2014 Create account Log in Article Talk Read Edit View history Search HTTP cookie From Wikipedia, the free encyclopedia Navigation A cookie, also known as an HTTP cookie, web cookie, or browser HTTP Main page cookie, is a small piece of data sent from a website and stored in a Persistence · Compression · HTTPS · Contents user's web browser while the user is browsing that website. Every time Request methods Featured content the user loads the website, the browser sends the cookie back to the OPTIONS · GET · HEAD · POST · PUT · Current events server to notify the website of the user's previous activity.[1] Cookies DELETE · TRACE · CONNECT · PATCH · Random article Donate to Wikipedia were designed to be a reliable mechanism for websites to remember Header fields Wikimedia Shop stateful information (such as items in a shopping cart) or to record the Cookie · ETag · Location · HTTP referer · DNT user's browsing activity (including clicking particular buttons, logging in, · X-Forwarded-For · Interaction or recording which pages were visited by the user as far back as months Status codes or years ago). 301 Moved Permanently · 302 Found · Help 303 See Other · 403 Forbidden · About Wikipedia Although cookies cannot carry viruses, and cannot install malware on 404 Not Found · [2] Community portal the host computer, tracking cookies and especially third-party v · t · e · Recent changes tracking cookies are commonly used as ways to compile long-term Contact page records of individuals' browsing histories—a potential privacy concern that prompted European[3] and U.S. -

Rečové Interaktívne Komunikačné Systémy
Rečové interaktívne komunikačné systémy Matúš Pleva, Stanislav Ondáš, Jozef Juhár, Ján Staš, Daniel Hládek, Martin Lojka, Peter Viszlay Ing. Matúš Pleva, PhD. Katedra elektroniky a multimediálnych telekomunikácií Fakulta elektrotechniky a informatiky Technická univerzita v Košiciach Letná 9, 04200 Košice [email protected] Táto učebnica vznikla s podporou Ministerstvo školstva, vedy, výskumu a športu SR v rámci projektu KEGA 055TUKE-04/2016. c Košice 2017 Názov: Rečové interaktívne komunikačné systémy Autori: Ing. Matúš Pleva, PhD., Ing. Stanislav Ondáš, PhD., prof. Ing. Jozef Juhár, CSc., Ing. Ján Staš, PhD., Ing. Daniel Hládek, PhD., Ing. Martin Lojka, PhD., Ing. Peter Viszlay, PhD. Vydal: Technická univerzita v Košiciach Vydanie: prvé Všetky práva vyhradené. Rukopis neprešiel jazykovou úpravou. ISBN 978-80-553-2661-0 Obsah Zoznam obrázkov ix Zoznam tabuliek xii 1 Úvod 14 1.1 Rečové dialógové systémy . 16 1.2 Multimodálne interaktívne systémy . 19 1.3 Aplikácie rečových interaktívnych komunikačných systémov . 19 2 Multimodalita a mobilita v interaktívnych systémoch s rečo- vým rozhraním 27 2.1 Multimodalita . 27 2.2 Mobilita . 30 2.3 Rečový dialógový systém pre mobilné zariadenia s podporou multimodality . 31 2.3.1 Univerzálne riešenia pre mobilné terminály . 32 2.3.2 Projekt MOBILTEL . 35 3 Parametrizácia rečových a audio signálov 40 3.1 Predspracovanie . 40 3.1.1 Preemfáza . 40 3.1.2 Segmentácia . 41 3.1.3 Váhovanie oknovou funkciou . 41 3.2 Spracovanie rečového signálu v spektrálnej oblasti . 41 3.2.1 Lineárna predikčná analýza . 43 3.2.2 Percepčná Lineárna Predikčná analýza . 43 3.2.3 RASTA metóda . 43 3.2.4 MVDR analýza . -

Tecnologias Da Informação E Comunicação Vs Exclusão Social
Instituto Superior de Engenharia do Porto Departamento de Engenharia Informática Ramo de Computadores e Sistemas Projecto 5º Ano Tecnologias da Informação e Comunicação vs Exclusão Social Autor/Número Sérgio Francisco dos Santos Morais / 990348 Orientador Dr. Constantino Martins Porto, Setembro de 2004 Agradecimentos “Não há no mundo exagero mais belo que a gratidão” La Bruyère (escritor francês 1645-1695) Aproveito este espaço para agradecer a todas as pessoas que directamente ou indirectamente contribuíram e me ajudaram na elaboração deste projecto, pelo seu apoio e incentivo, com um agradecimento especial: ü Ao meu orientador Dr. Constantino Martins, pelo interesse, ajuda e apoio que me prestou. Pela disponibilidade que teve para esclarecimento de dúvidas que foram surgindo e para a revisão das diversas versões do projecto; ü Ao Eng.º Paulo Ferreira pela ajuda que me deu na parte final do projecto; ü Ao Eng.º Carlos Vaz de Carvalho pela autorização concedida para a entrega dos inquéritos aos alunos. Pela revisão do inquérito e pelas suas sugestões; ü À Eng.ª Bertil Marques e ao Eng.º António Costa pela entrega e recolha dos inquéritos aos seus alunos; ü Aos alunos que preencheram os inquéritos; ü À minha família e amigos pela motivação e incentivo que me deram e pela paciência que tiveram para suportar dias e noites sem a minha atenção. A todos o meu muito obrigado. I Resumo Vivemos numa sociedade cada vez mais tecnológica, em que as Tecnologias de Informação e Comunicação (TIC) tem um papel importante e decisivo. As TIC fazem parte integrante do nosso quotidiano ao ponto de ser quase impossível viver sem elas. -

50 Are Gnome and KDE Equal? KNOW-HOW 50
KNOW-HOW Ask Klaus! ASK KLAUS! and even with its very reduced features, linking of KDE or Gnome programs is it has always been sufficient for me. more likely fail because of this modular There were quarrels between develop- structure than for any other reason.) ers and users about KDE being “non- This can get you into some problems. Klaus Knopper is the creator of free” in the old days, because of the qt li- If you use KDE regularly, and you want Knoppix and co-founder of the cense (for the library KDE is based on); to install a single Gnome program such that it was more memory-consuming as Gnopernicus, you end up installing LinuxTag expo. He currently than Gnome; or that its graphics were the entire Gnome software suite because poorer. None of these are genuine prob- you won’t be able to to get the program works as a teacher, program- lems today, and I don’t know if the ru- to run otherwise. In very bad cases, mer, and consultant. If you have mors about graphics and memory con- Gnome dependencies try to deinstall sumption ever were true, or whether parts of KDE (or vice versa) because of a configuration problem, or if they were just part of the creative com- conflicting services that are present in petition between different groups and both (a very rare case, though). you just want to learn more philosophies. OK, I cheated a little in this example. about how Linux works, send Nowadays, Gnome consumes the Gnopernicus is more like a suite of pl- same amount of system resources as ugins and addons for Gnome than like a your questions to: KDE (if not more), performance bench- standalone application. -

A Framework for Intelligent Voice-Enabled E-Education Systems
A FRAMEWORK FOR INTELLIGENT VOICE-ENABLED E-EDUCATION SYSTEMS BY AZETA, Agbon Ambrose (CUGP050134) A THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER AND INFORMATION SCIENCES, SCHOOL OF NATURAL AND APPLIED SCIENCES, COLLEGE OF SCIENCE AND TECHNOLOGY, COVENANT UNIVERSITY, OTA, OGUN STATE NIGERIA, IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE AWARD OF DOCTOR OF PHILOSOPHY IN COMPUTER SCIENCE MARCH, 2012 CERTIFICATION This is to certify that this thesis is an original research work undertaken by Ambrose Agbon Azeta with matriculation number CUGP050134 under our supervision and approved by: Professor Charles Korede Ayo --------------------------- Supervisor Signature and Date Dr. Aderemi Aaron Anthony Atayero --------------------------- Co- Supervisor Signature and Date Professor Charles Korede Ayo --------------------------- Head of Department Signature and Date --------------------------- External Examiner Signature and Date ii DECLARATION It is hereby declared that this research was undertaken by Ambrose Agbon Azeta. The thesis is based on his original study in the department of Computer and Information Sciences, College of Science and Technology, Covenant University, Ota, under the supervision of Prof. C. K. Ayo and Dr. A. A. Atayero. Ideas and views of this research work are products of the original research undertaken by Ambrose Agbon Azeta and the views of other researchers have been duly expressed and acknowledged. Professor Charles Korede Ayo --------------------------- Supervisor Signature and Date Dr. Aderemi Aaron Anthony Atayero --------------------------- Co- Supervisor Signature and Date iii ACKNOWLEDGMENTS I wish to express my thanks to God almighty, the author of life and provider of wisdom, understanding and knowledge for seeing me through my Doctoral research program. My high appreciation goes to the Chancellor, Dr. David Oyedepo and members of the Board of Regent of Covenant University for catching the vision and mission of Covenant University. -

Learning Technology Supplement Support
Welcome to this special issue of the Learning Technol- ogy supplement. This issue highlights new legislation Learning coming into force in September which has major impli- cations for any staff who publish information on the Web. Staff from many departments and teams have contributed to this issue and thanks are extended to all Technology of them for their contributions, comments, advice and BITs Learning Technology Supplement support. Number Eight: June 2002 8 Why do you want a website anyway? New legislation (see page 2) has major implications for any staff involved in producing Web pages. All staff involved in Web publishing should review their pages in the light of this legislation. Information seminars (see back page) are to be held on 12th June. Although this supplement focuses on making your website as accessible as possible, there is no point having a fully accessible, attractive website if it has no real purpose and if your students or target users don’t ever visit it. Before you go to the bother and effort of building a website, stop for a moment and ask yourself a couple of questions: “Who is this website for?” and “What is the user supposed to gain from using this site?” Websites can have many purposes, from attracting potential students to your course to publicising your excellent research activities. They can be used to provide up-to-date information or to act as a resource base or to give the students a self study centre, or… Whatever your reason, it has to be clear and appropriate for your users. -

Speechtek 2008 Final Program
FINAL PROGRAM AUGUST 18–20, 2008 NEW YORK MARRIOTT MARQUIS NEW YORK CITY SPEECH IN THE MAINSTREAM WWW. SPEECHTEK. COM KEYNOTE SPEAKERS w Analytics w Mobile Devices Ray Kurzweil author of The Age of Spiritual Machines and w Natural Language w Multimodal The Age of Intelligent Machines w Security w Video and Speech w Voice User Interfaces w Testing and Tuning Lior Arussy President, Strativity Group author of Excellence Every Day Gold Sponsors: Kevin Mitnick author, world-famous (former) hacker, & Silver Sponsor: Media Sponsors: security consultant Organized and produced by Welcome to SpeechTEK 2008 Speech in the Mainstream Last year we recognized that the speech industry was at a tipping Conference Chairs point, or the point at which change becomes unstoppable. To James A. Larson illustrate this point, we featured Malcolm Gladwell, author of the VP, Larson Technical Services best-selling book, The Tipping Point, as our keynote speaker. Not surprisingly, a lot has happened since the industry tipped: We’re Susan L. Hura seeing speech technology in economy-class cars and advertised on television to millions of households, popular video games with VP, Product Support Solutions more robust voice commands, and retail shelves stocked with affordable, speech-enabled aftermarket navigation systems. It’s Director, SpeechTEK clear that speech is in the mainstream—the focus of this year’s Program Planning conference. David Myron, Editorial Director, Speech technology has become mainstream for organizations CRM and Speech Technology magazines seeking operational efficiencies through self-service. For enterprises, speech enables employees to reset passwords, sign up for benefits, and find information on company policies and procedures. -

New Gnome 2.16 Desktop? NEW GNOME
REVIEWS Gnome 2.16 What’s new in the new Gnome 2.16 desktop? NEW GNOME The changes in Gnome 2.16 are more than cosmetic: the current release sees a leaner and faster version of the desktop. BY CHRISTIAN MEYER ust six months ago, when Gtk#. The libraries makes it easier for Although Metacity, the original Gnome Gnome 2.14 reached the mirror developers who prefer not to use C to window manager, does not support all Jservers, the Gnome developers enter the world of Gnome. Gnome bind- the effects I just referred to, it will still proved they can set milestones without ings are available for C++, C#, and perform well with the new 3D X servers. sacrificing usability. Programs such as Python. The features are not enabled by default, the Deskbar applet demonstrate the but enabling them will give you a first power of Gnome’s underpinnings, pro- 3D Desktop impression of the capabilities you can viding an attractive GUI that is both effi- In last couple of years, much time and expect with the new X server extensions. cient and remarkably uncluttered. money has gone into investigating new You don’t even need to terminate the The latest 2.16 version adds a variety GUI concepts. One of the results is the current session (that is, log off and back of new features, and there have been Looking Glass project [1] by Sun Micro- on) to disable the effects. major improvements with respect to per- systems, which gives users the ability to formance and memory consumption. -

Voice Synthesizer Application Android
Voice synthesizer application android Continue The Download Now link sends you to the Windows Store, where you can continue the download process. You need to have an active Microsoft account to download the app. This download may not be available in some countries. Results 1 - 10 of 603 Prev 1 2 3 4 5 Next See also: Speech Synthesis Receming Device is an artificial production of human speech. The computer system used for this purpose is called a speech computer or speech synthesizer, and can be implemented in software or hardware. The text-to-speech system (TTS) converts the usual text of language into speech; other systems display symbolic linguistic representations, such as phonetic transcriptions in speech. Synthesized speech can be created by concatenating fragments of recorded speech that are stored in the database. Systems vary in size of stored speech blocks; The system that stores phones or diphones provides the greatest range of outputs, but may not have clarity. For specific domain use, storing whole words or suggestions allows for high-quality output. In addition, the synthesizer may include a vocal tract model and other characteristics of the human voice to create a fully synthetic voice output. The quality of the speech synthesizer is judged by its similarity to the human voice and its ability to be understood clearly. The clear text to speech program allows people with visual impairments or reading disabilities to listen to written words on their home computer. Many computer operating systems have included speech synthesizers since the early 1990s. A review of the typical TTS Automatic Announcement System synthetic voice announces the arriving train to Sweden. -

Speech Recognition and Synthesis
Automatic Text-To-Speech synthesis Speech recognition and synthesis 1 Automatic Text-To-Speech synthesis Introduction Computer Speech Text preprocessing Grapheme to Phoneme conversion Morphological decomposition Lexical stress and sentence accent Duration Intonation Acoustic realization, PSOLA, MBROLA Controlling TTS systems Assignment Bibliography Copyright c 2007-2008 R.J.J.H. van Son, GNU General Public License [FSF(1991)] van Son & Weenink (IFA, ACLC) Speech recognition and synthesis Fall 2008 4 / 4 Automatic Text-To-Speech synthesis Introduction Introduction Uses of speech synthesis by computer Read aloud existing text, eg, news, email and stories Communicate volatile data as speech, eg, weather reports, query results The computer part of interactive dialogs The building block is a Text-to-Speech system that can handle standard text with a Speech Synthesis (XML) markup. The TTS system has to be able to generate acceptable speech from plain text, but can improve the quality using the markup tags van Son & Weenink (IFA, ACLC) Speech recognition and synthesis Fall 2008 5 / 4 Automatic Text-To-Speech synthesis Computer Speech Computer Speech: Generating the sound Speech Synthesizers can be classified on the way they generate speech sounds. This determines the type, and amount, of data that have to be collected. Speech Synthesis Articulatory models Rules (formant synthesis) Diphone concatenation Unit selection van Son & Weenink (IFA, ACLC) Speech recognition and synthesis Fall 2008 6 / 4 Automatic Text-To-Speech synthesis Computer Speech