Proceedings of Clouds and Big Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Netapp Solutions for Hadoop Reference Architecture: Cloudera Faiz Abidi (Netapp) and Udai Potluri (Cloudera) June 2018 | WP-7217
White Paper NetApp Solutions for Hadoop Reference Architecture: Cloudera Faiz Abidi (NetApp) and Udai Potluri (Cloudera) June 2018 | WP-7217 In partnership with Abstract There has been an exponential growth in data over the past decade and analyzing huge amounts of data in a reasonable time can be a challenge. Apache Hadoop is an open- source tool that can help your organization quickly mine big data and extract meaningful patterns from it. However, enterprises face several technical challenges when deploying Hadoop, specifically in the areas of cluster availability, operations, and scaling. NetApp® has developed a reference architecture with Cloudera to deliver a solution that overcomes some of these challenges so that businesses can ingest, store, and manage big data with greater reliability and scalability and with less time spent on operations and maintenance. This white paper discusses a flexible, validated, enterprise-class Hadoop architecture that is based on NetApp E-Series storage using Cloudera’s Hadoop distribution. TABLE OF CONTENTS 1 Introduction ........................................................................................................................................... 4 1.1 Big Data ..........................................................................................................................................................4 1.2 Hadoop Overview ...........................................................................................................................................4 2 NetApp E-Series -

Hadoop Tutorials Cassandra Hector API Request Tutorial About
Home Big Data Hadoop Tutorials Cassandra Hector API Request Tutorial About LABELS: HADOOP-TUTORIAL, HDFS 3 OCTOBER 2013 Hadoop Tutorial: Part 1 - What is Hadoop ? (an Overview) Hadoop is an open source software framework that supports data intensive distributed applications which is licensed under Apache v2 license. At-least this is what you are going to find as the first line of definition on Hadoop in Wikipedia. So what is data intensive distributed applications? Well data intensive is nothing but BigData (data that has outgrown in size) anddistributed applications are the applications that works on network by communicating and coordinating with each other by passing messages. (say using a RPC interprocess communication or through Message-Queue) Hence Hadoop works on a distributed environment and is build to store, handle and process large amount of data set (in petabytes, exabyte and more). Now here since i am saying that hadoop stores petabytes of data, this doesn't mean that Hadoop is a database. Again remember its a framework that handles large amount of data for processing. You will get to know the difference between Hadoop and Databases (or NoSQL Databases, well that's what we call BigData's databases) as you go down the line in the coming tutorials. Hadoop was derived from the research paper published by Google on Google File System(GFS) and Google's MapReduce. So there are two integral parts of Hadoop: Hadoop Distributed File System(HDFS) and Hadoop MapReduce. Hadoop Distributed File System (HDFS) HDFS is a filesystem designed for storing very large files with streaming data accesspatterns, running on clusters of commodity hardware. -

MÁSTER EN INGENIERÍA WEB Proyecto Fin De Máster
UNIVERSIDAD POLITÉCNICA DE MADRID Escuela Técnica Superior de Ingeniería de Sistemas Informáticos MÁSTER EN INGENIERÍA WEB Proyecto Fin de Máster …Estudio Conceptual de Big Data utilizando Spring… Autor Gabriel David Muñumel Mesa Tutor Jesús Bernal Bermúdez 1 de julio de 2018 Estudio Conceptual de Big Data utilizando Spring AGRADECIMIENTOS Gracias a mis padres Julian y Miriam por todo el apoyo y empeño en que siempre me mantenga estudiando. Gracias a mi tia Gloria por sus consejos e ideas. Gracias a mi hermano José Daniel y mi cuñada Yule por siempre recordarme que con trabajo y dedicación se pueden alcanzar las metas. [UPM] Máster en Ingeniería Web RESUMEN Big Data ha sido el término dado para aglomerar la gran cantidad de datos que no pueden ser procesados por los métodos tradicionales. Entre sus funciones principales se encuentran la captura de datos, almacenamiento, análisis, búsqueda, transferencia, visualización, monitoreo y modificación. Las empresas han visto en Big Data una poderosa herramienta para mejorar sus negocios en una economía mundial basada firmemente en el conocimiento. Los datos son el combustible para las compañías modernas y, por lo tanto, dar sentido a estos datos permite realmente comprender las conexiones invisibles dentro de su origen. En efecto, con mayor información se toman mejores decisiones, permitiendo la creación de estrategias integrales e innovadoras que garanticen resultados exitosos. Dada la creciente relevancia de Big Data en el entorno profesional moderno ha servido como motivación para la realización de este proyecto. Con la utilización de Java como software de desarrollo y Spring como framework web se desea analizar y comprobar qué herramientas ofrecen estas tecnologías para aplicar procesos enfocados en Big Data. -

Orchestrating Big Data Analysis Workflows in the Cloud: Research Challenges, Survey, and Future Directions
00 Orchestrating Big Data Analysis Workflows in the Cloud: Research Challenges, Survey, and Future Directions MUTAZ BARIKA, University of Tasmania SAURABH GARG, University of Tasmania ALBERT Y. ZOMAYA, University of Sydney LIZHE WANG, China University of Geoscience (Wuhan) AAD VAN MOORSEL, Newcastle University RAJIV RANJAN, Chinese University of Geoscienes and Newcastle University Interest in processing big data has increased rapidly to gain insights that can transform businesses, government policies and research outcomes. This has led to advancement in communication, programming and processing technologies, including Cloud computing services and technologies such as Hadoop, Spark and Storm. This trend also affects the needs of analytical applications, which are no longer monolithic but composed of several individual analytical steps running in the form of a workflow. These Big Data Workflows are vastly different in nature from traditional workflows. Researchers arecurrently facing the challenge of how to orchestrate and manage the execution of such workflows. In this paper, we discuss in detail orchestration requirements of these workflows as well as the challenges in achieving these requirements. We alsosurvey current trends and research that supports orchestration of big data workflows and identify open research challenges to guide future developments in this area. CCS Concepts: • General and reference → Surveys and overviews; • Information systems → Data analytics; • Computer systems organization → Cloud computing; Additional Key Words and Phrases: Big Data, Cloud Computing, Workflow Orchestration, Requirements, Approaches ACM Reference format: Mutaz Barika, Saurabh Garg, Albert Y. Zomaya, Lizhe Wang, Aad van Moorsel, and Rajiv Ranjan. 2018. Orchestrating Big Data Analysis Workflows in the Cloud: Research Challenges, Survey, and Future Directions. -

Apache Oozie Apache Oozie Get a Solid Grounding in Apache Oozie, the Workflow Scheduler System for “In This Book, the Managing Hadoop Jobs
Apache Oozie Apache Oozie Apache Get a solid grounding in Apache Oozie, the workflow scheduler system for “In this book, the managing Hadoop jobs. In this hands-on guide, two experienced Hadoop authors have striven for practitioners walk you through the intricacies of this powerful and flexible platform, with numerous examples and real-world use cases. practicality, focusing on Once you set up your Oozie server, you’ll dive into techniques for writing the concepts, principles, and coordinating workflows, and learn how to write complex data pipelines. tips, and tricks that Advanced topics show you how to handle shared libraries in Oozie, as well developers need to get as how to implement and manage Oozie’s security capabilities. the most out of Oozie. ■ Install and confgure an Oozie server, and get an overview of A volume such as this is basic concepts long overdue. Developers ■ Journey through the world of writing and confguring will get a lot more out of workfows the Hadoop ecosystem ■ Learn how the Oozie coordinator schedules and executes by reading it.” workfows based on triggers —Raymie Stata ■ Understand how Oozie manages data dependencies CEO, Altiscale ■ Use Oozie bundles to package several coordinator apps into Oozie simplifies a data pipeline “ the managing and ■ Learn about security features and shared library management automating of complex ■ Implement custom extensions and write your own EL functions and actions Hadoop workloads. ■ Debug workfows and manage Oozie’s operational details This greatly benefits Apache both developers and Mohammad Kamrul Islam works as a Staff Software Engineer in the data operators alike.” engineering team at Uber. -

Building Machine Learning Inference Pipelines at Scale
Building Machine Learning inference pipelines at scale Julien Simon Global Evangelist, AI & Machine Learning @julsimon © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Problem statement • Real-life Machine Learning applications require more than a single model. • Data may need pre-processing: normalization, feature engineering, dimensionality reduction, etc. • Predictions may need post-processing: filtering, sorting, combining, etc. Our goal: build scalable ML pipelines with open source (Spark, Scikit-learn, XGBoost) and managed services (Amazon EMR, AWS Glue, Amazon SageMaker) © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Apache Spark https://spark.apache.org/ • Open-source, distributed processing system • In-memory caching and optimized execution for fast performance (typically 100x faster than Hadoop) • Batch processing, streaming analytics, machine learning, graph databases and ad hoc queries • API for Java, Scala, Python, R, and SQL • Available in Amazon EMR and AWS Glue © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. MLlib – Machine learning library https://spark.apache.org/docs/latest/ml-guide.html • Algorithms: classification, regression, clustering, collaborative filtering. • Featurization: feature extraction, transformation, dimensionality reduction. • Tools for constructing, evaluating and tuning pipelines • Transformer – a transform function that maps a DataFrame into a new -

Accordion: Better Memory Organization for LSM Key-Value Stores
Accordion: Better Memory Organization for LSM Key-Value Stores Edward Bortnikov Anastasia Braginsky Eshcar Hillel Yahoo Research Yahoo Research Yahoo Research [email protected] [email protected] [email protected] Idit Keidar Gali Sheffi Technion and Yahoo Research Yahoo Research [email protected] gsheffi@oath.com ABSTRACT of applications for which they are used continuously in- Log-structured merge (LSM) stores have emerged as the tech- creases. A small sample of recently published use cases in- nology of choice for building scalable write-intensive key- cludes massive-scale online analytics (Airbnb/ Airstream [2], value storage systems. An LSM store replaces random I/O Yahoo/Flurry [7]), product search and recommendation (Al- with sequential I/O by accumulating large batches of writes ibaba [13]), graph storage (Facebook/Dragon [5], Pinter- in a memory store prior to flushing them to log-structured est/Zen [19]), and many more. disk storage; the latter is continuously re-organized in the The leading approach for implementing write-intensive background through a compaction process for efficiency of key-value storage is log-structured merge (LSM) stores [31]. reads. Though inherent to the LSM design, frequent com- This technology is ubiquitously used by popular key-value pactions are a major pain point because they slow down storage platforms [9, 14, 16, 22,4,1, 10, 11]. The premise data store operations, primarily writes, and also increase for using LSM stores is the major disk access bottleneck, disk wear. Another performance bottleneck in today's state- exhibited even with today's SSD hardware [14, 33, 34]. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Betrfs: a Right-Optimized Write-Optimized File System
BetrFS: A Right-Optimized Write-Optimized File System William Jannen, Jun Yuan, Yang Zhan, Amogh Akshintala, Stony Brook University; John Esmet, Tokutek Inc.; Yizheng Jiao, Ankur Mittal, Prashant Pandey, and Phaneendra Reddy, Stony Brook University; Leif Walsh, Tokutek Inc.; Michael Bender, Stony Brook University; Martin Farach-Colton, Rutgers University; Rob Johnson, Stony Brook University; Bradley C. Kuszmaul, Massachusetts Institute of Technology; Donald E. Porter, Stony Brook University https://www.usenix.org/conference/fast15/technical-sessions/presentation/jannen This paper is included in the Proceedings of the 13th USENIX Conference on File and Storage Technologies (FAST ’15). February 16–19, 2015 • Santa Clara, CA, USA ISBN 978-1-931971-201 Open access to the Proceedings of the 13th USENIX Conference on File and Storage Technologies is sponsored by USENIX BetrFS: A Right-Optimized Write-Optimized File System William Jannen, Jun Yuan, Yang Zhan, Amogh Akshintala, John Esmet∗, Yizheng Jiao, Ankur Mittal, Prashant Pandey, Phaneendra Reddy, Leif Walsh∗, Michael Bender, Martin Farach-Colton†, Rob Johnson, Bradley C. Kuszmaul‡, and Donald E. Porter Stony Brook University, ∗Tokutek Inc., †Rutgers University, and ‡Massachusetts Institute of Technology Abstract (microwrites). Examples include email delivery, creat- The Bε -tree File System, or BetrFS, (pronounced ing lock files for an editing application, making small “better eff ess”) is the first in-kernel file system to use a updates to a large file, or updating a file’s atime. The un- write-optimized index. Write optimized indexes (WOIs) derlying problem is that many standard data structures in are promising building blocks for storage systems be- the file-system designer’s toolbox optimize for one case cause of their potential to implement both microwrites at the expense of another. -

Polycom Realpresence Cloudaxis Open Source Software OFFER
Polycom® RealPresence® CloudAXIS™ Suite OFFER of Source for GPL and LGPL Software You may have received from Polycom®, certain products that contain—in part—some free software (software licensed in a way that allows you the freedom to run, copy, distribute, change, and improve the software). As a part of this product, Polycom may have distributed to you software, or made electronic downloads, that contain a version of several software packages, which are free software programs developed by the Free Software Foundation. With your purchase of the Polycom RealPresence® CloudAXIS™ Suite, Polycom has granted you a license to the above-mentioned software under the terms of the GNU General Public License (GPL), GNU Library General Public License (LGPLv2), GNU Lesser General Public License (LGPL), or BSD License. The text of these Licenses can be found at the internet address provided in Table A. For at least three years from the date of distribution of the applicable product or software, we will give to anyone who contacts us at the contact information provided below, for a charge of no more than our cost of physically distributing, the following items: • A copy of the complete corresponding machine-readable source code for programs listed below that are distributed under the GNU GPL • A copy of the corresponding machine-readable source code for the libraries listed below that are distributed under the GNU LGPL, as well as the executable object code of the Polycom work that the library links with The software included or distributed for the product, including any software that may be downloaded electronically via the internet or otherwise (the "Software") is licensed, not sold. -

Algorithms and Complexity (AL)
Algorithms and Complexity (AL) Algorithms are fundamental to computer science and software engineering. The real-world performance of any software system depends on the algorithms chosen and the suitability of the various layers of implementation. Good algorithm design is therefore crucial for the performance of all software systems. Moreover, the study of algorithms provides insight into the intrinsic nature of the problem as well as possible solution techniques independent of programming language, programming paradigm, computer hardware, or any other implementation aspect. An important part of computing is the ability to select algorithms appropriate to particular purposes and to apply them, recognizing the possibility that no suitable algorithm may exist. This facility relies on understanding the range of algorithms that address an important set of well-defined problems, recognizing their strengths and weaknesses, and their suitability in particular contexts. Efficiency is a pervasive theme throughout this area. This knowledge area defines the central concepts and skills required to design, implement, and analyze algorithms for solving problems. Algorithms are essential in all advanced areas of computer science: artificial intelligence, databases, distributed computing, graphics, networking, operating systems, programming languages, security, and so on. Algorithms that have specific utility in each of these are listed in the relevant knowledge areas. Cryptography, for example, appears in the new Knowledge Area on Information Assurance and Security (IAS), while parallel and distributed algorithms appear in the Knowledge Area in Parallel and Distributed Computing (PD). As with all knowledge areas, the order of topics and their groupings do not necessarily correlate to a specific order of presentation. Different programs will teach the topics in different courses and should do so in the order they believe is most appropriate for their students. -
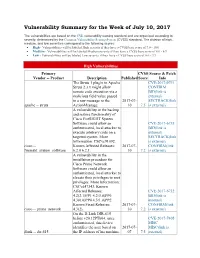
Vulnerability Summary for the Week of July 10, 2017
Vulnerability Summary for the Week of July 10, 2017 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 High Vulnerabilities Primary CVSS Source & Patch Vendor -- Product Description Published Score Info The Struts 1 plugin in Apache CVE-2017-9791 Struts 2.3.x might allow CONFIRM remote code execution via a BID(link is malicious field value passed external) in a raw message to the 2017-07- SECTRACK(link apache -- struts ActionMessage. 10 7.5 is external) A vulnerability in the backup and restore functionality of Cisco FireSIGHT System Software could allow an CVE-2017-6735 authenticated, local attacker to BID(link is execute arbitrary code on a external) targeted system. More SECTRACK(link Information: CSCvc91092. is external) cisco -- Known Affected Releases: 2017-07- CONFIRM(link firesight_system_software 6.2.0 6.2.1. 10 7.2 is external) A vulnerability in the installation procedure for Cisco Prime Network Software could allow an authenticated, local attacker to elevate their privileges to root privileges. More Information: CSCvd47343. Known Affected Releases: CVE-2017-6732 4.2(2.1)PP1 4.2(3.0)PP6 BID(link is 4.3(0.0)PP4 4.3(1.0)PP2.